- The paper presents HyperMem, a novel three-level hypergraph memory architecture that unifies high-order semantic associations in prolonged conversations.
- It employs LLM-based episode detection, topical aggregation, and fact extraction to efficiently segment and retrieve coherent multi-hop dialogue evidence.
- Empirical results on the LoCoMo benchmark demonstrate improved accuracy and reduced token usage compared to traditional RAG and graph-based methods.
HyperMem: Hypergraph Memory for Long-Term Conversations
Motivation and Problem Setting
Long-term conversational coherence, cross-session reasoning, and persistent tracking of entities or tasks are critical for agentic LLM systems, especially in scenarios involving extended interactions where fixed context windows of mainstream LLMs are insufficient. Traditional retrieval-augmented generation (RAG) and graph-based memory architectures either chunk dialogues or establish pairwise-relationship graphs, both of which induce fragmentation and loss of high-order associations inherent to natural conversation streams. This fragmentation leads to retrieval failures for multi-hop questions, temporal reasoning, or queries requiring aggregation of temporally dispersed evidence.
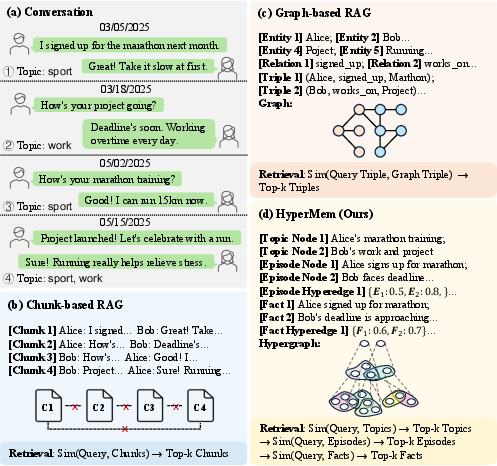
Figure 1: Memory structure comparison across Chunk-based RAG, Graph-based RAG, and HyperMem, highlighting HyperMem’s capacity to maintain high-order semantic associations.
HyperMem Architecture: Hierarchical Hypergraph Memory
HyperMem introduces a three-level hypergraph memory architecture to explicitly model high-order associations in conversational memory streams:
- Topic Level: Topic nodes represent persistent themes, aggregating non-consecutive episodes via topic hyperedges.
- Episode Level: Episodes partition the dialogue into semantically and temporally coherent segments, marking event boundaries through an LLM-driven boundary detector.
- Fact Level: Facts are atomic, query-answerable assertions distilled from episodes, with explicit anchoring for provenance.
Hyperedges connect arbitrary sets of nodes within and across these levels, capturing joint dependencies such as multi-episode events linked to the same topic and facts participating in multiple episodes. Such a structure unifies semantically related yet temporally dispersed content, enabling efficient, non-fragmented retrieval.
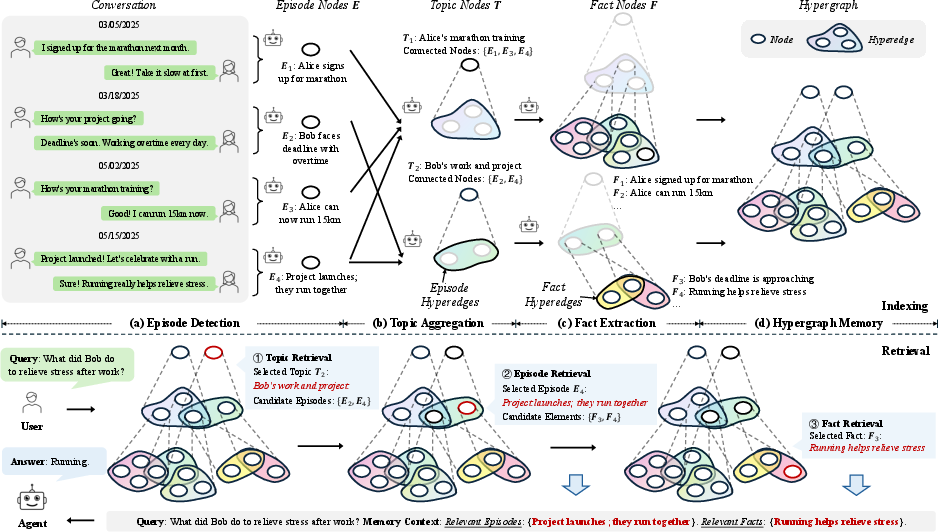
Figure 2: The HyperMem framework: indexing detects episode boundaries, aggregates topics via hyperedges, and extracts facts. Retrieval proceeds coarsely-to-finely from topics to episodes to facts.
Memory Construction Pipeline
Episode Detection
Automatic, LLM-based segmentation identifies coherent event boundaries, using semantic signals, intent transition, time gaps, and explicit linguistic markers. This mechanism incrementally processes the dialogue stream, isolating events and mitigating contamination of context with irrelevant discourse history.
Topic Aggregation and Hyperedge Construction
Topically related episodes are incrementally grouped via LLM-driven similarity assessment, forming topic nodes and topic-episode hyperedges. Topics thus act as anchors for temporally fragmented narratives.
A further LLM-based procedure extracts fine-grained, query-focused facts from episodes. Each fact node is annotated with content, anticipated query patterns, and keywords for facilitating both semantic and lexical retrieval. Facts are explicitly linked back to the episodes and topics through hyperedges, maintaining explainability and provenance alignment.
Indexing and Retrieval: Lexical-Semantic Fusion and Hierarchical Traversal
HyperMem leverages dual indices (BM25 for keyword-based search; Qwen3-Embedding-4B for dense semantic retrieval) across all node levels (topic, episode, fact). A lightweight hypergraph embedding propagation mechanism aggregates embeddings along hyperedges, aligning semantically related memory units. The offline index construction fuses these embeddings into the node representations.
Online retrieval is executed as a hierarchical, coarse-to-fine traversal:
- Topic retrieval: Candidates are selected using reciprocal rank fusion (RRF) over lexical/semantic scores, then reranked.
- Episode retrieval: For each topic, constituent episodes are expanded via hyperedges and filtered.
- Fact retrieval: Salient facts supporting answers are extracted from the selected episodes, with a final context constructed only from concise fact nodes and (optionally) episode-level summaries.
This pipeline enables early pruning of irrelevant contexts, preserves both topical and temporal coherence, and ensures minimization of token usage during downstream LLM inferences.
Empirical Evaluation and Results
Extensive experiments on the LoCoMo benchmark—designed to evaluate long-term conversational memory—demonstrate strong performance improvements. HyperMem achieves 92.73% overall LLM-as-a-judge accuracy, outperforming the nearest RAG competitor (HyperGraphRAG, 86.49%) by 6.24% and surpassing strong memory systems like MIRIX by 7.35%.
- Single-hop: 96.08% (precise atomic retrieval—Figure 3)
- Multi-hop reasoning: 93.62% (evidence aggregation across sessions)
- Temporal: 89.72% (accurate state as-of queries—Figure 4)
- Open Domain: 70.83% (challenging, oft requiring external knowledge)
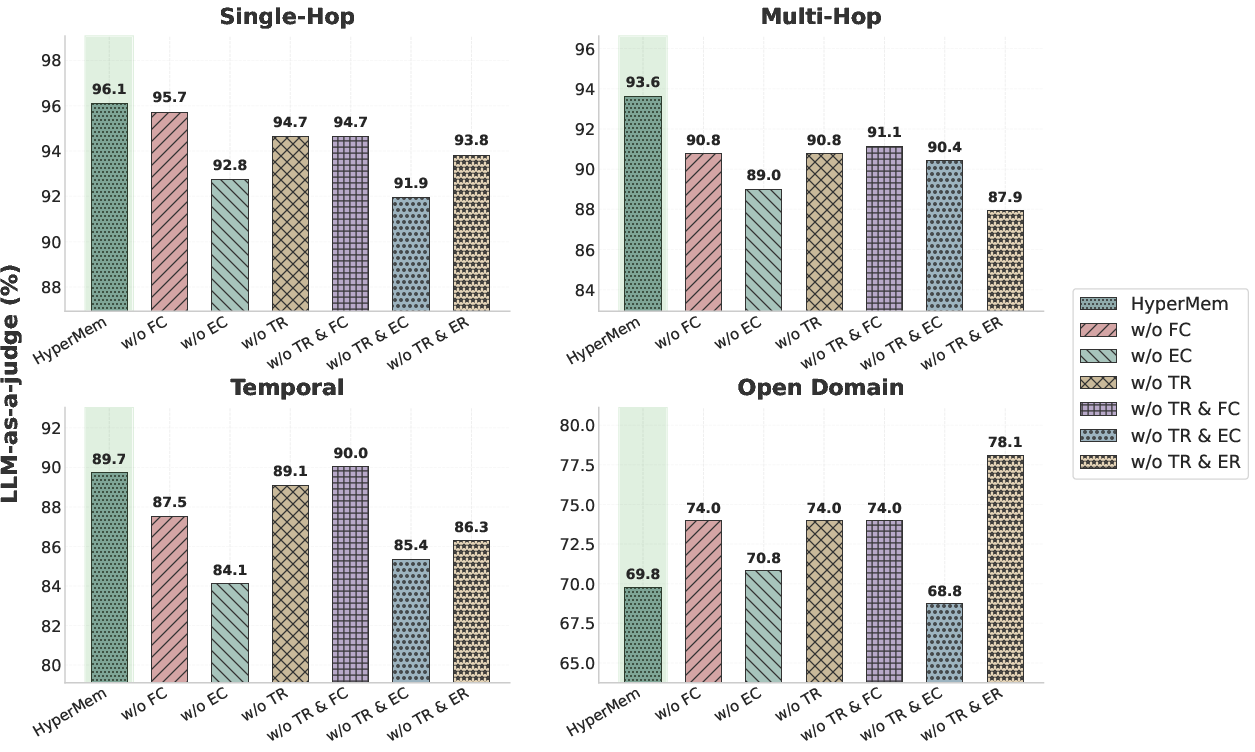
Figure 5: Ablation study—removal of episode or topic-level context significantly degrades performance, confirming the necessity of hierarchical storage and retrieval mechanisms.
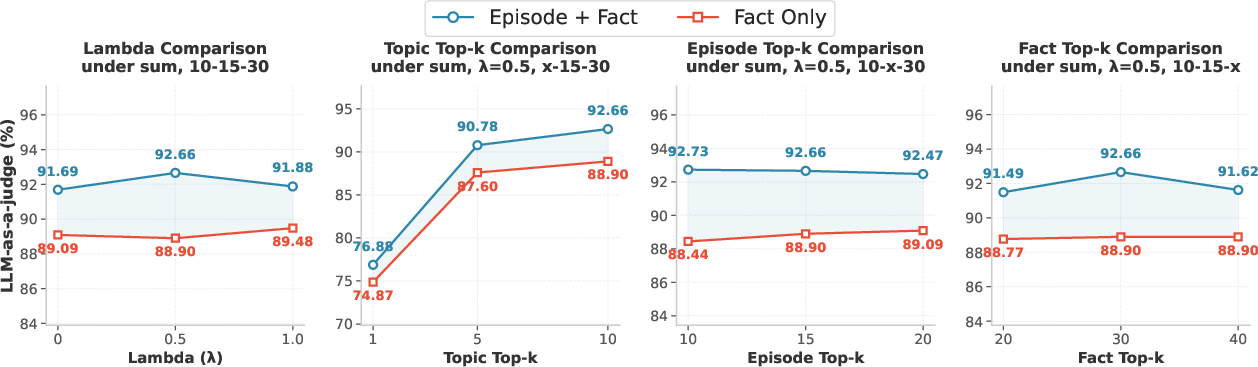
Figure 6: Hyperparameter sensitivity—accuracy is most sensitive to topic coverage, while embedding fusion and episode/fact parameters yield smooth efficiency-accuracy trade-offs.
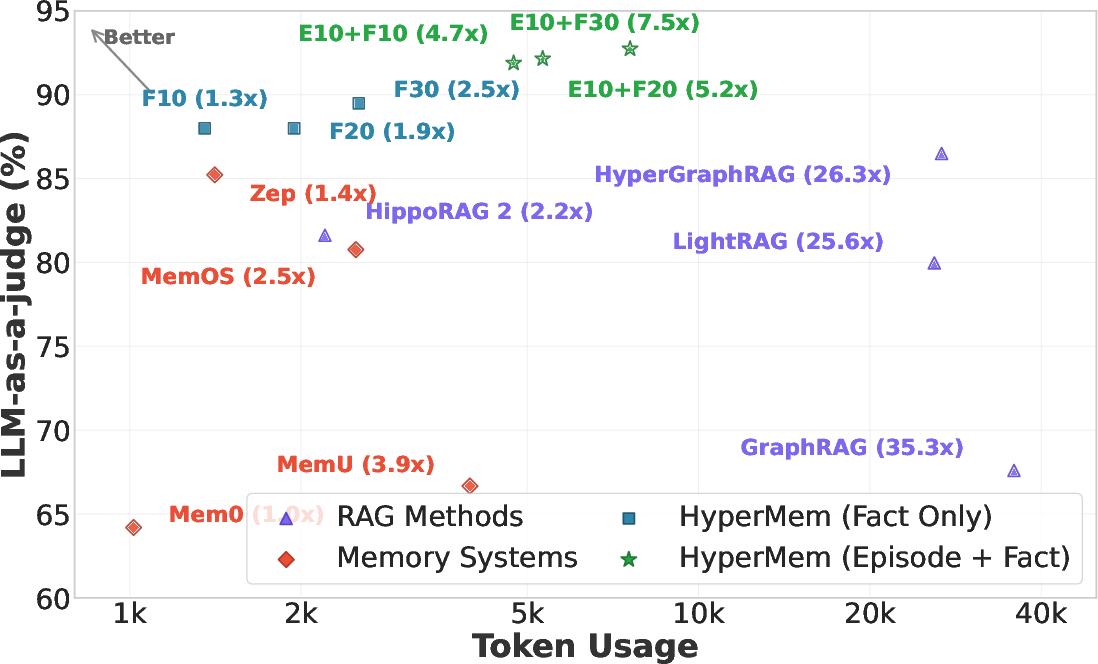
Figure 7: Token usage vs. accuracy—HyperMem achieves superior accuracy with lower token consumption compared to RAG-based approaches.
Notably, case studies demonstrate that HyperMem’s hierarchical hypergraph outperforms classic chunk-based and pairwise-graph methods in all LoCoMo test scenarios, as it avoids fragmented memory and enables coherent evidence gathering, even across widely separated conversational events.

Figure 3: Single-hop retrieval—HyperMem’s retrieval precision avoids entity confusion present in pairwise-graph architectures.

Figure 8: Multi-hop reasoning—HyperMem successfully aggregates all tournament mentions, whereas baselines split evidence.

Figure 4: Temporal reasoning—HyperMem accurately reconstructs the subject’s state at the query time, preventing subject drift or miscount.

Figure 9: Open-domain inferential tasks—HyperMem correctly synthesizes thematic evidence, while other models misattribute intent.
Architectural Implications and Future Directions
The introduction of hypergraph-based memory marks a substantial architectural refinement for LLM agent memory systems. By supporting high-order relational modeling, HyperMem remedies deficiencies in legacy RAG and graph-based solutions, particularly for tasks requiring evidence aggregation, temporal reasoning, or cross-session tracking.
Theoretically, this approach closes the gap between human associative memory and artificial memory management for dialogue agents. Practically, it enables lower token usage and increased answer accuracy, crucial for production deployment of long-term, persistent agents. Limitations remain in handling multi-agent/multi-user settings and Open Domain queries requiring augmentation with external knowledge bases.
Anticipated future advances include further scaling to multi-agent scenarios with memory isolation/access control, integration with external knowledge graphs for Open Domain reasoning, and learning-based optimization of memory construction and retrieval policies.
Conclusion
HyperMem establishes a robust, scalable paradigm for long-term conversational memory by structurally unifying temporally and semantically dispersed content through hierarchical hypergraph modeling. Its coarse-to-fine retrieval strategy, lexical-semantic indexing with hyperedge-based embedding propagation, and empirically validated efficiency and accuracy gains represent a significant development for agentic LLM architectures.