- The paper introduces a geometric view of hallucinations, modeling them as attractor basins in LLM latent spaces for a formal, task-dependent theory.
- It proves radial contraction and trajectory trapping theorems, linking hidden state dynamics to the irreversibility of hallucination propagation.
- The study proposes an adaptive geometry-aware steering method that reduces hallucination rates at inference time without requiring model retraining.
Hallucination Basins: A Dynamic Framework for Understanding and Controlling LLM Hallucinations
Introduction
"Hallucination Basins: A Dynamic Framework for Understanding and Controlling LLM Hallucinations" (2604.04743) introduces a geometric dynamical systems view of hallucinations in LLMs, characterizing them as emergent phenomena arising from attractor basins in model latent spaces. Rather than treating hallucinations as a black-box uncertainty property or addressing them via surface-level entropy metrics, the paper provides a formal, task-dependent theory, which is empirically validated, that links hallucination probability and irreversibility to explicit geometric structures of transformer hidden states. This framework unifies and explains task-dependent separability of factual and hallucinated modes and motivates a geometry-aware steering approach that effectively reduces hallucination propensity without model retraining.
Conceptual Framework and Theoretical Foundations
The central proposition is that hallucinations correspond to hidden-state trajectories entering locally attracting basins—specific regions in the model's latent space where representations lose context-dependency and the transformer contracts all subsequent activations towards basin centroids. The paper defines reference states μ(ℓ) for each layer, computed from uninformative contexts. The hallucination basin at a layer ℓ is then formalized as a ball centered at μ(ℓ) of radius r, equipped with two critical properties: (1) once a hidden trajectory enters, it is contractively trapped across subsequent layers (irreversibility), and (2) outputs in the basin are nearly invariant to the input context, yielding semantically or factually spurious but fluent generations.
The theoretical section provides:
- A proof of radial contraction—via spectral analysis of the local Jacobian—that formalizes when a transformer layer will cause geometric collapse towards the reference state.
- The trajectory trapping theorem, establishing that once a trajectory enters the contraction region, further context-sensitive deviations are exponentially suppressed across layers.
- Analysis of task-dependent basin geometry: for single-answer (factoid) tasks, hallucination states collapse to a singular reference point (sharp basins), while open-ended (generation) or misconception (multi-answer) tasks induce high-dimensional manifolds or multiple competing attractors.
- Definition of geometric risk metrics (Euclidean basin distance, Fisher discriminant ratio) providing quantifiable and robust signals that correlate with hallucination likelihood.
Task-Dependence and Empirical Geometry
The theory makes strong claims about the task-dependence of hallucination separability. For single-answer QA, factual and hallucinated states are highly separable due to point-attractor collapse, whereas for summarization and misconception-rich settings (e.g., TruthfulQA), factual and hallucinated distributions overlap significantly, undermining simple linear discriminability.
Empirical results, visualized using PCA projections of hidden states, confirm that:
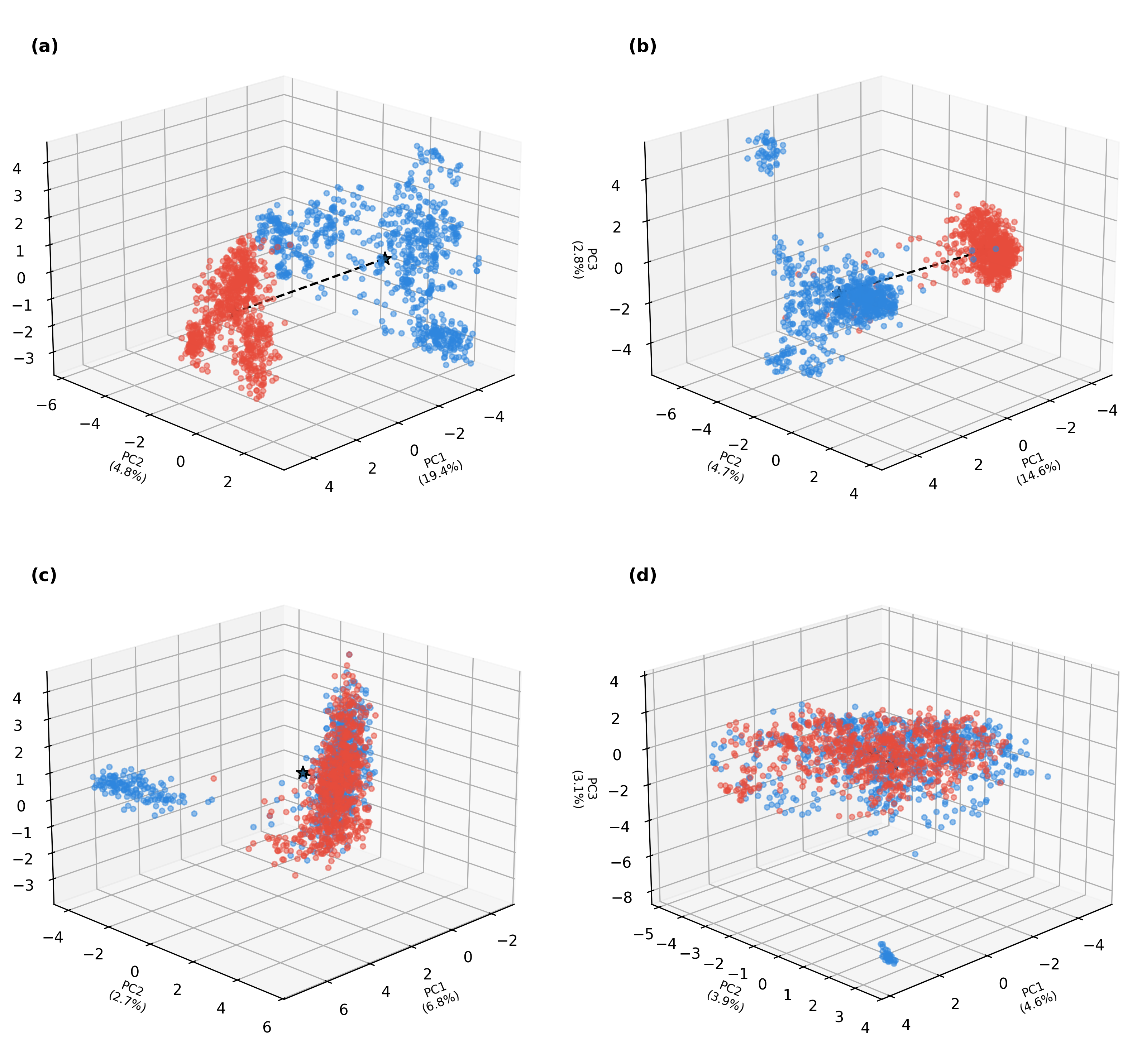
Figure 2: Task-dependent formation of hallucination basins: sharp separation for factoid settings (MuSiQue, HaluEvalQA), overlapping or manifold-like geometry in summarization and misconception tasks (HaluEvalSummarization, TruthfulQA).
The variance collapse for hallucinated versus factual states is quantified; factoid tasks exhibit up to 4–10× variance expansion in factual states (high ρvar), while summarization and misconception tasks have ρvar≈1. Geometric AUROC-based detection using centroid and Mahalanobis classifiers corroborates these distinctions, with near-perfect detection on factoid tasks and random-level detection on generative ones.
Causal and Irreversibility Evidence
A critical causal contribution is the demonstration that steering factual hidden representations along the hallucination basin direction increases hallucination probability via a dose-response effect, whereas orthogonal or random direction injections do not.
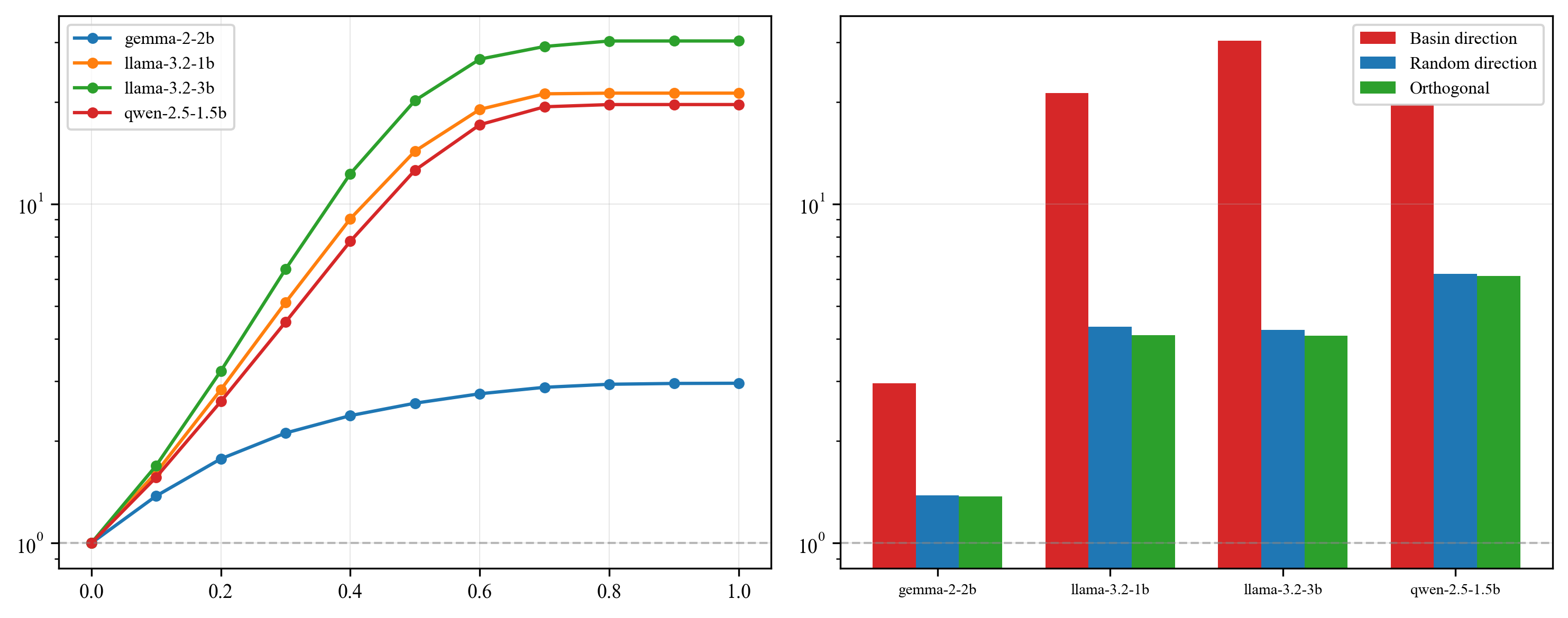
Figure 1: Causal interventions show that steering hidden states along the hallucination basin direction sharply increases hallucination probability, supporting the attractor model.
Furthermore, the analysis of irreversibility under autoregressive decoding shows that after entry into a basin, escape is rare, verifying the theoretical claim of basin-induced context-insensitivity.
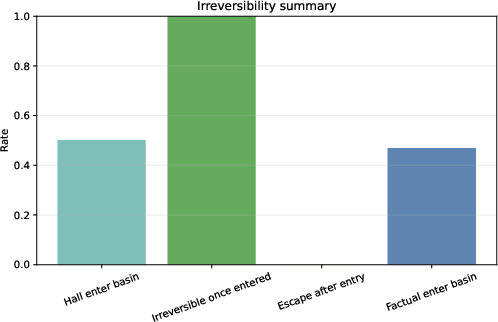
Figure 3: Summary of basin-entry, irreversibility, and escape rates during decoding confirms the geometric trapping of hallucination trajectories.
Geometry-Aware Steering as Mitigation
Leveraging the characterized basin geometry, the paper develops an adaptive geometry-aware steering method: it computes steering vectors (from class centroids), and dynamically adjusts the intervention magnitude based on proximity to the reference basin or local contraction rates. This algorithm effectively reduces hallucination rates across models and tasks, as evidenced by controlled empirical evaluations.
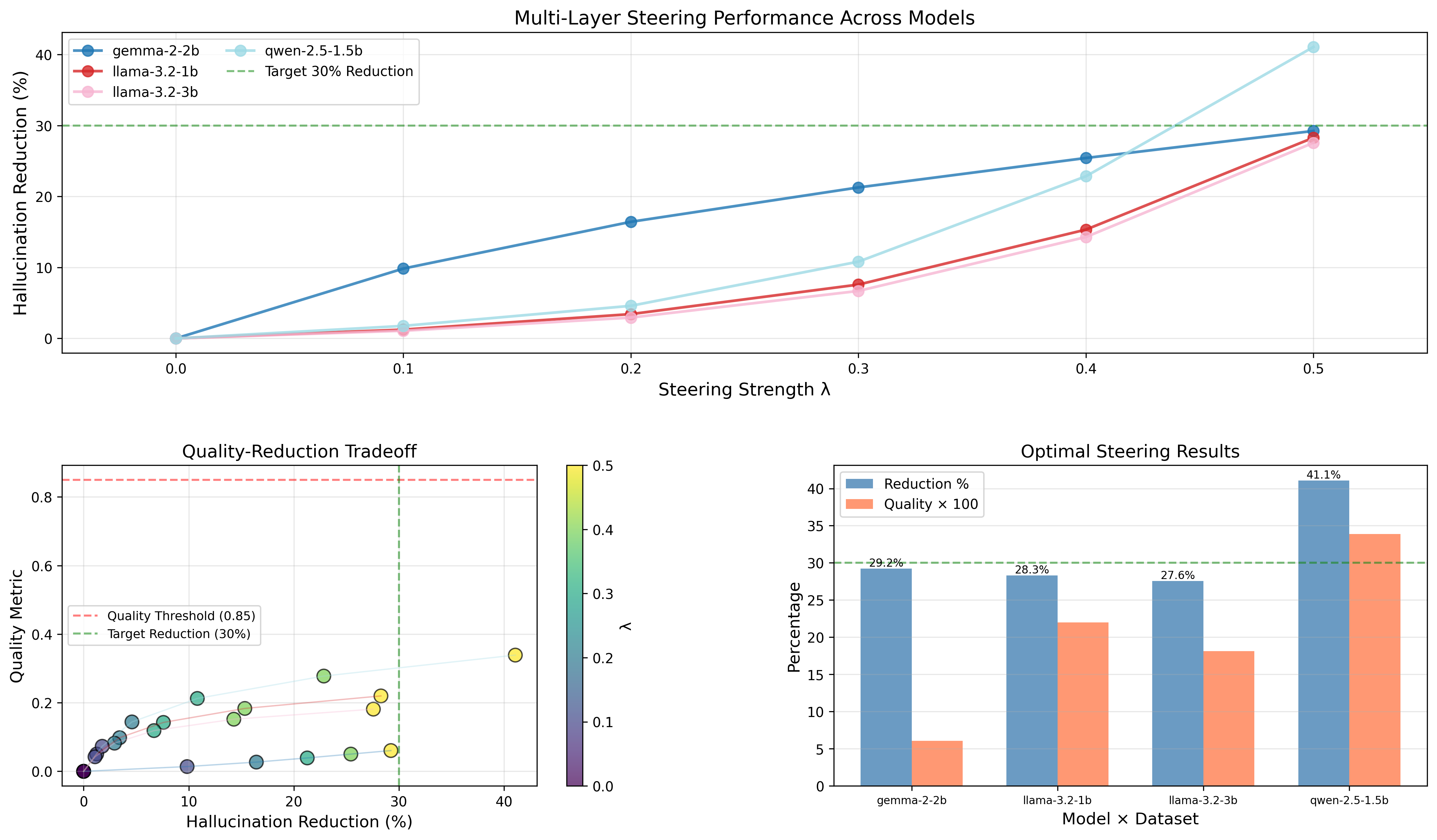
Figure 6: The geometry-aware adaptive steering algorithm yields a monotonic reduction in hallucination rate as a function of steering strength, without retraining.
Attention Entropy and Reference States
Layer-wise analysis of attention entropy demonstrates that in-uninformative contexts, hallucination basins coincide with elevated attention entropy, supporting the theoretical assumption that basin collapse arises under conditions where the attention mechanism produces near-uniform weights and ceases to focus on informative context.
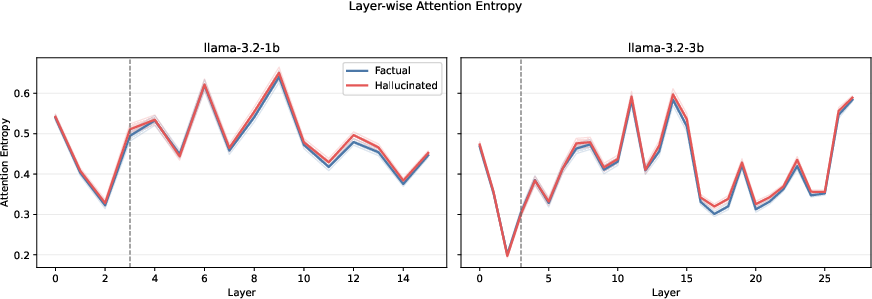
Figure 5: Factual and hallucinated generations under uninformative context show diverging layerwise attention entropy trends, reinforcing the geometric interpretation of basin formation.
Implications and Directions for Further Research
The results have direct implications for the theoretical understanding and practical mitigation of LLM hallucinations:
- Theoretically, the work positions hallucinations firmly as latent-space geometric phenomena, explainable and predictable via local spectral and contraction properties of transformer layers—a significant progression over output-only interpretation.
- Practically, the proposed geometry-aware steering is readily implementable at inference-time for open-source LLMs, does not require retraining or gradient access, and can yield material hallucination risk reductions.
- The basin theory motivates new formalizations of model interpretability, links to associative memory in neural systems, and provides concrete metrics (contraction rates, Fisher separation) for evaluating model trustworthiness.
Future research directions include:
- Extending the basin framework to RAG architectures and multimodal transformers.
- Black-box approximations for inference-only APIs (e.g., via surrogate modeling).
- Automated diagnosis of failure cases, such as overlapping multi-basin misconception tasks where geometric separability is currently limited.
Conclusion
This study formalizes LLM hallucinations as dynamic, task-dependent attractor phenomena rooted in the latent geometry of transformer models. By connecting the emergence of hallucinations to explicit contraction and trapping in hidden-state space, and by demonstrating strong task-dependent separability, causal controllability, and geometry-driven steering efficacy, it provides a rigorous analytic framework and actionable tools for hallucination understanding and intervention. This geometric paradigm lays the groundwork for principled analysis and control of hallucination risk in both current and future LLMs.