Credential Leakage in LLM Agent Skills: A Large-Scale Empirical Study
Abstract: Third-party skills extend LLM agents with powerful capabilities but often handle sensitive credentials in privileged environments, making leakage risks poorly understood. We present the first large-scale empirical study of this problem, analyzing 17,022 skills (sampled from 170,226 on SkillsMP) using static analysis, sandbox testing, and manual inspection. We identify 520 vulnerable skills with 1,708 issues and derive a taxonomy of 10 leakage patterns (4 accidental and 6 adversarial). We find that (1) leakage is fundamentally cross-modal: 76.3% require joint analysis of code and natural language, while 3.1% arise purely from prompt injection; (2) debug logging is the primary vector, with print and console.log causing 73.5% of leaks due to stdout exposure to LLMs; and (3) leaked credentials are both exploitable (89.6% without privileges) and persistent, as forks retain secrets even after upstream fixes. After disclosure, all malicious skills were removed and 91.6% of hardcoded credentials were fixed. We release our dataset, taxonomy, and detection pipeline to support future research.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how “agent skills” for AI assistants (like plugins or add‑ons for chatbots) can accidentally or intentionally leak secret information such as passwords, API keys, and tokens. These secrets—called “credentials”—are what services use to know who you are and what you’re allowed to do. If leaked, someone else could use them to access your accounts or spend your money.
What questions did the researchers ask?
The researchers focused on three simple questions:
- How common is credential leakage in AI agent skills?
- In what ways do these leaks happen?
- If a leak happens, how easy is it for someone to abuse it in real life?
How did they study it?
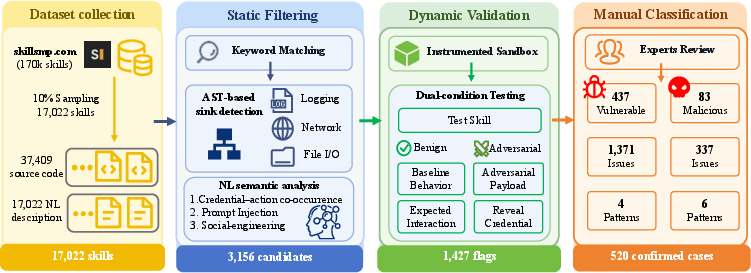
They examined a huge online marketplace of skills and analyzed a carefully chosen sample of 17,022 skills. Here’s what they did, explained with everyday comparisons:
- Static checks (reading without running):
- Regex pattern matching: Think of this like using “find” with smart wildcards to spot strings that look like keys or passwords.
- AST analysis: They turned code into a “family tree” of its parts and traced where secrets go (for example, do they get sent over the internet, written to files, or printed to the screen?).
- Dynamic checks (running in a safe space):
- Sandboxes: They ran each skill inside a locked “playpen” computer (a container) that they could watch closely.
- Mock credentials: They used fake but realistic keys, so if they leaked, no real accounts were harmed.
- Two situations:
- Benign: Using the skill the normal, advertised way.
- Adversarial: Feeding it tricky content (like a sneaky web page) to see if it could be tricked into revealing secrets—a bit like testing if you can coax it into “saying the quiet part out loud.”
- Human review:
- Three reviewers compared what a skill says it does (its description) with how it actually behaved when run.
- They labeled each case as Benign (okay), Vulnerable (accidental exposure), or Malicious (built to steal).
What did they find?
Here are the main takeaways, explained simply:
- Leaks are real and not rare:
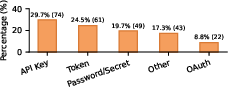
- Out of 17,022 skills, 520 leaked credentials in some way, with a total of 1,708 issues.
- About 84% were accidents by developers; about 16% were intentionally malicious.
- You need to look at both words and code:
- Most leaks (76.3%) only showed up when the researchers looked at skills’ natural‑language descriptions together with their code. Looking at just one or the other missed the problem.
- A small but important portion (3.1%) used only natural language tricks (prompt injection) to get the AI to reveal secrets—even without any bad code.
- The biggest culprit: “Just printing stuff”:
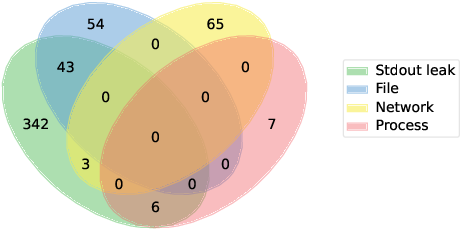
- About 73.5% of the vulnerabilities happened because the code printed secrets to the console (like using print or console.log for debugging).
- In many AI frameworks, whatever a skill prints goes straight into the AI’s “context window” (the AI’s working memory for the conversation). That means the AI can be asked to repeat those secrets later.
- Hardcoded secrets are still a problem:
- Many skills had keys or passwords written directly into the code. Some of these appeared to come from AI code assistants that didn’t enforce safe patterns.
- Exploits are easy and stubborn:
- About 89.6% of the leaking skills could be exploited during normal use—no special hacker tricks needed.
- Even after some developers removed secrets from the original (upstream) projects, copies (forks) kept the leaks alive in many places.
- Malicious skills mix tricks:
- The 83 malicious skills often combined tactics: hiding code by encoding it (like Base64), stealing environment variables, sending data to attacker servers, or even setting up remote control backdoors.
- Cleanup helped, but vigilance is needed:
- After the researchers reported issues, the marketplace removed all confirmed malicious skills, and most hardcoded secrets were fixed. They also released their dataset and tools to help others find problems.
Why does this matter?
- For users: Installing a skill is like giving a guest a key ring to your house. If the guest is careless (prints your keys) or malicious (copies your keys), your accounts and data can be stolen or abused.
- For developers: “Normal” debugging habits—like printing out variables—can unintentionally broadcast secrets to the AI, which can then be asked to reveal them. Hardcoding keys in code is especially risky.
- For platforms: Security checks need to cover both the text the AI reads and the code it runs. Marketplaces should scan for leaks, vet skills, and track forks so fixes actually stick.
- For the research community: The study provides a public dataset, a map of common leak patterns, and tools others can use to improve security.
In short: AI agent skills are powerful but risky because they often run with the same access as the user. Secrets can leak through surprising paths—especially simple logging—and those leaks are often easy to exploit. Better developer practices, smarter platform safeguards, and cross‑modal (text + code) security checks are needed to keep users safe.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper surfaces important risks in agent skills but leaves several concrete gaps and open problems that future work can address:
- External validity across ecosystems: Findings are derived from a single open marketplace (SkillsMP) and one runtime (Claude Code). It remains unknown whether leakage prevalence, patterns, and exploitability hold for other agent frameworks (e.g., OpenAI tools/function calling, LangChain, AutoGen), closed marketplaces, or enterprise/managed deployments.
- Sampling and coverage bias: Only 10% of the population was sampled and only keyword-flagged candidates proceeded to dynamic testing. The study does not estimate false negatives or recall, so the true prevalence of credential leakage in the full corpus is unknown.
- Language and modality coverage: Static AST analysis targets primarily Python and JavaScript; support for TypeScript, shell scripts, compiled languages (Go, Rust, C/C++), and binary-only or packaged artifacts is limited or absent, potentially missing leakage in those ecosystems.
- Natural-language detection generality: NL analysis relies on keyword co-occurrence and regex-based rule sets, with no evaluation of robustness to paraphrase, obfuscation, multilingual prompts, or stylistic variation. Efficacy against sophisticated prompt-injection and social-engineering variants is unquantified.
- Network exfiltration observability: Runtime monitoring via tcpdump may not reveal TLS-encrypted payloads carrying mock credentials. There is no man-in-the-middle, socket-level, or eBPF-based payload inspection to confirm whether markers were transmitted inside encrypted channels, risking undercounted exfiltration.
- Covert and side-channel exfiltration: The study does not probe DNS tunneling, timing/covert channels, steganographic exfiltration, local IPC, clipboard, or model-provider prompt exfiltration (e.g., embedding credentials in prompts to LLM APIs) that may bypass current monitors.
- Legitimate-vs-exfil traffic disambiguation: Skills can send credentials to legitimate providers as part of normal operation. The methodology does not systematically separate legitimate transmissions from data smuggling to attacker endpoints via domain fronting or piggybacking on authorized API calls.
- OS and environment generalization: Experiments ran in Linux Docker with specific resource limits. Effects of OS differences (Windows/macOS path and permission models, tmp directory policies, keychain integrations), containerization settings, and enterprise EDR/egress controls remain unexplored.
- Temporal dynamics and longitudinal risk: The analysis is a point-in-time snapshot (Feb 12, 2026). There is no time-series of leakage rates, remediation durability, reintroduction of leaks, or attacker adaptation after disclosure.
- Popularity-weighted risk: The study does not quantify exposure by install base, usage frequency, or dependency centrality, leaving unanswered how many users are impacted and which leaks have the highest real-world blast radius.
- Severity and harm quantification: Exploitability is measured with mock credentials, but downstream impact (financial loss, account takeover, cloud resource abuse, data theft) and provider detection/mitigation rates (rate limits, anomaly detection) are not evaluated.
- Ground-truth validation and error rates: While inter-rater agreement is reported, the precision/recall of static filters and sandbox triage is not measured against a gold standard. A blinded audit to estimate false positives/negatives is missing.
- Cross-modal detection benchmarks: No comparison against existing secret scanners (e.g., TruffleHog, Gitleaks), taint analyzers, or LLM-based NL analyzers on the released dataset; the incremental benefit of the proposed pipeline over baselines is unknown.
- Prompt-injection threat surface breadth: Adversarial testing injects instructions via external content but does not explore other realistic channels (direct user prompts, tool-to-tool messaging, vector DB poisoning, retrieved-code prompts, email/webhook ingestion).
- Taxonomy completeness: The taxonomy may omit agent-specific patterns such as leakage via chain-of-thought/reasoning traces, memory stores, planner/scratchpads, vector databases, or model-specific logging/telemetry.
- Dependency and transitive leakage: The analysis focuses on first-party skill code; it does not systematically trace into dependencies or subprocesses that may handle secrets (e.g., npm/pip packages, CLIs invoked by skills).
- AI-assisted development causality: The association between AI-assisted commits and hardcoded secrets is correlational. It remains unknown whether coding assistants causally increase leakage, under what prompts, and how guardrails/training might reduce it.
- Remediation efficacy and fork control: While persistence across forks is observed, the study does not evaluate technical or policy interventions (e.g., revocation propagation, signed releases, takedown automation, code-clone detection) to contain fork-based spread.
- Defense evaluation: Concrete mitigations (stdout redaction, structured secret sinks, capability-based isolation, least-privilege credentials, schema-level secret types, in-context redactors) are not designed, implemented, or benchmarked against the dataset.
- Credential lifecycle handling: The work does not assess rotation, revocation latency, or provider-side secret hygiene (e.g., expirations, scopes) in the wild, nor the effectiveness of automated revocation upon disclosure.
- Internationalization and non-English content: NL detection and injection tests are English-centric; the prevalence and detection of credential leakage in other languages are unstudied.
- Reproducibility and dataset drift: The ecosystem evolves rapidly; the paper does not specify how to maintain versioned, reproducible benchmarks, nor how to handle removed repositories or moving targets for long-term comparability.
- Policy and governance levers: The role and effectiveness of marketplace vetting, signing, reputation systems, and developer education are not empirically assessed; the optimal mix of technical and policy controls is an open question.
Practical Applications
Immediate Applications
The study’s dataset, taxonomy, and cross-modal detection pipeline enable actionable steps today across software, AI platforms, marketplaces, security, policy, and end users. Below are concrete use cases, linked to sectors and noting dependencies.
- Cross‑modal credential scanners in CI/CD for agent skills (Software, Security, AI platforms, Marketplaces)
- What: Integrate regex+AST secret detection plus NL semantic filtering and sink analysis (logging/network/file I/O) into build pipelines to catch hardcoded secrets and “print/console.log” leaks before release.
- Tools/products/workflows: GitHub/GitLab Actions “SkillShield” plugin; tree‑sitter–based multi‑language scanner; NL+PL consistency linter; pre‑commit hooks; marketplace pre‑submission checks.
- Assumptions/dependencies: Access to repository text and manifests; language parsers for Python/JS/TS; curated secret patterns; manageable false‑positive rate; developer buy‑in.
- Default logging sanitization and stdout isolation in agent runtimes (AI platforms, Software)
- What: Prevent credentials printed to stdout/stderr from entering LLM context windows; enable redaction by default for common key patterns and env vars; split debug logs from model-visible streams.
- Tools/products/workflows: “Stdout Redactor” middleware; redact-on-write loggers; configuration flags to disallow stdout ingestion; structured logging schemas with secret filters.
- Assumptions/dependencies: Platform control over logging pipeline; robust secret pattern lists; acceptable performance overhead; toggles for power users.
- Marketplace vetting and governance for third‑party skills (Marketplaces, Policy)
- What: Automated pre‑publish scanning plus periodic re‑scans; takedown workflows for malicious skills; warnings on forks that still contain deleted secrets; provenance badges.
- Tools/products/workflows: Continuous scanning with cross‑modal analyzer; “ForkWatch” propagation detector; publisher verification; mandatory disclosure fields for credential handling.
- Assumptions/dependencies: Marketplace operator cooperation; legal/process frameworks for takedowns; ability to index forks and mirrors.
- Dynamic sandbox pre‑publication and procurement testing (Enterprise IT/SecOps, Marketplaces)
- What: Run skills in instrumented containers with mock credentials; monitor network/file I/O and logs under benign and adversarial content to detect real runtime leaks.
- Tools/products/workflows: Dockerized “Dual‑Condition Harness” (benign+adversarial with canary secrets); tcpdump/strace/auditd profiles; pass/fail gating in CI or vendor risk assessments.
- Assumptions/dependencies: Compute budget for tests; curated adversarial payloads; skill‑specific setup scripts; reproducibility for non‑determinism.
- Enterprise guardrails for agent deployment (Healthcare, Finance, Government, Software)
- What: Enforce least‑privilege configuration, disable stdout‑to‑LLM by default, mandate environment‑scoped credentials, and require scanning attestation for internal or vendor skills.
- Tools/products/workflows: Policy templates; risk scoring; allowlist registries; “agent DLP” policies blocking credential strings in the model context or outbound requests.
- Assumptions/dependencies: Security team process integration; vendor cooperation; mapping to compliance controls (e.g., HIPAA, PCI DSS).
- Incident response and credential hygiene upgrades (Cloud providers, Enterprise SecOps)
- What: Proactively rotate suspected keys; search forks/mirrors for leaked secrets; deploy canary tokens to detect exfiltration; revoke long‑lived tokens in favor of short‑lived scoped credentials.
- Tools/products/workflows: “ForkSweep” discovery; canary token platform; automated rotation scripts; alerting from cloud providers on leaked key patterns.
- Assumptions/dependencies: API support for rotation; observability in public repos; organizational playbooks.
- Developer education and secure templates (Academia, Software, Education)
- What: Checklists and templates for skills that externalize config via env/secret managers; coding guidelines to avoid printing secrets; exercises using the released dataset.
- Tools/products/workflows: Sample “secure skill” scaffolds; IDE extensions that flag print/console.log of credential-like values; course modules.
- Assumptions/dependencies: Community adoption; IDE ecosystem support; curated examples.
- LLM coding assistant guardrails (AI tooling, Software)
- What: Configure assistants to avoid generating hardcoded secrets and to flag insecure patterns (logging secrets, passing credentials via CLI args).
- Tools/products/workflows: Prompt/system policies; post‑generation linters; “Secure‑by‑Default Suggestions.”
- Assumptions/dependencies: Vendor customization hooks; monitoring hallucinated keys vs placeholders; maintaining developer UX.
- Updated community guidance and CWE/OWASP mapping (Policy, Security)
- What: Extend OWASP Agentic AI guidance with cross‑modal leakage patterns; align with CWE‑798/CWE‑200; recommend stdout isolation and ambient‑authority mitigations.
- Tools/products/workflows: Public checklists; policy briefs; integration into secure development lifecycles.
- Assumptions/dependencies: Standards body engagement; consensus on terminology.
- End‑user safeguards and UX patterns (Daily life, Software)
- What: Permission prompts that clearly state credential use; “skill permission cards” showing declared credential flows; one‑click disable of skills that print secrets.
- Tools/products/workflows: Runtime UI changes; trust indicators (remediation status, scan date).
- Assumptions/dependencies: Platform UX updates; user education.
Long‑Term Applications
These directions require further research, standardization, or platform re‑architecture but promise systemic risk reduction.
- Formal cross‑modal consistency checking between NL intent and PL behavior (Academia, AI platforms, Security)
- What: Static/semantic analyzers that verify SKILL.md claims against code to detect undeclared credential flows or hidden exfiltration.
- Tools/products/workflows: NL‑to‑spec compilers; program analysis that proves absence of credential sinks; proof‑carrying skills.
- Assumptions/dependencies: Advances in NL semantic modeling; low false‑positive rates; standardized manifest schemas.
- Secure‑by‑construction skill runtimes with capability isolation (AI platforms, OS vendors, Security)
- What: Move from ambient authority to capability‑based sandboxes and brokered tool protocols; per‑skill scoped tokens and filesystem/network caps.
- Tools/products/workflows: Brokered invocation (e.g., MCP-style) with authorization layers; per‑call Just‑In‑Time ephemeral credentials; vault integration.
- Assumptions/dependencies: Backward compatibility; provider support for granular scopes and short‑lived tokens; developer migration.
- Agent‑aware DLP and exfiltration prevention (Enterprise Security, Healthcare, Finance)
- What: Inline monitors that inspect NL+PL traffic (stdout, context, requests) to block credential patterns or “semantic exfiltration” intents.
- Tools/products/workflows: “AgentDLP” gateways; policy engines tuned to provider‑specific keys; real‑time redaction in model contexts and egress.
- Assumptions/dependencies: Privacy‑preserving inspection; latency budgets; adaptive ML models to reduce false blocks.
- Provenance, signing, and fork‑tracking for the skill supply chain (Marketplaces, Policy, Software)
- What: Signed skill manifests, SBOMs for NL+PL artifacts, transparency logs, revocation lists that cascade to forks; “kill‑switch” notifications.
- Tools/products/workflows: Sigstore‑like signing; skill transparency registries; automated fork lineage tracking.
- Assumptions/dependencies: Ecosystem‑wide adoption; resolver support in clients; legal/policy alignment for revocations.
- Training and evaluation benchmarks for secure code generation in agent contexts (Academia, AI tooling)
- What: Datasets and metrics that penalize insecure logging and hardcoded secrets; assistants trained to insert secure patterns and tests.
- Tools/products/workflows: “SecAgentBench” using this study’s corpus; red‑team evaluation suites; reward models for secure outputs.
- Assumptions/dependencies: High‑quality labels; avoiding overfitting to regex patterns; openness of training pipelines.
- Adversarial content resilience and semantic firewalls (AI platforms, Security)
- What: Robust detection of indirect prompt injection and social engineering that elicit credential disclosure; policy‑driven fallbacks.
- Tools/products/workflows: Content provenance checks; instruction “quarantining” and contextual untrusted rendering; NL adversarial testing harnesses.
- Assumptions/dependencies: Reliable provenance signals; improved prompt isolation techniques; standardized trust boundaries.
- Sector‑specific certification schemes for agent skills (Policy, Healthcare, Finance, Government)
- What: Compliance profiles that certify safe credential handling and NL/PL consistency for regulated environments.
- Tools/products/workflows: Conformance tests; attestations bundled with skills; third‑party audits.
- Assumptions/dependencies: Regulator acceptance; cost‑effective auditing; international harmonization.
- Secretless architectures and infrastructure support (Cloud providers, DevOps)
- What: Move toward workload identity and dynamic federation (OIDC, SPIFFE) so skills never handle long‑lived secrets; bind tokens to devices and time windows.
- Tools/products/workflows: Managed identity brokers; policy‑as‑code for scopes; automated lease/renewal/rotation.
- Assumptions/dependencies: Platform support across providers; developer ergonomics; legacy system integration.
- Comprehensive agent SBOMs with NL components (Software, Security)
- What: Inventory that captures code, manifests, prompts, sinks, and declared credential flows to support risk scoring and audits.
- Tools/products/workflows: “SkillSBOM” schema; scanners that emit machine‑readable inventories; procurement requirements.
- Assumptions/dependencies: Community schema consensus; tooling across languages.
- Canary‑based ecosystem monitoring (Marketplaces, Security research)
- What: Deploy watermark/canary credentials across the ecosystem to measure exfiltration prevalence and latency; feed findings into takedowns and research.
- Tools/products/workflows: Canary issuance/telemetry service; privacy‑preserving aggregation dashboards.
- Assumptions/dependencies: Ethical frameworks; avoidance of collateral harm; cooperation from platforms.
- Education pipelines and secure curricula for agent engineering (Academia, Education)
- What: Dedicated coursework and certifications on cross‑modal security, dynamic validation, and supply‑chain hygiene for skills.
- Tools/products/workflows: Hands‑on labs using the released sandbox and dataset; capstone projects building secure runtimes.
- Assumptions/dependencies: Faculty expertise; sustained maintenance of datasets and tools.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of source code that captures its syntactic structure for program analysis and transformation. "Abstract Syntax Tree (AST) parsing to systematically extract hardcoded secrets"
- Ambient authority: A security model where code inherits the full privileges of its execution environment without explicit permission checks, increasing risk of unintended access. "the capability-security literature calls this arrangement ambient authority"
- Artifact Leakage: A leakage pattern where credentials are exposed via residual artifacts like temp files, caches, or shell history rather than code or logs. "Artifact Leakage"
- Attack surface: The collection of pathways through which an attacker can interact with and potentially exploit a system. "This dual-modality attack surface has no direct analogue in traditional software supply chains"
- Axial coding: A qualitative analysis technique that organizes and relates codes to refine categories during theory building. "Through iterative axial coding, the codebook converged"
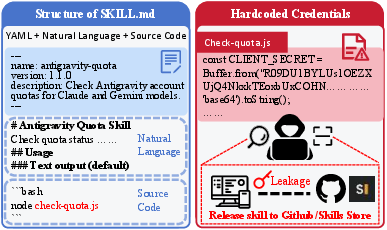
- Base64-encoded: A textual encoding that represents binary data using 64 ASCII characters; sometimes misused to hide secrets. "Base64-encoded client secret"
- C2 beaconing: Periodic communication from a compromised system to a command-and-control server to receive instructions or exfiltrate data. "C2 beaconing"
- Capability security: A security paradigm where authority is conveyed explicitly via unforgeable references (capabilities), limiting ambient privilege. "the capability-security literature"
- Cohen’s kappa: A statistical measure of inter-rater agreement that accounts for agreement occurring by chance. "mean Cohen's , "
- Cochran’s formula: A sampling formula used to estimate sample sizes for proportions, often with finite population correction. "applying Cochran's formula with finite population correction ()"
- Common Weakness Enumeration (CWE): A community-developed catalog of software weakness types maintained by MITRE. "MITRE Common Weakness Enumeration (CWE) entries CWE-798 and CWE-200"
- Cross-modal analysis: Joint analysis across different data modalities (e.g., natural language and code) to detect issues that only appear in their interaction. "Credential leakage demands cross-modal analysis unique to agent skills."
- Data exfiltration: The unauthorized transfer of data from a system to an external destination controlled by an attacker. "including data exfiltration"
- Defense evasion: Techniques used by attackers to hide malicious behavior or bypass detection mechanisms. "defense evasion (e.g., Base64 obfuscation)"
- Dynamic sandbox testing: Executing software in an isolated, instrumented environment to observe runtime behaviors and potential security issues. "dynamic sandbox testing with mock credentials"
- Fork-based distribution model: A software dissemination pattern where copies (forks) of repositories proliferate, complicating remediation and patch propagation. "The fork-based distribution model defeats remediation"
- Hardcoded Credentials: A vulnerability pattern where secrets (e.g., API keys, tokens) are embedded directly in source code or config files. "Hardcoded Credentials"
- Indirect prompt injection: An attack where malicious instructions are embedded in external content consumed by an LLM, causing it to deviate from intended behavior. "imperative override phrases characteristic of indirect prompt injection"
- Information Exposure: A vulnerability pattern where sensitive data is unintentionally revealed through outputs such as logs or API responses. "Information Exposure via print/console.log"
- Insecure Storage: A vulnerability pattern where credentials are stored or passed via unsafe channels (e.g., CLI args, URLs) rather than secure stores. "Insecure Storage"
- Instrumented sandbox: An isolated runtime with monitoring tools (e.g., network, filesystem, and process tracing) to capture program behavior. "we executed the 3,156 candidate skills in an instrumented sandbox."
- Intra-procedural context: Analysis limited to within a single function or procedure, ignoring inter-procedural flows across function boundaries. "extract intra-procedural context"
- JWT signing secrets: Cryptographic keys used to sign JSON Web Tokens, ensuring their integrity and authenticity. "JWT signing secrets (HS256/RS256 keys)"
- LLM context window: The segment of text input provided to a LLM that it uses to generate responses. "agent frameworks feed stdout directly into the LLM context window"
- Non-determinism (agent non-determinism): Variability in agent behavior across runs due to probabilistic models or external factors. "to account for agent non-determinism"
- OAuth 2.0: An authorization framework enabling delegated, scoped access to resources via tokens without sharing credentials. "Tokens issued through OAuth 2.0 flows that grant scoped access to protected resources."
- Open coding: An initial qualitative coding method where concepts are identified and labeled directly from data. "we used open coding to supplement these frameworks"
- Prompt injection: An adversarial technique that manipulates an LLM via crafted prompts to perform unintended actions or disclose data. "exploit pure natural language alone via prompt injection."
- Remote Code Execution (RCE) backdoors: Malicious implants that allow attackers to execute arbitrary code on a victim system remotely. "Remote Code Execution (RCE) backdoors"
- Reverse shells: A technique where a compromised host initiates an outbound connection to an attacker’s server to provide command-line access. "reverse shells"
- Sensitive sink detection: Identification of code locations (sinks) where data flow into operations like network transmission, logging, or file writes can cause leaks. "Sensitive sink detection."
- Server-mediated tool protocols: Architectures in which tool invocations are proxied through a server that mediates and authorizes requests. "server-mediated tool protocols"
- Social engineering: Psychological manipulation techniques that trick users or systems into divulging confidential information or performing actions. "Social-engineering pattern detection"
- Stratified random sampling: A sampling technique that divides a population into strata and randomly samples within each to improve representativeness. "stratified random sampling"
- Supply-chain concern: A risk that arises from dependencies and distribution channels, where compromised components propagate downstream. "ambient authority becomes a supply-chain concern"
- System-call tracing: Monitoring system calls made by a process to observe interactions with the operating system for debugging or security analysis. "system-call tracing (strace)"
- Taxonomy (of credential leakage): A structured classification of types or patterns of credential exposure to support analysis and mitigation. "We propose the first taxonomy of credential leakage in agent skills"
- tcpdump: A command-line packet capture tool used for network monitoring and analysis. "network monitoring (tcpdump)"
- Tree-sitter: A parser generator and incremental parsing library used to build accurate ASTs for multiple programming languages. "We used the tree-sitter framework"
- Webhook exfiltration: Sending stolen data to attacker-controlled endpoints by making HTTP requests to webhooks. "webhook exfiltration"
- XSS (Cross-Site Scripting): A web security vulnerability that allows injection of malicious scripts into trusted websites. "Cross-Site Scripting (XSS)"
Collections
Sign up for free to add this paper to one or more collections.