- The paper demonstrates that token-to-token differences in contextual embeddings exhibit a robust power-law scaling with an exponent near 5/3 across languages and models.
- It uses spectral density analysis on BERT and GPT outputs, showing that context and sequential token order are essential for producing this turbulence-analogous scaling, unlike static embeddings.
- The study highlights that deeper transformer layers progressively develop self-similar, scale-free structures, offering a benchmark for evaluating contextual integration in language models.
Turbulence-like $5/3$ Spectral Scaling in Contextual Representations of Language
Introduction
This paper addresses the statistical regularities underpinning natural language as captured by neural LLMs, proposing a quantitative, model-agnostic benchmark that characterizes multiscale organization in contextual embeddings. The authors investigate whether token-level representations produced by transformer-based architectures, when analyzed spectrally, display reproducible and interpretable scaling laws analogous to those seen in complex physical systems, most notably in the turbulence literature.
The central finding is that the embedding-step signal—the token-to-token difference in contextual vector representations—exhibits robust power-law scaling in its power spectral density (PSD) with an exponent remarkably close to $5/3$ across languages, domains, and generations (human or AI). This scaling is absent in static embeddings (Word2Vec, GloVe) and is disrupted by shuffling token order, confirming dependence on contextual and sequential linguistic organization.
Methodological Framework
The analysis leverages contextual embeddings from BERT and GPT-style transformers across four languages (Chinese, English, German, Japanese). The embedding-step signal is constructed by differencing the contextual embedding vectors across tokens (v(t)=x(t+1)−x(t)). The PSD is computed by averaging over embedding dimensions and document samples, followed by normalization with respect to variance for universal comparison.
Critical control experiments include:
- Comparison to static word embeddings to isolate the contribution of context-dependence.
- Order randomization to test the necessity of sequential information flow.
- Layer-wise analysis across transformer layers to describe the evolution of scaling during contextual integration.
Main Results
Spectral Analysis of Embedding-Step Sequences
Across all human and AI-generated corpora, languages, and architectures, contextual embeddings show a pronounced power-law region in their spectral density with a slope close to +5/3:
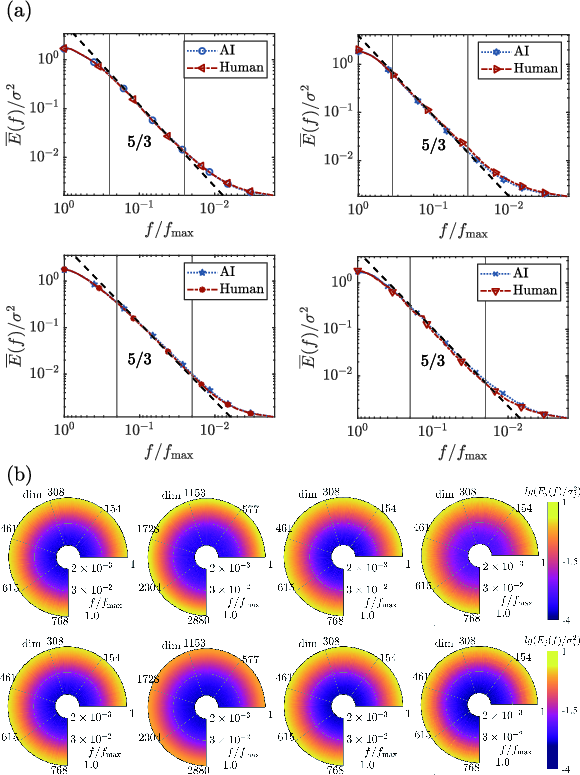
Figure 1: Power spectra of contextual embedding-step sequences across languages and models, all normalized and highlighting the +5/3 scaling slope.
The observed scaling holds pervasively across embedding dimensions (as evidenced by the polar heatmaps), contrasting with a small subset-driven effect. Over 90% of embedding dimensions present exponents within ±10% of $5/3$, supporting the statistical robustness and embedding-space universality of the effect.
Controls: Static Embeddings and Sequence Randomization
When contextual embeddings are replaced with static ones, the spectral scaling disappears. Further, randomizing the sequence of token representations also abolishes the $5/3$ regime, producing exponents that diverge from this characteristic value. These results tightly localize the $5/3$ scaling as a signature of context-sensitive, sequential models rather than an epiphenomenon of lexicon or embedding vector statistics.
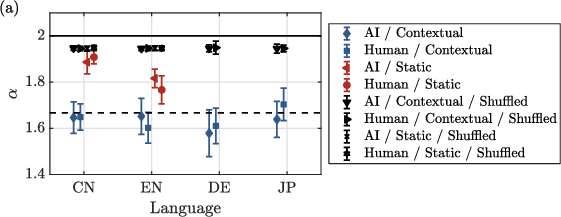
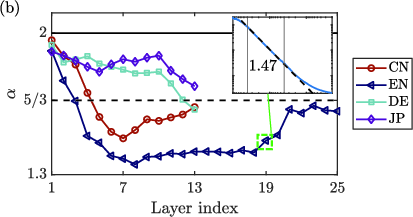
Figure 2: (a) Summary of scaling exponents across languages and models; static embeddings and shuffled contexts break the $5/3$ regime. (b) Exponent evolution across transformer layers, with approach toward $5/3$0 evident in deeper contextual processing.
By analyzing embeddings extracted from individual transformer layers, the $5/3$1 scaling is revealed to intensify in deeper model layers—where contextual integration is greatest. Early layers produce flatter or even non-monotonic exponent progressions, while layers nearer the output converge towards the canonical $5/3$2 exponent regardless of language or model architecture. This suggests a progressive emergence of self-similar, scale-free structure as contextual information propagates through the network hierarchy.
Implications
Theoretical
The persistent emergence of a turbulence-analogous $5/3$3 scaling law in token sequence embeddings implies that state-of-the-art LLM architectures capture long-range dependencies and cross-scale semantic coupling in a self-similar, statistically invariant manner. The analogy to the Kolmogorov inertial range spectrum, a cornerstone of physical turbulence phenomenology, suggests that information aggregation in LLMs, like energy in turbulence, lacks a single characteristic scale and instead propagates through a hierarchy of linguistic contexts. The observation that the law emerges only in deep, contextualized architectures highlights the presence of hierarchical, multi-scale processing, absent in purely lexical representations.
Practical
The universality and robustness of the observed scaling provide a task-agnostic, model-agnostic diagnostic of contextual integration and representational organization in sequential models. Such a spectral fingerprint may serve diverse practical purposes:
- Model evaluation: Quantitative comparison across models, layers, datasets, and languages independent of downstream task performance.
- Fingerprinting and anomaly detection: Systematic identification of models or corpora that deviate from canonical contextual language structure (e.g., for model auditing or red-teaming).
- Benchmarking multi-scale structure: Facilitates principled ablation and probing experiments on linguistic or semantic organization in neural representations.
Prospects for Future Research
This result motivates multiple lines of inquiry:
- Investigating whether similar spectral signatures exist in non-linguistic sequence models (e.g., protein families, code, music).
- Theorizing or mechanistically modeling the emergence of $5/3$4 scaling based on transformer attention dynamics or corpus-level statistics.
- Examining whether deviations from $5/3$5 scaling (by layer, domain, language, or fine-tuning regime) correspond to functional or interpretability modifications.
- Extending the analysis to non-transformer architectures, various pre-training objectives, and emerging classes of multi-modal models.
Conclusion
The paper systematically documents a robust, turbulence-like $5/3$6 spectral law in the sequence of contextual embedding differences across diverse languages, domains, and model architectures. This phenomenon is a direct function of context-dependent, sequential information integration—becoming most pronounced in deep transformer layers. The result not only establishes a universal empirical regularity in learned language representations but also offers a practical, model-agnostic benchmark for evaluating and understanding multiscale structure in neural LLMs.