- The paper introduces LT-MIA, a learned attack that reframes membership inference as a supervised sequence classification task using distributional feature sequences.
- It demonstrates impressive architecture and domain transferability with AUCs up to 0.972 and significantly improved recall in low false-positive regimes.
- The work highlights that the memorization signature is an architecture-agnostic byproduct of gradient descent and cross-entropy fine-tuning, raising key privacy concerns.
Learning the Signature of Memorization in Autoregressive LLMs
Introduction
"Learning the Signature of Memorization in Autoregressive LLMs" (2604.03199) addresses the fundamental and technically unresolved issue of membership inference in LLMs. The work introduces a learned attack, LT-MIA, that generalizes MIA across diverse neural architectures, leveraging the observation that fine-tuning via gradient descent and cross-entropy inherently imprints an architecture-agnostic “memorization signature.” Unlike earlier heuristic approaches bounded by statistic design and often limited in transferability, LT-MIA reframes membership inference as a supervised sequence classification task over distributional features extracted from both a fine-tuned and its corresponding pre-trained reference model, achieving zero-shot generalization to new architectures and data domains.
Methodological Framework
LT-MIA replaces heuristic membership statistics with data-driven learning, exploiting the key property that known membership labels can be generated ad infinitum by synthetic fine-tuning runs. Under a black-box threat model, the adversary has query access to both a fine-tuned model and its reference checkpoint sharing identical architecture but requires no white-box access, dataset knowledge, or expensive shadow models. This shift enables the standard deep learning advantages: scalable training by accumulating feature-labeled data from model–dataset combinations, and generalization forced through diversity.
Feature extraction forms the core of LT-MIA. For an input sequence x, 154 per-token features are computed, including per-token losses from the target/reference models, difference statistics, rank and logit features for ground-truth and top/bottom tokens, and cross-distribution rank comparisons, all normalized for scale invariance. These features are encoded as a sequence (not mean pooled), preserving the positional structure that can be exploited by a 2-layer transformer classifier, which adaptively weights the tokens most informative for membership detection.
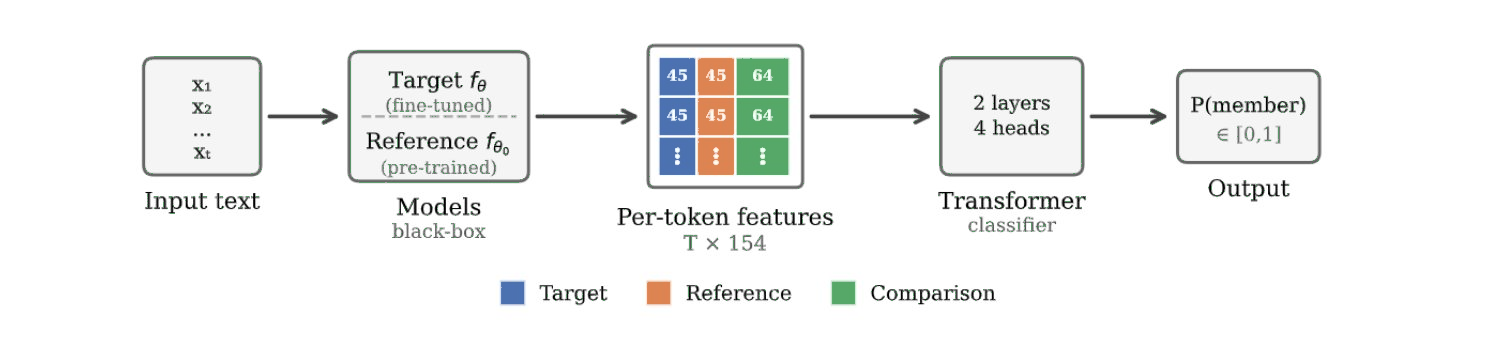
Figure 1: The LT-MIA pipeline extracts distributional feature sequences contrasting fine-tuned and pre-trained models and applies a lightweight transformer as membership predictor.
This reframing brings MIA into the regime of deep learning, with features, classifier capacity, and diversity all scalable for further performance improvements.
Evaluation and Key Results
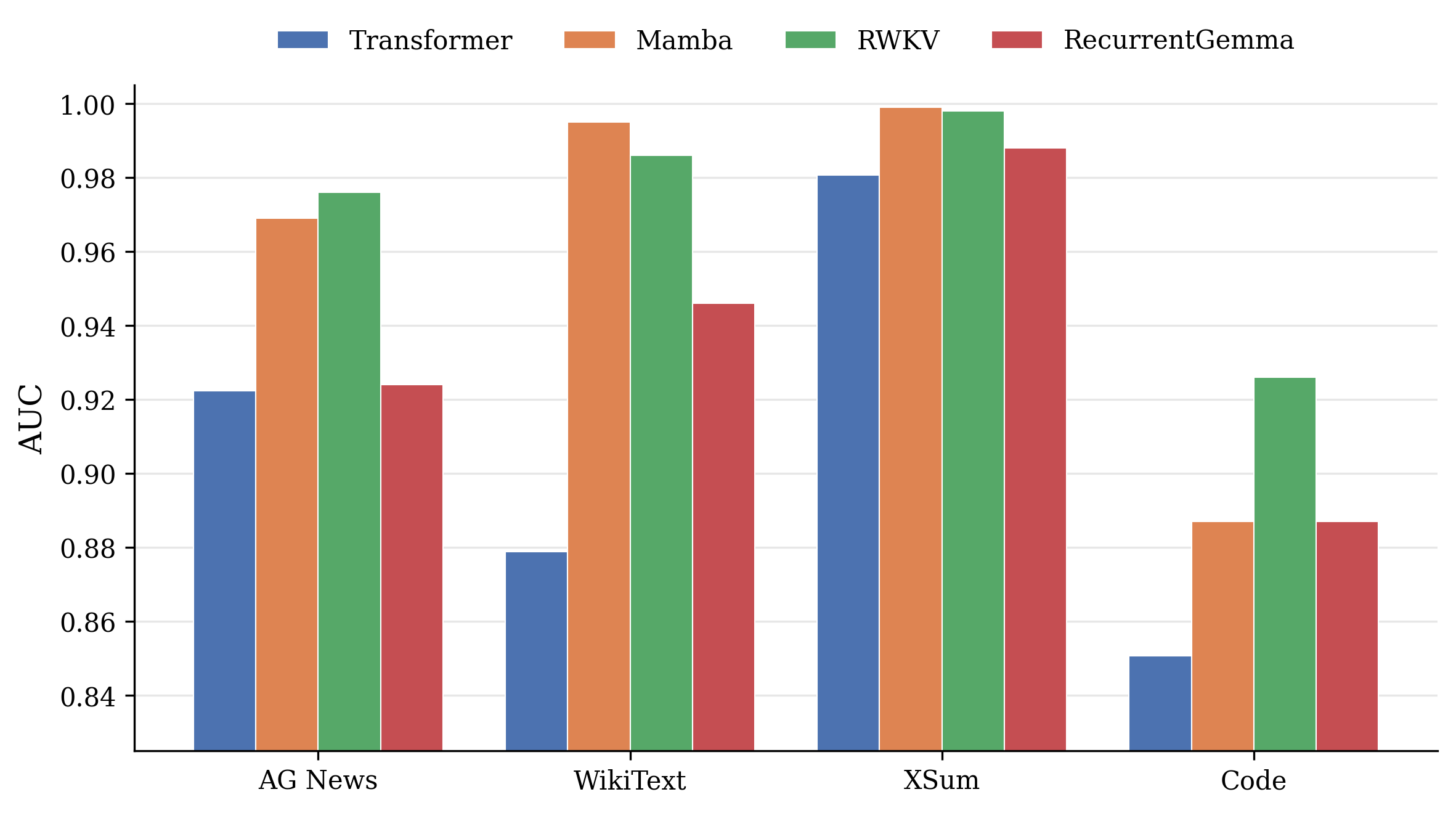
Evaluation comprises extensive held-out transfer: LT-MIA is trained solely on transformer models and evaluated on never-seen transformer combinations as well as non-transformer architectures including Mamba (selective state-space), RWKV (linear attention), and RecurrentGemma (gated recurrence), excluding all overlap between training and test splits at the model, family, and data levels.
LT-MIA achieves the following salient results:
Likewise, all likelihood-based statistics (Loss, RefLoss, EZ-MIA) transfer across architectures—the signal is not specific to any detection method, but LT-MIA captures it most effectively.
Analysis: Invariances and Enablers
Ablation studies identify why LT-MIA achieves cross-architecture transfer. Feature importance analysis demonstrates that the dominant membership signal is relational—comparison features contrasting target and reference model predictions—rather than absolute model outputs. This results in invariant importance hierarchies across transformer, state-space, linear attention, and gated recurrent families.
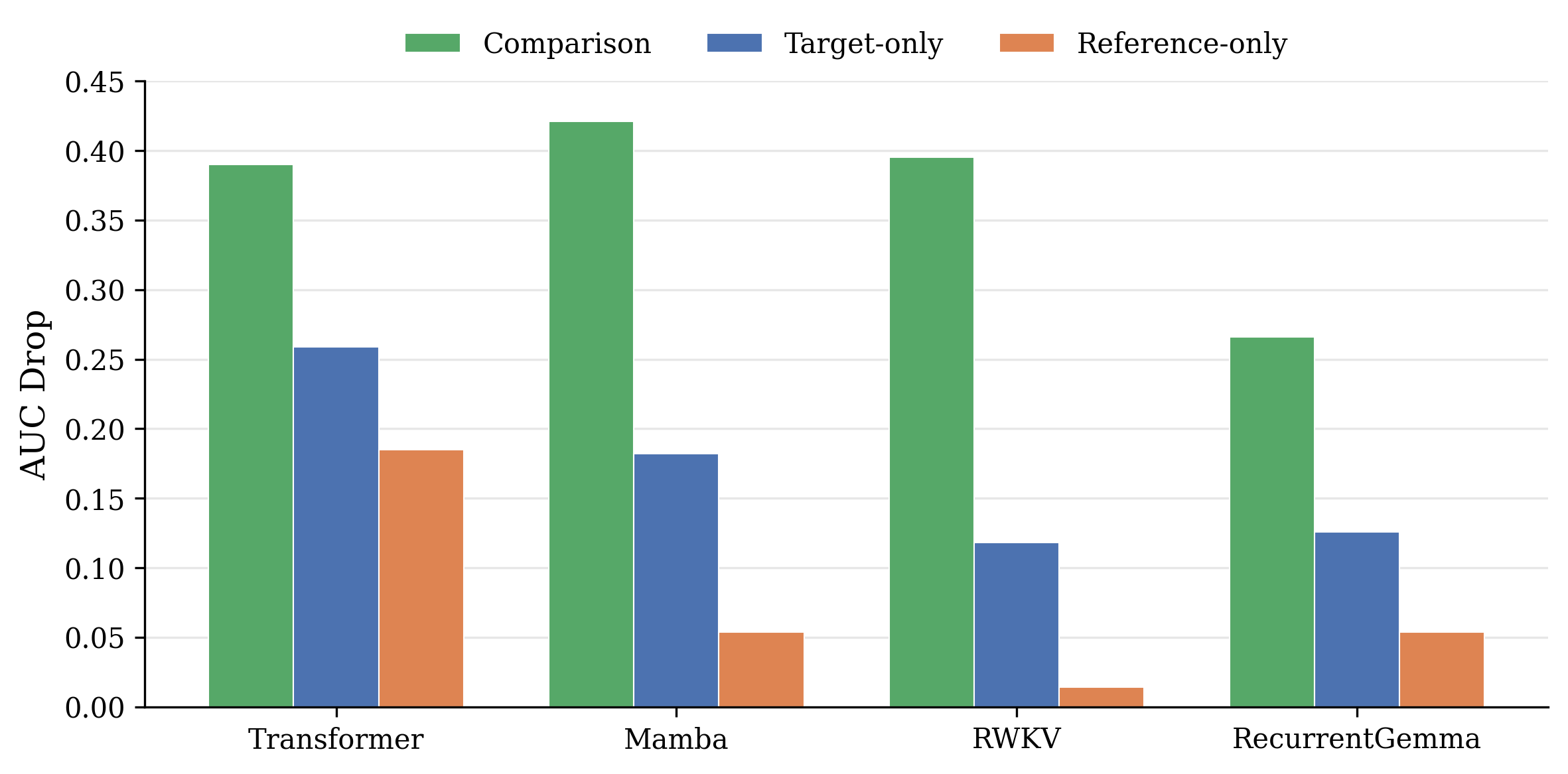
Figure 3: Ablation-based feature importance illustrates the primacy of comparison features for all model families, underscoring the universality of the relational signal.
Training diversity analysis reveals that increasing the number of model–dataset combinations (while keeping total data fixed) closes the generalization gap: artifacts specific to individual models (e.g., tokenizer quirks, logit scale) are filtered, yielding a classifier sensitive only to the architecture-agnostic memorization shift.
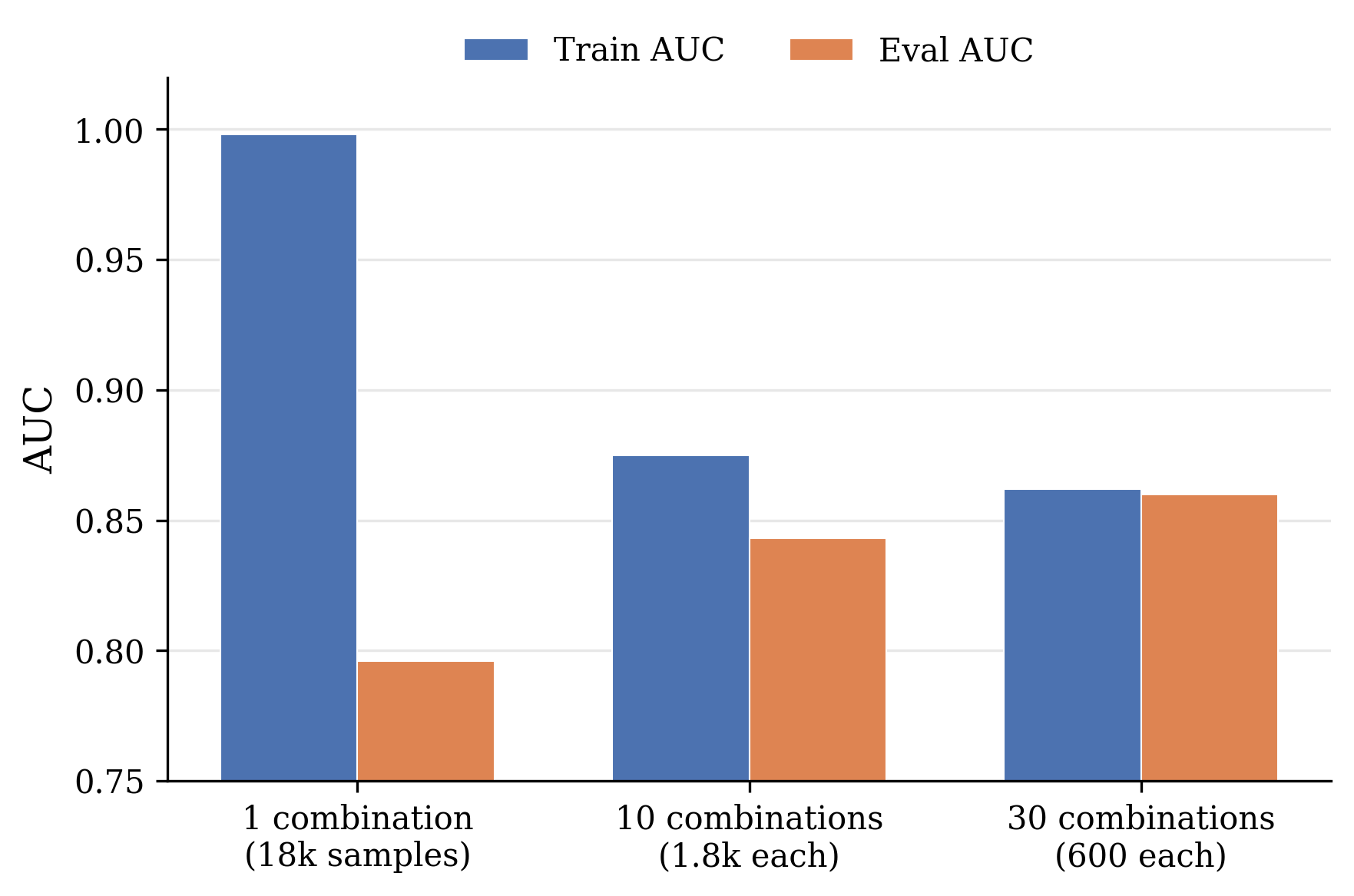
Figure 4: Effect of diversity on generalization—scaling combinations, not just data size, diminishes train–eval gap.
Sequence modeling outperforms aggregation; encoding positional dependence grants a 5 AUC point improvement versus mean pooling or flat MLPs.
Implications and Future Directions
Several implications arise from these findings:
- Memorization as a universal phenomenon: The persistence of the membership signal across architecture families, matched with the failure of architectural migration (e.g., to SSMs or linear-RNN hybrids) to mitigate attack success, implicates cross-entropy/minimization via gradient descent as the fundamental cause. The leakage is output-distributional, independent of underlying computation.
- Scalability of learned attacks: With classifier capacity, training diversity, and feature expressiveness all open to scaling, the ceiling for learned MIA performance is an open question. Scaling laws governing attack generalization across families and domains remain to be elucidated.
- Defensive considerations: Differential privacy is the only known defense offering theoretical guarantees, but requires noise magnitudes that destroy utility for LLMs. Architectural defenses are contraindicated by architecture-invariant attack success; any practical defense would need to fundamentally alter the training (e.g., by undermining the output shift that results from memorization).
- Beyond supervised fine-tuning: The extent to which RLHF, DPO, or large-scale pretraining (which imprints weaker per-example shifts) manifest the same signature remains an open research direction. Non-cross-entropy training paradigms may offer partial mitigation, but this hypothesis remains to be tested empirically.
Limitations
- Reference required: The attack presumes access to both fine-tuned and matching pre-trained checkpoints, which is generally feasible for open-weight models, not closed APIs.
- Pretraining data detection: Performance degrades when reference already encodes high likelihood for target text, limiting applicability to strong memorization settings (fine-tuning or rare pretraining data).
- Unexplored regimes: Application to reinforcement learning, instruction tuning, and other optimization regimes has not been empirically validated.
Conclusion
This work rigorously characterizes the architecture-invariant signature of memorization induced by autoregressive LLM fine-tuning. LT-MIA manifests a transferable learned MIA that sets new state-of-the-art in both architecture and domain transfer, decisively moving membership inference into the deep learning paradigm. The findings stress that privacy risks from memorization are an intrinsic product of the loss function and optimization, not architectural choice. This mandates a recalibration of defense focus toward training objective adjustments and motivates future research into the limits of learned privacy attacks and their mitigations under diverse optimization schemes.