- The paper introduces a benchmark (GenFig1) for visual summarization in scientific figure generation using a dataset of nearly 10,000 scholarly figure-text tuples.
- The paper evaluates multiple generation paradigms including zero-shot prompting, Chain-of-Thought, and SVG synthesis, demonstrating significant discrepancies between human and model outputs.
- The paper highlights that current vision-language models fail to capture detailed compositional and spatial nuances, urging the need for enhanced multimodal reasoning capabilities.
Introduction
The GenFig1 benchmark (2604.04172) introduces a rigorous, large-scale dataset and evaluation protocol for assessing the scientific reasoning and visual synthesis capabilities of vision-LLMs (VLMs). Unlike traditional text-to-image platforms designed for general visual domains, the GenFig1 task targets a high-value, unconstrained subproblem: generating the archetypal "Figure 1" from a scholarly manuscript, given the title, abstract, introduction, and the figure caption. These Figure 1s function as distilled graphical abstracts, concise overviews, or exemplars of the central technical contribution. The generation of such figures requires models to perform genuine scientific abstraction and selective visual rendering, a task that demands both multimodal and domain-specific intelligence.
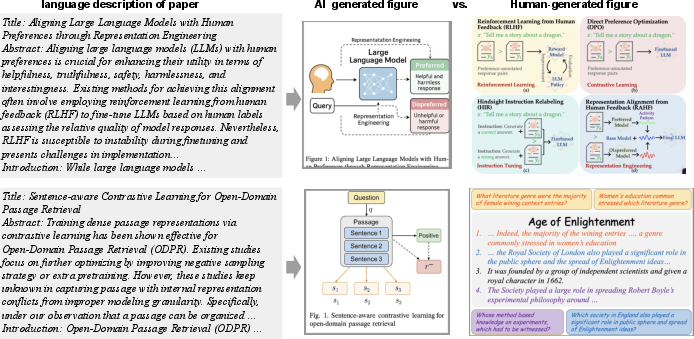
Figure 1: Representative instances from GenFig1, including original human-created figures, VLM zero-shot generations, Chain-of-Thought, SVG pipelines, and multi-image assembly; task performance is highly dependent on conceptual understanding and layout fidelity.
Dataset Construction and Taxonomy
GenFig1 comprises nearly 10,000 tuples from peer-reviewed publications in the top AI, ML, CV, and NLP venues (2020–2025). Each tuple consists of the full Figure 1, the title, abstract, introduction, and figure caption, allowing the evaluation of full-document summarization to diagrammatic synthesis. The dataset creation pipeline includes extensive source collection, canonical mapping to arXiv LaTeX sources, abstract/introduction/caption/figure extraction, and stringent post-hoc filtering. In particular, quantitative result figures (charts, metrics, etc.) are excluded in favor of visual blueprints or technical exemplars—tasks that require abstract technical reasoning rather than straightforward mapping from results.
Taxonomic analysis, derived from manual annotation over a representative sample, reveals three main categories: Overview (with Model Architecture and Method as subtypes), Example (Background, Method, Dataset), and Experimental Results (filtered out for the generative task). Distributional statistics indicate that Example—Method and Example—Background dominate, while Overview diagrams (pipelines, architectures) are also prevalent.
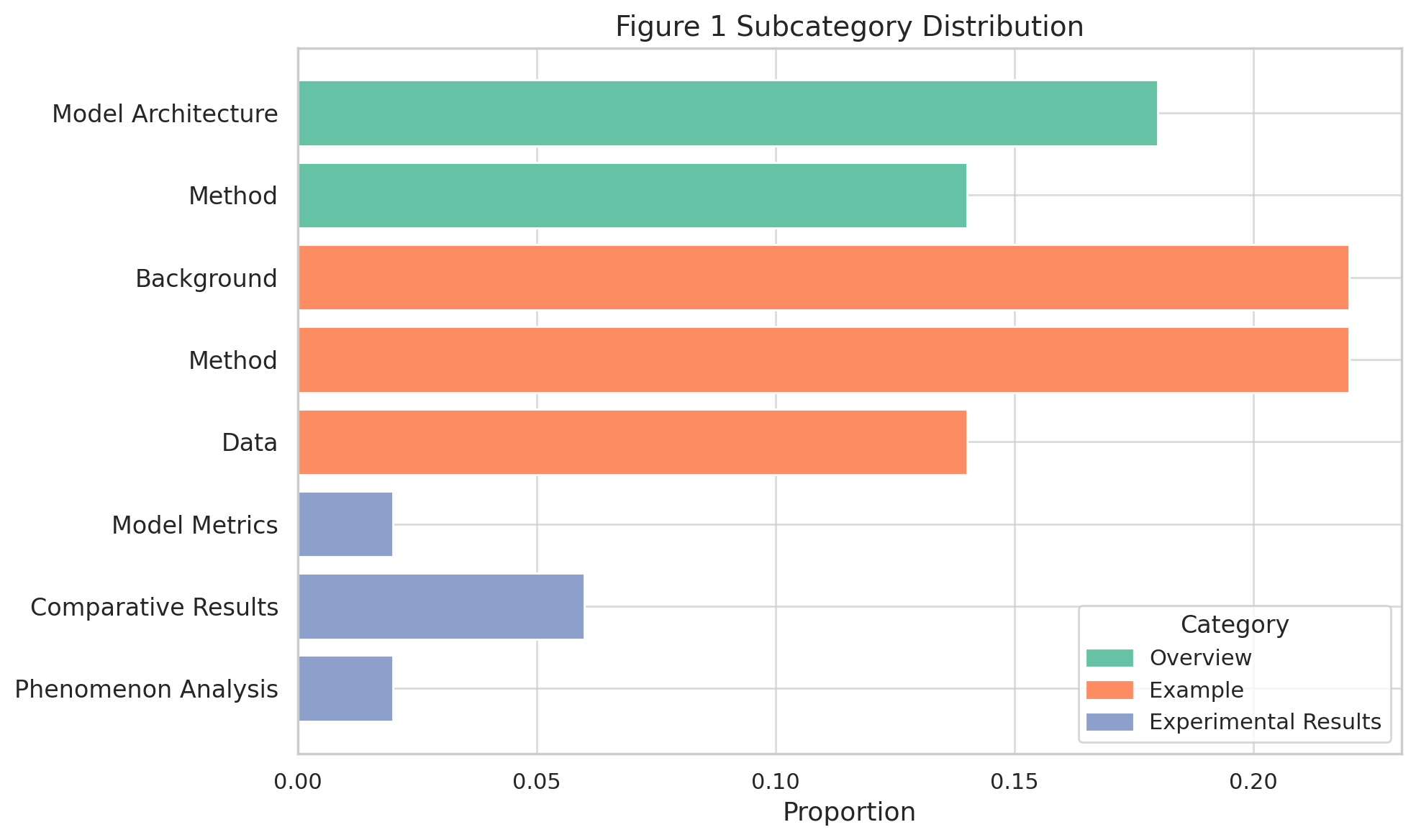
Figure 2: Extracted taxonomy of Figure 1s, showing the predominance of Method and Background exemplars, with architectural and conceptual overviews forming a secondary cluster.
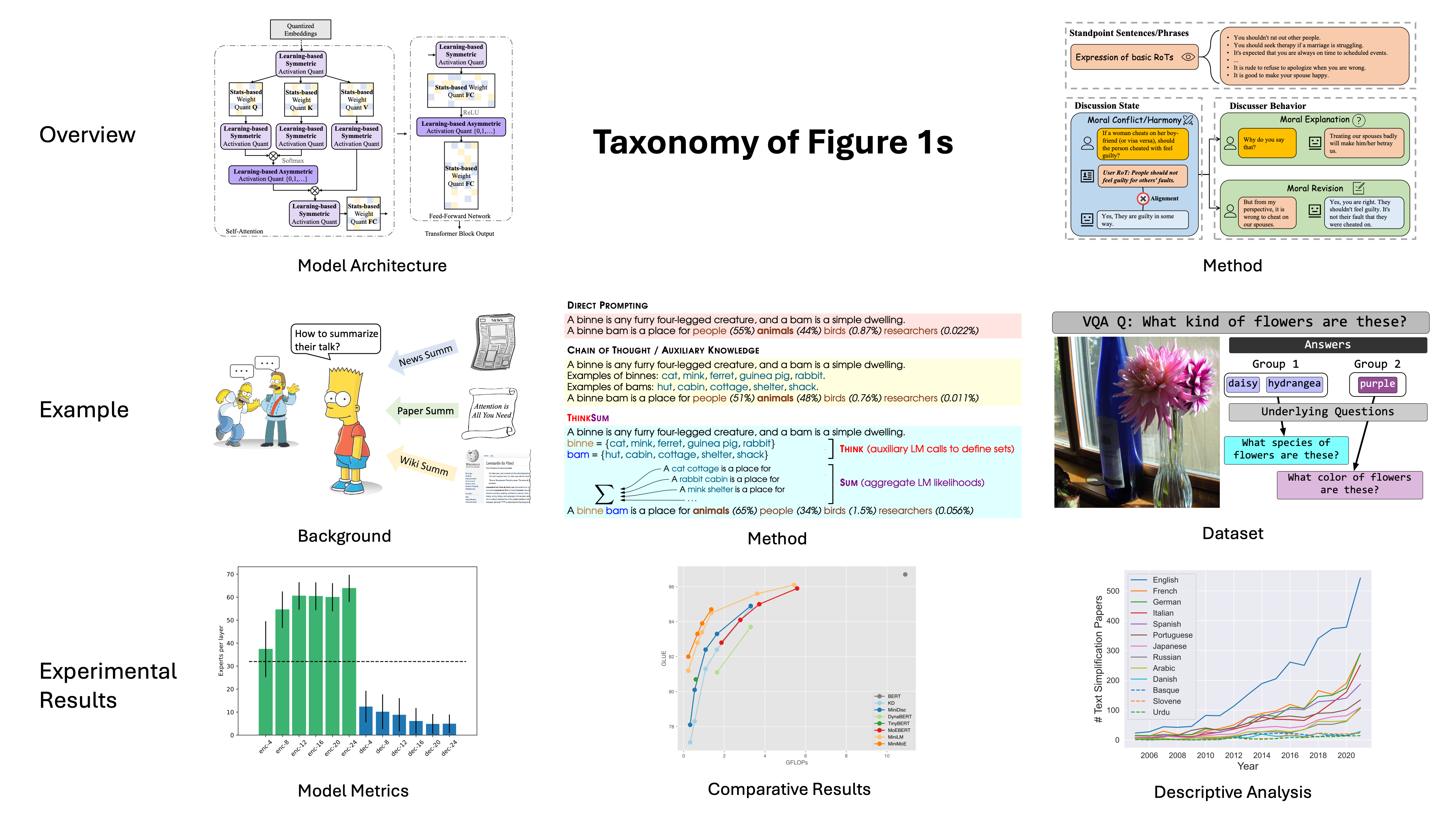
Figure 3: Visual exemplars illustrating the defined taxonomy classes, highlighting diversity across domains.
The dataset analysis shows significant style overlap between venues, with computer vision conferences forming a marginally distinct cluster in embedding space, but overall substantial commonality in figure design conventions.
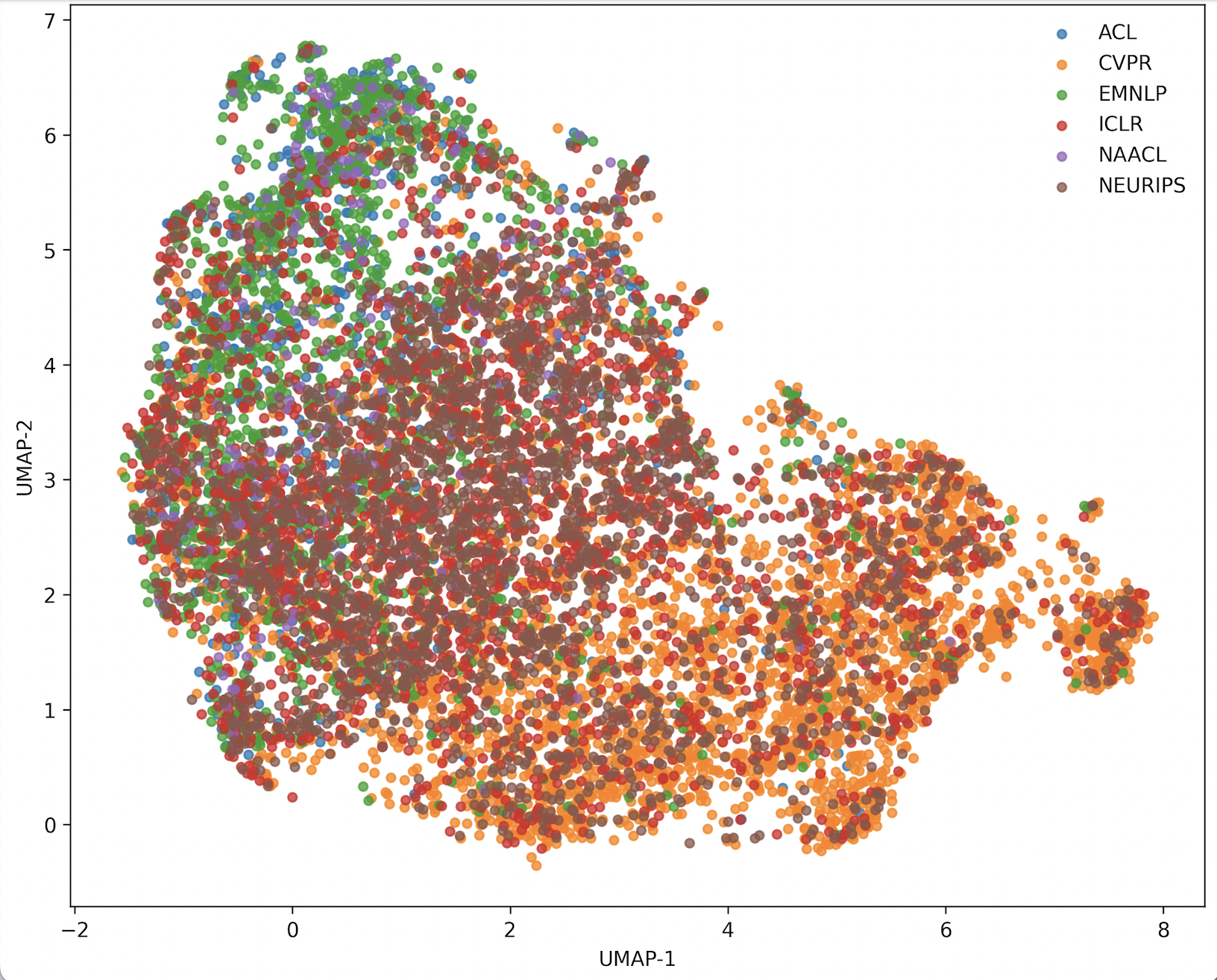
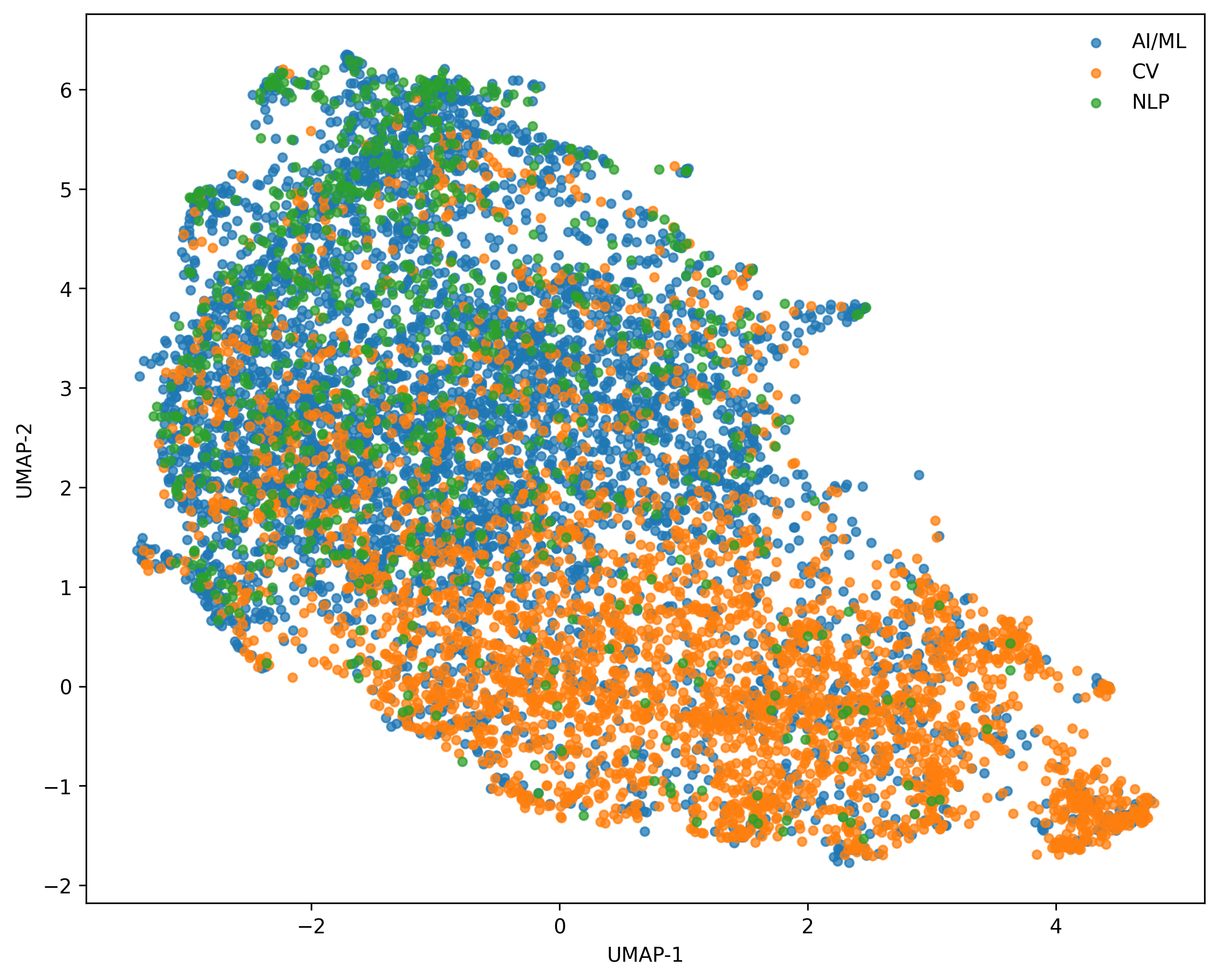
Figure 4: CLIP-based visual embeddings of figures, projected by UMAP, with minor clustering by venue/field but large shared latent structure.
Baselines and Evaluation
The study rigorously benchmarks multiple generation paradigms:
- Zero-shot image generation: Direct prompt-to-image mapping using a VLM (GPT-Image-1).
- Chain-of-Thought (CoT): Decomposition into taxonomy identification, layout reasoning, and region specification before final rendering.
- Chain-of-Images (CoI): Region-wise sequential generation, with assembly after individual region rendering.
- Text-to-SVG and CoT-SVG: SVG code synthesis (GPT-4o mini), both direct and hierarchical.
Diffusion and TikZ code-based pipelines are also considered but found nonfunctional/unsupported at scale.
Automatic evaluation leverages both reference-based (DINOv2 visual embedding similarity) and reference-free (VLM-as-a-Judge, text-rich catastrophic neglect) metrics. The VLM-as-a-Judge rubric scores clarity, faithfulness, information density, interestingness, aesthetics, and legibility using GPT-4.1, with strong correlation to expert human rankings.
Empirical Analysis
Strong and consistent results emerge:
- Human vs. Model Gap: All automatic and VLM-based pipelines underperform humans across all metrics—e.g., faithfulness (humans: 99.5, best model: 85.2), clarity, and legibility. The mean reciprocal rank (MRR) for human figures (0.787) substantially outpaces VLM generations (e.g., zero-shot: 0.453).
- Image-based vs. SVG-based: Text-to-image approaches significantly outperform SVG code synthesis in information density, faithfulness, and overall human preference.
- CoT/CoI vs. Zero-shot: Contrary to typical LLM reasoning, the zero-shot baseline yields higher scores than decomposition pipelines; the added complexity does not improve alignment, likely due to propagation of layout errors and compounding visual dissonance.
- Metric Validity: Among automatic metrics, VLM-as-a-Judge shows the highest correlation with human judgments (Spearman’s ρ up to 0.79 for info density), whereas embedding similarity is only moderately correlated.
Failure analysis reveals that VLMs, while sometimes capturing broad technical themes, often mishandle spatial composition, truncate key content, or misalign visual semantics with the context.
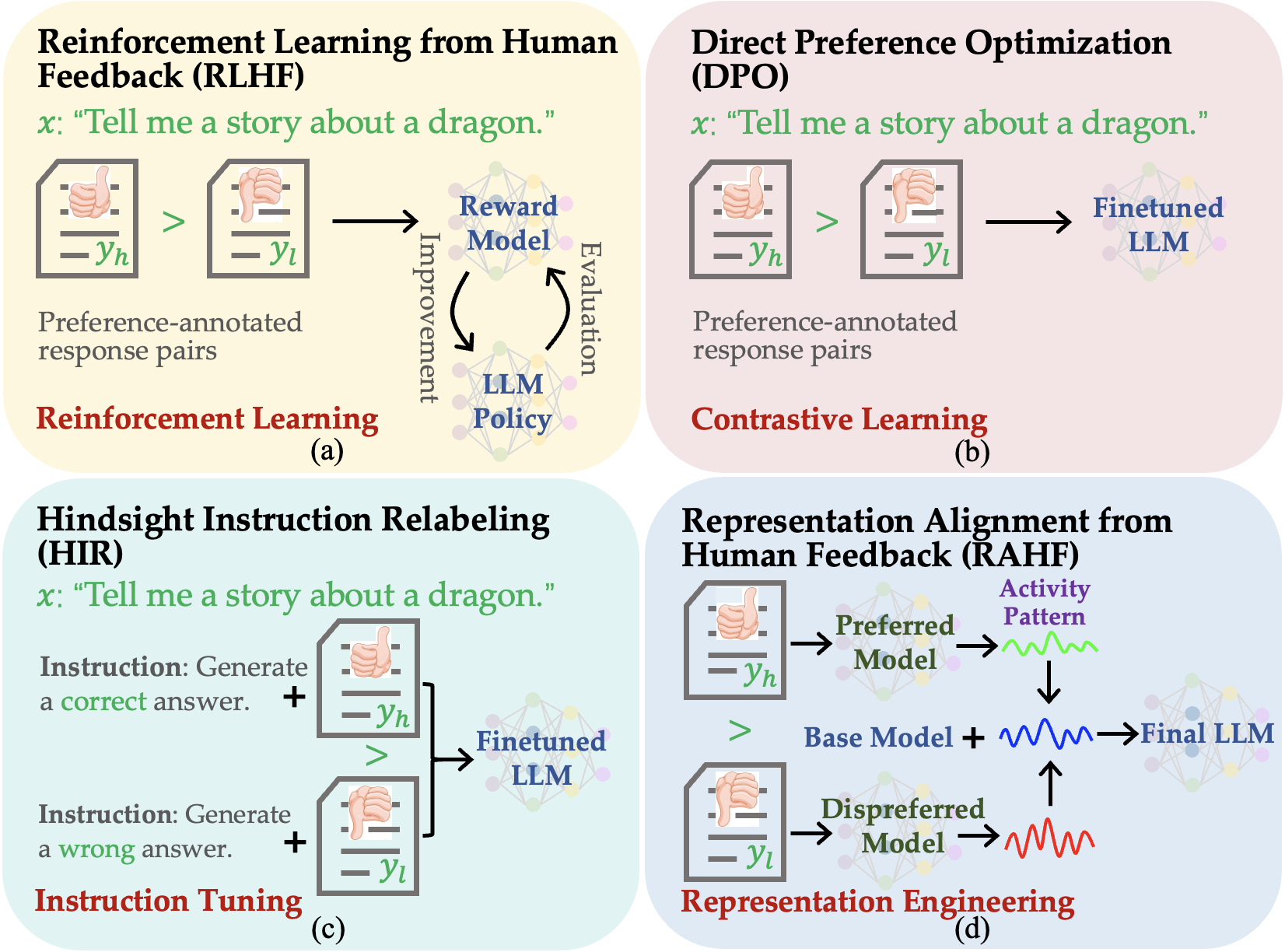
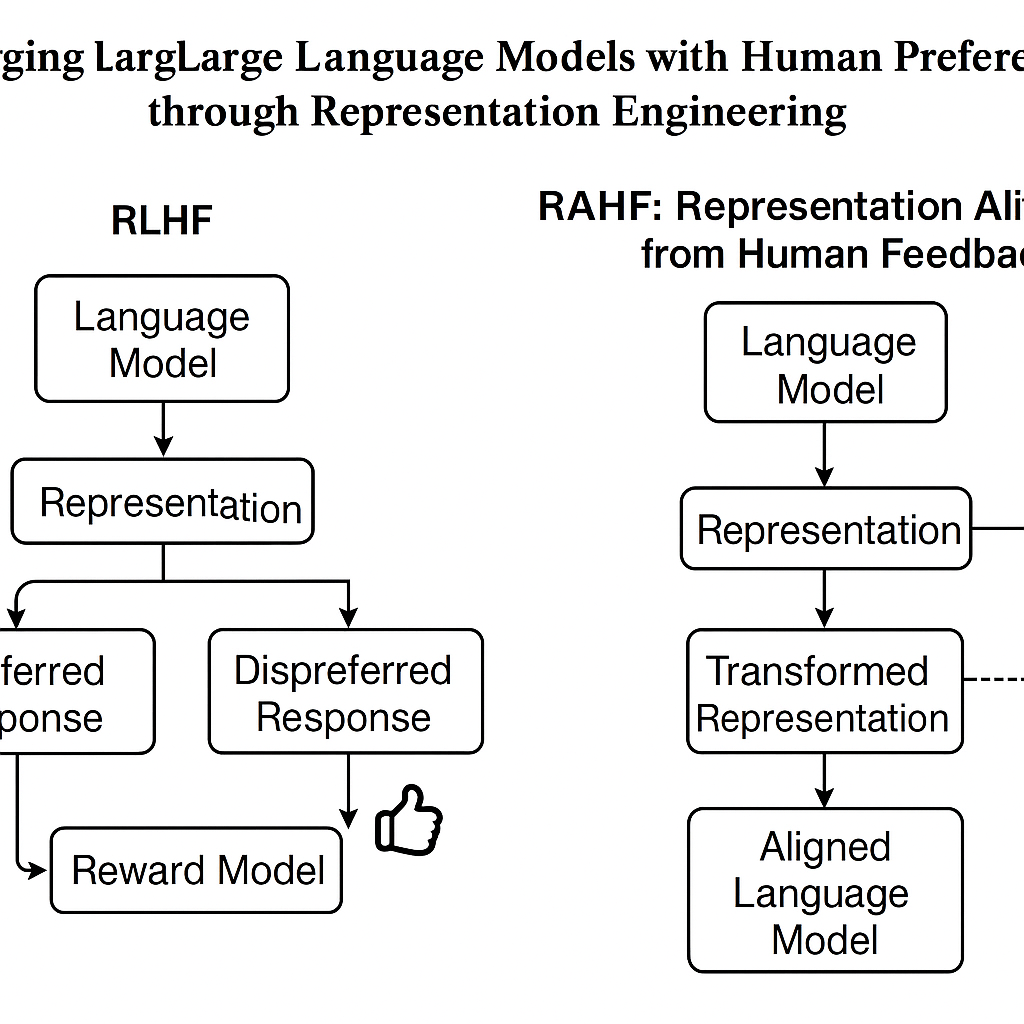
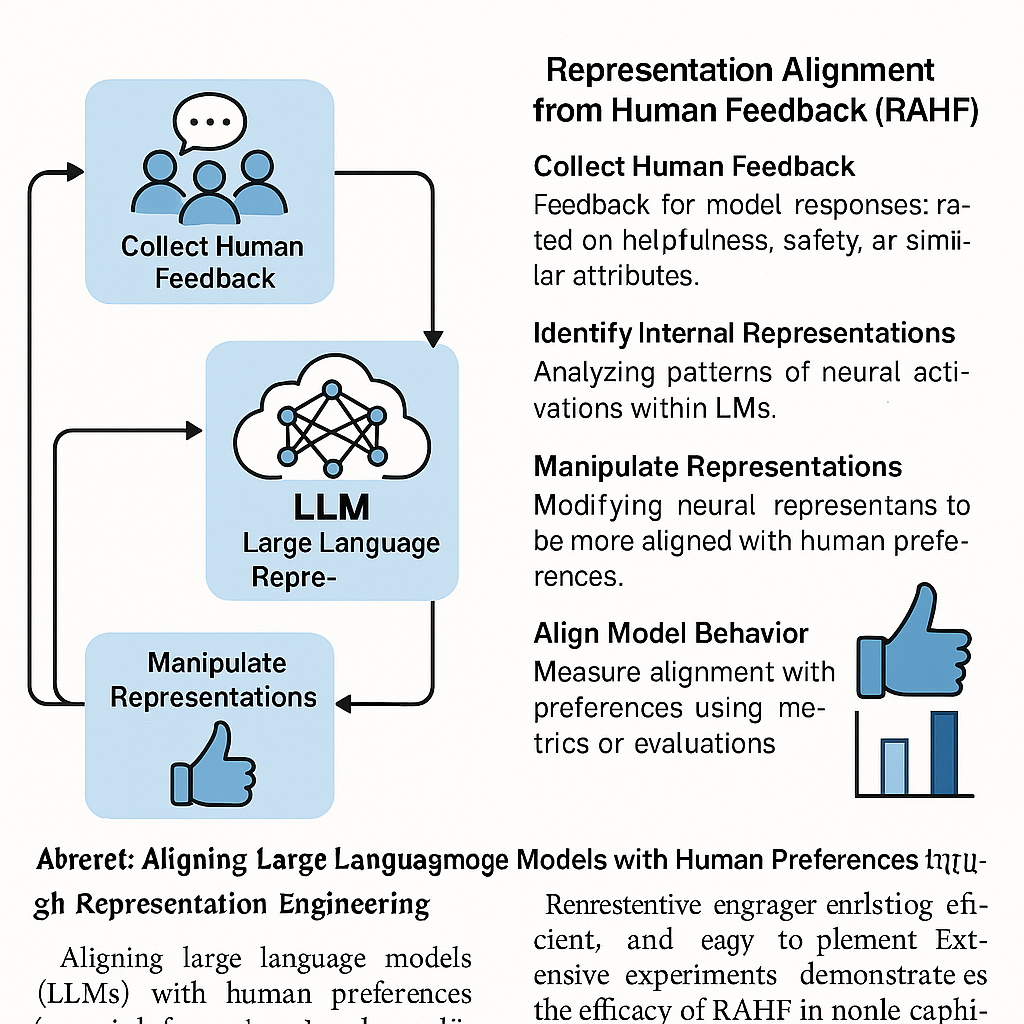

Figure 5: Examples of human and VLM-generated figures, illustrating superior compositionality and technical faithfulness by humans even under similar input constraints.
Implications and Future Directions
GenFig1 provides evidence that controllable, abstract, and scientifically faithful figure generation lies outside the capabilities of current state-of-the-art VLMs and hybrid architectures. The inability of multi-step reasoning (CoT, region-wise assembly) to outperform direct zero-shot prompting indicates intrinsic limitations—not simply insufficient prompt engineering or inadequate sample diversity, but lack of deep text-to-diagram translation and abstraction capabilities.
This result grounds the hypothesis that scientific visual communication demands a higher-order multimodal reasoning than general photorealistic image synthesis. Furthermore, the dataset and evaluation protocol expose weaknesses in current evaluation metrics for multimodal scientific reasoning, underscoring the importance of VLM-as-a-Judge approaches and emphasizing the need for robust, human-aligned metrics.
From a practical perspective, GenFig1 establishes a precise, reproducible benchmark and a canonical, high-quality testbed for generative AI methods targeting scientific communication. The explicit disaggregation of the figure taxonomy can seed future development of conditionally controllable or domain-adaptive figure generation models. The formalization of automatic metrics and their correlation with expert preference enable scalable auditing and comparison of future advances.
Theoretically, the documented gap between human and machine performance invites investigation into new architectures for multimodal abstraction, compositional spatial parsing, and the explicit representation of mathematical/algorithmic relationships. The failure of SVG and code-based synthesis relative to pixel-based image generation suggests that domain-specific priors or hybrid symbolic-connectionist pipelines may be necessary for progress.
Conclusion
GenFig1 positions itself as the de facto benchmark for visual scientific summarization. By systematizing the generation and evaluation of Figure 1 as a challenge for vision-LLMs, it reveals both the current limitations and the fundamental requirements for future scientific AI. The benchmark, the associated metrics, and the empirical findings guide the development of next-generation models—those that aspire not only to produce plausible images but to genuinely translate technical complexity into visual clarity and conceptual fidelity.

