- The paper introduces SkillSieve, a hierarchical triage framework that integrates static pre-filtering, structured semantic decomposition, and a multi-LLM jury to detect malicious AI agent skills.
- It leverages regex, AST feature extraction, and parallel LLM sub-tasks to achieve higher precision (0.752) and recall (0.854) compared to traditional methods.
- The framework is operationally scalable with low scanning costs and robust defense against evasive tactics like prompt injection, cross-file logic splitting, and obfuscation.
SkillSieve: Hierarchical Triage for Malicious AI Agent Skill Detection
Motivation and Context
OpenClaw’s ClawHub marketplace presents a significant supply chain security risk by hosting over 13,000 community-contributed agent skills, with between 13% and 26% containing security vulnerabilities as shown by recent audits. Existing detection approaches—regex-based scanners (ClawVet), formal static analyzers (SkillFortify), and LLM-based tools (VirusTotal Code Insight, SkillScan)—are each limited: regex fails on obfuscated or cross-file payloads, formal static analysis cannot cover natural language instruction files (SKILL.md), and single-model LLM prompts lack robustness and reproducibility. The two-modality nature of skills (executable code and agent instructions in natural language) exacerbates this, introducing prompt injection, social engineering, and multi-layered code attacks.
SkillSieve addresses this with a progressive three-layer detection pipeline designed for cost efficiency, high recall, and explainability, leveraging traditional static features along with structured LLM analysis and multi-model jury protocols.
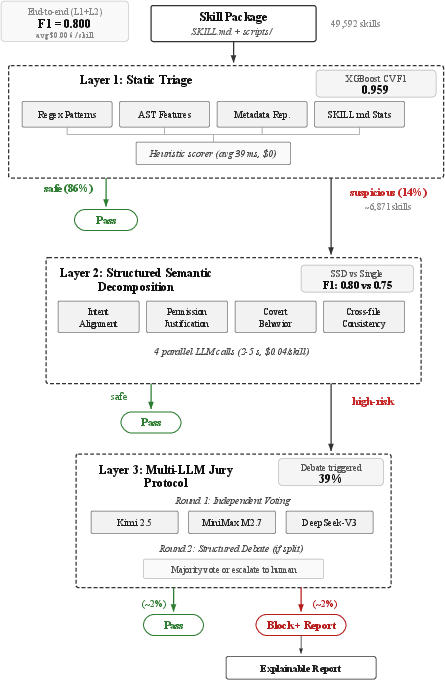
Figure 1: SkillSieve’s triage architecture filters ∼86% of benign skills statically, applies four parallel LLM sub-tasks for suspicious candidates, and convenes a multi-LLM jury for high-risk cases.
Threat Model and Attack Surface
Attackers exploit the lack of mandatory skill review to launch supply chain attacks—credential theft, remote code execution, data exfiltration, prompt injection, and social engineering—often employing evasion techniques such as encoding, cross-file logic splitting, conditional triggers, homoglyphs, and delayed payloads. Defenders need to statically and semantically analyze skill packages without executing code, balancing recall, precision, and scanning costs.
SkillSieve confines its detection to static and semantic analysis, targeting skills adhering to the ClawHub format and eschewing runtime inspection.
SkillSieve Architecture
Layer 1: Static Triage
The first layer aggregates four modules: regex pattern matching, AST feature extraction (via tree-sitter), metadata reputation (e.g., edit distance for typosquatting, sensitive env request, binary dependencies), and SKILL.md surface statistics (instruction length, URLs, permission requests, urgency language, etc.). Feature vectors (15 selected from 31 candidates) are scored by a weighted heuristic; XGBoost trained models show promising F1 but are ultimately limited by dataset heterogeneity. With a threshold r<0.3, 86% of skills are resolved as benign in under 40ms per skill, at zero API cost, maximizing cost efficiency and pre-filtering for subsequent layers.
Layer 2: Structured Semantic Decomposition (SSD)
Layer 2 decomposes LLM-based security analysis into four parallel sub-tasks:
- Intent Alignment: Validates consistency between skill name, description, and actual agent instructions to detect disguised attacks.
- Permission Justification: Assesses if requested permissions (env, binaries, network) are justified for the claimed function, identifying over-privilege.
- Covert Behavior Detection: Flags attempts to hide actions, suppress errors, or bypass safeguards, surfacing social engineering.
- Cross-File Consistency: Ensures scripts implement SKILL.md as claimed; detects undeclared behaviors and logic splitting.
Each sub-task uses domain-specific prompts with strict JSON schemas, executes concurrently (latency ∼2–5s), and outputs individual risk scores, aggregated with task-weighted importance (highest weight on intent alignment). Skills scoring R2≥0.4 are escalated.
Layer 3: Multi-LLM Jury Protocol
Critical cases face a jury of three independent LLMs (Kimi 2.5, MiniMax M2.7, DeepSeek-V3), each voting via structured JSON verdicts. Disagreements trigger a debate round: jurors review each other's reasoning and may revise verdicts; majority determines outcome, with ambiguous cases escalated to human review. This protocol quantifies uncertainty and systematically handles model bias.
Empirical Evaluation
Dataset Construction
SkillSieve is validated on a 49,592-skill ClawHub archive (snapshot 2026-04-04), malicious sample datasets (Snyk ToxicSkills, ClawHavoc campaign), and a 400-skill human-labeled benchmark (89 malicious, 311 benign), covering seven attack archetypes and five adversarial evasion techniques.
SkillSieve demonstrates robust performance:
- Layer 1 only: Recall 0.989, Precision 0.583, F1 0.733 (flags suspicious skills for Layer 2).
- L1 + Single LLM prompt: Precision 1.000, Recall 0.596, F1 0.746 (misses covert attacks).
- L1 + SSD (SkillSieve): Precision 0.752, Recall 0.854, F1 0.800, Accuracy 0.905, False Positive Rate 0.08.
SkillSieve substantially outperforms ClawVet (F1 0.421) and single-prompt LLM baselines, particularly on attacks using complex camouflage. SSD detects 23 more threats by independently tracking security dimensions.
Adversarial Robustness
All five tested bypass techniques (obfuscation, cross-file logic, conditional triggers, homoglyph substitution, time-delay) are intercepted when paired with malicious payloads. Layer 1 detects strong signature cases; Layer 2 resolves weaker signals; compound attacks (e.g., typosquatting + credential theft) activate multiple static and semantic flags.
Cost and Edge Deployment
SkillSieve’s triage enables scalable deployment: on a $440 ARM board (Orange Pi AIpro, 4-core ARM64, 24GB RAM), Layer 1 processes 49,592 skills in 31 minutes (38.8ms avg/skill), flagging only 13.86% for LLM analysis. The average scan cost is$0.006/skill—compared to ∼ $0.01/skill using a naive single-LLM pipeline—making SkillSieve practical for CI/CD pipelines, self-hosted edge deployment, and air-gapped environments.
Jury Dynamics
Layer 3 jury protocol yields consensus in the majority of borderline cases, with structured debate resolving dissent in two-thirds of activated sessions. Contested ambiguous skills are rare and correlate with genuine uncertainty observed in human reviewers.
Practical and Theoretical Implications
SkillSieve validates the hierarchical triage paradigm for agent supply chain security, combining static pre-filtering with structured semantic decomposition and multi-model voting. The framework enables efficient scaling to tens of thousands of skills, mitigates single-model bias, and produces explainable evidence chains. Its edge compatibility and low marginal scan cost facilitate universal adoption in resource-constrained and privacy-sensitive settings.
SkillSieve’s decomposed LLM prompts significantly enhance attack coverage compared to monolithic analysis, especially for prompt injection, covert behavior, and logic-splitting techniques. Multi-LLM jury protocols set a precedent for cross-model validation in AI security auditing.
Real-world attacks continue to evolve: logic splitting, time-delayed payloads, and typosquatting demand adaptive static rules and semantic task design. While SkillSieve’s static and semantic analysis suffices for most attacks, runtime behavioral monitoring and customized small-model fine-tuning for Layer 2 could further enhance detection and remove API dependencies.
Conclusion
SkillSieve’s layered approach effectively detects malicious agent skills by combining efficient static analysis, structured semantic decomposition, and multi-LLM jury verdicts. The framework achieves strong detection metrics on a large real-world benchmark, intercepts all tested adversarial techniques, and is operationally scalable to edge environments. Its methodological innovations—SSD and multi-LLM debate—improve robustness, explainability, and practical deployment for AI supply chain security. Future directions involve runtime monitoring and adaptation for new agent ecosystems.