- The paper presents a distributed, single-pass framework that enables scalable, real-time activation logging and control for LLMs up to 70B parameters.
- The paper details a deferred vocabulary projection with logit-lens analysis that captures token prediction evolution across transformer layers while optimizing memory and latency.
- The paper demonstrates effective real-time steering via contrastive vector injection, achieving a mean steerability slope of 0.70 without compromising model fluency.
Distributed Activation-Level Interpretability and Control for LLMs
Introduction
The exponential scaling of LLMs has accentuated interpretability and real-time behavioral control as essential requirements for reliable and deployable AI systems. However, practical access to intermediate activations for understanding and modulating LLM behavior has historically been limited to models small enough for single-GPU execution. The paper "Distributed Interpretability and Control for LLMs" (2604.06483) tackles these constraints by introducing a system for high-throughput, memory-efficient activation logging and behavioral steering for 10--70B parameter LLMs in tensor-parallel, multi-GPU environments. The proposed framework integrates logit-lens analysis and steering-vector injection directly into the inference path, enabling scalable, single-pass interpretability and real-time modifications of model outputs.
System Architecture
The architecture is designed around a distributed, single-pass execution model that integrates seamlessly within tensor-parallel inference pipelines. Layer instrumentation is implemented via lightweight block wrappers at selected transformer layers. During autoregressive generation with active KV caching, each step logs the most recent token's hidden activation from attention, MLP, and block outputs at all instrumented layers. These activations are buffered efficiently, circumventing the need for multi-pass decoding or per-layer vocabulary projections, with memory complexity scaling as O(Td∣L∣∣C∣).
Post-generation, a deferred vocabulary projection is performed in batch using the final normalization layer and shared LM head weights, yielding top-k vocabulary logits for each token and each layer. This approach amortizes the expensive vocabulary projection, keeping peak memory use and latency tractable even for multi-thousand token sequences and 70B parameter models.
(Figure 1)
Figure 1: Logit lens heatmap for the token "university" in LLaMA-3.1–70B visualizes top-k probable tokens by layer and activation type, indicating the sharpening of predictions in deeper layers.
Activation-Level Logit Lens
The logit lens exposes the token-wise evolution of predictions within the model as activations are transformed through the stack. By deferring the projection (Equation 1 in the paper) to post-generation and restricting output to top-k, the method allows fine-grained, per-layer analysis without prohibitive computational burden. Layer-wise logit lens heatmaps reveal the sharpening of distributions from uniform or noisy guesses in early layers to near-deterministic high-probability mass in the upper stack (Figure 1). This is crucial for analyzing how LLMs disambiguate between syntactic roles and semantic targets through the residual stream.
Efficient Distributed Implementation
The framework demonstrates up to 7× reduction in activation logging memory and 41× increase in throughput compared to prior single-GPU, multi-pass approaches such as LogitLens4LLMs [wang2025logitlens4llms]. Tabled results in the paper indicate sustained decoding speeds of 20–25 tokens/s for 8–70B models during full-layer logging, with negligible slowdowns relative to standard inference, enabling research and production tracing for long contexts and large batch experiments. The scalability across LLaMA-3.1 (8B, 70B) and Qwen-3 (4B, 14B, 32B) is empirically demonstrated, with multi-thousand token generations completed under strict multi-GPU memory budgets.
Real-Time Activation Steering
The same instrumentation supports steering-vector interventions by constructing contrastive directions between base and target behaviors. These directions are injected post-LayerNorm, immediately after attention computation, preserving the native inference semantics (including KV cache residency) and avoiding additional forward passes. The behavioral shift induced by steering is quantified via dose-response analysis: the mean steerability slope across datasets is 0.70, reflecting strong, monotonic shifts in label-token propensity per unit of α multiplier without loss of throughput.
Empirical analysis demonstrates that steerability is maximized at mid-layer depths (e.g., layer 35 in LLaMA-3.1–70B), whereas early and deep layers show minimal or saturating effects, respectively. This aligns with and substantiates recent findings on the spatial localization of latent features for controllability [tan2024analyzinggeneralizationreliabilitysteering].
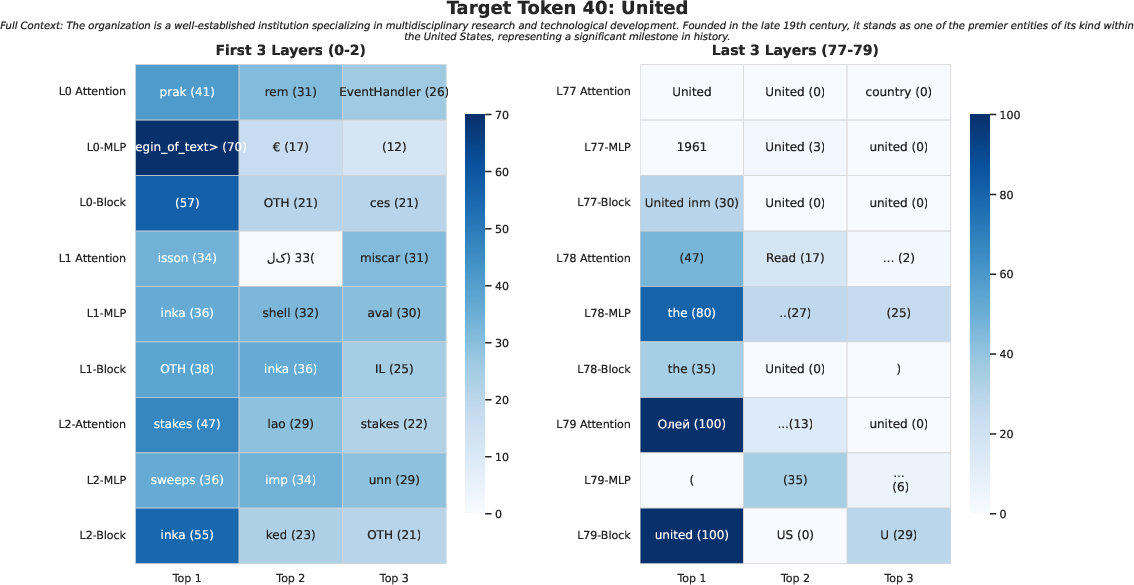
Figure 2: Steering-vector propensity response in LLaMA-3.1–70B, exhibiting maximal effects at mid-layer depths (e.g., L=35).
Notably, this steering method avoids degradation of fluency or semantic collapse up to moderate α values. At extreme multipliers, minor degeneration is observed, but the system’s default operation regime resides well within stable, interpretable behavioral boundaries.
Practical Implications
This unified design makes it tractable to deploy activation-level interpretability and behavioral control infrastructures on state-of-the-art LLMs in both research and deployment settings. Key implications include:
- Scalability: Supports full-layer logging and intervention on 70B+ parameter models using commodity 4× GPU nodes.
- Single-Pass Integration: No second forward pass, and no abrogation of KV caching semantics, allowing use in interactive or latency-sensitive systems.
- Uniform Interface: Reusable codebase and activation format across model families (LLaMA, Qwen, etc.), minimizing friction for comparative studies.
- Behavioral Probing/Control: Enables scheduled and per-token steering at arbitrary stack depths for mechanistic analyses or user-driven modifications (e.g., safety, style, persona control).
- Production Readiness: Logging and steering add minimal system overhead, making them suitable for continuous monitoring and adaptive interfaces.
Theoretical Consequences and Future Outlook
Mechanistic interpretability at the activation level enables empirical testing of hypotheses regarding representation drift, feature localization, and behavior control. By closing the execution gap for large models, the framework should catalyze richer factoring between learned representations and emergent behaviors and foster new methodologies for evaluation and diagnosis. It promises to accelerate the maturation of robust safety and alignment protocols that require both interpretability and control hooks at scale.
Future work must generalize the approach to encoder-decoder or non-transformer models, explore nonlinear or subspace-based intervention strategies, and integrate training-time interpretability for dynamics analysis. The codebase’s open release will likely seed rapid follow-up work and wider adoption.
Conclusion
The proposed tensor-parallel, single-pass infrastructure achieves fast, memory-efficient, full-layer interpretability and real-time steering for LLMs up to 70B parameters. It bridges the operational gap for activation-level logging and control in multi-GPU settings and demonstrates robust, monotonic, high-slope behavioral modification with negligible inference overhead and no model parameter changes (2604.06483). By enabling scalable, unified introspection and control, the framework is poised to inform both mechanistic research agendas and the practical deployment of transparent, steerable LLMs.