- The paper’s main contribution is its empirical analysis of how functional versus structural mental models affect user oversight and output quality in AI writing assistants.
- The study found that structural priming, while improving perceived ease of use, led to increased uncritical acceptance of erroneous suggestions, resulting in more grammatical errors.
- Methodologically, a between-subjects experiment with 48 participants measured behavioral metrics and subjective perceptions using mixed qualitative and quantitative approaches.
Influence of Mental Models on Oversight and Output in AI Writing Assistants
"From Use to Oversight: How Mental Models Influence User Behavior and Output in AI Writing Assistants" (2604.05166) offers a rigorous empirical investigation into the impact of user mental models—primed as either functional (focused on usage) or structural (focused on understanding inner mechanisms)—on user interaction, oversight, and outcomes when engaging with LLM-assisted writing systems. The work seeks to bridge gaps in understanding how conceptual framing affects trust, control, and oversight in contemporary AI-assisted creative tasks, where errors are subtle and harm is often non-catastrophic but still meaningful for authorship and quality.
Experimental Design and Methodology
The study utilized a between-subjects experiment (N=48), randomly assigning novice users to either functional or structural mental model priming via instructional videos. Participants then wrote cover letters with a modified CoAuthor LLM-based writing assistant, deliberately seeded with ungrammatical AI-suggested completions to expose and measure users’ oversight behaviors. Comprehensive behavioral logs, writing output, and subjective metrics were collected to address three principal research questions: control behaviors during writing, output quality, and perceptions of the system.

Figure 1: Experimental design and flow with priming, writing, and assessment stages, highlighting the mental model manipulation point.
The experimental platform (CoAuthor derivative) permitted on-demand sentence completions, guided suggestions via an "Instruction Box" for meta-prompting, and direct text editing.
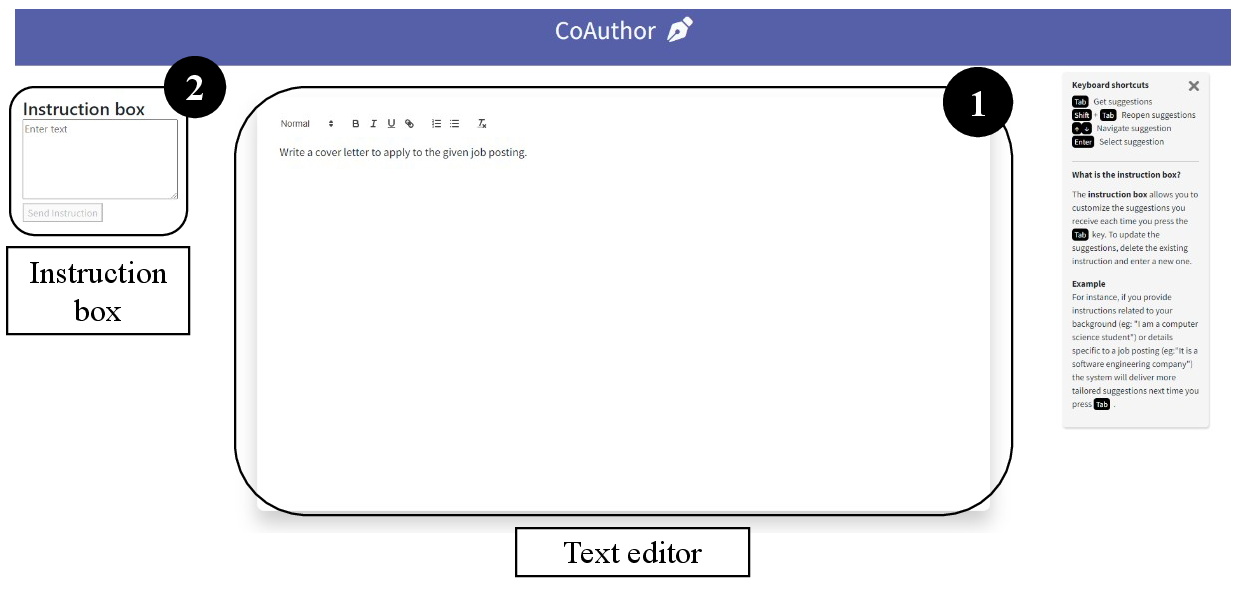
Figure 2: Screenshot of the AI writing assistant, showing core UI elements: text editor, instruction box, and usage summary.
Key Quantitative and Qualitative Results
Interaction Behaviors and Control: Null Effects of Mental Model Priming
The core expectation—grounded in system safety theory—that structural understanding would foster enhanced oversight and more deliberate interaction was not borne out in operational measures. Across metrics such as suggestion requests, acceptance ratios, post-acceptance edits, instruction use, and direct user contribution, there were no statistically significant differences between functional and structural groups.
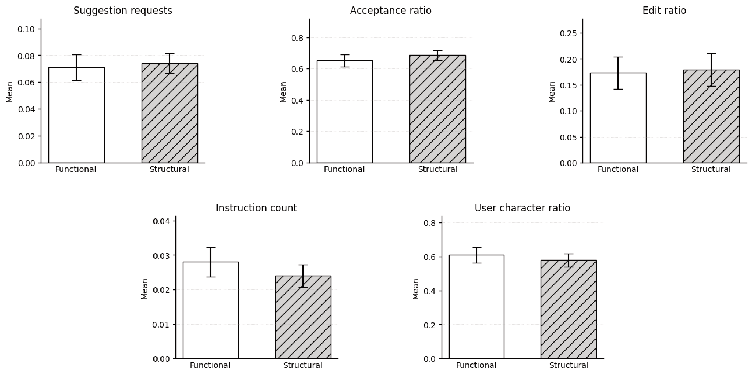
Figure 3: Behavioral metrics across experimental conditions, showing effect size distributions and error bars.
Qualitative data indicated that regardless of condition, users appropriated AI completions opportunistically, with acceptance strongly modulated by perceived relevance and style fit rather than understanding of system operation.
Output Quality: More System Understanding, More Errors
Contrary to hypotheses and prior work in safety-critical contexts, participants in the structural mental model condition produced final letters with significantly more grammatical errors (p<0.05, d=0.67). Exploratory behavioral analyses attribute this to higher rates of erroneous suggestion acceptance in the structural group, with error ratios and errors-per-word both elevated.
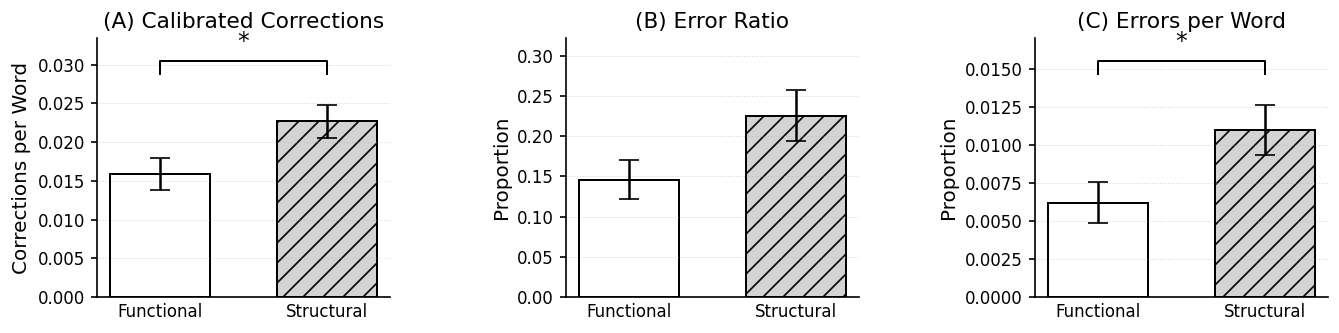
Figure 4: Automated grammar check corrections and error acceptance metrics, contrasting conditions; statistical significance indicated.
However, qualitative human rubric assessment of cover letter content (relevance, flow, tone/style) revealed no statistically significant differences between groups.
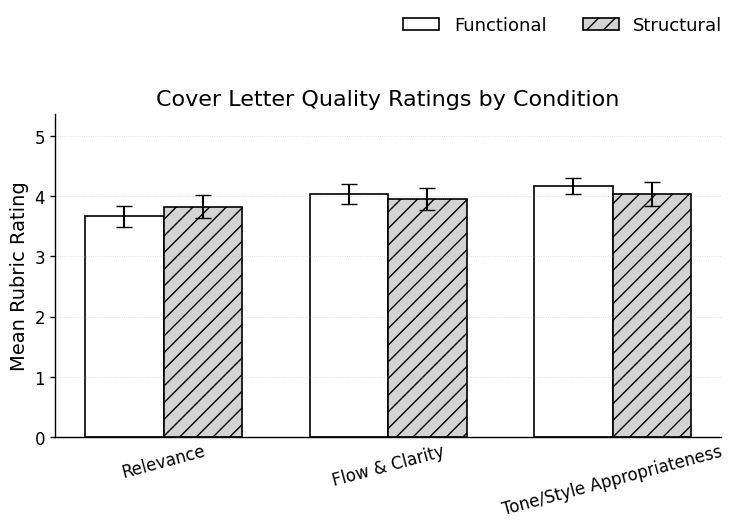
Figure 5: Rubric-based mean cover letter quality ratings across dimensions, showing high and statistically indistinguishable performance.
Subjective Experience: Ease of Use Modestly Improved, Agency and Ownership Invariant
On self-reported perceptions, only ease of use was reliably higher for the structural condition at uncorrected alpha level (d=0.60), but this effect did not survive Bonferroni correction. Usefulness, perceived quality, ownership, and perceived control showed no robust group differences. Both conditions reported high baseline agency and ownership.
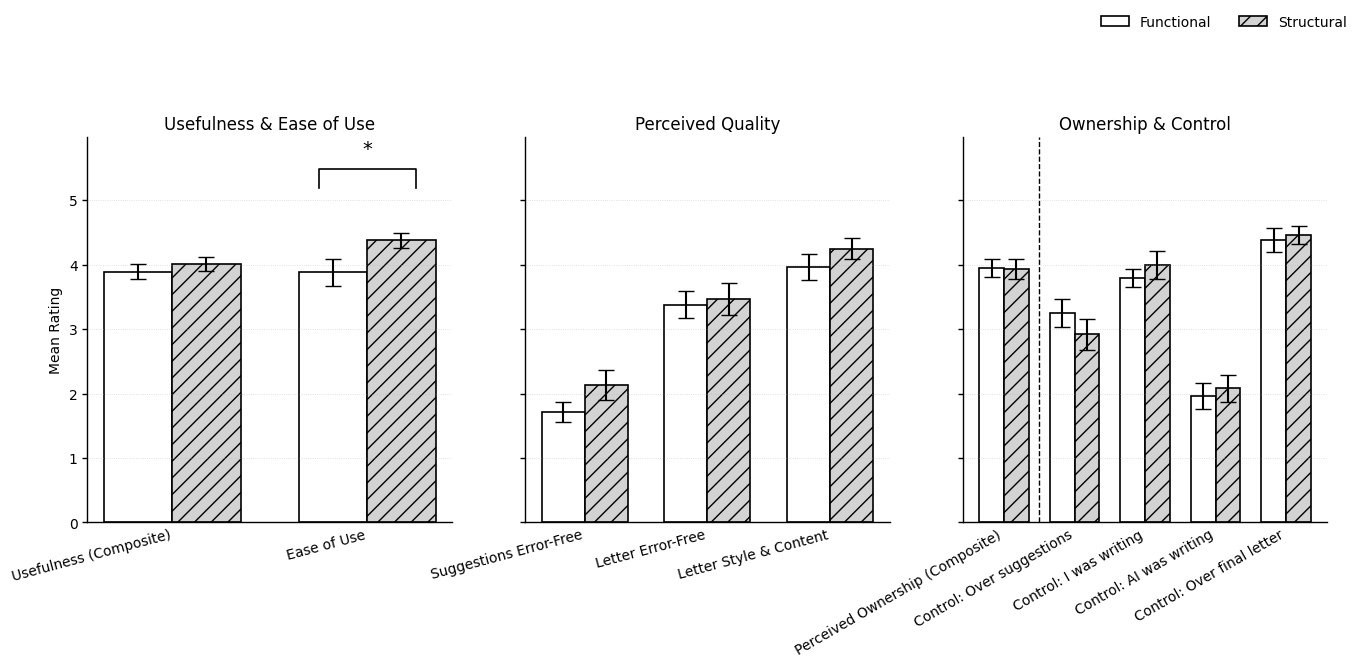
Figure 6: Self-reported ratings for usefulness, ease of use, quality, ownership, and control, with statistical indications.
Qualitative investigation indicated that agency and authorship were anchored primarily in interface affordances—on-demand control, editable suggestions, and non-autonomous system behaviors—rather than mental model sophistication.
Interpretation and Implications
Overtrust and the "Backfire" of Structural Explanations
The result that more thorough system understanding increased both ease of use and error-prone reliance reflects a form of overtrust or automation bias. Structural priming may serve as a competence cue, inadvertently promoting uncritical acceptance of suggestions—even when explicit errors exist. This constitutes an inversion of classic system safety theories (e.g., [Leveson2012-jp]), which posit richer mental models as the substrate of oversight and safe control.
Interface Affordances as Determinants of Agency
The prominence of interactive affordances in supporting perceived control and ownership, irrespective of system conceptualization, aligns with interaction design research emphasizing flexible, user-driven workflows as foundational for meaningful user agency in creative tasks [Kadoma2024-sv, Draxler2024-ut]. This finding problematizes the presumption that educational interventions alone will foster robust oversight in human-AI collaboration.
Recalibrating Mental Model Interventions
Given that mental models are dynamic and interaction-dependent [Holstein2025-xr], the observed limitations of static structural explanations suggest greater effectiveness for adaptive, feedback-rich system designs. Methods such as progressive disclosure, uncertainty indicators, and contextually-triggered explanations [Cortinas-Lorenzo2025-dx, Schafer2025-pr] merit further investigation for calibrating trust and mitigating automation bias in everyday writing support.
Broader Responsible AI System Design
The nuanced patterns revealed by this study reinforce a need for a shift from static “user education” to the design of interaction paradigms that foreground user oversight, reflection, and contestation. Instead of treating mental model alignment as a “once-and-done” onboarding problem, AI writing platforms—and, by extension, other generative co-creation tools—should emphasize design affordances that encourage scrutiny and iterative recalibration of reliance as system behaviors, user goals, and social contexts evolve [Vera_Liao2023-gv, Swaroop2025-ie].
Conclusion
This work demonstrates that structural mental model priming in AI writing assistants can unintentionally decrease critical oversight and degrade surface-level writing quality, even while increasing perceived ease of use. In contrast, moment-to-moment authorship, agency, and satisfaction are driven primarily by granular interaction affordances rather than depth of system understanding. These findings caution against uncritical application of system safety theory from high-stakes domains to AI-mediated creative work, highlighting the risk of overtrust, the potential for behavioral backfire from system explanations, and the primacy of interface design in supporting meaningful user control and oversight.
Future research should focus on adaptive, context-aware scaffolding strategies and interrogate the transferability of safety frameworks to broad generative AI deployments. A nuanced, empirically grounded theory of oversight in human-AI co-creation is necessary to responsibly shape the trajectory of AI-enhanced writing and similar systems.