Symmetry in language statistics shapes the geometry of model representations
Abstract: Although learned representations underlie neural networks' success, their fundamental properties remain poorly understood. A striking example is the emergence of simple geometric structures in LLM representations: for example, calendar months organize into a circle, years form a smooth one-dimensional manifold, and cities' latitudes and longitudes can be decoded by a linear probe. We show that the statistics of language exhibit a translation symmetry -- e.g., the co-occurrence probability of two months depends only on the time interval between them -- and we prove that the latter governs the aforementioned geometric structures in high-dimensional word embedding models. Moreover, we find that these structures persist even when the co-occurrence statistics are strongly perturbed (for example, by removing all sentences in which two months appear together) and at moderate embedding dimension. We show that this robustness naturally emerges if the co-occurrence statistics are collectively controlled by an underlying continuous latent variable. We empirically validate this theoretical framework in word embedding models, text embedding models, and LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
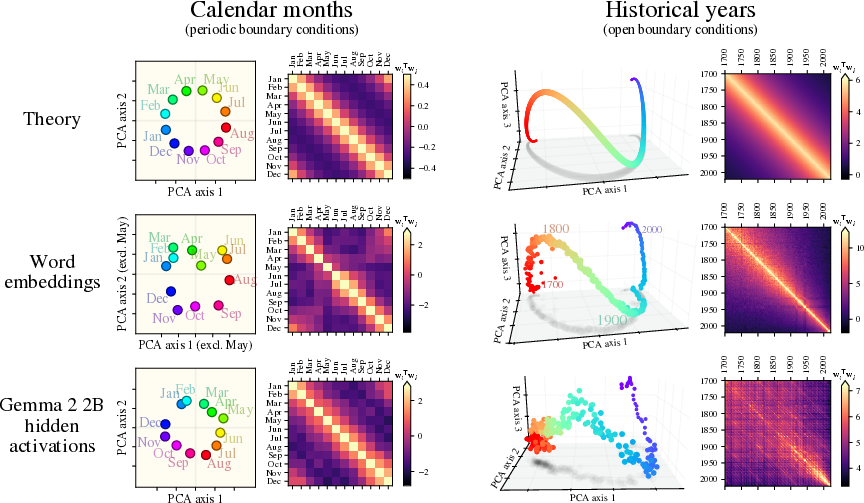
This paper asks a simple question with a big answer: Why do LLMs (like chatbots) arrange certain ideas in neat shapes inside their “thinking space”? For example, words for the months sit around a circle, years line up along a wavy line, and cities arrange so their latitude and longitude can be read off with a simple rule. The authors show that these shapes are not accidents. They come from a basic pattern in text: words that are closer in time or space tend to appear together more often. This “symmetry” in how words co-occur shapes the geometry of what models learn.
What questions did the paper ask?
The paper focuses on three main questions:
- Why do concepts that repeat (like months or colors) form circles in a model’s internal space?
- Why do ordered concepts (like years or numbers) form one-dimensional paths with small “ripples”?
- Why can a simple linear rule read off coordinates (like when a model predicts a city’s latitude and longitude) from its representations?
How did they study it?
Key ideas in everyday language
- Co-occurrence: Count how often two words appear near each other in text. For example, “April” and “May” co-occur more than “April” and “November.”
- Translation symmetry: The co-occurrence of two months depends mostly on how far apart they are in the calendar, not on which specific months they are. In other words, “April vs. May” looks a lot like “August vs. September” because both are one month apart.
- Embedding: Each word gets turned into a vector (a list of numbers). Similar words end up near each other in this space.
- PCA (Principal Component Analysis): A way to find the main directions in the data, like turning a messy 3D object so you see its longest, most important stretch first.
- Fourier/sine waves: Any smooth repeating pattern can be built by adding up simple waves. Think of music: a note is made of pure tones (sine waves) layered together.
The simple model they analyze
- Step 1: Start from counts of how often pairs of words appear together.
- Step 2: Assume a symmetry: for words arranged along a hidden line or circle (time of year, timeline, or map), co-occurrence depends mainly on distance along that hidden shape.
- Step 3: Do math to show that, under this symmetry, the best directions in the word space are sinusoids (sine and cosine waves). That means:
- For periodic concepts (like months), embeddings trace a circle when you look at the top two directions.
- For ordered but non-repeating concepts (like years), embeddings trace an open curve that looks like a line with gentle ripples.
- In 2D (like geography), the top directions change slowly over space, similar to smooth waves across a map.
Testing the idea
- The authors check their theory on:
- Word embeddings trained on Wikipedia (e.g., word2vec-style models),
- Sentence/text embedding models,
- LLMs.
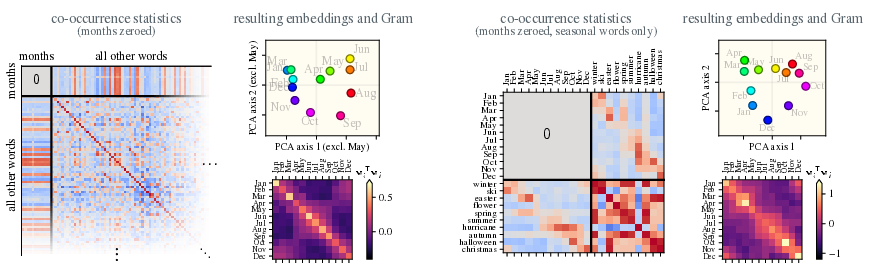
- They also run a surprising test: even if they remove all sentences where two months appear together, the model still arranges the months in a circle. Why? Because many other “seasonal” words (like “ski” or “beach”) still link months together through the shared idea of time of year. This hidden shared factor is called a latent variable.
What did they find and why is it important?
Here are the main results, along with their importance:
- Circular geometry for cycles: Months, days of the week, and color hues form circles in the embedding space. This is predicted by the symmetry and the math of sine and cosine waves. It explains why models can handle questions like “Five months after November is…”
- Wavy lines for ordered sequences: Years or number lines form a one-dimensional path with “ripples.” These ripples are just higher-frequency sine waves added on top of the main trend.
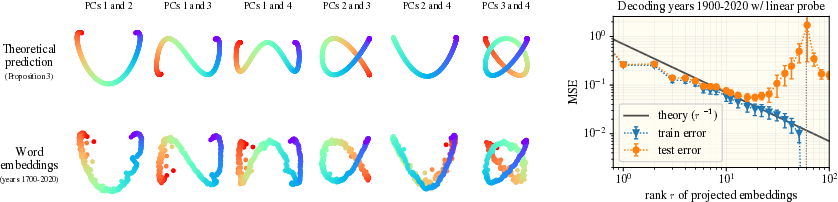
- Linear decoding of coordinates: A simple linear rule can read out things like latitude/longitude or year from embeddings. The theory predicts how the error shrinks as you use more principal components: adding more components gives finer “resolution,” especially in higher dimensions.
- Robustness to missing data: Even if you remove all direct month–month co-occurrences from the data, the circle still appears at moderate embedding sizes. Reason: many other words are seasonal, so the “season” signal is spread across the whole vocabulary. This collective effect makes the geometry sturdy.
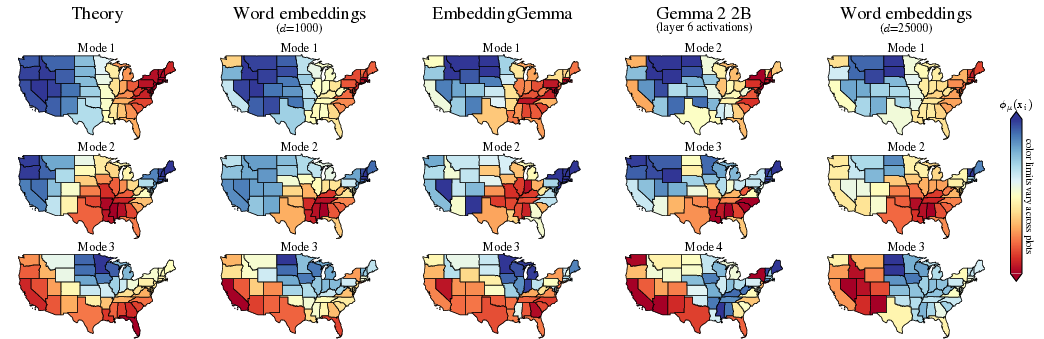
- Geography generalizes: For US states, the top embedding directions change smoothly across space, consistent with the “distance controls co-occurrence” idea.
Why it matters: These results show that very simple, low-level statistics in text—who appears with whom, and how often—are enough to explain the neat shapes we see inside powerful LLMs. That helps us predict and understand model behavior, not just observe it.
Implications and potential impact
- Better understanding of models: If geometry comes from simple co-occurrence symmetry, we can predict and interpret model internals more reliably.
- Practical tools: Knowing that coordinates can be decoded linearly suggests efficient ways to build timelines, maps, or modular arithmetic tools from embeddings.
- Robust design: Because these shapes are collective and robust, models can still learn useful structure even when data are noisy or some pairs are missing.
- Data and probing strategies: We can use symmetry-aware probes or training data designs to encourage desired structures in embeddings.
- Beyond language: Similar ideas may explain brain maps of space (like grid cells), where smooth spatial patterns can arise from combining a few wave-like signals.
In short, the paper shows that the “shapes” inside LLMs aren’t mysterious. They’re the natural result of a symmetry in how words appear together, and this symmetry pushes models to learn wave-like features that form circles, lines, and smooth maps.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored, framed to be actionable for future research.
- Formalizing deep-model theory: Derive when and how pairwise co-occurrence symmetries provably propagate through multi-layer transformer training, connecting PMI/eigenmodes to internal representations learned under attention, residuals, and nonlinearity.
- Higher-order statistics: Quantify how tri- and higher-gram dependencies perturb or refine the Fourier/Lissajous geometry; provide bounds or regimes where pairwise symmetry dominates representation structure.
- Kernel estimation from data: Develop procedures to infer latent coordinates and the co-occurrence kernel C nonparametrically from finite corpora (with uncertainty), and systematically test translation symmetry across domains and languages.
- Indefinite co-occurrence matrices: Provide a full treatment when M* (or PMI) is indefinite, including how negative eigenvalues, centering, and sign-indefinite spectra affect predicted manifolds and linear decoding.
- Finite embedding dimension theory: Predict which modes survive when d ≪ rank(M*); quantify reconstruction error and robustness as a function of spectral truncation and spectral gaps.
- Beyond exponential kernels: Identify empirical conditions under which exponential vs Gaussian/Matérn/power-law kernels best fit language; analyze how different kernels change mode amplitudes, frequency quantization, and manifold shape.
- Windowing and objective dependence: Systematically study how co-occurrence window size, subsampling, negative sampling distributions, and objective choice (SGNS, GloVe, CBOW) alter the inferred kernel and resulting geometry.
- Non-lattice and irregular sampling: Provide analytic predictions (not just numerics) for unevenly spaced items and irregular point clouds on 1D/2D manifolds; connect to kernel integral operators and graph Laplacians.
- 2D and non-Euclidean domains: Extend theory to 2D/3D with realistic domain geometry (e.g., spherical Earth, irregular boundaries); derive eigenfunctions for spherical or geodesic metrics and predict lat/long decodability.
- Interacting continuous variables: Build theory for multiple simultaneous continuous factors (e.g., time and geography), including identifiability, disentanglement, and how entangled modes appear in PCA.
- Mixed continuous–discrete attributes: Extend the joint latent model to multiple binary/semantic attributes plus continuous variables; characterize when circular/linear modes remain recoverable and how they mix.
- Polysemy and contextualization: Model how multi-sense tokens break translation symmetry; extend predictions to contextual embeddings and quantify how disambiguating prompts reshape manifolds through layers.
- Training dynamics and sample complexity: Characterize the emergence rates of low-frequency modes under finite data and optimization; provide finite-sample error bars tied to spectral properties of M*.
- Generalization of linear probes: Tighten theory for test error (not only training error), including lower bounds and the impact of noisy/biased coordinates, finite training points, and model misspecification.
- Robustness to perturbations: Theoretically bound how many (and which) co-occurrence entries can be ablated before geometry deteriorates; relate thresholds to eigenvalue gaps and helper-word set size.
- Helper-word selection algorithms: Devise procedures (with guarantees) to actively select minimal helper sets that reconstruct ordering/geometry under ablated co-occurrences; compare greedy vs spectral criteria.
- Cross-lingual and cross-domain validation: Test symmetry strength, kernel form, and geometry across languages (morphology, scripts), domains (news, fiction, scientific text), and tokenization schemes (BPE vs words).
- Gauge fixing and calibration: Establish practical methods to fix latent coordinate gauge freedoms (rotation/scale) and calibrate absolute units (e.g., years, degrees latitude) with uncertainty quantification.
- Downstream causal role: Run controlled ablations of specific spectral modes to quantify their causal contribution to tasks (e.g., modular arithmetic, temporal reasoning, mapping), not just correlational decoding.
- Impact of finetuning stages: Determine whether instruction tuning, RLHF, or domain-specific finetuning preserve, distort, or amplify symmetry-induced manifolds and under what conditions.
- Boundary conditions and non-exponential open BC: For open intervals beyond the exponential kernel, characterize boundary-induced deviations from sinusoids and their consequences for geometry and decoding.
- Data bias and nonstationarity: Measure how seasonal publication cycles, historical skew, and domain drift bias the inferred kernel; develop corrections/diagnostics for nonstationary corpora.
- Token granularity and phrases: Analyze how subword segmentation and multiword expressions affect symmetry and geometry; extend theory to phrase/entity embeddings and composition rules.
- Neuroscience link, testable predictions: Translate the spectral-mode framework into concrete neural predictions (e.g., interference patterns, frequency ratios) and design experiments to compare with grid/place cell data.
Glossary
- Circulant matrix: A square matrix where each row is a cyclic shift of the previous row; diagonalized by Fourier modes. "Circulant matrices are diagonalized by discrete Fourier modes"
- Compact SVD: The singular value decomposition restricted to nonzero singular values/vectors. "Let its compact SVD be $\mW_\sys= \mPhi\mLambda^{1/2}\mU^\top$."
- Convolution kernel: A function specifying pairwise interactions that depend only on distance, forming a translation-invariant matrix. "Thus, the co-occurrence convolution kernel is simply a reparameterization of ."
- Davis-Kahan theorem: A perturbation bound that controls changes in eigenvectors under matrix perturbations. "Using the Weyl or Davis-Kahan theorem, we obtain that the top eigenvectors and thus the word embeddings are not perturbed in this limit."
- Discrete Fourier transform (DFT): A transformation mapping a discrete function to its frequency components. "Define $\tilde m(\vk)$ to be the discrete Fourier transform of $m(\vx)\defn C(\mathrm{dist}(\vx, \bm{0}))$."
- Eigendecomposition: Factorization of a matrix into its eigenvectors and eigenvalues. "In terms of the eigendecomposition $\Mstar=\mPhi\mLambda^\star\mPhi^\top$, the learned embeddings are"
- Fourier modes: Sinusoidal basis functions corresponding to specific frequencies used to diagonalize translation-invariant structures. "the top principal components encode the slowest Fourier modes."
- Gram matrix: A matrix of inner products between representation vectors, encoding pairwise similarities. "and we show the representation vectors' Gram matrix."
- Isotropic rescaling: Uniform scaling in all directions that preserves directional structure. "and isotropic rescaling induces only a scalar reparameterization of ."
- Kronecker structure: A structured matrix expressible via Kronecker products, enabling separable interactions. "can be understood as a consequence of Kronecker structure in $\Mstar$."
- Latent variable (continuous): An unobserved continuous factor that governs observed statistics. "We show that this robustness naturally emerges if the co-occurrence statistics are collectively controlled by an underlying continuous latent variable."
- Lattice (semantic lattice): A regularly spaced set of points representing discrete positions on a semantic continuum. "the words then occupy sites on a latent semantic lattice."
- Lissajous curves: Parametric curves formed by combining orthogonal sinusoids with possibly different frequencies and phases. "In \cref{fig:fig2} (left), we empirically confirm that Lissajous curves arise in the representation geometry of Wikipedia word embeddings."
- Linear probe: A simple linear model trained atop fixed representations to decode target variables. "we consider the coordinate decoding task in which one aims to predict $\vx_i$ from the representation vector $\vw_i$ using a linear probe."
- Mean-centering matrix: A projection that subtracts the mean to center data. "where $\mP=\mI- |\sys|^{-1}\bm 1\T{\bm 1}$ is the mean-centering matrix."
- Open boundary conditions (open BC): Boundary settings where the domain does not wrap around; edges are distinct. "We now turn to lattices with open BC, where the corresponding submatrix of $\Mstar$ is Toeplitz."
- Periodic boundary conditions (periodic BC): Boundary settings where the domain wraps around so endpoints are identified. "We denote by the dimension of that sematic continuum, and characterize it by “periodic BC” if it displays periodic boundary conditions and by “open BC” otherwise."
- Pointwise Mutual Information (PMI): A measure of association between two tokens based on their joint versus independent probabilities. "approximately equal to the pointwise mutual information (PMI) matrix"
- Principal Component Analysis (PCA): A technique that projects data onto directions of maximal variance. "it is sufficient to specify their PCA coordinates."
- Quantization condition: Constraints determining allowed wavenumbers/frequencies under boundary conditions. "the wavenumbers obey the self-consistent quantization condition"
- Toeplitz matrix: A matrix with constant values along each diagonal, arising from translation invariance with open boundaries. "the corresponding submatrix of $\Mstar$ is Toeplitz."
- Translation symmetry: Invariance of statistics under shifts, so co-occurrence depends only on relative distance. "We show that the statistics of language exhibit a translation symmetry---e.g., the co-occurrence probability of two months depends only on the time interval between them---"
- Wavenumber: The spatial frequency parameter of sinusoidal modes. "the wavenumbers obey the self-consistent quantization condition"
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s findings on translation symmetry in language statistics and their induced Fourier/Lissajous geometries in model representations.
- Symmetry-based embedding QA and interpretability
- Sectors: software, AI/ML tooling, academia
- What: Build automated checks that verify whether embeddings/LLM hidden states for cyclical and continuous concepts (e.g., months, years, hue, geography) form predicted circular/1D manifold structures and Lissajous curves; surface principal modes and their frequencies; compare Gram matrices against symmetry-derived kernels.
- Tools/workflows: “SymmetryProbe” library that (i) estimates PMI/M* from a corpus, (ii) computes PCA of target token sets, (iii) visualizes manifold geometry and Lissajous projections, (iv) flags deviations from translation symmetry.
- Assumptions/dependencies: Target concept follows approximate translation symmetry; access to embeddings or hidden states; sufficient sample size for stable co-occurrence estimation.
- Linear coordinate decoding for analytics and product features
- Sectors: search/retrieval, geospatial, media, finance, healthcare
- What: Use small linear probes to decode coordinates (time, latitude/longitude, ordinal scales) from embeddings for: (a) timeline extraction from narratives, (b) geolocation inference from place mentions, (c) seasonal topic timelines, (d) cyclical feature visualization in customer feedback.
- Tools/workflows: Add a “spatiotemporal-decoder” module to vector databases and embedding platforms; surface decoded coordinates as filters.
- Assumptions/dependencies: Top principal components capture slow Fourier modes; probe dimension r chosen per error scaling r-1/D; polysemy and context effects managed or filtered.
- Retrieval and navigation enhanced by manifold structure
- Sectors: enterprise search, education, news/media, travel
- What: Improve semantic retrieval by indexing items (e.g., events, articles, locations) along decoded continuum coordinates; enable “map view” or “timeline view”; exploit circular distances for cyclical queries (e.g., “content similar to November”).
- Tools/workflows: Manifold-aware distance metrics and filters (e.g., angular distance for months, geodesic proximity for places).
- Assumptions/dependencies: Decoded coordinates are accurate and stable; content adheres to underlying continuous latent variable.
- Seasonality mining from text at scale
- Sectors: retail, finance, advertising, healthcare/epidemiology, operations
- What: Detect words/entities with strong seasonal signatures using the spectral structure (top Fourier modes); use to plan campaigns, staffing, inventory, or flu-season alerts.
- Tools/workflows: “Seasonality miner” pipeline estimating per-entity amplitudes/phases; dashboards showing annual cycles; alerts when patterns drift.
- Assumptions/dependencies: Periodic latent factor governs many tokens; corpus reflects the relevant market/region; seasonal signals not dominated by confounders.
- Dataset curation and anomaly detection via symmetry tests
- Sectors: data engineering, compliance, trust & safety
- What: Identify anomalies or synthetic injections that break expected translation symmetry (e.g., month co-occurrences misaligned with calendar structure); flag potential data corruption or targeted manipulation.
- Tools/workflows: Off-the-shelf spectral tests comparing empirical co-occurrence kernels to symmetric templates; outlier detection on eigenmodes.
- Assumptions/dependencies: Expected symmetry is known for the concept set; enough coverage to estimate co-occurrences.
- Privacy-aware data redaction impact assessment
- Sectors: compliance, privacy, MLOps
- What: Evaluate whether redacting sensitive co-occurrences (e.g., month–month or location–location pairs) preserves utility due to collective latent structure; quantify representational robustness before/after redaction.
- Tools/workflows: “Redaction impact analyzer” that recomputes embeddings with ablated entries and checks manifold preservation, Gram-matrix reconstruction, and downstream task performance.
- Assumptions/dependencies: Collective latent variable influences many tokens; embedding dimension not too small; compliance constraints permit aggregate analysis.
- Lightweight, domain-specific embeddings tuned for slow modes
- Sectors: edge/embedded, mobile apps, on-device search
- What: Train or distill low-dimensional encoders that preserve top Fourier modes for domain concepts (e.g., timeline browsing in news apps); achieve memory/latency gains while retaining key structure.
- Tools/workflows: Spectral targeting in distillation (prioritize top modes); evaluation with manifold QA.
- Assumptions/dependencies: Tasks primarily rely on slow-mode structure; acceptable performance trade-offs.
- Cross-lingual alignment using universal cyclic/continuous anchors
- Sectors: localization, multilingual NLP
- What: Align languages by anchoring on universal continua (months, weekdays, hue, geography) via shared manifold geometry; improve cross-lingual retrieval and knowledge transfer.
- Tools/workflows: Build alignment maps by matching principal modes and their phases across languages.
- Assumptions/dependencies: Comparable corpora and concepts; culturally consistent cycles; minimal orthographic ambiguity.
- Educational and communication tools
- Sectors: education, science communication
- What: Interactive visualizations that show how Fourier modes appear in embeddings; use months/years/cities to teach symmetry, PCA, and manifold learning.
- Tools/workflows: Notebooks and web demos integrating PMI estimation, PCA, and Lissajous plots.
- Assumptions/dependencies: Curated examples; stable embeddings.
- Unit tests and acceptance criteria for text encoders
- Sectors: software/ML engineering
- What: Include “months form a circle,” “years form an open 1D manifold,” “cities’ lat/long are linearly decodable” as regression tests for encoder releases.
- Tools/workflows: Continuous integration checks with fixed concept lists and success thresholds on manifold metrics and decoding error.
- Assumptions/dependencies: Stable training data; predictable variance due to model randomness.
Long-Term Applications
These applications are promising but require additional research, scaling, or development to meet production standards.
- Symmetry-regularized training objectives and architectures
- Sectors: AI model development, software
- What: Incorporate translation-symmetry priors (e.g., kernel-based regularizers, latent-lattice objectives) into embedding and LLM training; add layers that preferentially learn slow modes; design positional or token encodings with symmetry-aware inductive biases.
- Tools/workflows: Loss terms that penalize deviations from predicted kernels; architectural modules inspired by Fourier eigenfunctions.
- Assumptions/dependencies: Gains generalize beyond curated concept sets; avoids over-constraining models in contexts where symmetry does not hold.
- Unified framework for continuous, binary, and hierarchical attributes
- Sectors: AI research, foundation models
- What: Extend the theory to jointly model and disentangle multiple latent structures (continuous manifolds, binary attributes underlying analogies, and hierarchical attributes) to guide representation learning and interpretability.
- Tools/workflows: Joint spectral-factorization pipelines; multi-objective training; structured probes.
- Assumptions/dependencies: Sufficient data to separate factors; identifiability under realistic noise and polysemy.
- Robust model editing, unlearning, and compliance by spectral control
- Sectors: privacy, policy, regulated industries
- What: Use the collective latent-variable perspective to edit or unlearn data while preserving desired slow modes; certify what structure persists after removal; create standards for dataset transparency based on symmetry tests.
- Tools/workflows: Spectral unlearning operators; compliance reports showing mode preservation or attenuation; policy templates referencing symmetry diagnostics.
- Assumptions/dependencies: Regulatory acceptance; reliable estimation of spectral impact at scale.
- Spatiotemporal reasoning agents grounded in manifold geometry
- Sectors: robotics, geospatial intelligence, digital assistants
- What: Agents that plan and reason using decoded coordinates (maps/timelines) derived directly from language; combine text and sparse metadata to build internal spatial/temporal maps with minimal supervision.
- Tools/workflows: Hybrid pipelines integrating text-derived manifolds with navigation/planning modules; map/timeline memory slots in agent architectures.
- Assumptions/dependencies: Accurate coordinate decoding in open-world text; robustness to ambiguous or metaphorical language.
- Safety and red-teaming via symmetry violations
- Sectors: AI safety, trust & safety
- What: Systematically generate adversarial or pathological prompts/corpora that break expected translation symmetry to stress-test model reliability in reasoning about time/space; develop detectors that monitor symmetry drift in deployed systems.
- Tools/workflows: Symmetry-violation generators; deployment monitors measuring kernel drift and probe errors.
- Assumptions/dependencies: Clear baseline symmetry profiles; meaningful thresholds for intervention.
- Domain-specific clinical and bio/eco-epidemiological models
- Sectors: healthcare, public health, climate/ecology
- What: Apply manifold-based seasonality and spatial decoding to clinical notes, surveillance reports, and scientific text to infer time-to-event patterns, seasonality of diseases, or spatial spread signals from textual evidence alone.
- Tools/workflows: Secure pipelines integrating EHR/text embeddings with linear decoders; fusion with structured data for forecasting.
- Assumptions/dependencies: Privacy constraints; clinical corpora with sufficient coverage; careful handling of confounders and biases.
- Economic and policy analytics from text-derived cycles
- Sectors: finance, public policy
- What: Extract cyclical patterns (e.g., business seasons, policy cycles, supply chain oscillations) from large text corpora (earnings calls, filings, legislative records) using spectral modes; improve forecasting and policy timing.
- Tools/workflows: Enterprise analytics platforms adding spectral-text modules; scenario analysis tied to mode amplitudes/phases.
- Assumptions/dependencies: Language reflects underlying cycles; separation from media hype cycles; access to high-quality corpora.
- Compression, distillation, and pruning guided by spectral importance
- Sectors: model deployment, edge AI
- What: Prioritize preserving slow Fourier modes during compression/distillation for tasks dominated by spatiotemporal reasoning; provide “mode-preserving” guarantees.
- Tools/workflows: Spectral-aware pruning criteria; teacher-student objectives targeting selected modes.
- Assumptions/dependencies: Target applications truly rely on slow modes; minimal loss in general capabilities.
- Benchmarking and synthetic corpora with controlled symmetries
- Sectors: academia, AI evaluation
- What: Create benchmarks and synthetic datasets that systematically vary translation symmetry and latent variable structure to test representation learning and reasoning; quantify when ripples and manifolds emerge.
- Tools/workflows: Open datasets and harnesses; leaderboards tracking manifold metrics and decoding accuracy vs. probe dimension.
- Assumptions/dependencies: Community adoption; careful design to avoid overfitting to benchmarks.
- Neuroscience-inspired representation modules
- Sectors: neuromorphic computing, AI research
- What: Explore modules that emulate grid-cell-like interference of Fourier modes for 2D spaces, informed by the paper’s symmetry–geometry mechanism; test in navigation and memory tasks.
- Tools/workflows: Prototype layers with a small set of learned plane-wave bases; integration with RL agents.
- Assumptions/dependencies: Transfer of insights from text-induced manifolds to sensorimotor domains; training stability.
Notes on global assumptions across applications:
- The translation symmetry signal is sufficiently present in the relevant corpus and concept set; strong confounders (polysemy, domain shifts) are managed by curation or context conditioning.
- Linear probes are feasible because top principal components capture slow Fourier modes; error scales roughly as r-1/D for probe dimension r on a D-dimensional continuum.
- Robustness to data ablation relies on collective latent variables affecting many tokens, yielding large, stable eigenmodes; very small datasets or extreme sparsity may break this.
- For LLM internal states, context can reshape representations; the symmetry-induced geometry is most reliably observed in average-case or context-neutral settings unless explicitly controlled in prompts.
Collections
Sign up for free to add this paper to one or more collections.