- The paper introduces a scalable and explainable pipeline that leverages MLLM embeddings to predict learner-video interactions from raw video segments.
- It fuses multimodal features from transcripts, visuals, and slides to align predictions with CTML principles, achieving AUCs up to 0.76 in behavior prediction.
- The approach employs TCAV analysis to interpret CTML features, offering actionable insights that bridge empirical behavioral traces and instructional design.
Scalable and Explainable Prediction of Learner-Video Interactions with Multimodal LLMs
Introduction
This paper explores the problem of predicting moment-to-moment learner interactions (watching, pausing, rewinding, skipping) with educational video content, using only the raw video segment as input. Rather than relying on retrospective video analytics or aggregated behavioral data, the proposed pipeline leverages multimodal LLMs (MLLMs) for content-based pre-screening and explainable modeling. Importantly, the approach is grounded in the Cognitive Theory of Multimedia Learning (CTML), with explicit feature coding and interpretation of model outputs in relation to well-established instructional design principles.
The work addresses three core research questions: (1) To what degree can MLLM embeddings of short video segments predict population-level interaction peaks; (2) Can these predictions be interpreted through CTML feature codings; (3) How sensitive are embedding-based models to multimedia learning concepts, as quantified by Testing with Concept Activation Vectors (TCAV).
Methodological Framework
A scalable, interpretable pipeline is introduced (Figure 1). The approach first aggregates clickstream interactions into percentile-ranked behavioral signals and preprocesses video content into synchronized multimodal views: automatic transcripts, visual slide text, and sampled video frames.
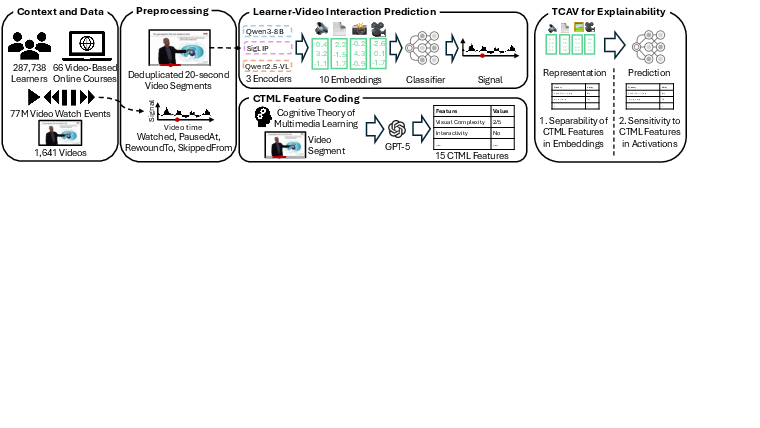
Figure 1: Pipeline for predicting learners’ interactions with online learning videos and explaining predictions from multimedia learning theory.
Video segments (20 seconds around each time-point) are embedded with state-of-the-art vision-language and text transformers (e.g., Qwen3-Embedding-8B, SigLIP, Qwen2.5-VL). Embeddings from these modalities are concatenated and fed into a lightweight neural classifier, which predicts whether a given moment falls among the top K% of interaction peaks (watching, pausing, rewinding, or skipping) per video. The model includes a video-level reference embedding to normalize importance across heterogeneous content.
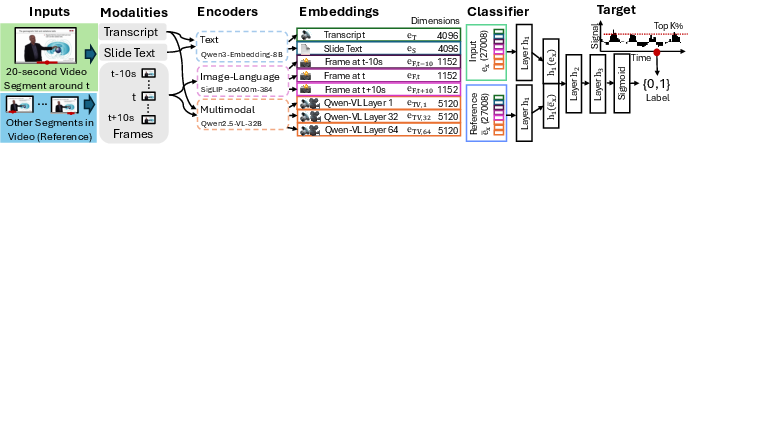
Figure 2: Three modalities of video segments around t are encoded by pre-trained transformers. A neural classifier predicts if Signalv(t) is among the top K\% at timepoint t.
To expose theoretical interpretability, video moments are annotated with a rubric of 15 CTML features, including visual complexity, instructor presence, formulas, semantic and visual breakpoints, redundancy, and more. These features are coded by GPT-5, and their presence/absence forms the basis for subsequent TCAV analysis: for each concept, a linear probe is trained on the model’s hidden layers, and the TCAV score quantifies the fraction of correct predictions that are locally sensitive to the given feature.
Experimental Results
Evaluation spans 77 million video interactions across 1,641 videos from 66 STEM-focused courses. Predictive performance is measured by area under the ROC curve (AUC) and operational Lift@K metrics.
The multimodal classifier achieves AUCs up to 0.76 for rewinding behavior and 0.74 for pausing, clearly outperforming random baselines for all signals except skipping (which is less temporally localized to content). Models generalize effectively to unseen academic fields, with only minor performance degradation outside the training domain (Figure 3).
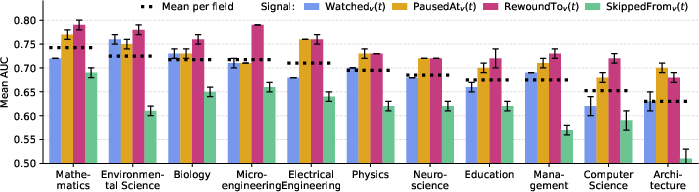
Figure 3: AUC (± std, 5 seeds) for prediction of top 5% learner-video interaction moments on fields unseen during training as a measure of generalization of the classifier.
Segment transcript and visual embeddings both convey informative signal, but maximal performance is obtained by fusing all modalities and including the context-averaged video reference embedding. The choice of layer and encoding depth in vision-LLMs affects performance (layer 32 offers best linear separability for CTML concepts), but smaller 7B parameter encoders perform comparably well to larger models, supporting the pipeline’s scalability.
CTML features auto-coded by GPT-5 display high inter-rater agreement with humans for visually objectified concepts (e.g., instructor presence, visual breakpoints) and moderate agreement for subjective transcript-driven features (e.g., signaling, interactivity).
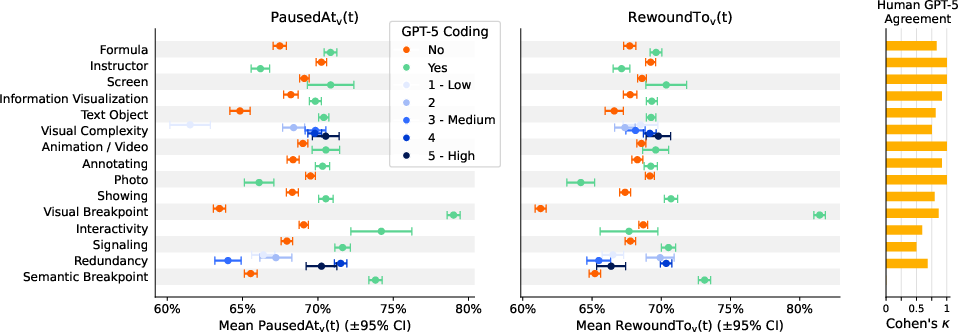
Figure 4: Learner-video interactions at 6,000 video moments (50% from top 5% ranks) by CTML features coded by GPT-5; inter-rater agreement is shown in the right panel.
Most CTML features are significantly associated with behavioral signal. E.g., moments containing formulas, semantic or visual breakpoints show elevated pausing and rewinding; photo- or instructor-present scenes correlate with lower cognitive-load proxy signals. Visual complexity and redundancy display non-linear influences, matching theoretical expectations from CTML.
Predictive power of CTML feature sets alone saturates quickly as sample size grows, and is outperformed by high-dimensional MLLM embeddings at scale. However, with moderate (<1,000) annotated datapoints, CTML features confer stronger predictive performance—highlighting their value as interpretable, low-cost priors.
TCAV-Based Explainability
TCAV analysis on the classifier’s embedding and hidden spaces uncovers robust, statistically significant model sensitivity to nearly all CTML features—demonstrating that MLLM embeddings not only support high classification accuracy, but encode meaningful instructional design concepts.
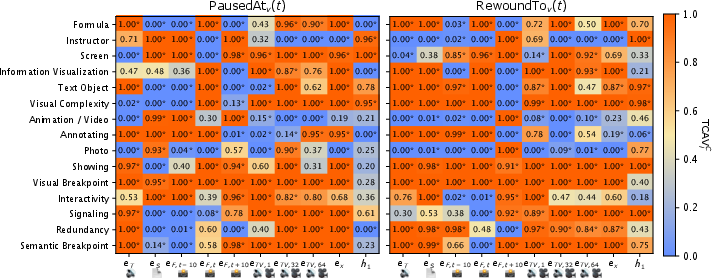
Figure 5: TCAV values of CTML concepts and activations in the classifier H. Significant (
) values above 0.5 indicate positive sensitivity to the concept.*
The model’s positive sensitivity is strongest for visual breakpoints, annotations, redundancy, and structured visualizations, consistent with CTML’s predictions on cognitive load. Some modality-dependent and concept-position-specific effects are also revealed (e.g., formulas’ positive association with pausing when spoken, negative when on slides). Binary CTML concepts reach AUCs above 0.82 in linear probe decoding tests. Even transcript-only embeddings contain latent information about visual features, indicating MLLM cross-modal integration.
Practical and Theoretical Implications
This research demonstrates the feasibility of pre-screening instructional videos for cognitive load proxies prior to deployment—overcoming the cold-start challenge with scalable content-based AI explainability. The pipeline enables empirical hypothesis testing in multimedia learning research at unprecedented granularity and scale and opens new frontiers for rapid, interpretable instructional design feedback.
On the methodological side, the integration of MLLMs with interpretable concept-based probing sets a template for explainable educational AI, strengthening alignment with cognitive theory rather than opaque association mining.
Going forward, several directions emerge: (1) extension to non-STEM domains to uncover discipline-specific generalization limits; (2) integration of course- or learner-level covariates; (3) more fine-grained, temporally adaptive context selection; (4) improved annotation of abstract CTML concepts with additional human-AI collaboration.
Conclusion
This paper introduces a content-grounded, scalable, and interpretable framework for predicting and explaining learner-video interaction patterns. Leveraging MLLM-based segment embeddings, automated theory-driven coding, and concept activation probing, the approach yields high predictive accuracy, strong generalizability, and rich interpretability with minimal cost. The results substantiate the view that multimodal LLMs, when coupled with explicit theoretical constructs and explainable AI methods, can bridge the long-standing gap between empirical behavioral traces and actionable instructional design.

