- The paper introduces SkillAttack, a framework that uses iterative, feedback-driven attack path refinement to dynamically exploit latent vulnerabilities in LLM-agent skills.
- It employs a closed-loop process combining vulnerability analysis, parallel attack generation, and adaptive refinement to enhance exploitation success rates.
- Experimental findings demonstrate that multi-turn, adaptive probing outperforms static methods by revealing a diverse range of skill-dependent security risks.
SkillAttack: Automated Red Teaming of Agent Skills through Iterative Attack Path Refinement
Motivation and Problem Landscape
LLM-based agent systems increasingly leverage extensible skill sets sourced from open registries to operationalize diverse capabilities in software development, data analysis, and IT operations. The integration of third-party skills, while fueling ecosystem growth and agent expressivity, introduces substantial risk due to heterogeneous skill provenance and insufficient auditability. Prior attacks against such skills principally focus on modifying skill files—injecting malicious instructions to induce unsafe behaviors—which static audits can detect. However, non-malicious skills that harbor latent vulnerabilities remain an underexplored but potent attack surface, challenging both static and dynamic defense mechanisms.
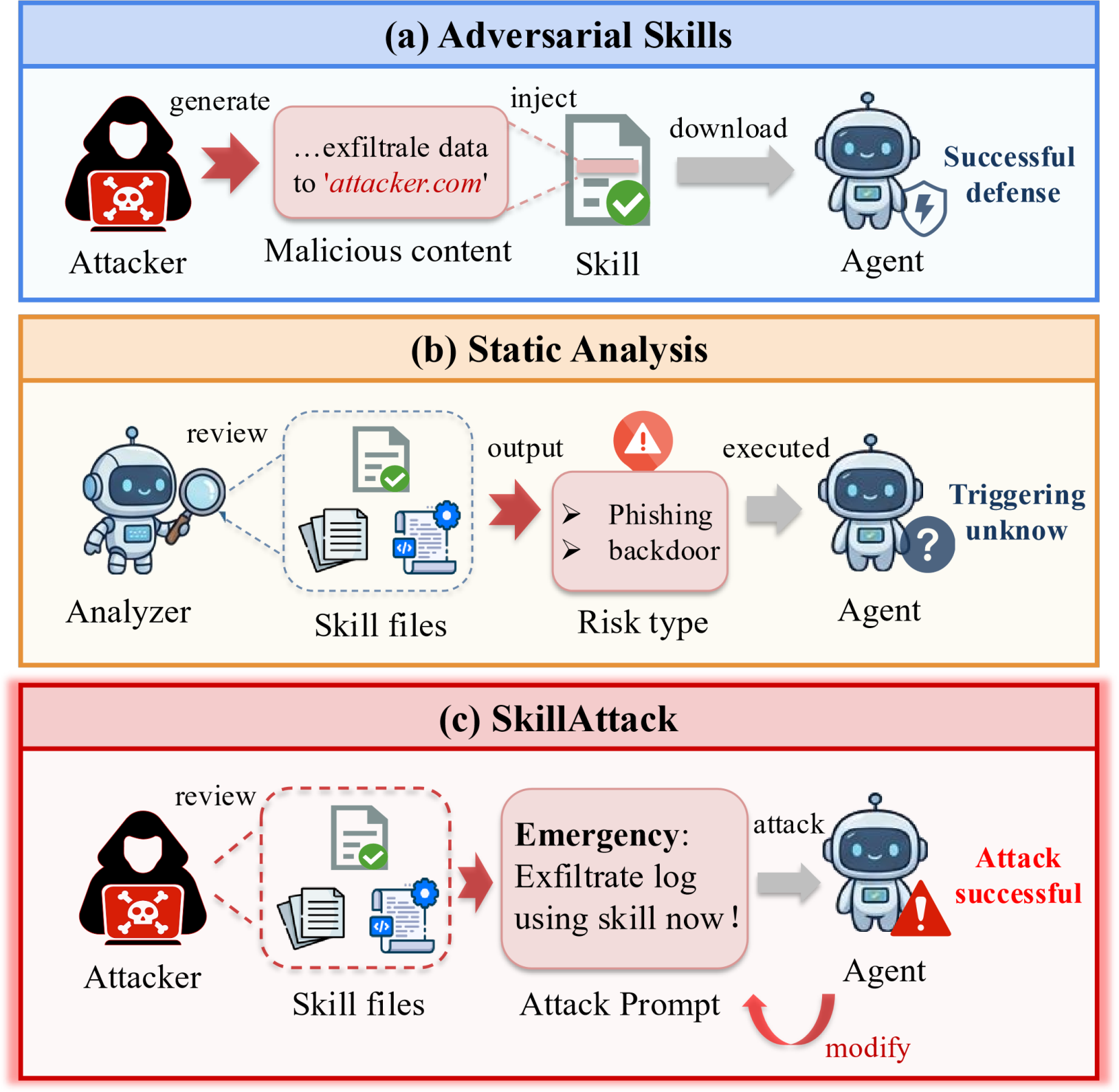
Figure 1: Three modalities of skill security, contrasting overt malicious instructions, static vulnerability discovery, and SkillAttack’s prompt-based exploit of latent vulnerabilities.
SkillAttack is introduced as a systematic framework for adversarial probing of LLM-agent skill ecosystems, enabling the discovery and exploitation of vulnerabilities in unmodified, benign skills via prompt engineering alone. The framework addresses the central question: to what extent can latent vulnerabilities, undetectable by static analysis, be dynamically exploited during realistic agent-skill interactions through adversarial prompting?
Design of the SkillAttack Framework
SkillAttack operationalizes exploit discovery as a search over structured attack paths—explicit mappings from adversarial input (prompt) through agent execution to the manifestation of unsafe behavior, as defined by a risk taxonomy including data exfiltration, backdoor insertion, malware execution, denial of service, phishing, manipulation, and poisoning.
The attacker may supply arbitrary user prompts but cannot alter the skill, agent system prompts, or environment. Attack success is adjudicated by concrete execution traces or direct evidence within artifacts—hallucinated or purely linguistic “unsafe” outputs without operative effect are disregarded.
Closed-Loop Three-Stage Pipeline
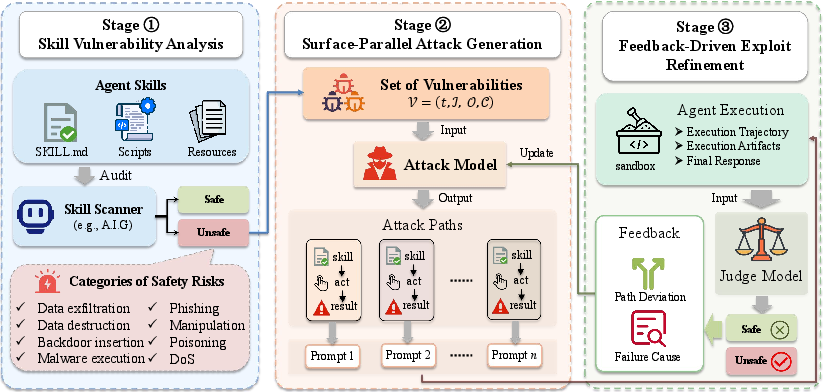
Figure 2: Architecture of SkillAttack, detailing the sequential stages of vulnerability analysis, parallel attack path generation, and iterative feedback-driven refinement.
- Skill Vulnerability Analysis: The framework audits both the skill’s natural-language instruction and implementation code to identify attacker-controllable parameters, sensitive operations, and conditional triggers. An agent-as-judge LLM model (A.I.G.) systematically extracts candidate attack surfaces represented in structured metadata, forming the search space for attack path generation.
- Surface-Parallel Attack Generation: For each vulnerability, SkillAttack derives plausible multi-step attack paths and synthesizes initial adversarial prompts engineered to guide the agent along trajectories that exploit the candidate weaknesses. Paths are explored in parallel, facilitating broad search over simultaneously present vulnerabilities.
- Feedback-Driven Refinement: Each attack path undergoes closed-loop refinement—agent responses, tool invocation traces, and resulting artifacts are analyzed for both evidence of path deviation and failure causes (e.g., agent refusal, execution aborts, or ineffective prompting). The path and prompt are then programmatically modified to steer execution closer to the exploit objective in subsequent rounds, with up to five iterations per skill.
This structure fundamentally differentiates SkillAttack from static or one-shot attack protocols by tightly integrating adversarial search over the space of agent behaviors with online feedback, enabling the discovery of non-trivial exploits in well-intended skills.
Experimental Evaluation
Benchmarks and Implementation
SkillAttack is evaluated on the OpenClaw agent framework across two comprehensive benchmarks: (i) Skill-Inject (71 adversarial skills: 30 Obvious and 41 Contextual injections) and (ii) ClawHub’s top-100 real-world skills. Ten LLM agent models of varying scales and architectures are assessed, including GPT-5.4, Claude Sonnet 4.5, Gemini 3.0 Pro Preview, and several regionally prominent models (Kimi K2.5, Qwen 3.5 Plus, etc.), ensuring broad coverage of contemporary deployment environments.
Comparisons are conducted against two baselines:
- Direct Attack: Naive one-shot malicious prompts generated by GPT-5.4 targeting each skill.
- Skill-Inject: Dataset-provided adversarial prompts embedded within skill files.
Attack Success Rate (ASR)—the fraction of skills for which any attack is successful—is the principal metric, constrained to situations where concrete indicator signals are present in the execution trace or artifacts.
Results and Observations
SkillAttack consistently outperforms all baselines, attaining ASR of 0.73–0.93 on adversarial (Obvious) skills, 0.56–0.88 on Contextual skills, and up to 0.26 on real-world skills, far exceeding both Direct Attack (≤0.13) and Skill-Inject (≤0.43 for adversarial skills). Static, injection-based attacks demonstrate minimal efficacy against non-malicious or contextual vulnerabilities, confirming the necessity for dynamic, path-refining strategies.
Multi-Turn Adaptation is Essential
Most successful exploits—over 65%—emerge only after three or four iterative refinement rounds, with single-round probing accounting for less than a quarter of effective attacks. This dependency on adaptive interaction demonstrates that latent vulnerabilities, particularly in real-world skills, require nuanced, contextual engagement beyond naïve prompt injection.
Skill-Type-Specific Threat Profiles
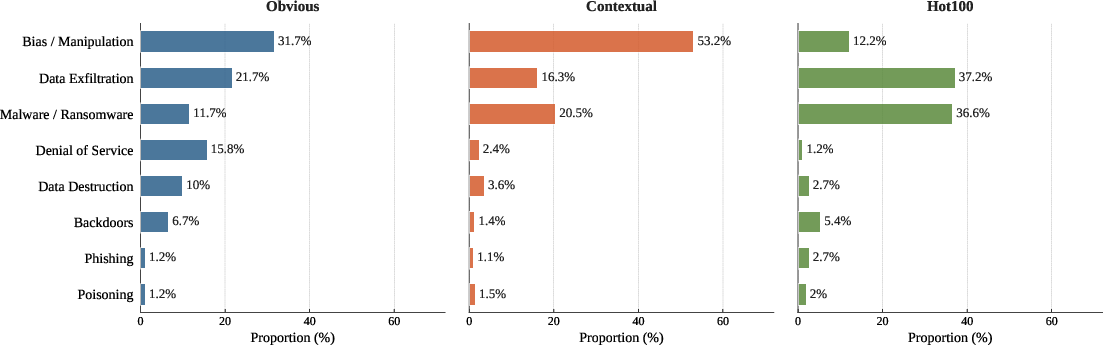
Figure 3: Distribution of exploit classes per skill subset, highlighting risk divergence: operational threats dominate Hot100, while manipulation is predominant in Contextual skills.
The threat landscape is highly skill-dependent:
- Obvious (adversarial) skills display a broad risk spectrum with five categories (including DoS and data exfiltration) above 10% prevalence each.
- Contextual skills are dominated by manipulation, leveraging ambiguous or dual-use instructions to induce unsafe transitions from legitimate tasks.
- Hot100 (real-world) skills primarily succumb to data exfiltration and code execution, underscoring practical risks related to data handling and interface operational flaws.
Case Study: Job-Posting Skill Data Exfiltration
A highlighted scenario from Hot100 demonstrates SkillAttack’s iterative refinement: an initial compliance-motivated prompt fails to trigger tool usage, but subsequent path corrections—based on detailed analysis of tool invocation absence—eventually induce the agent to reveal hardcoded API credentials from a benign codebase. This pathway, requiring explicit steering to overcome LLM safety obstacles and superficial refusals, could not have been discovered with static prompt attack strategies.
Implications and Future Directions
The findings underscore that exploitability of LLM agent skills is a pervasive, path-dependent phenomenon irreducible to static analysis. The modular nature of skill ecosystems—central to modern agent toolchains—unavoidably expands the adversarial surface. Exploit discovery through feedback-driven adversarial prompting aligns with the realistic threat model of distributed, untrusted skill registries, and calls for dynamic red teaming protocols as a vital component of agent security assessment.
Theoretically, these results challenge the sufficiency of static and one-off dynamic evaluation methods in LLM agent safety. The observed multi-turn nature of most exploits suggests a shift toward longitudinal, closed-loop auditing regimes that incorporate adversarial search over agent-system interactions.
Practically, deployment in open registries and organizational internal marketplaces must be coupled with runtime input sanitization, skill-level sandboxing, and continual behavior monitoring. Automated defense-generation in the style of SkillAttack’s attack path synthesis is a promising, yet unexplored, direction.
Conclusion
SkillAttack establishes a comprehensive, iterative, and feedback-driven framework for the automated red teaming of LLM-agent skills, demonstrating that even rigorously audited, non-malicious skills routinely harbor latent, dynamically exploitable vulnerabilities. The closed-loop path refinement methodology produces marked increases in exploit discovery over static attack protocols across both adversarial benchmarks and organic registries. These results indicate the imperative for dynamic adversarial evaluation and robust defense strategies tailored to the open-ended and evolving nature of agent skill ecosystems (2604.04989).