- The paper introduces MV-VDP, a novel 3D-aware video diffusion model that explicitly models spatio-temporal evolution through multi-view projections.
- The methodology employs a multi-view diffusion transformer that jointly encodes RGB images and heatmaps, enabling precise 3D action decoding and interpretable control.
- Empirical results show that MV-VDP achieves high success rates in both simulated and real-world manipulation tasks with minimal data, outperforming traditional approaches.
Multi-View Video Diffusion Policy: 3D Spatio-Temporal Action Modeling for Data-Efficient and Robust Manipulation
Introduction
The paper "Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model" (2604.03181) proposes MV-VDP, a new robot manipulation architecture that aligns video pretraining and visuomotor action finetuning by explicitly modeling the 3D spatio-temporal evolution of the environment. In contrast to existing VLA models and video-prediction policies—which typically operate on 2D visual information and backbones pretrained on static image-text data—MV-VDP employs 3D-aware multi-view projections and leverages a large-scale video foundation model to enable data-efficient, robust, and interpretable visuomotor control from minimal demonstrations.
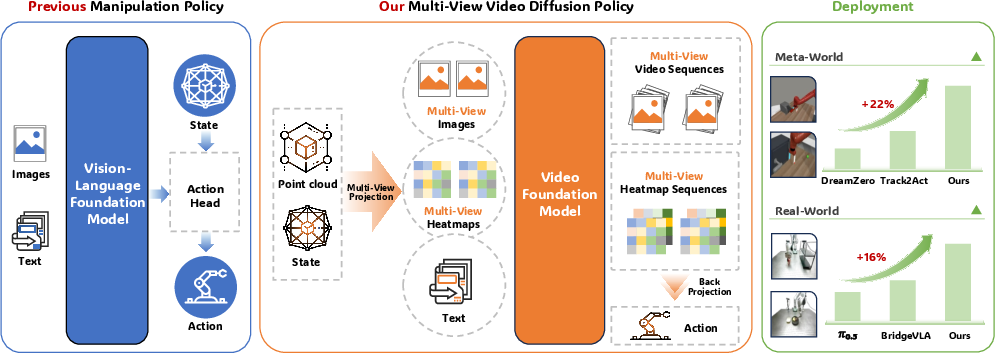
Figure 1: MV-VDP overview. The model reasons over multi-view images, predicts future videos and heatmaps, and establishes state-of-the-art performance on both simulated and real-world manipulation benchmarks.
Methodology
Multi-View Projection and 3D-Aware State Encoding
The model first transforms colored point clouds and the end-effector pose into three orthographic multi-view RGB images. The end-effector pose is projected into heatmaps for each view, Gaussian-smoothed and spatially truncated, which serve as a spatially aligned, low-bias representation. This projection mitigates the observation-action representation gap inherent in standard 2D approaches, providing geometric information that aligns with the 3D action space while remaining compatible with pretrained video model encoders.
The core policy utilizes a multi-view video diffusion transformer based on Wan2.2 (5B parameters). The architecture augments the original single-view video backbone with view-attention modules for explicit spatio-temporal and cross-view correlation. Inputs—current context RGB and heatmap images—are encoded together, producing latent representations concatenated along the view axis. During training, future sequences (both RGB and heatmap) are corrupted with Gaussian noise per a standard diffusion process; the model is trained to denoise via an MSE objective, balancing the RGB and heatmap channels with a tunable weight.
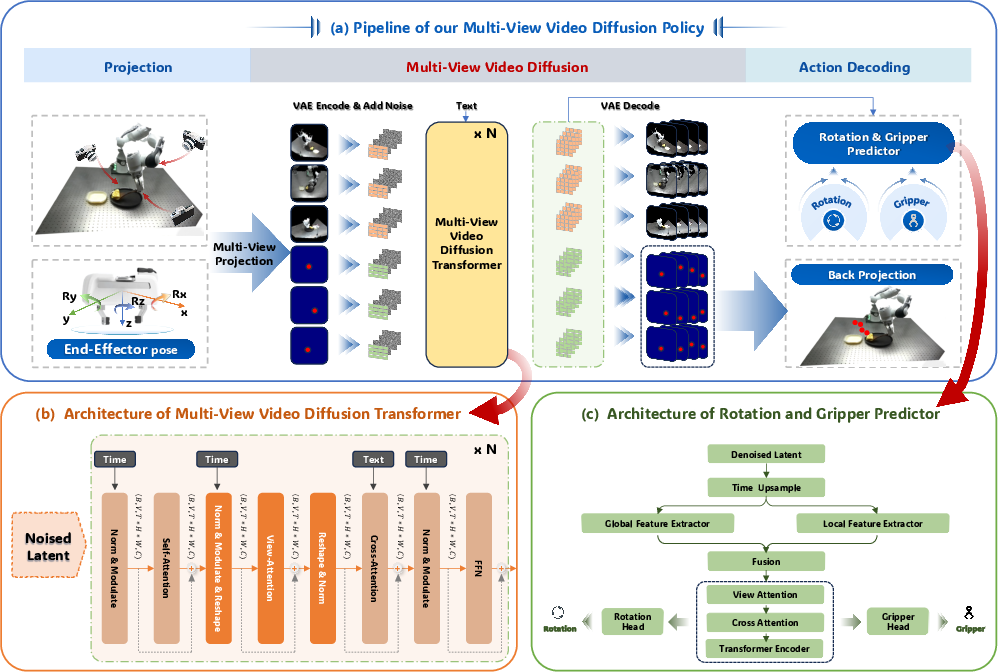
Figure 2: MV-VDP pipeline: multi-view projection and heatmap encoding, joint diffusion modeling, action decoding.
Action Decoding
Actions are produced in two steps: 3D positions are recovered by backprojecting the peak locations in each predicted heatmap sequence using camera parameters; rotations and gripper states are decoded from the denoised latent video representation via shallow convolutional and transformer heads. This yields a continuous action chunk (positions, Euler rotations, gripper status) aligned with the predicted environmental evolution.
Training and Inference Protocol
The pipeline is trained with LoRA for the diffusion transformer for scalability, and standard AdamW optimization for all modules. Training requires only ten demonstration trajectories per task (often <100 total), without auxiliary robotic pretraining. Inference involves projecting new observations, encoding into the VAE latent space, and running the diffusion denoising loop (as few as 1–5 steps) to predict an action chunk executable by a low-level controller.
Empirical Results
MV-VDP achieves an 89.1% average success rate across seven diverse Meta-World tasks with just five demonstrations per task, decisively outperforming strong baselines—BC-Scratch, BC-R3M, DP, video-prediction models (AVDC, UniPi, DreamZero), and keypoint-based approaches (Track2Act). Notably, models lacking multi-view and 3D information exhibit strong overfitting and catastrophic generalization failures under data-constrained regimes.
Real-World Manipulation
In physical deployments (Franka Research 3, three ZED2i cameras), MV-VDP demonstrates high success rates (up to 100% for simple pick-and-place, strong scores for complex push and scoop tasks), robust generalization to out-of-distribution backgrounds, object heights, categories, and lighting. Competing policies based on point-cloud 3D models, single-view video prediction, and VLA models pretrained on static images all fail to learn or generalize from limited data. BridgeVLA—another multi-view architecture—performs competitively but cannot predict intermediate action sequences, operating only in keyframe space and requiring hand-designed motion planning for traversals. MV-VDP's video-based generative planning enables continuous, precise control.
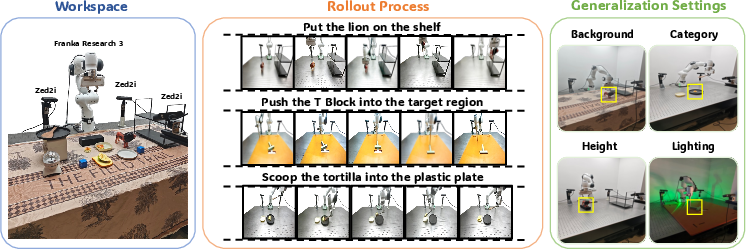
Figure 3: Real-world tasks and experimental setup: three multi-view ZED2i input streams and a range of manipulation challenges assessed for MV-VDP's robustness and generalization.
Model Robustness and Ablations
MV-VDP demonstrates high robustness with respect to key hyperparameters such as the video/heatmap diffusion loss weight, spatial heatmap spread, and number of inference denoising steps. Success rates remain in the 86–92% range under large hyperparameter variation. Remarkably, the model can operate with a single denoising step during inference while preserving high success and stability, distinguishing it from other diffusion architectures that typically require 30–50 steps. The explainability provided by joint RGB/heatmap sequence prediction further enables pre-execution action validation, substantially mitigating unsafe or destructive actions.
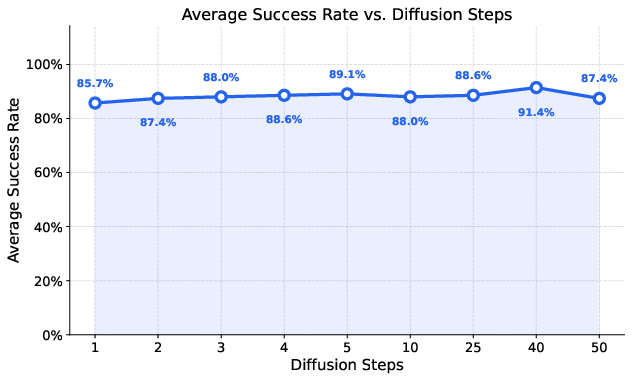
Figure 4: MV-VDP achieves strong success rates even at a single denoising step, enabling substantial inference acceleration with minimal performance loss.
Ablation trials validate the necessity of: joint video and action prediction, multi-view spatial encoding (vs. channel concatenation), retention of large-scale video-pretrained weights, and LoRA-based training for efficient adaptation.
Qualitative Analysis
Predicted RGB and heatmap sequences for a variety of tasks (Button-Press-Top, Door-Open, Push-T, Scoop Tortilla, Put Lion) are highly temporally consistent and visually realistic. The predicted heatmap peaks closely trail physical end-effector motion in the ground truth, supporting faithful, interpretable action anticipation.

Figure 5: Button-Press-Top task predictions: predicted future RGB and heatmap sequences are realistic and their peaks reliably follow the ground truth end-effector trajectory.

Figure 6: Door-Open task predictions: MV-VDP maintains strong alignment between generated and ground-truth RGB and heatmap series.

Figure 7: Push-T task: the model's predicted environmental evolution is coherent and correctly captures the manipulation process.

Figure 8: Scoop Tortilla, illustrating ability to model complex deformation and multi-object conditional outcomes.

Figure 9: Put Lion, further validating temporal and geometric consistency across both static and highly dynamic tasks.
Theoretical and Practical Implications
MV-VDP constitutes a significant empirical and methodological advance in robotic policy learning. By creating a unified representation format for pretraining and finetuning, and leveraging explicit 3D-aware, temporally consistent prediction, it bridges the perceptual and action planning gap encountered by VLA and prior video-prediction policies. This unification drastically improves learning efficiency (order-of-magnitude lower demonstration requirements), enables interpretable deployment (by predicting future environmental evolution), and supports robust generalization to previously unseen configurations and objects—a core requirement for generalist embodied intelligence.
From a theoretical standpoint, results affirm that multi-view spatial representations embedded into end-to-end generative video-action architectures, jointly trained with a denoising diffusion framework, offer superior inductive bias for manipulation tasks that require reasoning about 3D geometry and non-stationary dynamics.
Practically, applications span scalable few-shot adaptation of dexterous manipulation policies, real-world robot deployment with human-in-the-loop safety validation, and accelerated learning protocols where demonstration data is extremely scarce or expensive. By achieving high success rates with minimal data and hardware cost, MV-VDP reduces barriers for deployment in industrial, service, or domestic robotics.
Future Directions
Key limitations remain. Inference speed, while improved by the model's denoising efficiency, still lags behind real-time requirements for fast, highly dexterous control. Integration of accelerated diffusion techniques (e.g., TurboDiffusion [zhang2025turbodiffusion]) and real-time action chunking is an obvious next step. Further, scaling the backbone video model with larger, more diverse spatio-temporal data—and extending multi-view prediction to variable camera topologies and occlusion scenarios—offers a pathway toward general robotic foundation models capable of universal manipulation with minimal supervision.
Conclusion
MV-VDP introduces a general, robust, and data-efficient framework for 3D-aware spatio-temporal action generation in robot manipulation, decisively outperforming prior behavioral cloning, video-prediction, and VLA policies under practical demonstration constraints. Through explicit multi-view encoding, unified video and action prediction, and foundation model leveraging, MV-VDP closes the gap between perception and control, yielding manipulators that are robust, interpretable, and capable of rapid adaptation.
(2604.03181)