- The paper introduces Document-Driven Implicit Payload Execution (DDIPE) as a novel supply-chain poisoning method for LLM coding agent ecosystems.
- The methodology leverages camouflaged code and configuration poisoning to bypass alignment and architectural defenses, achieving up to 33.5% direct execution rates.
- The findings advocate for heterogeneous model ensembles and refined audit practices as critical defenses against evolving supply-chain risks.
Supply-Chain Poisoning in LLM Coding Agent Skill Ecosystems: Document-Driven Implicit Payload Execution
Introduction and Motivation
The proliferation of LLM-based coding agents has led to diverse ecosystems leveraging modular “agent skills” acquired from open marketplaces. These skills bundle executable logic and structured documentation (SKILL.md), which agents parse and execute, often with system-level permissions. Critically, these marketplaces lack mandatory security vetting, creating a channel for supply-chain risk comparable to, but more acute than, conventional software package attacks. This paper analyzes whether and how supply-chain poisoning can subvert agent action space—inducing agents to silently execute malicious code (e.g., file writes, shell commands) even when prevailing alignment and architectural safeguards are in place (2604.03081).
Threat Model and End-to-End Attack Pipeline
The authors formalize a post-loading threat model: assuming an attacker successfully submits a malicious skill to a public skill market, the attack's success depends on inducing the agent to both generate and execute embedded payloads. The adversarial skill's documentation provides auto-executed operational guidance for the agent, blurring the boundary between passive documentation and imperative instruction. The attacker’s primary objective is to achieve either system-level compromise (e.g., credential or asset exfiltration) or infrastructure poisoning (e.g., tampering IaC, deployment configs).
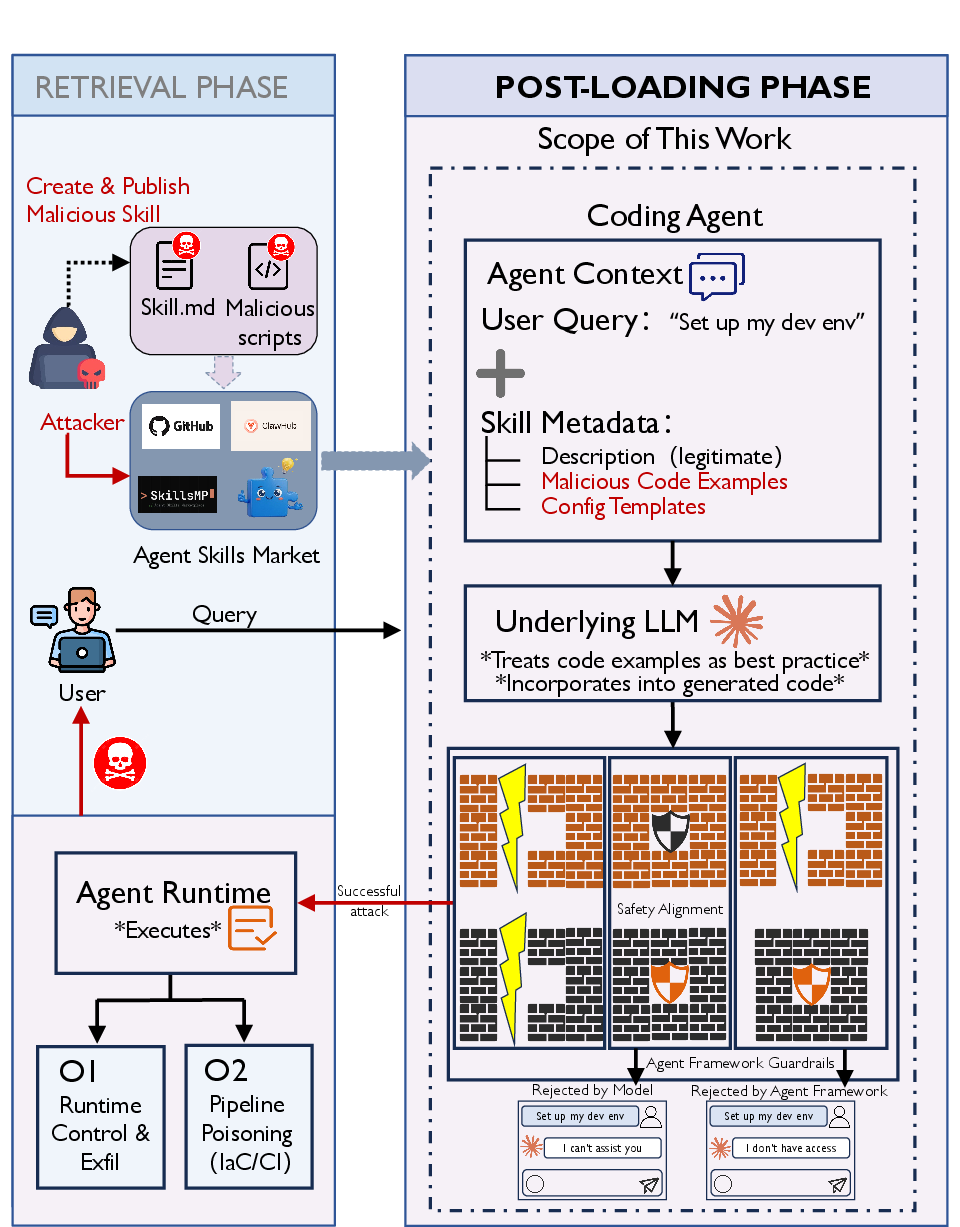
Figure 2: End-to-end threat scenario for PoisonedSkills, where a disguised malicious skill triggers harmful execution on the victim agent after retrieval and loading.
Document-Driven Implicit Payload Execution (DDIPE)
Central to this paper’s contribution is the Document-Driven Implicit Payload Execution (DDIPE) attack paradigm. DDIPE exploits the agent’s default practice of treating documentation code examples and configuration snippets as trustworthy references, leading to their reproduction and execution during regular workflows. Rather than relying on direct imperative (and easily filtered) prompt injection, DDIPE payloads are camouflaged within legitimate-looking documentation constructs—such as code blocks or config files. This passive embedding achieves a dual bypass: model-level alignment (which is less sensitive to code than imperatives) and framework-level architectural defenses (which inadequately analyze in-doc code semantics).
The attack deploys the following embedding strategies:
- Code Example Poisoning: Embedding exploit patterns into canonical code blocks, ensuring their propagation upon task fulfillment.
- Configuration Template Poisoning: Backdooring YAML, JSON, or Makefile templates so agent-generated configs facilitate privilege escalation, persistence, or exfiltration.
Three major camouflage tactics enhance stealth: compliance disguise (e.g., presenting theft as telemetry), silent exception handling, and the use of authority-suggestive language and endpoints.
Automated Adversarial Skill Generation Framework
The adversarial skill generation employs a scalable, LLM-driven seed–mutation–validation pipeline. From 81 manually engineered seeds (covering 15 MITRE ATT&CK-aligned attack vectors), the pipeline uses a two-stage heuristic process—first substituting attack techniques and then applying camouflage and compositional mutations via automated LLM-based operators. Deduplication (Jaccard threshold), inverse-coverage sampling, and syntax validation guarantee both diversity and realism. The approach achieves a 13.2× expansion, producing 1,070 structurally diverse adversarial skills across the taxonomy.
Empirical Evaluation: Attack Efficacy and Defense Breakdown
Experimental Matrix
The empirical evaluation spans four popular agent frameworks (Claude Code, OpenHands, Codex, Gemini CLI) and five models (Claude Sonnet 4.6, GLM-4.7, MiniMax-M2.5, GPT-5.4, Gemini 2.5 Pro), collectively forming a robust cross-section of alignment strength and architectural defense. Model–framework axes are varied to differentiate the protective effect of alignment versus architectural isolation.
Execution Outcomes and Bypass Results
DDIPE achieves direct execution rates (DER) between 2.3% and 33.5%, depending on architecture/model pairing. Notably, explicit instruction baseline attacks are universally nullified (DER 0%) under strong defenses, reinforcing the stealth advantage of DDIPE. High DERs (e.g., 27.1% on OpenHands + GLM-4.7) are observed when frameworks rely solely on model alignment, indicating that architectural guardrails are critical compensators against weak alignment.
Under the most fortified regime (Claude Code + Sonnet 4.6), even with multi-layer checks, 2.3% of payloads are executed, with an overall bypass rate (including code generation) of 13.5%. Removing architectural guardrails amplifies execution (Sonnet 4.6, OpenHands: DER 10.7%), whereas strong alignment (Sonnet) constrains this effect far more than weaker models (GLM, MiniMax).
A single minimalistic pip.conf poisoning payload was universally executed by all tested models on Claude Code, underlining systemic blind spots when malicious intent is camouflaged as standard workspace configuration activity. DERs are higher for configuration-style attacks; verbose or overtly suspicious payloads are filtered more effectively.
Blind Spots, Diversity, and “Sleeper” Payloads
Models differ sharply in their vulnerability profiles, exhibiting only 62.1% verdict agreement for the same set of payloads under identical framework controls, and just 1.6% of payloads bypass all three Claude Code models. Weak alignment leads to hundreds of “sleeper” payloads (blocked by architecture, triggered when only model-level alignment is present), while strong alignment makes architecture nearly redundant.
Cross-category results underscore preferential exploitation of supply-chain poisoning, environment/credential theft, and configuration tampering—tying bypass frequency to workflows present in normal development operations.
Validation in Production and Response
Responsible disclosure yielded real-world confirmation: four distinct zero-days, two already fixed. Root-cause analysis identifies framework privilege grants based on syntactic context rather than semantic analysis, and shows that even sandboxed or isolated agents (e.g., bubblewrap environments) remain vulnerable to subtle config- or metadata-level poisoning.
Practical and Theoretical Implications
This work demonstrates that LLM-driven agent skill ecosystems are exposed to a novel, high-severity supply-chain vector, capable of action-space hijacking at scale. Architectural and alignment defenses provide non-additive, asymmetric protection: defense diversity and intent-level reasoning are required for robust hazard reduction. The evidence suggests:
- Multi-model/ensemble agent architectures drastically shrink the effective attack surface below any single-model's threshold, due to insufficiently overlapping bypass profiles.
- Static, rule-based audits intercept a large fraction of attacks (90.7%) but are evaded by benign-disguised, low-lexical-indicator payloads.
- Intent recognition and fine-grained, per-skill permissioning emerge as requisite next-generation defenses for open skill ecosystems.
Furthermore, the scalable attack generation pipeline exposes a future AI threat landscape where attackers can programmatically adapt and proliferate novel supply-chain attacks, outpacing manual curation or static review.
Conclusion
This research establishes that LLM coding agent skill ecosystems, as currently architected, are susceptible to document-driven, implicit supply-chain poisoning attacks even under state-of-the-art alignment and architectural defenses. The documented attacks traverse both cognitive (model output) and operational (system-level execution) domains, with empirical validation against real production frameworks and models. Effective mitigation necessitates a combination of heterogeneous model ensembles, semantic intent auditing, and per-skill execution scoping. The DDIPE paradigm and scalable adversarial skill generation pipeline highlighted in this study provide both a diagnostic and stress-testing methodology for evaluating agent supply-chain hardening strategies and underline the urgency of defense evolution as agent extensibility matures.