- The paper introduces HumanGS, a feed-forward system that constructs animatable 3D avatars from sparse images using vertex-aligned Gaussian primitives.
- It employs a transformer with intermediate feature aggregation to preserve high-frequency details, achieving near state-of-the-art performance in reconstruction metrics.
- Its decoupled animation via linear blend skinning enables real-time model building and rendering, significantly reducing computation time compared to iterative methods.
Real-Time Feed-Forward Gaussian Splatting for Human Reconstruction and Animation
Introduction and Motivation
Explicit and efficient human avatar reconstruction and animation remain central challenges in neural rendering, complicated by articulated movement, non-rigid deformations, and observation sparsity. The paper "Real-Time Human Reconstruction and Animation using Feed-Forward Gaussian Splatting" (2604.10259) introduces HumanGS, a novel generalizable, feed-forward system that constructs animatable 3D human avatars from sparse multi-view images and associated SMPL-X poses without relying on classical depth supervision or iterative per-pose network inference. By generating an explicit canonical set of 3D Gaussian primitives aligned with SMPL-X vertices, HumanGS fundamentally decouples representation learning from animation, supporting efficient, real-time re-pose synthesis.
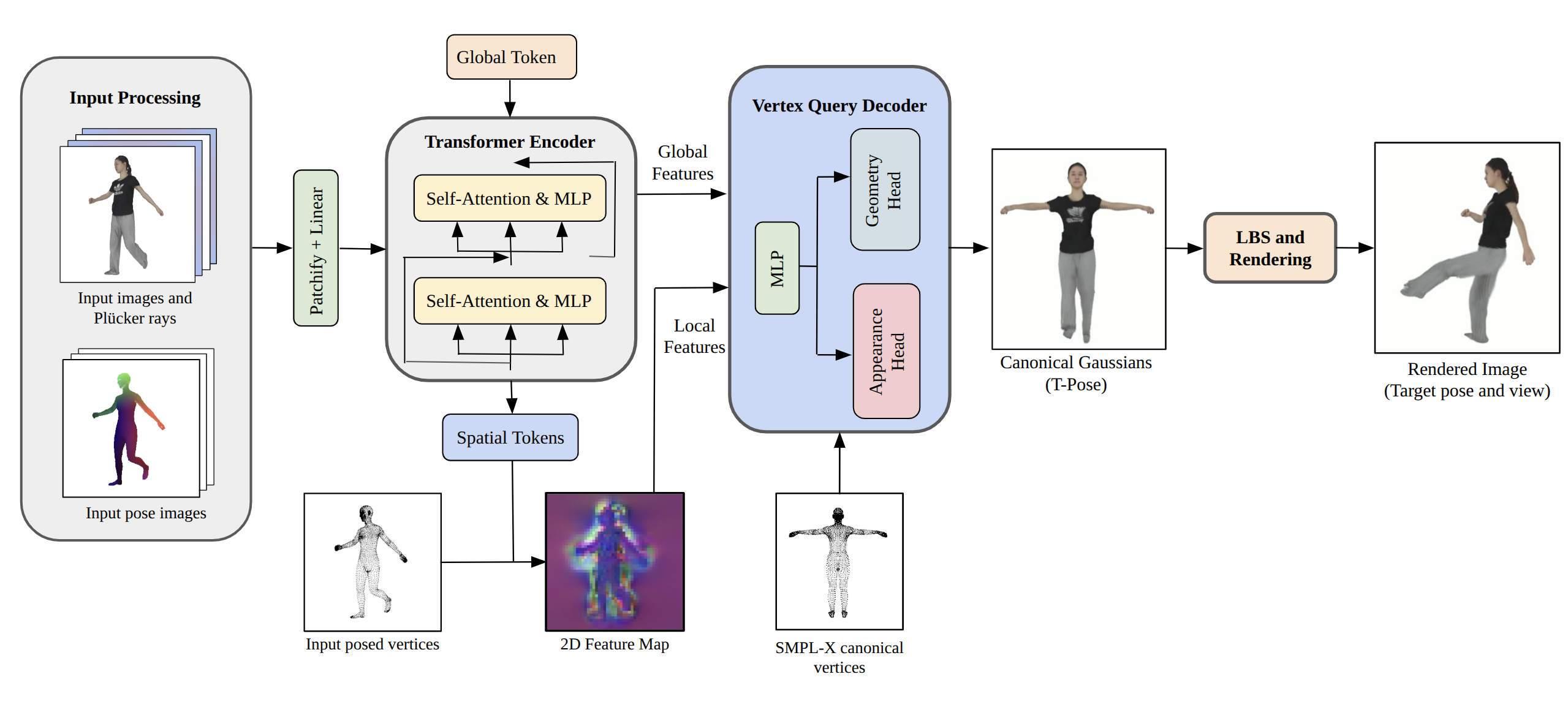
Figure 1: Overview of the HumanGS architecture: sparse input images and pose maps are encoded via a transformer, global 2D features are learned, and vertex-aligned sampling assigns local features to canonical SMPL-X mesh locations for 3DGS asset prediction.
Methodological Contributions
HumanGS is architected on the transformer-based LVSM paradigm for multi-view feature aggregation. Sparse RGB images, together with pose image maps derived from neural texture projections on SMPL-X, are tokenized alongside camera parameters, delivering robust spatial context to a transformer encoder. The architecture makes critical use of an Intermediate Feature Aggregation Module to preserve high-frequency details by combining feature maps from four depths of the transformer and upsampling to a high spatial resolution for downstream geometry prediction.
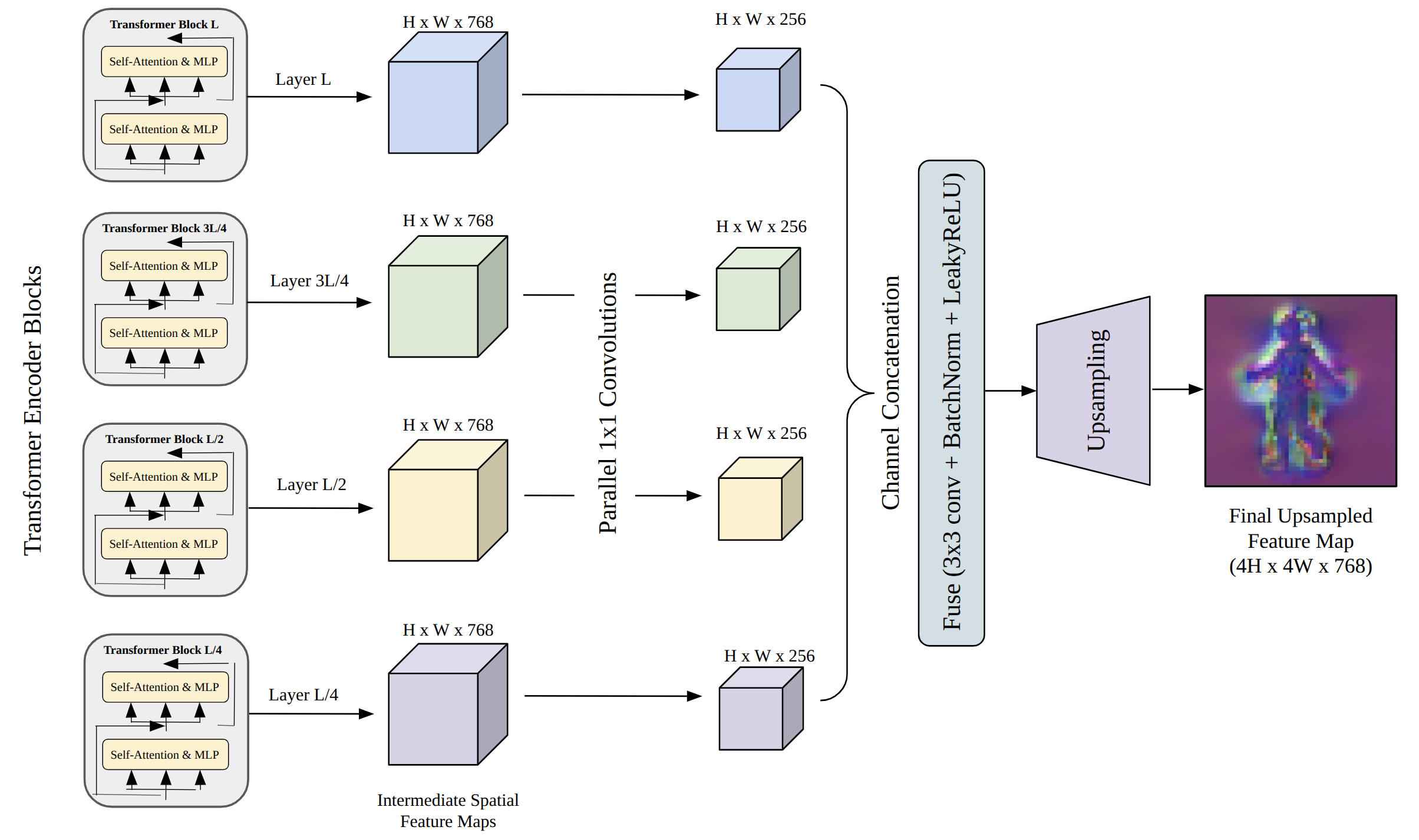
Figure 2: Intermediate features extracted at varied transformer depths are fused and upsampled to form a dense, high-resolution feature map.
The aggregation mechanism addresses transformer over-smoothing of fine details, as quantitatively confirmed by patch-based LPIPS evaluation and qualitative visualization: inclusion of intermediate features substantially improves the fidelity of high-frequency clothing textures and sharpness compared to terminal-layer-only maps.
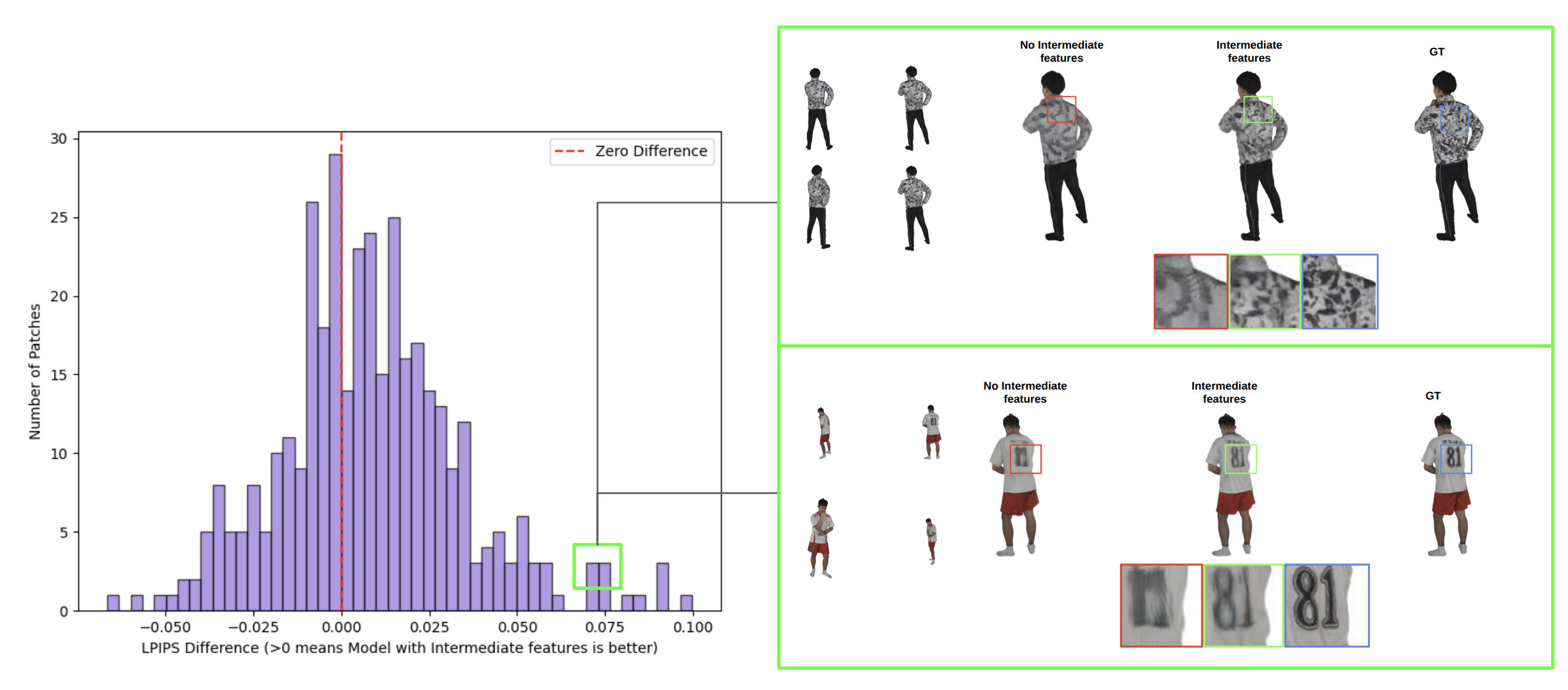
Figure 3: Aggregation of intermediate features consistently recovers fine details lost in standard single-layer aggregation frameworks.
Vertex-Aligned Canonical 3D Gaussian Regression
Core to HumanGS is regressing parameters for K=5 3D Gaussians per SMPL-X vertex in the canonical T-pose: one "tight" primitive (strongly regularized to the SMPL surface) and four "free" primitives (permitting geometric deviation for clothing/hair). Features sampled via per-vertex projection onto the upsampled feature map are concatenated with global context and positional information, then mapped to 3DGS parameters via a multi-head MLP. Losses include MSE, perceptual loss, and a "tightness" geometrical regularization term penalizing excessive offset of tight Gaussians.
Efficient Animation: Decoupling Inference from Rendering
Animation is made explicit: once canonical Gaussians are predicted for an actor, arbitrary pose transformations are effected solely by linear blend skinning (LBS) according to SMPL-X weights, requiring no additional network inference at test time. The posed asset is rasterized using 3D Gaussian splatting to synthesize the desired viewpoint and configuration.
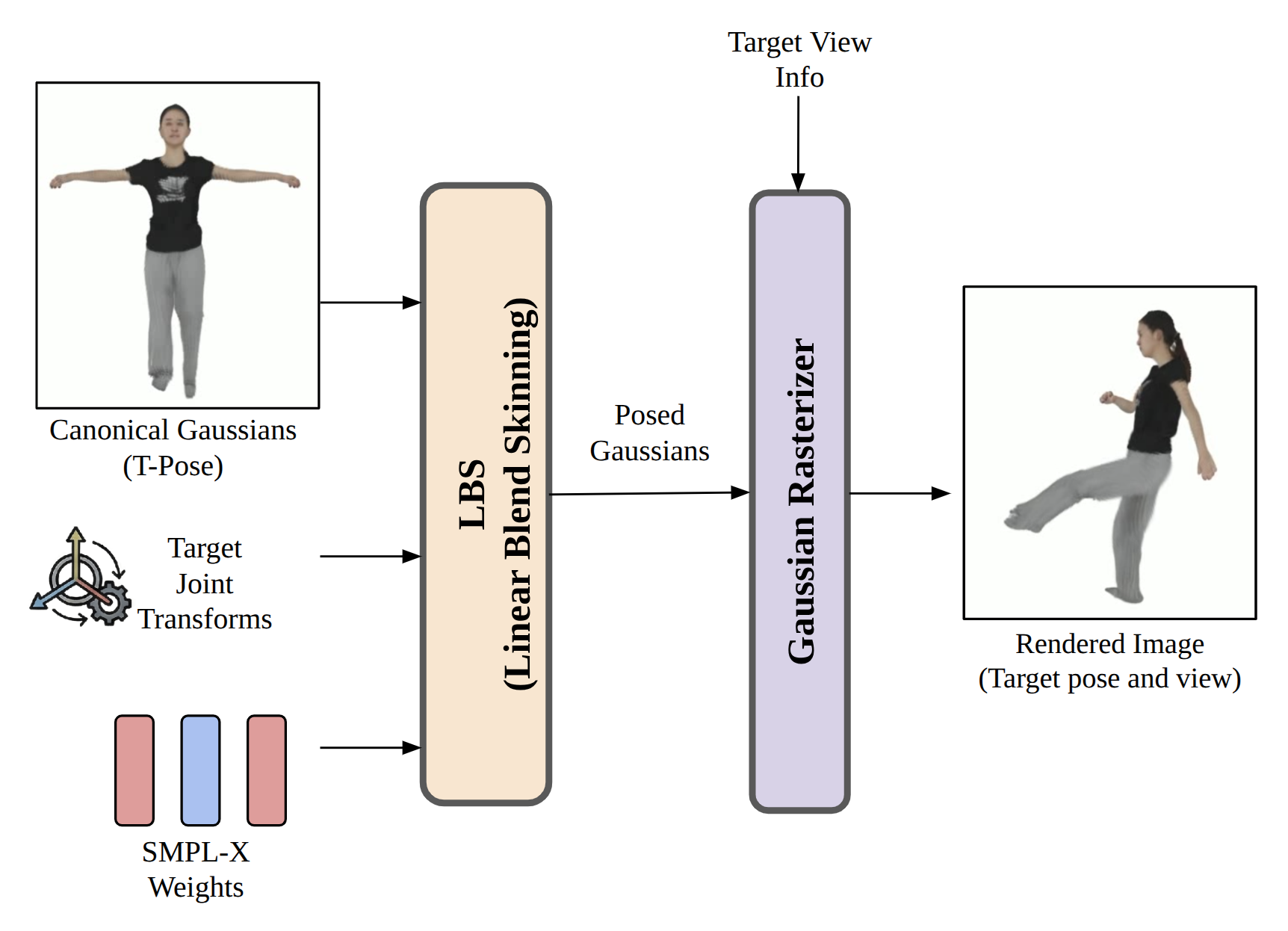
Figure 4: Canonical Gaussians are efficiently animated by LBS and rendered via Gaussian rasterization, bypassing any further neural inference.
Experimental Validation
Comparative Evaluation
Extensive experiments were performed on THuman 2.1, THuman 4.0, and AvatarReX datasets under both fixed-pose NVS and animatable NVS settings. HumanGS was evaluated against representative transformer (HumanRAM), convolutional (GHG, LVSM), transformer-single-image (GST), and optimization-based (Animatable Gaussians) baselines.






Figure 6: Visual comparison highlights HumanGS's ability to match or exceed the synthesis quality of HumanRAM while supporting direct animation.



Figure 7: Sparse inputs yield consistent, re-poseable canonical avatars, validated by animation on out-of-distribution motion capture.
Generalization, Ablation, and Robustness
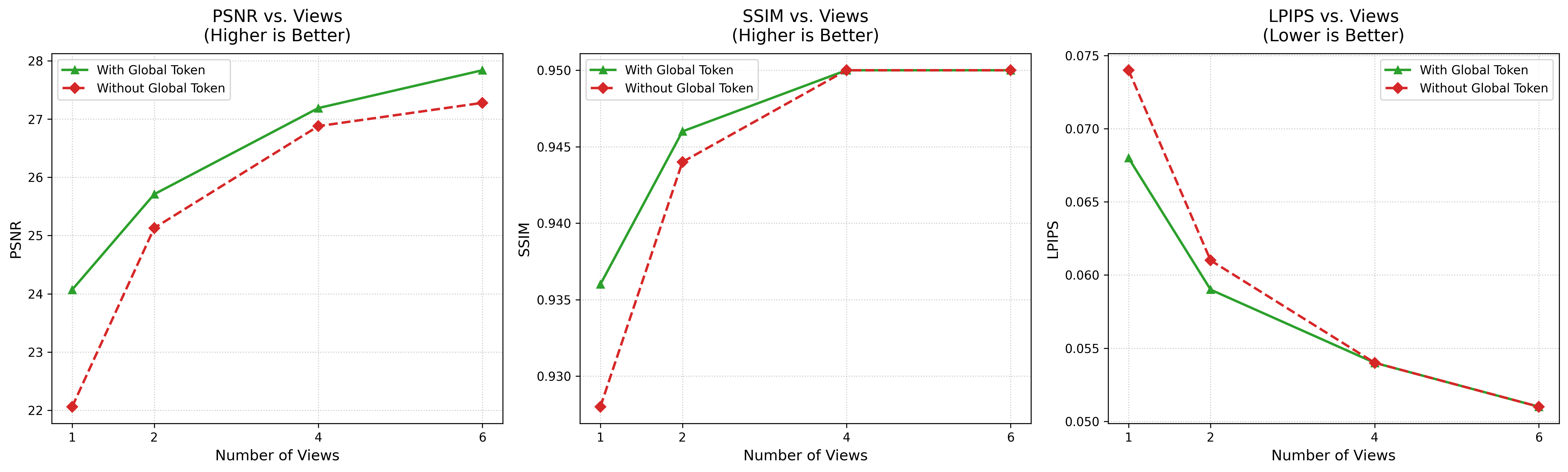
HumanGS demonstrates strong cross-dataset generalization and maintains detail even in the sparse-view setting (N=1,2), outperforming competitors under such conditions both quantitatively and perceptually.
Implications and Future Directions
HumanGS's explicit canonical representation framework has both immediate practical and theoretical implications:
- Practical Deployment: The ability to synthesize animatable avatars from a handful of posed images in under a second, and re-animate at real-time rates, facilitates integration into VR/AR, telepresence, and content creation pipelines unsuitable for slow, per-pose optimization or repeated inference.
- Theoretical Implications: The architectural decoupling of feature aggregation, canonicalization, and animation suggests new directions for fast, reusable, and generalizable asset creation in neural rendering. The canonical per-vertex Gaussian paradigm provides a substrate for integrating learned deformation models, clothing transfer, and even dynamic non-rigid effects without requiring recurrent neural passes.
- Future Developments: The authors point to temporal modeling for handling complex dynamic deformations as a key research avenue. Combining the HumanGS paradigm with learned implicit surface deformations, texture transfer, or diffusion-based generative priors could further expand its practical utility and domain of generalization.
Conclusion
HumanGS presents a significant step in efficient, generalizable 3D human reconstruction and animation. By decoupling canonical asset prediction (in a single feed-forward transformer pass) from explicit LBS-based animation and rasterization, it streamlines avatar creation for interactive environments. HumanGS achieves strong quantitative and perceptual fidelity, rapid modeling times, real-time synthesis, and robust generalization—enabling practical deployment in scenarios where previous approaches were computationally prohibitive or inflexible. The explicit, reusable representation formulated here sets the stage for future research in scalable, learning-based human avatar synthesis and manipulation, particularly in resource-constrained or real-time interactive settings (2604.10259).