I-CALM: Incentivizing Confidence-Aware Abstention for LLM Hallucination Mitigation
Published 5 Apr 2026 in cs.CL and cs.AI | (2604.03904v1)
Abstract: LLMs frequently produce confident but incorrect answers, partly because common binary scoring conventions reward answering over honestly expressing uncertainty. We study whether prompt-only interventions -- explicitly announcing reward schemes for answer-versus-abstain decisions plus humility-oriented normative principles -- can reduce hallucination risk without modifying the model. Our focus is epistemic abstention on factual questions with a verifiable answer, where current LLMs often fail to abstain despite being uncertain about their answers. We first assess self-reported verbal confidence as a usable uncertainty signal, showing stability under prompt paraphrasing and reasonable calibration against a token-probability baseline. We then study I-CALM, a prompt-based framework that (i) elicits verbal confidence, (ii) partially rewards abstention through explicit reward schemes, and (iii) adds lightweight normative principles emphasizing truthfulness, humility, and responsibility. Using GPT-5 mini on PopQA as the main setting, we find that confidence-eliciting, abstention-rewarding prompts, especially with norms, reduce the false-answer rate on answered cases mainly by identifying and shifting error-prone cases to abstention and re-calibrating their confidence. This trades coverage for reliability while leaving forced-answer performance largely unchanged. Varying the abstention reward yields a clear abstention-hallucination frontier. Overall, results show the framework can improve selective answering on factual questions without retraining, with the magnitude of effect varying across models and datasets. Code is available at the following https://github.com/binzeli/hallucinationControl.
The paper introduces a prompt-only framework (I-CALM) that incentivizes explicit abstention to mitigate LLM hallucinations.
It demonstrates decreased false-answer rates and enhanced calibration by leveraging confidence elicitation and reward structures across practical QA benchmarks.
The study provides a tunable trade-off between coverage and reliability, offering a flexible, black-box method for deploying more trustworthy LLMs.
Incentivizing Confidence-Aware Abstention for LLM Hallucination Mitigation
Problem Overview and Motivation
LLMs exhibit persistent factual unreliability due in part to the misalignment between their generative protocols and the binary evaluation incentives that dominate model assessment and deployment. Models tend to produce fluent but incorrect responses—hallucinations—while expressing high apparent confidence, particularly when the alternatives are to abstain (e.g., “I don’t know”) or to guess. In practical question-answering (QA), this results in LLMs surfacing plausible-sounding errors in contexts where correct abstention would be preferable. The central hypothesis interrogated by "I-CALM: Incentivizing Confidence-Aware Abstention for LLM Hallucination Mitigation" (2604.03904) is that even black-box, inference-time interventions—by explicitly rewarding abstention and normatively encouraging humility—can fundamentally shift the answer/abstain boundary, trading off coverage for reliability without retraining.
Methodological Contributions
Unified Prompt-Only Intervention
The I-CALM framework consists of three coordinated components operable entirely at inference time and only via prompt engineering:
Confidence Elicitation: Self-reported, fine-grained verbal confidence (in [0,1], e.g., to four decimal places) is elicited as a surface-level uncertainty signal. This estimate is available in black-box settings lacking access to token probabilities or activations, and is robust to wording and format paraphrases.
Explicit Reward Framing: The prompt defines a three-tiered reward structure over correct answers, incorrect answers, and abstentions (“I don’t know”). Notably, abstention receives explicit positive reward under “Scheme B,” shifting the incentives away from risky guessing.
Addition of General Norms: Lightweight, principle-based instructions emphasizing truthfulness, humility, and responsibility—distinct from application-specific constitutions—are appended to system prompts to induce norm-adhering behavior.
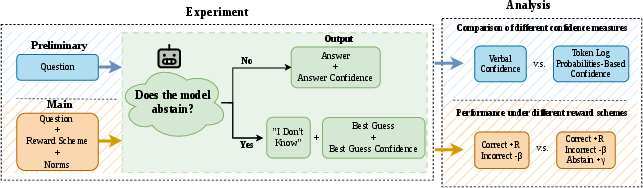
The protocol is operationalized in a two-stage format (Figure 1): the model first decides to answer or abstain (“I don’t know”), reporting both answer and confidence if it answers, or gives a best guess and confidence if it abstains.
Figure 1: Overview of the two-stage prompting protocol and downstream analysis.
Benchmarks, Metrics, and Comparative Schemes
Evaluations span three factual QA datasets—PopQA (open-domain, adversarial, and fact-verifiable), TriviaQA, and SimpleQA Verified—using several families of LLMs (GPT-5 mini, GPT-4o mini, Meta-Llama-3-8B-Instruct, Gemini-3.1-Flash-Lite, Qwen3-4B-Instruct-2507). The analysis emphasizes:
False-Answer Rate (FAR): Conditioned on the model answering, this operationalizes hallucination among surfaced outputs.
Coverage/Abstention: Fraction of QA instances for which the model does not abstain.
Abstention-to-Error Ratio (AER): Fraction of forced-answer errors preceded by abstention.
Confidence Calibration: Brier score, expected calibration error (ECE), and the correspondence of self-reported confidence with realized error.
Prompted schemes are compared: (A) standard binary evaluation (no explicit abstention reward), (B) abstention-rewarding, and (B+Norms) with truth/humility norms.
Empirical Findings
Calibration and Reliability of Verbal Confidence
Self-reported verbal confidence exhibits moderate, stable correlation with token-probability-based confidence (Pearson r≈0.54–$0.58$, stable across prompt paraphrasing). Calibration metrics—Brier scores (∼0.33–0.36), ECE—are comparable between self-report and token-level baselines. These findings validate verbal confidence as a robust, inference-tractable uncertainty signal, with minimal sensitivity to surface prompt variation.
Selective Answering via Reward Framing and Normative Guidance
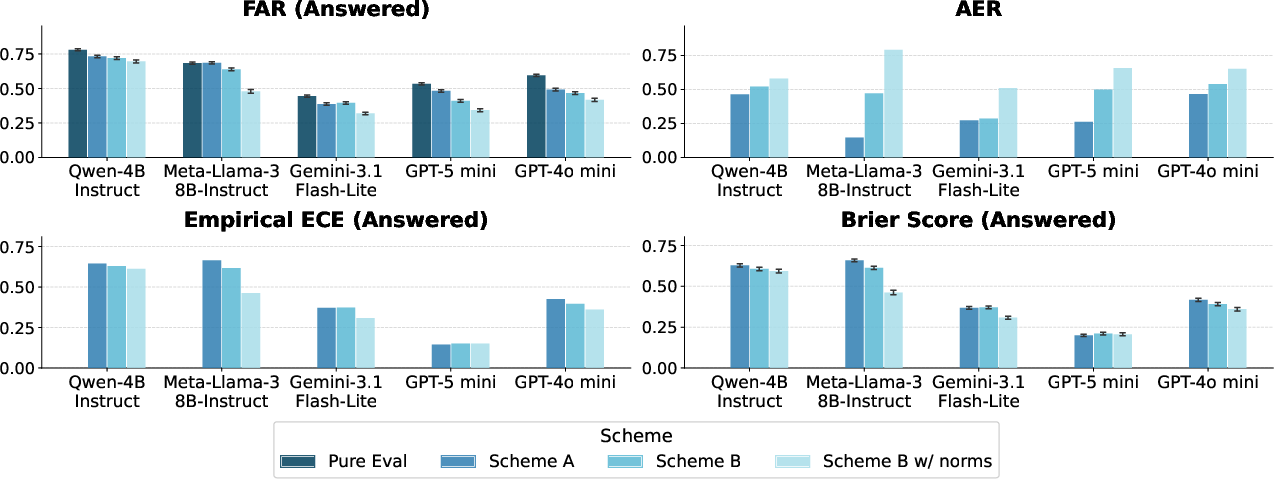
Cross-model evaluation on PopQA reveals that explicit abstention reward and norms substantially decrease hallucination rates among surfaced answers (FARanswered) and increase the model’s willingness to abstain on risky questions (AER), with the locus of improvement due to coverage–reliability reallocation rather than enhanced forced-answer competence (Figure 2).
Figure 2: Cross-model PopQA comparison under representative setups. Panels show FARanswered, AER, and confidence calibration for multiple models and prompt configurations.
For GPT-5 mini, Pure Eval yields FARanswered=52.3%; Scheme A reduces this to 48.2%, Scheme B to 41.0%, and Scheme B with norms to 34.2%. This reliability improvement is realized by abstaining on a much larger fraction of queries (coverage drops from r≈0.540 to r≈0.541 to r≈0.542 across these conditions).
AER (fraction of errors preceded by abstention) increases monotonically across the same progression (Figure 3):
Figure 3: AER for GPT-5 mini on PopQA across reward configurations.
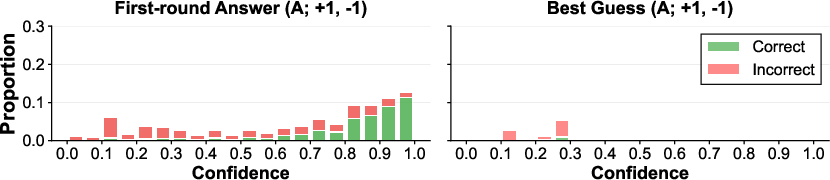
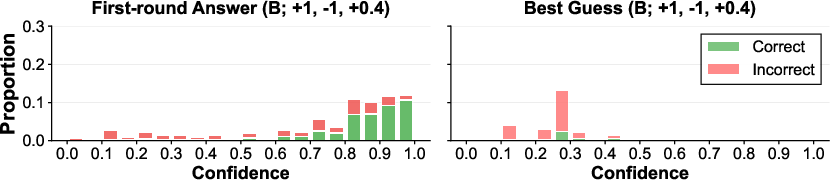
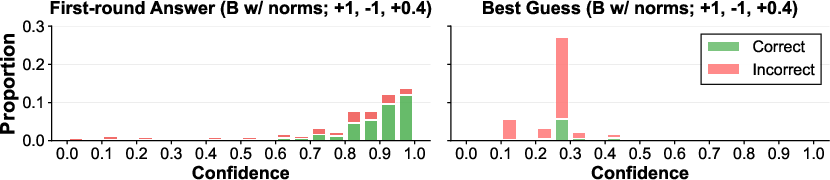
Confidence histograms (Figure 4) reveal that abstention incentives route error-prone, lower-confidence cases into abstention, while shifting best-guess confidences to the low end (r≈0.5430.3), sharpening the correspondence between reported confidence and actual correctness.
Figure 4: Confidence distributions for GPT-5 mini under representative PopQA reward schemes. Left: first-round surfaced answers. Right: second-round best guesses after initial abstention.
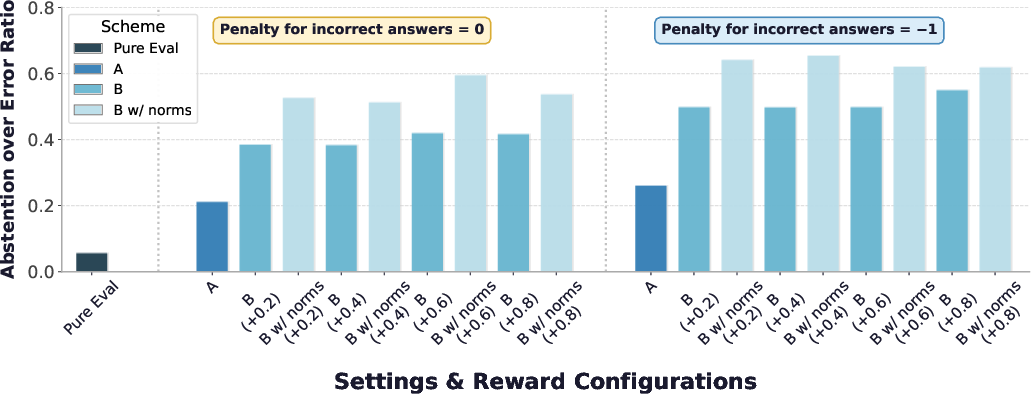
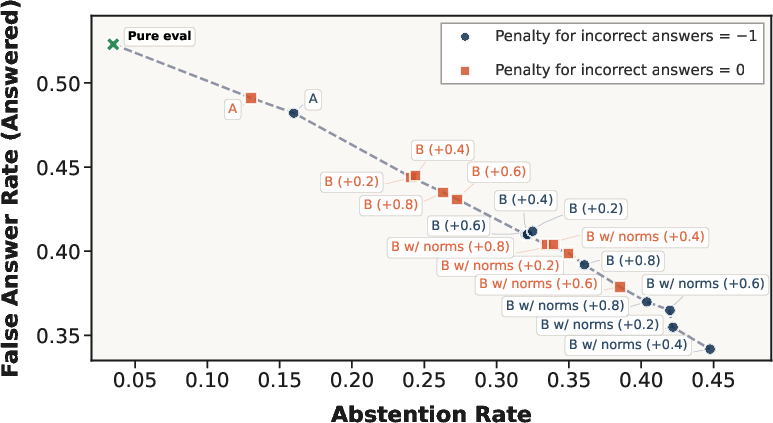
Abstention–Hallucination Frontier and Control
Adjusting the abstention reward r≈0.544 or penalty for incorrect answers r≈0.545 realizes an explicit frontier trading off coverage and hallucination risk (Figure 5). The model’s selective-answering locus can be tuned at inference, achieving user-controllable reliability guarantees without weight updates.
Figure 5: Abstention–hallucination frontier for GPT-5 mini on PopQA across all tested reward configurations.
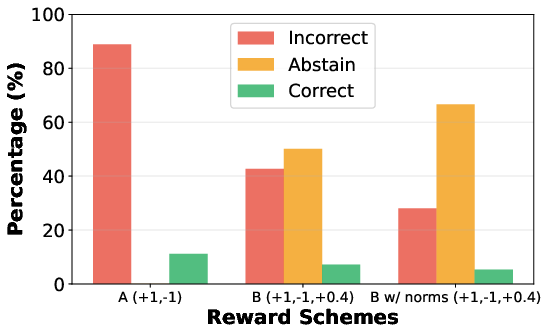
Component Ablation: Division of Labor
Ablation demonstrates that reward-only prompting increases abstention (AER r≈0.546) but reduces coverage and, absent confidence elicitation, increases abstention even on high-confidence, correct cases. Conversely, confidence elicitation alone modestly reduces FAR but cannot drive significant abstention. The full framework balances these forces, achieving substantial FAR reduction without excessive loss of correct answers.
Transfer and Robustness
Performance gains are most pronounced on harder factual QA benchmarks (PopQA, SimpleQA Verified), with magnitude of effect varying across model/dataset pairs. In easy settings (TriviaQA), improvements from selective abstention are limited by weak baseline hallucination risk.
Theoretical Implications
The empirical answer/abstain policy deviates from the Bayes-optimal threshold implied by the announced payoff function, with models answering across a broad confidence spectrum rather than rigidly thresholding as the payoff structure would mathematically dictate. This implies that current LLMs imperfectly couple verbal confidence to answer routing, highlighting a gap for future research in hardware-efficient selective-prediction.
Practical Implications and Deployment
The I-CALM framework enables deployment of black-box LLMs under selective-answering mandates. By allowing calibration of abstention reward, system designers can operationally control hallucination risk dynamically. Post-hoc confidence thresholding and certified risk-limiting wrappers (e.g., Clopper–Pearson-based acceptance) are directly enabled by prompted confidence estimates, providing finite-sample guarantees on surfaced-answer risk.
Limitations and Future Directions
The abstention mechanism is evaluated on factual QA with verifiable ground truths. Extension to settings involving underspecified, unsupported, or multi-possible-answer queries is deferred. Notably, the effectiveness of the prompt-based approach hinges on the model’s underlying capacity for uncertainty monitoring and may degrade under domain drift or adversarial re-prompting.
Future work should integrate prompt-level abstention incentives with retrieval, tool-use, or escalation modules, yielding uncertainty-aware agents that route challenging queries to fallback mechanisms or humans. Complementary approaches—e.g., lightweight training-time abstention or explicit calibration finetuning—may further improve alignment between stated and actual reliability.
Conclusion
The study rigorously demonstrates that explicit, inference-time reward framing and minimal normative prompting, when coupled with confidence elicitation, meaningfully reduce the hallucination risk of surfaced answers without modifying the underlying model. Practically, the method provides a flexible mechanism for tuning coverage–risk trade-offs in black-box LLM deployments, and theoretically, it highlights the potential and limits of prompt-based control over LLM epistemic humility.