Uni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Abstract: Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Uni‑ViGU: A simple explanation for teens
What is this paper about?
This paper introduces Uni‑ViGU, a single AI model that can both:
- make videos from text (video generation), and
- write text descriptions from videos (video understanding).
Most past systems start from LLMs and try to add video making on top. The authors flip that idea: they start from a strong video maker and teach it to read and talk about videos. Their goal is to build one model that’s good at both, instead of two separate models glued together.
What questions are the researchers asking?
The paper focuses on three easy‑to‑grasp questions:
- Since creating videos is much more expensive than reading them, can we build everything around a video generator and still get good understanding?
- Can one process be used to generate both smooth video pixels and step‑by‑step text tokens at the same time?
- Can the knowledge a model learns while making videos help it get better at understanding videos?
How does their method work?
To make this main idea easy to understand, here are the building blocks and how they fit together.
1) Starting from a video generator
- Think of a video generator like an artist who starts with a canvas full of “static” (random noise) and gradually turns it into a clear video.
- This “cleaning up noise” process is called diffusion. The model learns how to move from chaos to a finished video by taking many small, guided steps.
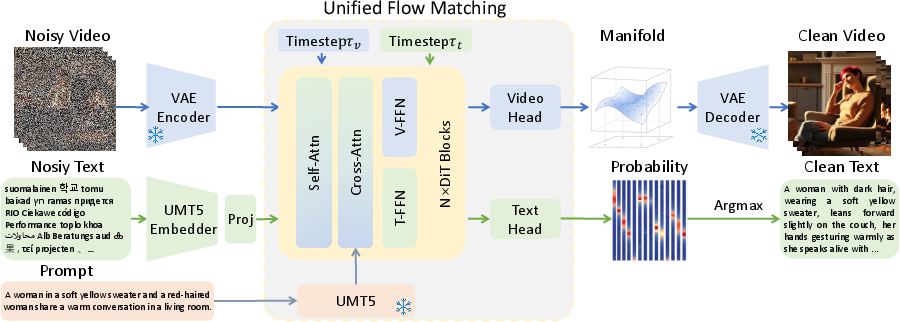
- To make this faster, the video is first “zipped” into a smaller form (like compressing a file). This is done by a VAE (Variational Autoencoder), which turns the big video into a compact, easier‑to‑handle version.
2) One “flow” that works for both video and text
- Video is smooth and continuous (like colors and movement), while text is made of discrete tokens (words).
- The authors create a single “flow” process that can handle both at once:
- For video: the model learns how to push the noisy video toward a clean video in small steps (continuous flow).
- For text: they treat each word as a point in a special space (an embedding) and learn how to push noise toward the right word points (discrete flow).
- Because both use the same kind of guided pushing (“flow matching”), one model can generate videos and sentences together. You can think of it like two dancers moving together: as the text becomes clearer, it guides the video; as the video becomes clearer, it helps the text become more accurate.
3) A shared “brain,” with specialized “hands”
- The model is built from Transformer blocks (the same kind of network used in LLMs). Each block has:
- Attention layers: like the model’s “eyes and ears,” deciding what to look at in the video and text.
- FFN (feed‑forward) layers: like specialized “hands” that do the detailed work for each type.
- Uni‑ViGU shares the attention layers for both video and text so the two can learn from each other, but it uses separate FFN branches:
- One FFN specializes in video,
- Another FFN specializes in text.
- This setup is called a modality‑driven Mixture‑of‑Experts (MoE). It keeps the common sense shared, while letting each modality keep its unique skills.
4) Training in two steps to reuse knowledge
To help the model learn to understand videos using the skills it already has from making them, training is done in two stages:
- Stage 1: Knowledge Recall
- The model is asked to reconstruct the input prompt (the short text that was used to generate the video) from the video.
- To stop the model from simply copying the prompt, the prompt is sometimes hidden (“dropped out”), forcing the model to “look” at the video and learn the link between the text and visuals it already knows from generation.
- Stage 2: Capability Refinement
- Now the model learns to produce detailed captions (longer, richer descriptions) for videos.
- Since these captions include extra details that weren’t in the short prompt, the model must pay real attention to the video content (objects, actions, timing) to succeed.
- This grows its true video understanding skills.
What did they find, and why does it matter?
- The model can:
- Turn text into high‑quality videos (as before),
- Turn videos into clear text descriptions (new ability),
- And even generate a video and its matching detailed caption at the same time—both starting from noise, improving together as they go.
- On tests, Uni‑ViGU performs competitively for both video generation and video understanding, even though it’s built around a generator.
- This shows that starting from a video generator (instead of a LLM) can be a smart, scalable way to build “all‑in‑one” models that work across video and text.
Why it matters:
- Making videos is much heavier (computationally) than reading them. Building around a video maker respects this imbalance and can save resources.
- Using one shared model encourages video and text to help each other, which can improve quality on both sides.
- The approach points toward future “unified” AI that can watch, describe, and create—with fewer parts and better coordination.
What’s the bigger impact?
If this idea catches on:
- We may see more “generation‑first” AI that can both create and understand across different media (video, images, text).
- Tools could more easily produce a video and a high‑quality script together, or watch a video and explain it in detail.
- Education, entertainment, and accessibility could benefit: think auto‑descriptions for videos, or creative tools that draft both scenes and narration at once.
In short, Uni‑ViGU shows a practical path to building one model that both makes videos and understands them—by treating understanding as the reverse of generation and letting video and text learn together through a shared process.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to help guide targeted follow-up research.
- Quantitative validation is absent: no standard metrics or benchmarks are reported for either video generation (e.g., FVD, VBench, GenEval) or understanding (e.g., MSR-VTT/MSVD/VATEX captioning metrics, TVQA/VQA-T scores, retrieval R@K).
- Generalization to real videos is untested: training is performed on 20K synthetic samples (video-prompt pairs/triples), with no evaluation on real-world video corpora or OOD settings.
- Synthetic data bias and leakage risks are unaddressed: using a video generator to create training videos may trivialize the reverse mapping and induce distributional bias; the paper does not test transfer to natural data or measure overfitting.
- LLM-generated captions are used as “ground truth” without quality control: there is no analysis of hallucination, factuality, bias amplification, or label noise introduced by LLM captions.
- Scope of “understanding” is narrow (captioning only): no experiments on question-conditional tasks (VQA), temporal grounding, retrieval, action recognition, or instruction-following that would demonstrate broader understanding capabilities.
- No head-to-head comparisons against unified MLLM or dual-tower baselines: claims of scalability and competitiveness lack controlled comparisons in both performance and compute/inference cost.
- Compute and efficiency claims are unquantified: there are no measurements of inference latency, memory footprint, or throughput versus understanding-centric and dual-tower approaches, especially at long durations/high resolutions.
- Quadratic attention over large joint sequences is not optimized: the model concatenates text and ~30K+ video tokens with shared attention, but there is no exploration of sparse/linear attention, chunking, or memory-saving schemes.
- Stability and solver details for uni-flow are unspecified: the ODE/SDE solver type, step counts, noise schedules, and their impact on quality/speed (for both modalities) are not analyzed.
- Independent sampling of τv and τt is not ablated: it is asserted as key, but there is no study of correlated schedules, curricula, or noise-coupling variants and their effect on learning cross-modal dependencies.
- Discrete flow for text lacks critical implementation details: vocabulary/tokenizer, EOS/length modeling, padding/masks, and length control (beyond 256 tokens) are not described or evaluated.
- Language capability and reasoning quality are unmeasured: there is no comparison to autoregressive LMs on fluency, coherence, long-context handling, multilingual support, or instruction-following.
- Text decoding is a simple argmax over embeddings: diversity/temperature control, calibration, and stochastic decoding effects on quality/alignment are unstudied.
- Token-embedding alignment to the “video manifold” is claimed but unspecified: the method used to “encourage” alignment is not defined, and no diagnostics (e.g., embedding geometry, retrieval across modalities) are provided.
- MoE design lacks ablations: no comparisons against alternatives (adapters, LoRA, gated MoE, partial sharing strategies), and no analysis of parameter overhead vs. performance.
- Risk of catastrophic forgetting is unquantified: the impact of shared-attention fine-tuning on pretrained video generation quality is not measured; no retention curves or before/after generator benchmarks are shown.
- Effect of freezing vs. finetuning modules is unclear: the paper does not specify which layers are frozen or updated and how those choices affect understanding/generation trade-offs.
- Loss-weighting sensitivity is not studied: λt = |zv|/|zt| is chosen heuristically without robustness analysis; alternative normalizations or curriculum schedules remain unexplored.
- Conditioning dropout (Stage 1) has no sensitivity analysis: dropout rate p and its impact on avoiding prompt-copying vs. learning genuine video-to-text mappings are not evaluated.
- “Capability Refinement” depends on detailed captions but lacks diagnostics: improvements in fine-grained grounding (attributes, relations, temporal dynamics) are not quantified or visualized (e.g., attention maps, localization probes).
- Joint sampling control is under-specified: when denoising both modalities from noise, how content is steered (e.g., with or without prompts) and how semantic drift/alignment failures are handled is not discussed.
- Controllability and editing are unaddressed: negative prompts, style control, motion control, and instruction-conditioned editing are not studied within the uni-flow framework.
- Robustness is untested: no evaluation under video artifacts (compression, occlusions), adversarial prompts, or distribution shifts.
- Safety and ethics are not considered: content moderation, harmful content risks, bias/fairness assessments, and misuse mitigations are missing.
- Multimodal extensibility is unproven: extension to audio, speech, images, 3D/embodied inputs, or additional modalities is posited but not demonstrated.
- Resolution/duration scalability is unknown: performance and efficiency at higher resolutions (e.g., 1080p/4K) and longer videos (e.g., 30–60s) are not evaluated.
- Mutual consistency metrics for joint generation are missing: no objective measures (e.g., CLIPScore/VideoCLIP alignment between generated video and text) to verify cross-modal coherence.
- Data and code reproducibility are unclear: curated datasets, prompts, captions, preprocessing tools, and training scripts are not documented/released; seed sensitivity and variance across runs are unreported.
- Theoretical grounding of “share attention, split FFN” is not validated: no probing or causal analyses demonstrate that alignment resides in attention while modality-specific knowledge resides in FFNs.
- Transfer to discriminative heads is unexplored: whether unified representations help downstream classifiers/segmenters/localizers with lightweight heads is not tested.
- Multilingual and cross-lingual capabilities are not evaluated: despite using umT5 for conditioning, the generated text branch’s tokenization and multilingual competence are unspecified.
- Alignment beyond captioning is untested: no cycle-consistency, contrastive alignment, or retrieval-based objectives are explored to further tighten video–text coupling.
- Failure modes are not analyzed: examples of semantic drift, repetitive text, generic captions, temporal misalignment, or mode collapse are not cataloged or mitigated.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating Uni-ViGU’s generation-centric architecture, unified flow matching, and bidirectional training into existing tools and workflows.
- Automated detailed video captioning and summarization — sectors: media platforms, education, accessibility
- Description: Use the video-to-text pathway to produce fine-grained captions and summaries for UGC, lectures, tutorials, and corporate training videos; improves accessibility (subtitles) and discoverability.
- Tools/workflows: “CaptionAssist” API or plug-in for CMS/video platforms; batch captioning pipelines; editor integrations for subtitle tracks and semantic scene descriptions.
- Assumptions/dependencies: Domain alignment between deployment videos and pretraining data; GPU availability for processing; safety filters for inappropriate content; multilingual support depends on text encoder adaptation.
- Semantic video indexing and search — sectors: software, media archives, enterprise content management
- Description: Generate discriminative shared representations and detailed textual metadata to enable semantic tagging, topic clustering, and retrieval over large video libraries.
- Tools/workflows: “Unified Video Indexer” service combining caption outputs with embeddings; integration with vector databases and enterprise DAM systems.
- Assumptions/dependencies: Reliable video understanding on in-domain content; scalable storage/embedding infrastructure; moderation and compliance tagging layered on top.
- Content moderation and compliance screening — sectors: policy, trust & safety, ad tech
- Description: Convert videos to detailed, policy-checkable descriptions for automated screening (e.g., violence, self-harm, brand safety, legal compliance).
- Tools/workflows: Moderation pipeline where Uni-ViGU provides captions plus risk signals to rule-based/ML classifiers; audit logs storing video-text pairs.
- Assumptions/dependencies: Robust classification layer; clear policy taxonomies; adversarial robustness; human-in-the-loop review.
- Joint video+copy generation for marketing and creative teams — sectors: advertising, social media, creator economy
- Description: Generate short-form videos with matching copy (product descriptions, hooks, CTAs) in a single pass, enabling fast A/B experimentation.
- Tools/workflows: “Joint Video+Copy Generator” studio; prompt templates for campaigns; brand guidelines constraints; batch variant generation.
- Assumptions/dependencies: Compute budgets for multi-iteration denoising; prompt hygiene; brand-safety controls; licensing for any external assets.
- Synthetic data factories for vision-language training — sectors: academia, computer vision, MLLM/AV research
- Description: Co-generate videos and richly annotated captions to bootstrap training datasets for downstream recognition, grounding, and reasoning tasks.
- Tools/workflows: Data generation pipelines with scenario prompts; curriculum scheduling (coarse-to-fine captions); metadata normalization.
- Assumptions/dependencies: Domain fidelity vs. real-world variance; potential bias in synthetic content; licensing and provenance for datasets; validation against real benchmarks.
- Previsualization and storyboard co-pilots — sectors: film, game development, animation
- Description: Rapidly prototype scenes and generate descriptive scripts; iterate on mood, camera movement, and actions with synchronized text.
- Tools/workflows: “Previz Co-Pilot” inside DCC tools; shot lists auto-derived from captions; versioned scene beats.
- Assumptions/dependencies: Temporal coherence across frames; compute constraints for longer sequences; production-specific fine-tuning.
- Accessibility and personal productivity apps — sectors: daily life, accessibility tech
- Description: Auto-caption and summarize personal recordings, lectures, meetings, and sports footage; generate highlights with textual notes.
- Tools/workflows: Mobile/desktop apps; cloud inference with privacy controls; offline batching.
- Assumptions/dependencies: Privacy-by-design; edge/offline feasibility limited by model size; potential need for language/domain adaptation.
- Video question answering and assisted review — sectors: customer support, training, e-learning
- Description: Enable Q&A over videos by producing detailed captions plus retrieval over shared representations; assist instructors and support teams in content review.
- Tools/workflows: “Video QA API” combining caption outputs and retrieval; UI overlays for timestamped answers.
- Assumptions/dependencies: Task-specific fine-tuning on QA datasets; reliable timestamp alignment; handling ambiguous content.
- Editing assistance and semantic cut suggestions — sectors: video software, creator tools
- Description: Use generated descriptions to propose cuts, segment boundaries, and highlight reels; suggest alt-text and thumbnails aligned with content.
- Tools/workflows: NLE plug-ins; semantic scene segmentation; caption-driven edit decision lists.
- Assumptions/dependencies: Stable shot-boundary detection; integration with editor timelines; human approval loops.
Long-Term Applications
These applications will benefit from further research, scaling, and engineering to reach production robustness or domain breadth.
- Real-time, on-device unified video understanding/generation for AR/XR — sectors: hardware, AR/VR
- Description: Stream visual understanding and lightweight generation overlays on wearables for guidance, translation, or safety cues.
- Tools/products: Edge-optimized DiT/uni-flow variants; distillation and quantization toolchains; sensor fusion with IMU/SLAM.
- Assumptions/dependencies: Major efficiency gains; fast ODE solvers; heat/power constraints; low-latency memory bandwidth.
- World-simulator training loops for robotics and autonomy — sectors: robotics, autonomous driving, industrial automation
- Description: Use joint video-text generation as richly annotated simulation to pretrain policies and perception models; unify narration of scene dynamics with visual rollouts.
- Tools/products: “Sim-to-Policy” pipelines; RL/IL frameworks ingesting synthetic episodes plus captions; scenario generators.
- Assumptions/dependencies: Physical realism and causal consistency; domain transfer to real sensors; safety validation; large-scale compute.
- Text-guided video editing via uni-flow conditioning — sectors: creative software, post-production
- Description: Perform precise edits (style transfer, object insertion/removal, motion retiming) by co-evolving text and video latents under unified flow constraints.
- Tools/products: “Flow-based Video Editor” with inversion, mask-aware conditioning, and prompt-time editing.
- Assumptions/dependencies: Editing-specific training data; robust inversion to latents; fine-grained controls and guardrails.
- Multimodal digital twins with semantic overlays — sectors: manufacturing, energy, smart cities
- Description: Create simulated processes where videos and textual incident reports co-evolve, enabling operators to train on scenarios and procedures.
- Tools/products: Ops training simulators; incident replay with synchronized captions; analytics dashboards.
- Assumptions/dependencies: Domain datasets; integration with SCADA/IoT streams; regulatory approvals; fidelity to physical processes.
- Healthcare education and procedural training — sectors: healthcare, medical education
- Description: Generate and understand procedural videos with step-by-step narration for training clinicians; create annotated libraries.
- Tools/products: “Med-Previz” studio; skill assessment via caption-to-procedure matching; privacy-preserving content pipelines.
- Assumptions/dependencies: Clinical validation; patient privacy and compliance; domain-specific fine-tuning; risk management for hallucinations.
- Personalized education content and tutors — sectors: edtech
- Description: Produce lesson videos with aligned scripts, auto-assess learners via video responses, and adapt pacing using understanding signals.
- Tools/products: Course authoring suites; interactive lessons with video+text co-evolution; assessment engines.
- Assumptions/dependencies: Pedagogical alignment; factuality guarantees; bias/fairness audits; multilingual instruction capability.
- Content provenance and watermarking standards for video+text pairs — sectors: policy, platform governance
- Description: Mandate provenance tags and synchronized captions for generated media; audit pipelines that bind video and text outputs cryptographically.
- Tools/products: Watermarking libraries; ledger-backed provenance; policy dashboards linking captions to trust signals.
- Assumptions/dependencies: Industry standards; robust watermarking under transformations; user education and adoption.
- Extension to audio, 3D, and interactive modalities — sectors: media, XR, gaming
- Description: Generalize uni-flow to synchronize audio waveforms or 3D scene graphs with video and text, enabling tri-modal generation and understanding.
- Tools/products: “Tri-Modal Uni-Flow” (audio-video-text); “SceneFlow” (video-3D-text) for XR content creation and analysis.
- Assumptions/dependencies: New datasets and encoders/decoders (audio VAEs, NeRF/mesh latents); training stability for coupled modalities.
- Multilingual and cross-cultural localization at scale — sectors: localization, global media
- Description: Jointly generate region-specific videos and culturally appropriate copy; auto-localize captions and scripts.
- Tools/products: Localization pipelines; culturally-aware prompt libraries; QA on correctness and sensitivity.
- Assumptions/dependencies: Broad multilingual training; cultural context modeling; evaluation benchmarks; in-market review.
- Enterprise knowledge mining from video — sectors: enterprise software, compliance, HR/L&D
- Description: Convert internal training, safety, and meeting recordings into structured, searchable knowledge with action items and compliance evidence.
- Tools/products: “Video Knowledge Miner” connecting captions to taxonomies and workflows (tickets, SOP updates).
- Assumptions/dependencies: Data governance; secure deployment; taxonomy design; adaptation to domain jargon.
Notes on feasibility across applications:
- Compute and latency: Diffusion-based video generation remains expensive; many applications rely more on understanding (cheaper) or on batch generation/offline workflows.
- Data quality: Capability Refinement hinges on high-quality, detailed captions; weak or biased target text will propagate errors.
- Domain adaptation: Pretraining on general video may not transfer to specialized domains (healthcare, industrial); targeted fine-tuning and evaluation are needed.
- Safety and compliance: Generated content and captions must pass policy filters; provenance and watermarking are advisable in regulated or public-facing contexts.
- Integration: Production systems require robust APIs, observability, and fallback/human-in-the-loop mechanisms to handle edge cases and failures.
Glossary
- 3D convolution layers: Neural network layers that convolve across three dimensions (time, height, width) to capture spatiotemporal features in videos. "uses 3D convolution layers to sequentially encode each chunk into a compact latent representation."
- Asymmetric initialization: An initialization strategy where different parts of a model are initialized differently to leverage prior knowledge in some components while adding new capacity in others. "This asymmetric initialization, combined with the shared-attention design, yields three practical benefits"
- Autoregressive sequence prediction: A modeling approach that generates outputs one token at a time, conditioning on previously generated tokens. "formulate image generation as an autoregressive sequence prediction problem within multimodal LLMs (MLLMs)."
- Bidirectional training mechanism: A training approach that teaches a model to map in both directions between modalities (e.g., text↔video) to reuse knowledge. "we design a bidirectional training mechanism with two stages"
- Capability Refinement: A fine-tuning stage focused on producing detailed, semantically precise outputs to improve understanding. "Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations."
- Causal generation: Generation that proceeds in a fixed directional order (e.g., left-to-right in text), where each step depends only on past outputs. "such causal generation often yields limited visual fidelity"
- Causal VAE: A variational autoencoder that processes sequences with causal (temporal) structure, respecting ordering over time. "WAN2.1 adopts a causal VAE that decomposes a video into a set of chunks"
- Condition dropout: A regularization technique that randomly drops conditioning inputs to prevent trivial copying and encourage reliance on other signals. "we apply condition dropout"
- Continuous flow matching: A diffusion-style training objective in continuous spaces that learns a velocity field transporting noise to data. "continuous flow matching for video"
- Cross-attention: An attention mechanism where queries from one sequence attend to keys/values from another, enabling conditioning across modalities. "a cross-attention layer"
- Cross-modal alignment: The consistent mapping between different modalities’ representations (e.g., text and video) so they correspond semantically. "share attention to preserve cross-modal alignment"
- Cross-modal dependencies: Statistical relationships between different modalities that a model learns to leverage jointly. "enabling the model to learn cross-modal dependencies"
- Denoising: The iterative process of removing noise to recover clean data samples in diffusion models. "iterative denoising steps"
- Diffusion Transformers (DiT): Transformer-based architectures used as the backbone for diffusion models in image/video generation. "WAN2.1 adopts Diffusion Transformers (DiT) as its diffusion model."
- Diffusion-based language modeling: Generating text by modeling token embeddings with diffusion/flow processes instead of autoregressive prediction. "Drawing inspiration from recent advances in diffusion-based language modeling"
- Discrete flow matching: Applying flow matching to discrete data by operating over continuous token embeddings instead of raw symbols. "discrete flow matching for text"
- Dual-tower unified framework: An architecture with separate branches (towers) for understanding and generation that are integrated, often via attention. "proposes a dual-tower unified framework to couples understanding and generation."
- Embedding lookup: Converting continuous embeddings back to discrete tokens by selecting the nearest embedding in the vocabulary. "decoded to tokens via embedding lookup."
- Flow matching: A training paradigm that learns the velocity field transporting samples from noise to data along a prescribed path. "WAN2.1 follows flow matching"
- Generative priors: Previously learned generative knowledge that guides new tasks, helping maintain high-quality synthesis. "preserving generative priors."
- Gaussian noise: Random noise drawn from a normal distribution used as the starting point for diffusion-based generation. "At test time, generation begins from Gaussian noise"
- Joint video-text generation: Simultaneous generation of both video and its corresponding text within a single process. "As for the joint video-text generation, both modalities are initialized from noise"
- Latent diffusion: Performing diffusion in a compressed latent space rather than pixel space to improve efficiency. "adopts a standard latent diffusion paradigm"
- Latent space: A lower-dimensional representation space (e.g., produced by a VAE) where diffusion or modeling is performed. "this procedure is typically performed in the latent space"
- Learnable query tokens: Trainable tokens that interface a frozen LLM with diffusion modules to enable generation. "introduce a set of learnable query tokens"
- Mixture-of-Experts (MoE): An architecture with multiple expert subnetworks, with inputs routed to different experts (here, by modality). "structured Mixture-of-Experts (MoE)"
- Non-autoregressive language modeling: Text generation without step-by-step dependency on previous tokens, enabling parallel or denoising-based decoding. "non-autoregressive language modeling scales competitively"
- ODE solver: A numerical integrator that solves ordinary differential equations to follow the learned velocity field during inference. "At inference, an ODE solver integrates this field"
- Self-attention: An attention mechanism where tokens attend to others within the same sequence to capture dependencies. "a self-attention layer"
- Spatiotemporal priors: Prior knowledge about spatial and temporal regularities in videos learned during pretraining. "leveraging their rich spatiotemporal priors as a more scalable foundation."
- Token embeddings: Continuous vector representations of discrete vocabulary tokens used for modeling and decoding. "the manifold of valid token embeddings"
- Token-count normalization: Adjusting loss weights by the number of tokens per modality to balance supervision. "token-count normalization ensures that each modality receives balanced per-token supervision."
- Transport path: The interpolation path from noise to data along which the model learns a velocity field in flow matching. "This formulation defines a transport path from noise to data "
- Uni-flow: A single generative process that jointly handles continuous (video) and discrete (text) flow matching. "we propose a uni-flow process"
- Variational autoencoder (VAE): A generative model that learns to encode data into a latent space and decode it back, enabling latent diffusion. "via a variational autoencoder (VAE)"
- Velocity field: The vector field that indicates the direction and magnitude of change along the transport path from noise to data. "using the learned velocity field"
- Video-to-text generation: Generating textual descriptions from video content within the same generative framework. "repurposed for video-to-text generation"
- Learned gating mechanisms: Trainable routers that select which expert processes each token in conventional MoE setups. "learned gating mechanisms"
Collections
Sign up for free to add this paper to one or more collections.

