- The paper introduces a tri-level hierarchical evaluation protocol that decomposes video understanding into visual aggregation, temporal modeling, and complex reasoning.
- It employs a group-based non-linear scoring mechanism that penalizes inconsistencies, revealing a significant model-human performance gap.
- Experimental results show that proprietary models outperform open-source counterparts, underscoring the need for stronger cross-modal fusion and robust temporal grounding.
Video-MME-v2: A Comprehensive Benchmark for Robust and Faithful Video Understanding
Motivation and Background
The transition from static image-based MLLMs to video-centric architectures has highlighted substantial deficiencies in both the design of benchmarks and the actual multimodal reasoning capacity of state-of-the-art systems. Contemporary video MLLM benchmarks are rapidly approaching saturation, with single-question accuracy metrics masking profound inconsistencies in perception, temporal modeling, and logical reasoning. Existing evaluations are typically focused either on restricted domains (e.g., action recognition, long-context retrieval) or oversimplify the assessment of multimodal reasoning by neglecting the compounded effects of failures at different stages of comprehension. This paper, "Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding" (2604.05015), directly addresses these shortcomings through an integrated, multi-level, group-based evaluation protocol designed to distinguish true multimodal intelligence from ad hoc or inconsistent behavior.
Benchmark Architecture: Hierarchical and Group-Based Protocol
Video-MME-v2 operationalizes a tri-level hierarchical taxonomy of tasks to decompose video understanding into successive layers of complexity: visual information aggregation (Level 1), temporal dynamics modeling (Level 2), and complex multimodal reasoning (Level 3). Each level incorporates a diverse set of subcategories and task types, emphasizing not only the variety of perceptual and reasoning skills required but, crucially, their dependencies. By organizing the evaluation this way, the benchmark exposes the hierarchical bottlenecks where upstream failures in perception or temporal analysis percolate into downstream reasoning errors, compounding the overall performance degradation.
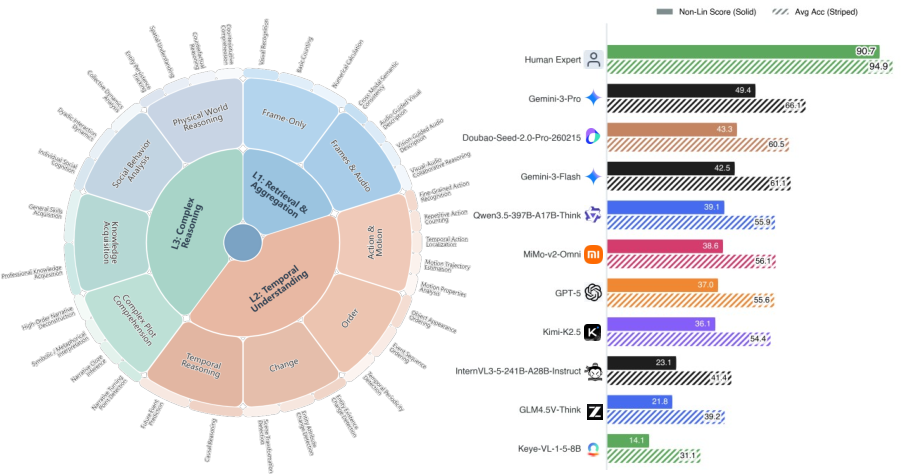
Figure 1: (Left) The three-level capability hierarchy of Video-MME-v2, which structures levels from information aggregation to temporal understanding to complex reasoning. (Right) Non-linear group-based scores highlight the marked gap between human and model performance.
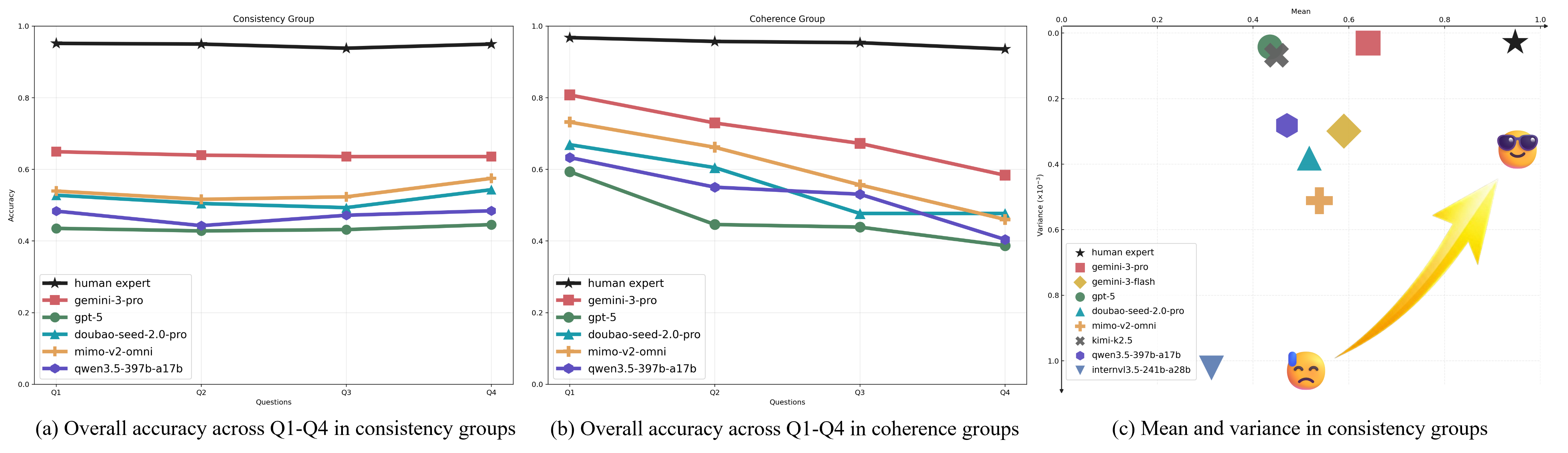
The core innovation lies in the group-based evaluation and non-linear scoring protocol: Consistency-based groups probe the breadth and granularity of specific perceptual or temporal skills via correlated question sets, while coherence-based groups target the depth of multi-step reasoning by structuring queries as progressive logical chains. Non-linear scoring functions penalize fragmented or guess-based success, rigorously enforcing both capability consistency and logical faithfulness.
Dataset Curation and Quality Control
The Video-MME-v2 dataset comprises 800 temporally recent, high-quality videos, each paired with 4 group-structured questions and 8 carefully adversarial answer options, annotated through an extensive pipeline involving more than 3,300 human-hours. Rigorous quality controls include a recency filter (mitigating pretraining leakage), balanced category taxonomy, multi-stage cross-validation, independent blind testing with 50 reviewers, and iterative closed-loop error correction.
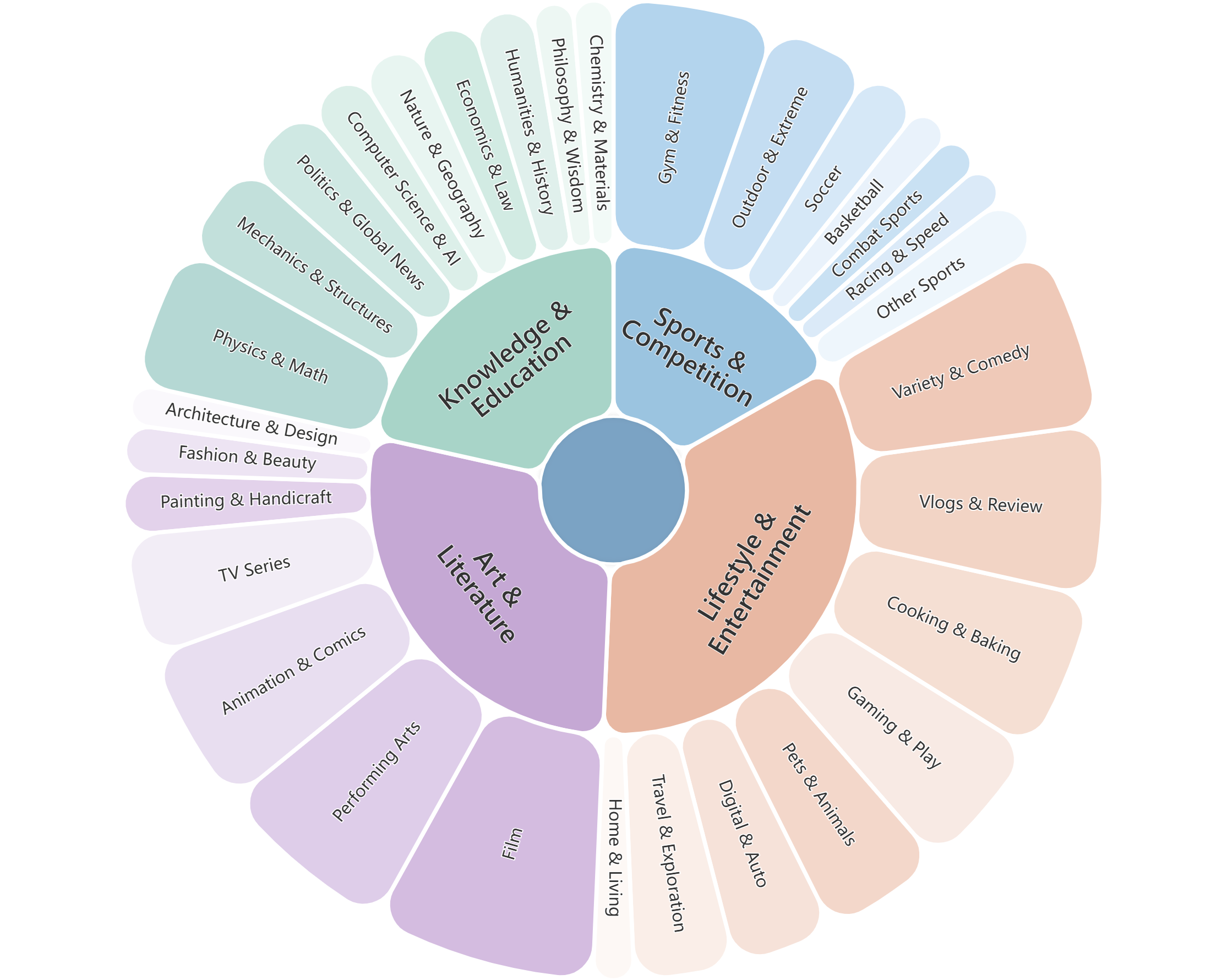
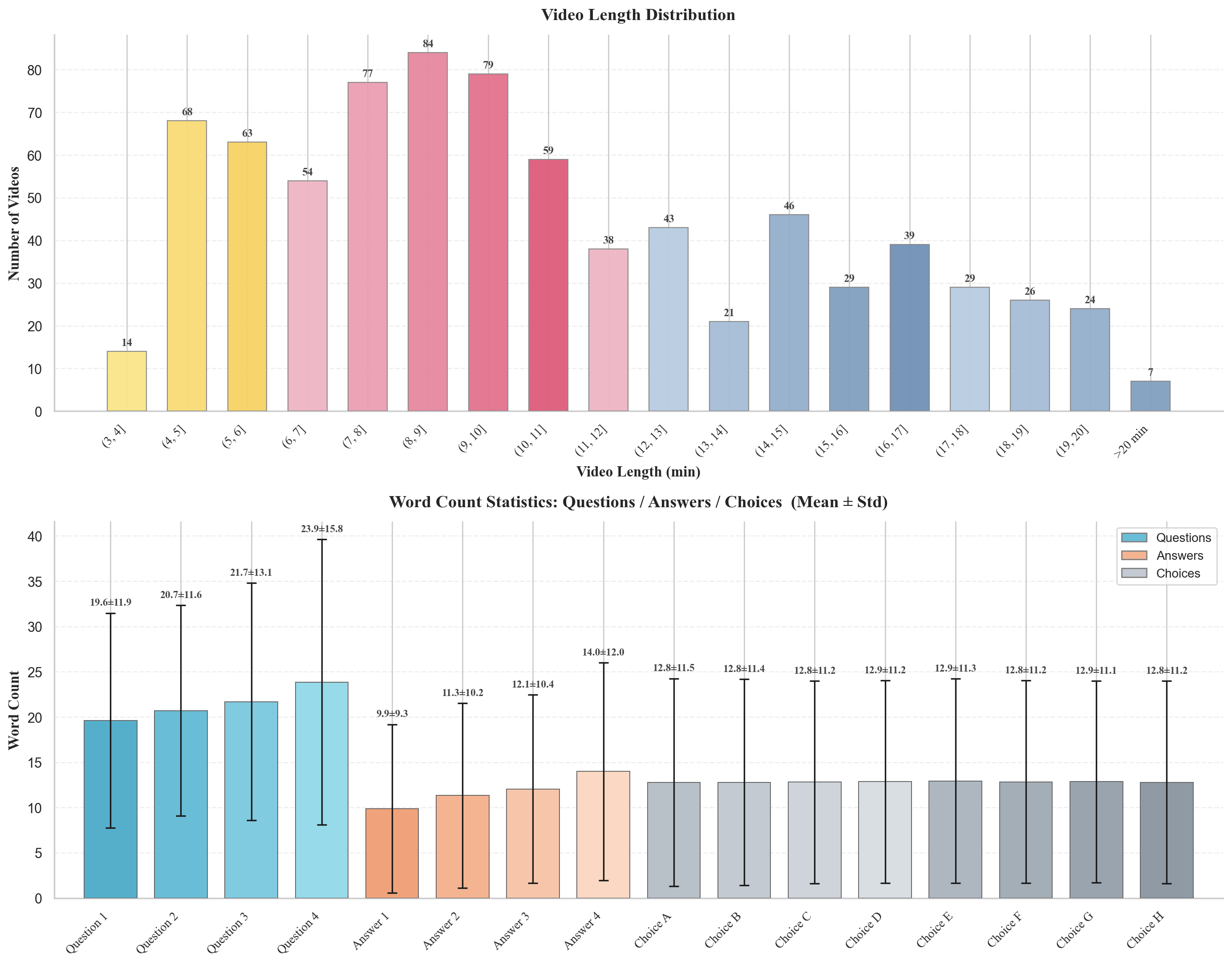
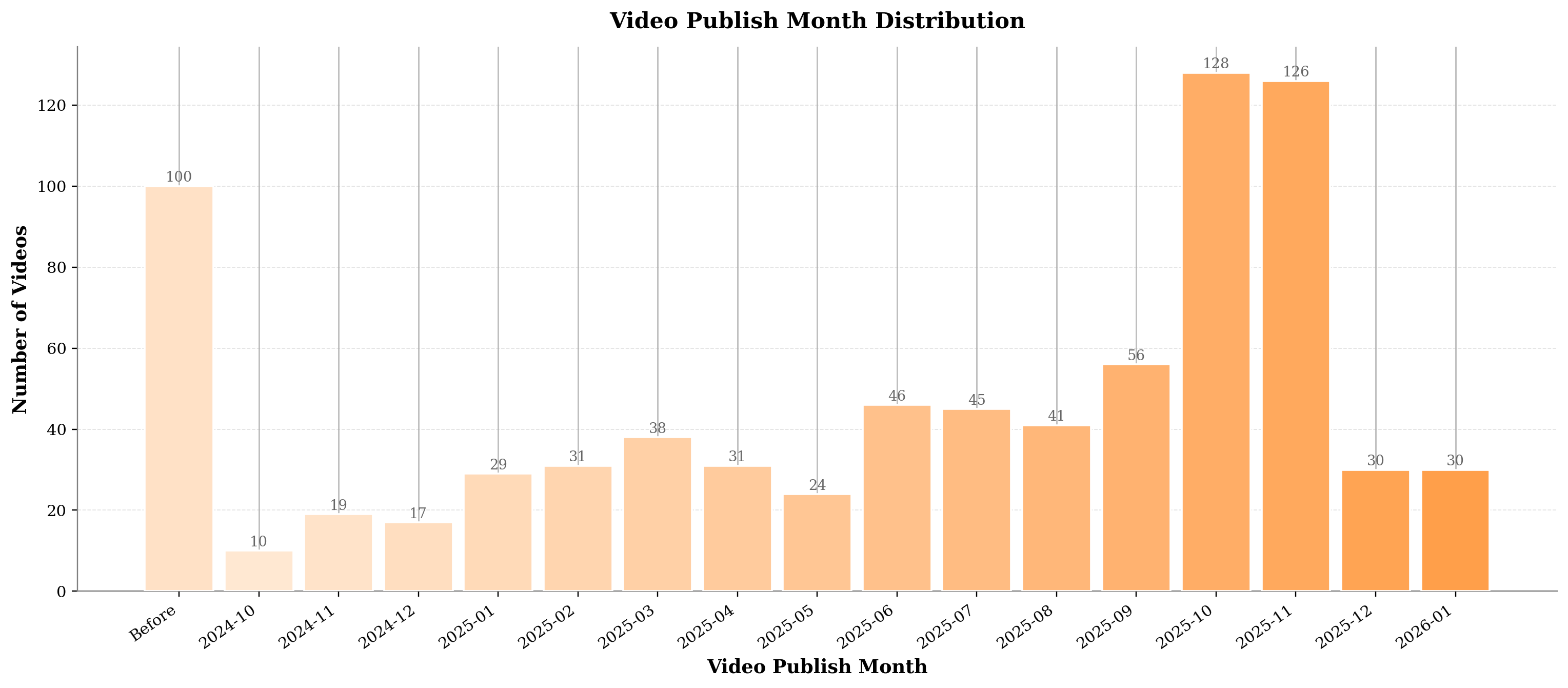
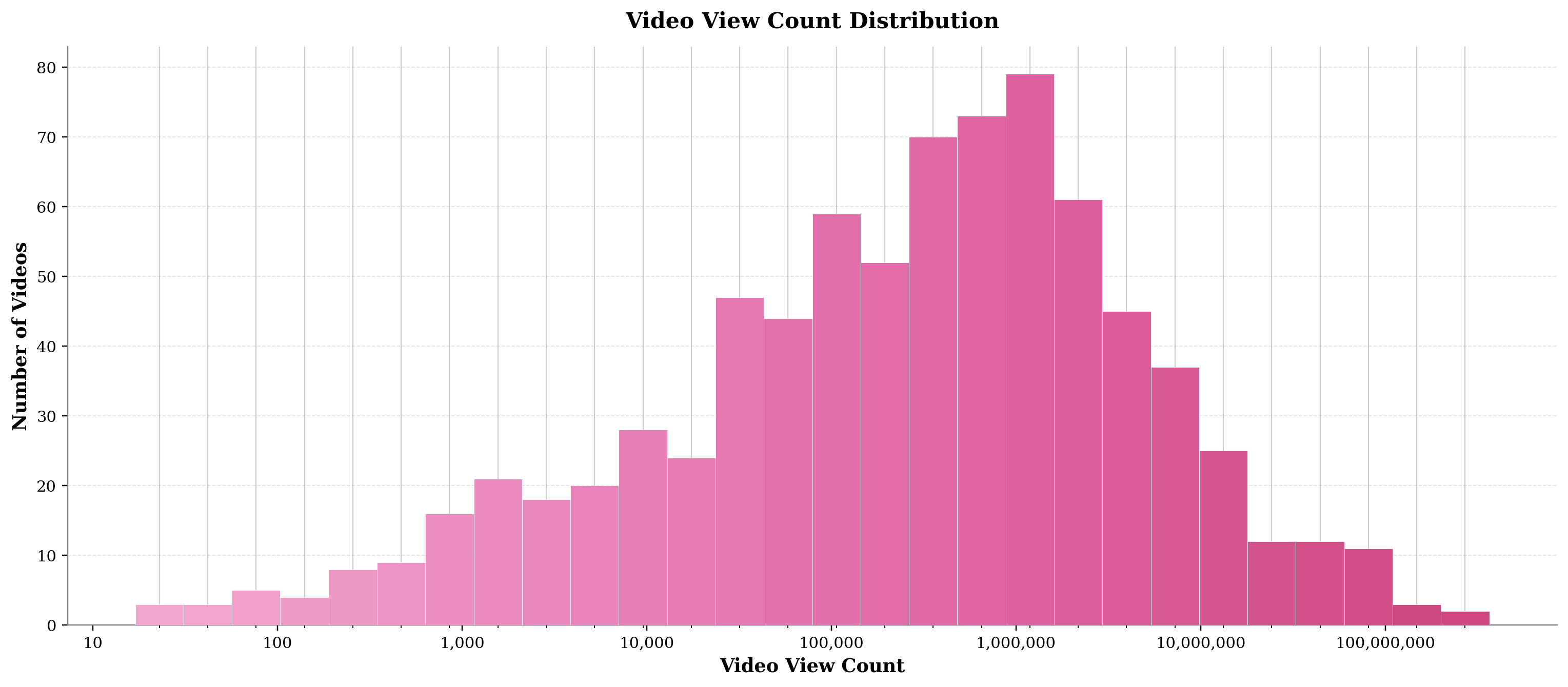
Figure 2: Video composition statistics—category diversity, length and word count, publication time, and view-count distribution—demonstrate the dataset’s recency, quality, and balance.
The adversarial distractor design and strict multimodal dependability (eliminating questions solvable by language priors alone) yield minimal baseline guessing probabilities and force true cross-modal comprehension. Moreover, the explicit progression from visual retrieval to causal reasoning in each group, as reflected in the increasing question and option lengths, precisely mirrors the real-world requirements of robust video understanding.
Evaluation Protocol and Metric Design
Unlike conventional per-question accuracy, Video-MME-v2 introduces a group-focused non-linear scoring regime. For consistency groups, quadratic suppression ensures that only high internal group agreement contributes meaningfully to the overall score; for coherence groups, a first-error truncation mechanism reflects the importance of unbroken reasoning chains (errors terminate any claim of logical validity, independent of subsequent lucky guesses). This design fundamentally shifts the evaluation from superficial pattern matching to robust, systematic assessment.
Experimental Results and Hierarchical Analysis
Extensive benchmarking covers both commercialization and open-source MLLMs, including proprietary models (Gemini-3-Pro, GPT-5, MiMo-v2-Omni) and the strongest open-source models (Qwen, Kimi, InternVL, LLaVA-Video). The results reveal several striking trends:
Thinking Mode and Reasoning Alignment
Enabling explicit “Thinking” modes—a collection of chain-of-thought or stepwise reasoning procedures—yields significant performance improvements primarily when textual information is available (with subtitles or ASR). Paradoxically, in visual-only settings, reasoning modes can degrade performance, suggesting that current architectures are disproportionately reliant on language signals for logical structuring and fail to support grounded visual-only reasoning chains in the absence of text.
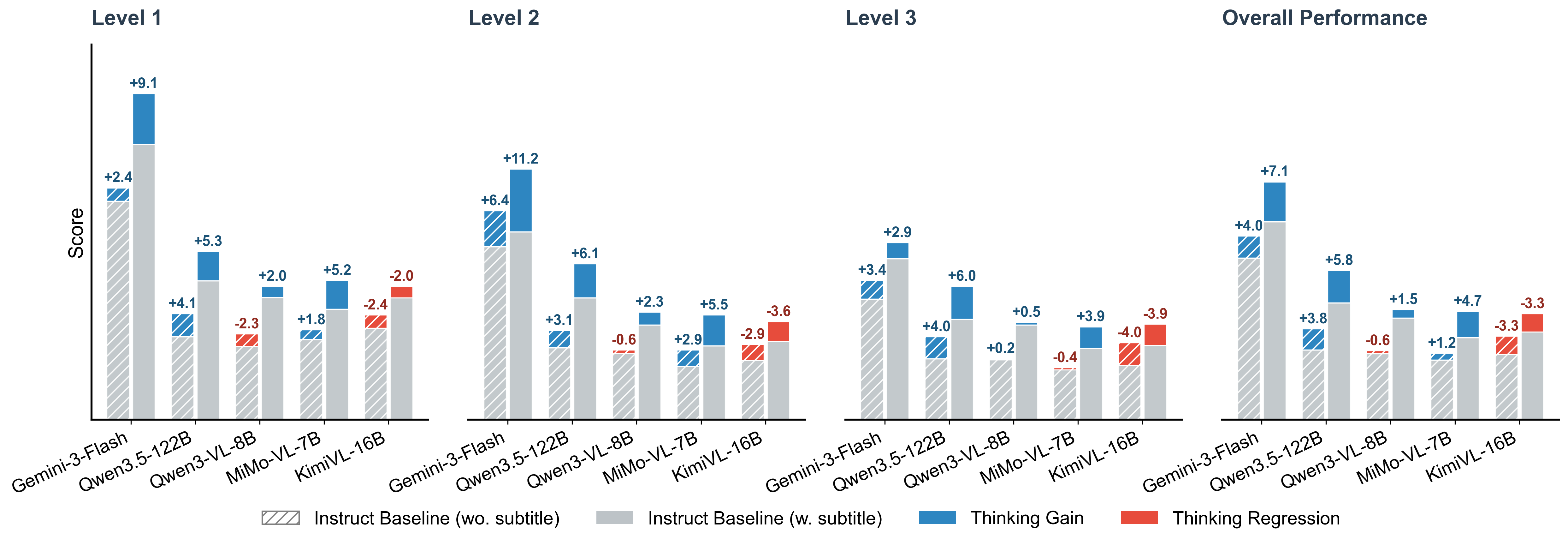
Figure 4: Thinking mode produces variable gains contingent on the presence of textual cues—highlighting over-reliance on subtitles and weakness in purely visual reasoning.
Multidimensional Capability Profiling
Capability radar analyses confirm that leading models achieve their strongest gains in settings demanding synergy across omni-modal aggregation, long-context temporal modeling, and deep reasoning, but all models saturate far below human benchmarks, particularly in action semantics, social dynamics, and physical world reasoning.
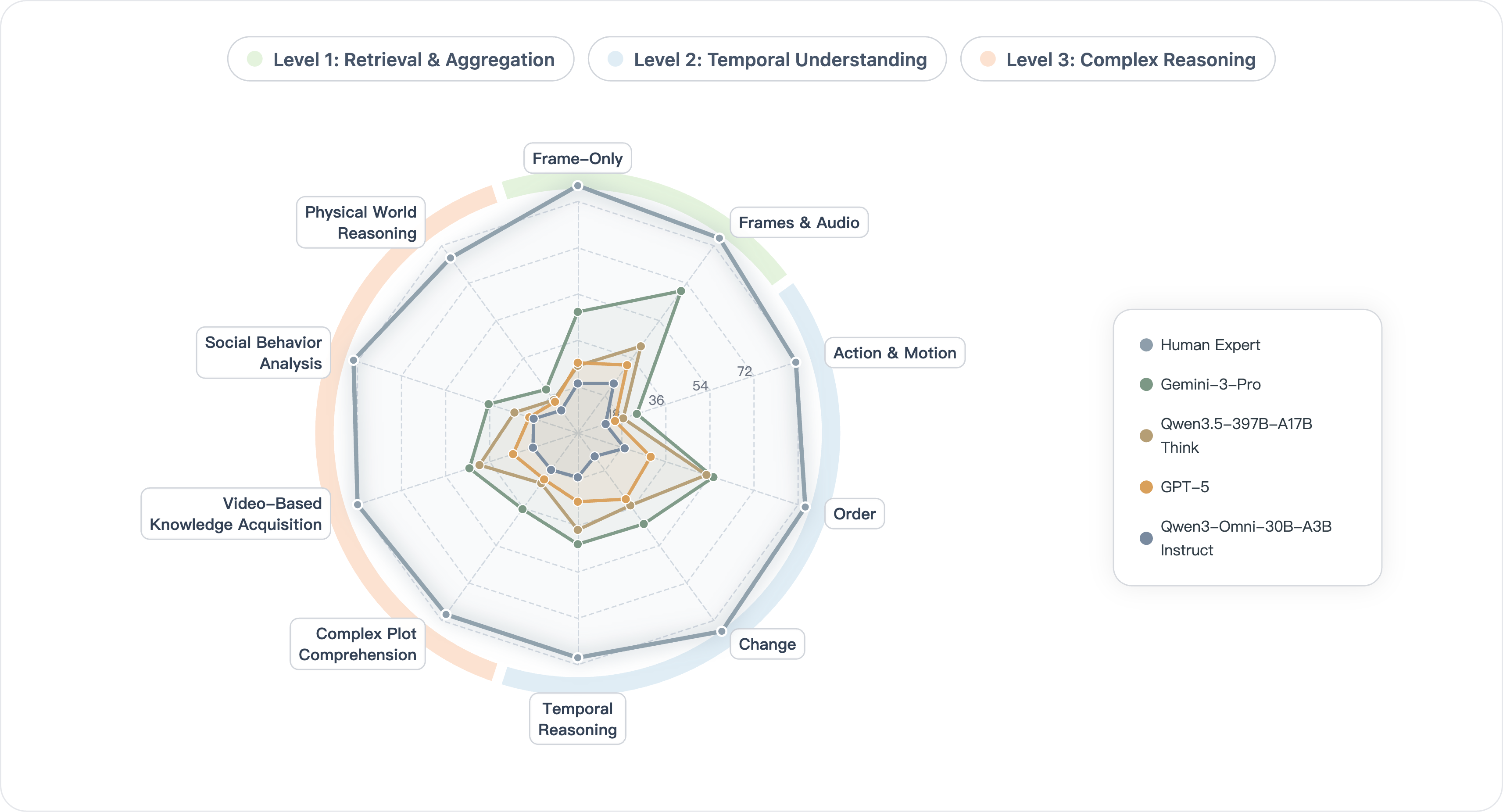
Figure 5: Radar plots trace performance deltas across Video-MME-v2 task dimensions; even comprehensive architectures display marked weaknesses in complex physical and social reasoning.
Implications and Future Directions
The empirical results forcefully demonstrate that inflated per-question accuracy benchmarks radically overestimate the true robustness and reliability of video MLLMs. The hierarchical, group-based, and non-linear structure of Video-MME-v2 exposes pervasive fragmentation and inconsistency in all current SOTA models, with serious implications for any deployment in high-stakes or open-world scenarios where both faithfulness and logical coherence are required.
For practical adoption and theoretical advancement, Video-MME-v2 provides a rigorous, discriminative testbed that incentivizes not only the scaling of parameters but—importantly—the systematic enhancement of both omni-modal perceptual grounding and robust, verifiable reasoning mechanisms. Advances in temporal grounding, adversarial robustness, and native cross-modal fusion are likely to be competitive differentiators. Furthermore, direct architectural and training innovations that mitigate overdependence on language priors while enhancing faithfulness of the internal reasoning process (e.g., through fine-grained intermediate supervision or explicit reasoning chain modeling) are critically needed.
Conclusion
Video-MME-v2 establishes a new standard for evaluating video MLLMs, focusing on robustness, consistency, and faithfulness across a comprehensive hierarchy of real-world capability demands. By shifting emphasis from isolated, per-question scores to group-based consistency and chain-of-thought coherence, this benchmark provides uniquely fine-grained insight into the strengths and limitations of current and future models. It is positioned to drive future development in the design, training, and adoption of video-centric multimodal reasoning architectures.