- The paper introduces HingeMem, a boundary-guided long-term memory model that segments dialogue using key elements like person, time, location, and topic.
- It employs query-adaptive retrieval with dynamic hyperedge reranking and adaptive stopping to effectively balance recall and precision.
- Empirical results show notable improvements in F1 scores and token efficiency, demonstrating scalability and robustness in multi-session dialogue systems.
HingeMem: Boundary-Guided Long-Term Memory with Query-Adaptive Retrieval for Scalable Dialogues
Introduction and Motivation
Long-term memory (LTM) support is increasingly central in dialogue systems built upon LLMs, particularly for scenarios requiring sustained, personalized, and multi-session interactions. Contemporary approaches predominantly rely on continuous summarization updates or OpenIE-based graph memories paired with static Top-k retrieval mechanisms. However, these paradigms exhibit limited adaptability to diverse query categories and incur excessive computational overhead, often neglecting event granularity and the alignment of retrieval with a spectrum of user queries.
HingeMem is proposed to address these deficiencies by operationalizing event segmentation theory and introducing a neuro-inspired, boundary-centric long-term memory architecture. This framework introduces dual innovations: (i) boundary-triggered memory construction based on four pivotal elements (person, time, location, topic), and (ii) query-adaptive retrieval strategies that optimize both what and how much memory to access depending on query type. The model directly simulates cortical and hippocampal mechanisms for memory formation, aiming for scalable integration in web dialogue applications.
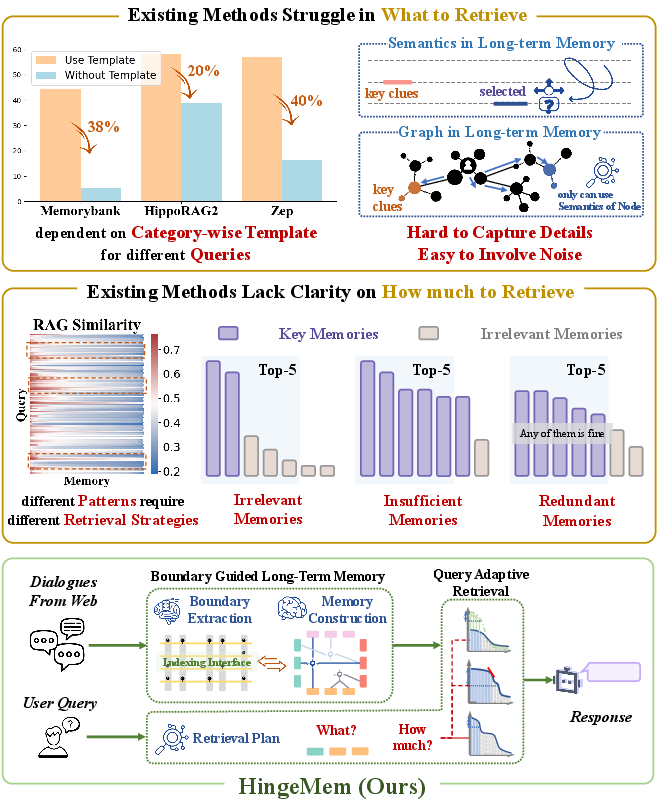
Figure 1: HingeMem's neuro-inspired architecture simulates the cortex and hippocampus to implement boundary-guided memory with adaptive retrieval planning, directly addressing the clue-identification and retrieval-control limitations of prior work.
Neuro-Inspired Boundary-Guided Memory Construction
Event Segmentation and Memory Encoding
Drawing on event segmentation theory and neuroscientific findings regarding boundary-centric memory encoding, HingeMem introduces explicit memory segmentation at changes in person, time, location, or topic. Each segment is represented as a hyperedge in a hypergraph structure, connecting the relevant element nodes and attaching a structured description alongside a rationale for segmentation. This mechanism not only minimizes unnecessary memory writes but also maximizes context salience, preserving crucial details for downstream retrieval tasks.
Each conversational session is processed to extract boundaries, which demarcate segments, and the information in each segment is indexed using element-specific nodes. Hyperedges connect elements within the same segment, storing both semantic and topological information. The integration and consolidation of new boundary memories into the existing long-term memory utilize field-aware Jaccard similarity and clustering to merge redundant or overlapping hyperedges, yielding a compact yet detailed memory store.
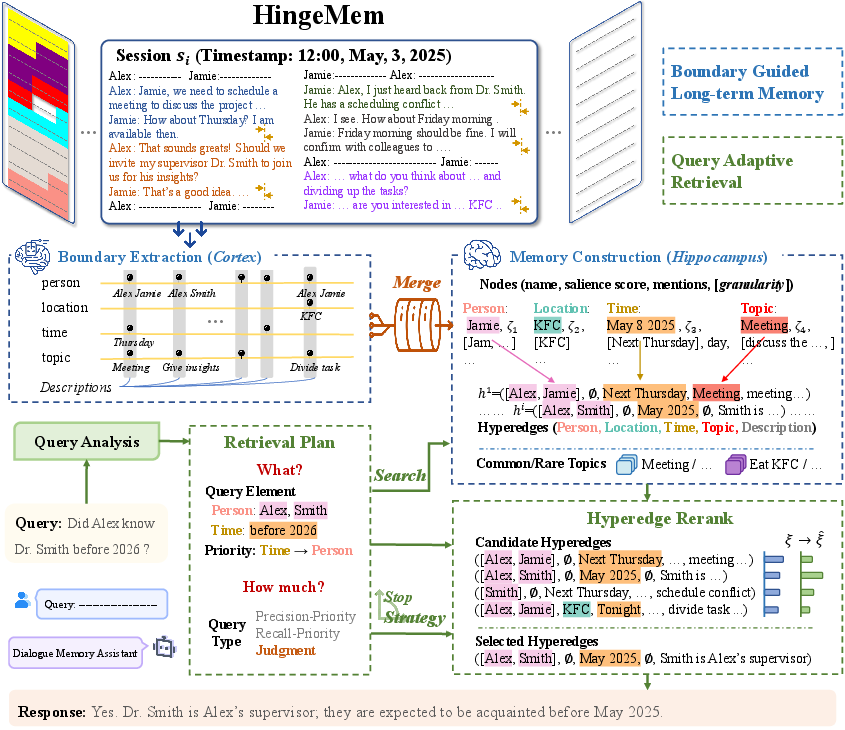
Figure 2: The pipeline for constructing boundary-guided long-term memory and executing query-adaptive retrieval, distinguishing cortical boundary extraction and hippocampal memory consolidation.
Query-Adaptive Retrieval: From Plan Generation to Adaptive Stopping
Retrieval Planning and Typing
HingeMem’s retrieval operates in three stages: generation of a retrieval plan, hyperedge reranking, and adaptive stopping based on query analysis. Unlike systems that depend on dataset-specific query type information, HingeMem abstracts queries into three retrieval-oriented types—recall-priority, precision-priority, and judgment—through prompt-driven analysis, and extracts constraints and element priorities for each.
Given a user query, the plan specifies which element interfaces to interrogate, which names to target, and the priority ranking of these constraints. This enables instance-level alignment between the query and relevant memory segments, both structurally (via hyperedges) and semantically (via embeddings).
Hyperedge Reranking
Candidate hyperedges matched from the index undergo reranking via a scoring function that sums initial match scores, node salience (aggregated according to element priority), and a penalty reflecting topic frequency (highlighting rare vs. common topics). This process seeks to maximize both specificity and informativeness, reducing the impact of high-frequency but low-utility memory segments.
Adaptive Stopping
Rather than uniformly applying Top-k selection, HingeMem uses adaptive stopping policies contingent on query type:
- Recall-priority: Retrieve until the inflection point in score differences, ensuring coverage for enumerative queries.
- Precision-priority: Select only memories exceeding a fixed proportion (e.g., 80%) of the top score, boosting response accuracy.
- Judgment: Use softmax-scaled thresholds, admitting any highly confident segment to avoid redundant evidence.
This framework directly reduces token cost and noise while ensuring that retrieved content matches the query's information requirements.
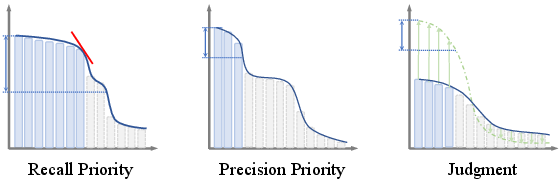
Figure 3: Adaptive stop mechanism for each query type, illustrating dynamic thresholds for memory segment selection.
Empirical Evaluation
Benchmarking on LOCOMO
LOCOMO, a large-scale, multi-session conversational memory benchmark, is used to assess both lexical and LLM-based evaluation metrics (F1, BLEU-1, LLM-as-a-Judge). HingeMem is compared against strong baselines spanning both semantic and graph-based memory architectures, utilizing both small- and production-scale models (e.g., Qwen-series).
Key empirical findings and strong numerical results:
- HingeMem achieves a 20% relative performance gain over memory construction baselines without query type specification, with absolute improvements of 5–10% on overall F1 and LLM-as-a-Judge scores, and over 10% in multi-hop reasoning—substantially outperforming variants that require category-specific prompts.
- Token efficiency: HingeMem reduces question answering token cost by 68% vs. HippoRAG2 and maintains competitive performance even as context windows scale to 128K tokens. Memory construction overhead is comparable to prior state-of-the-art solutions, but inference token cost is significantly lower, enhancing practical deployability.
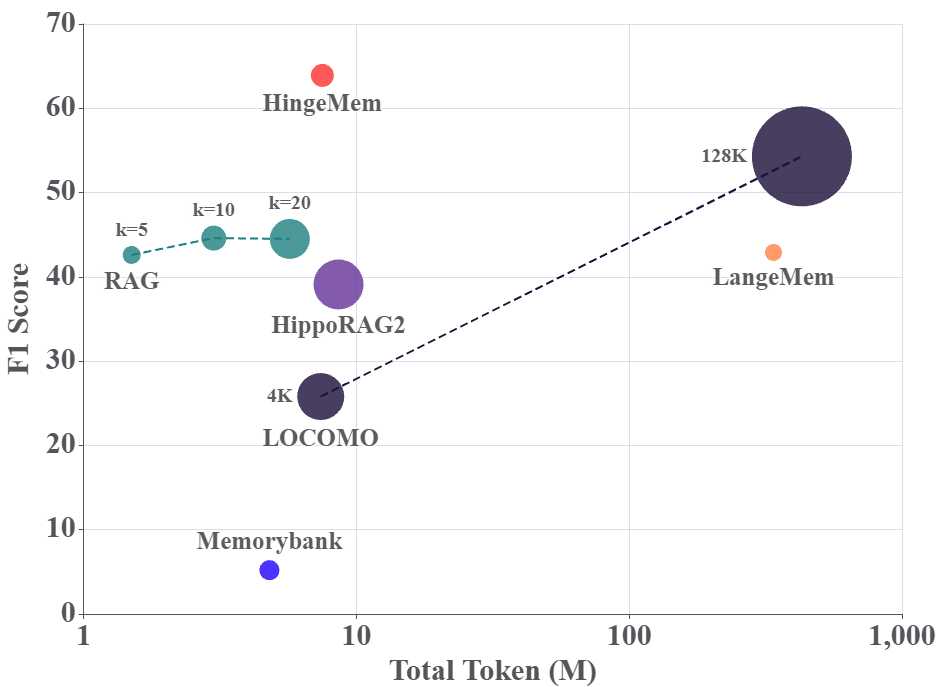
Figure 4: Comparative analysis of token efficiency across retrieval and memory construction strategies, highlighting HingeMem’s balance of performance and computational cost.
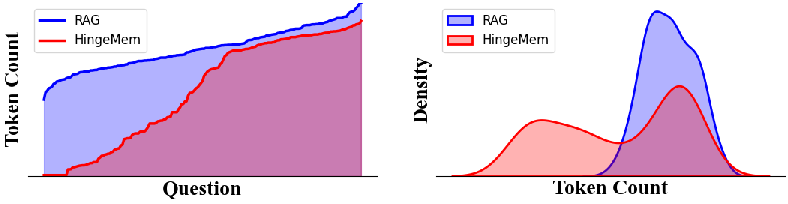
Figure 5: Example analysis of token usage in retrieval, showing how HingeMem adaptively tailors retrieval capacity and minimizes noise relative to fixed Top-k RAG.
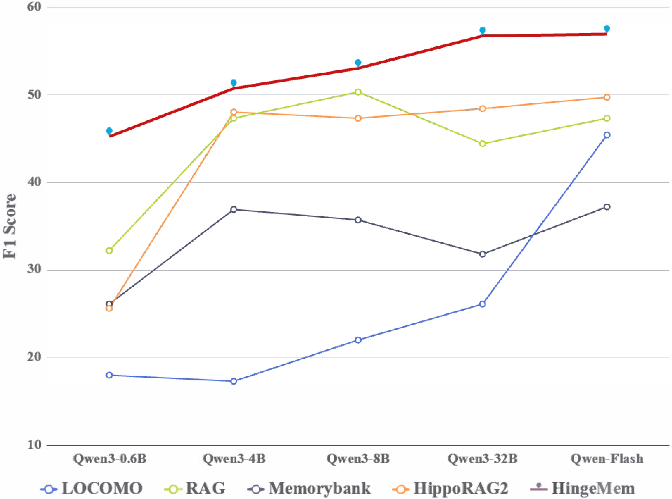
Figure 6: Robustness of HingeMem across scales in the Qwen model family, with consistent optimal results.
Ablation and Analytical Studies
Ablation experiments confirm the additive value of each architectural component—boundary-guided memory, node indexing, reranking, and adaptive stopping—with boundary-based memory structures alone yielding a >10% increase in overall F1 over text-based baselines. Additional analyses reveal that the model’s adaptive retrieval maximizes performance and efficiency across diverse question types and is robust to model scaling from edge (0.6B) to production (Flash) sizes.
Theoretical and Practical Implications
Theoretically, HingeMem's approach embodies a cognitively plausible model for LTM integration—segmenting experience at event boundaries and explicitly representing relational structure. This improves both interpretability and retrieval alignment for conversational AI. The structured, event-bound representation enables future developments in continual learning, memory refinement, and meta-cognitive operations.
Practically, the combination of query-adaptive retrieval and efficient boundary-indexed storage addresses the latency, redundancy, and hallucination risks of scalable web dialogue systems. HingeMem offers a blueprint for integrating neuro-symbolic memory with LLMs in edge and cloud environments, supporting both real-time and persistent memory-intensive applications.
Future Directions
Future work may extend HingeMem by:
- Generalizing beyond dialogues to multi-modal, multi-agent, or task-oriented LTM.
- Incorporating RL or self-supervised feedback to further refine adaptive retrieval policies.
- Investigating dynamic abstraction and forgetting mechanisms for lifelong memory.
- Exploring integration with compositional neuro-symbolic reasoning in LLM agents.
Conclusion
HingeMem introduces a neuro-inspired, boundary-guided LTM model with query-adaptive retrieval for dialogue systems. By encoding conversations at key event boundaries and adaptively tailoring retrieval plans at query time, HingeMem achieves strong gains in both accuracy and efficiency without recourse to query-type templates. This framework offers theoretical foundations for event-centric memory modeling and practical pathways for scalable, trustworthy LLM-based dialogue assistants.
(2604.06845)