Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
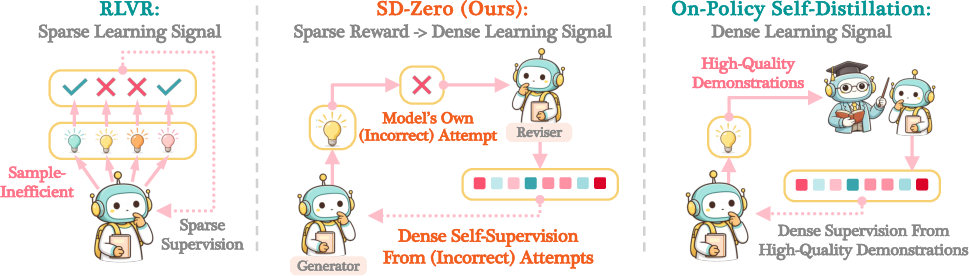
Abstract: Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (overview)
This paper introduces a new way to train AI models to solve math and coding problems better. The method is called Self-Distillation Zero (SD‑Zero). It teaches a single model to first write an answer, then revise that answer using only a simple “right or wrong” signal, and finally learn from its own revision. In short: the model turns a simple thumbs‑up/thumbs‑down into detailed, word‑by‑word guidance for itself—without needing a stronger outside teacher.
What the researchers wanted to figure out
- Can an AI learn good step‑by‑step reasoning using only a simple “correct/incorrect” check at the end of each answer, instead of lots of expensive, detailed solutions?
- Can the model act as both a “student” (who tries an answer) and a “teacher” (who revises that answer) so it can teach itself?
- Can this self‑teaching be more efficient than reinforcement learning (which usually needs many sampled attempts) and work without any external expert examples?
How the method works (in simple terms)
Think of a model as a student who also learns to be their own teacher. SD‑Zero has two phases.
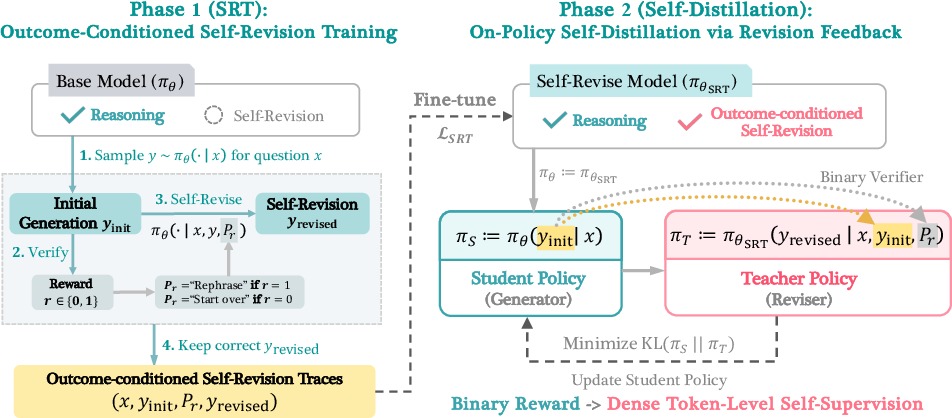
Phase 1: Self‑Revision Training (learning to revise)
- The model tries a problem and writes an answer.
- We check if the final answer is correct (just a yes/no).
- If it’s wrong, we prompt the model to revise its solution; if it’s right, we ask it to rephrase.
- We keep only the cases where the revision ends up correct.
- We train the model on two skills at once:
- Revision: improve or rephrase an earlier attempt when told whether it was right or wrong.
- Generation: solve from scratch, so it doesn’t forget how to answer without revising.
Analogy: The student writes an essay, gets a simple “good” or “needs fixing,” then rewrites it. They practice both revising and writing cleanly from the start.
Phase 2: Self‑Distillation (learning from your better self)
- Now the model plays two roles:
- Generator (student): writes a fresh answer.
- Reviser (teacher): looks at that answer plus the correct/incorrect signal and produces a “better” word‑by‑word guide.
- We train the student to match the teacher’s word‑by‑word choices—basically, to imitate the reviser.
- This turns a single yes/no outcome into detailed, token‑level feedback at every word, making learning much richer and faster.
Analogy: The student writes an essay; their “teacher self” rewrites it line by line. The student then practices imitating that improved version, so next time they write better from the start.
Key ideas explained:
- Binary reward = a simple final check: correct (1) or incorrect (0).
- Dense supervision = detailed feedback on each word/token, not just the final result.
- On‑policy = the teacher revises the student’s actual attempt, not a hypothetical example.
What they found (main results)
- Big gains without outside teachers: On tough math and coding benchmarks, SD‑Zero improved two different base models (Qwen3‑4B and Olmo‑3‑7B) by about 10% over their original performance.
- Better than strong baselines under the same budget: It outperformed methods like Rejection Fine‑Tuning (RFT), a popular reinforcement learning approach (GRPO), and other self‑distillation methods that need expert solutions (SDFT), by around 5% on average.
- Efficient training and shorter answers:
- Phase 1 (self‑revision) alone gave large boosts, but the answers got long because the model tended to think out loud and revise mid‑response.
- Phase 2 (self‑distillation) made answers more direct and about 2× shorter while improving accuracy further.
- Training in Phase 2 needs only one attempt per question (sample‑efficient), unlike many RL setups that need groups of attempts.
- Two especially interesting behaviors:
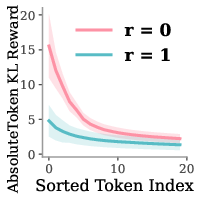
- Token‑level self‑localization: The reviser doesn’t just say “wrong”—it focuses feedback on the exact words or steps that caused the mistake, and nudges the model toward a better route.
- Iterative self‑evolution: After some training, the improved student can replace the teacher, leading to another round of gains (about +3%) without outside data. It’s like the student keeps promoting themselves to a better teacher.
Why this matters (impact)
- Less reliance on expensive resources: SD‑Zero doesn’t need expert solution write‑ups or a stronger external teacher model—just a simple correct/incorrect checker. That’s far easier to get for tasks like math and programming.
- Faster progress with fewer tries: By turning a yes/no result into detailed, word‑by‑word guidance, the model learns more from each attempt. This can speed up training and reduce cost.
- Better, more concise reasoning: The model learns to spot likely pitfalls and aim straight for good answers, which is useful in real applications where long, rambling outputs are slow and costly.
- A path to continual self‑improvement: Because the student can become the teacher, models can keep improving themselves over time with simple feedback signals.
In short, SD‑Zero shows how an AI can use simple “thumbs up/thumbs down” checks to produce its own rich feedback and steadily teach itself to reason better—making advanced training more practical and widely available.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide future research.
- Generalization to long “thinking” chains of thought: How to adapt SD-Zero when generations contain exploratory false starts and partial corrections that are not errors, i.e., credit assignment at trajectory-level rather than local tokens; what supervision and objectives avoid penalizing productive exploration.
- Extension beyond verifiable domains: How to define reliable rewards without ground-truth answers or testcases (e.g., open-ended QA, summarization, safety-aligned generation); which meta-cognitive proxies (consistency, self-checks) are robust, and how to prevent reward hacking.
- Robustness to reward noise and ambiguity: Sensitivity to incorrect or noisy final-answer extraction, incomplete/weak test suites for code, multi-answer math problems, or numeric formatting issues; methods to make SD-Zero robust to such noise.
- Dependence on successful revision traces in Phase 1: The SFT Phase trains only on correct self-revisions; how does the method perform when revision success rates are low (e.g., harder tasks, weaker models), and would incorporating failed revisions (with appropriate labels) improve robustness.
- Sampling budget and success-rate reporting: The paper does not quantify revision success rates, number of samples required per example to obtain a usable trace, or how these scale with task difficulty and model size; such measurements are needed to assess practical data costs.
- Stability and convergence of iterative teacher synchronization: How many synchronization rounds yield gains, when (and why) improvements plateau, and whether the self-improvement loop can drift, oscillate, or amplify subtle errors; need for diagnostics and safeguards.
- Compute- and wall-clock efficiency: While sample efficiency is emphasized, the actual FLOPs, training time, and memory footprint of Phase 1 multi-sampling and Phase 2 token-level teacher forward passes are not reported; head-to-head cost comparisons with GRPO/RL are needed.
- Objective design choices: The distillation uses forward KL; how do reverse KL, symmetric JS, temperature scaling, or weighting schedules affect pass@1 vs pass@k, diversity, and calibration.
- Prompt and control-signal sensitivity: The outcome prompts (“rephrase” vs “start over”) may strongly influence concision and behavior; robustness to phrasing, languages, domains, and alternative control schemes remains untested.
- Validation of token-level “self-localization”: The evidence relies on KL-based proxies; does high-KL mass actually align with true error spans or faulty reasoning steps, as verified by human or heuristic annotations; need precision/recall-style evaluations.
- Behavioral side effects of concision: SD-Zero reduces tokens substantially; does this shorten necessary explanations or degrade interpretability/user satisfaction; human evaluation of explanation quality and completeness is missing.
- Distribution shift and transfer: Generalization across unseen math subdomains, different programming languages (beyond C++/Python), varied coding benchmarks, or non-competition math remains untested; cross-domain transfer from math→code and vice versa is also unexplored.
- Model-size scaling laws: Results cover 4B and 7B models; how do gains scale to larger frontier models or smaller distilled models; do SFT Phase success rates, revision quality, and distillation efficacy change with capacity.
- Combining with RL: Whether SD-Zero pretraining improves RL sample efficiency or final performance, or whether alternating/interleaving with RL (e.g., GRPO/DAPO) yields complementary gains, is not investigated.
- Graded/continuous rewards: Many settings (e.g., partial unit tests passing) yield scalar rewards in (0,1); how to exploit richer signals within the reviser conditioning and the distillation objective is not evaluated.
- Safety, bias, and alignment: In non-verifiable tasks, self-distillation may reinforce existing biases or unsafe behaviors when guided by weak proxies; methods to detect and mitigate such risks are unaddressed.
- Failure-mode analysis: The paper lacks systematic analysis of where SD-Zero fails (problem types, error categories, code failure patterns) and how revision attempts fail, which would inform targeted improvements.
- Hyperparameter and schedule sensitivity: Limited ablations leave open sensitivity to data splits, KL weights, temperatures, number of on-policy samples, and synchronization cadence; guidance for robust defaults is missing.
- Inference-time revision strategies: The final model internalizes revision, but when should explicit generate-then-revise still be used; can multi-pass inference (with reward-conditioned revision) trade more tokens for higher accuracy.
- Multi-turn and interactive settings: Extension to dialogue or iterative user-in-the-loop workflows, where rewards arrive across turns, is unstudied.
- Multi-modality and other task formats: Applicability to multimodal reasoning (e.g., VQA with verifiable answers), structured prediction, or planning tasks remains an open question.
- Reproducibility and release details: The paper does not specify whether code, prompts, and curated self-revision datasets will be released in a way that enables faithful reproduction and further study.
Practical Applications
Practical Applications of SD-Zero (Self-Distillation Zero)
SD-Zero trains a single model to act as both a generator and a reviser, converting binary rewards (e.g., pass/fail, correct/incorrect) into dense token-level supervision without requiring external teachers or curated high-quality demonstrations. Below are actionable applications that leverage its sample and compute efficiency, token-level self-localization, and iterative self-evolution.
Immediate Applications
The following can be deployed now in settings where binary/verifiable rewards are available.
- Code assistants fine-tuned with tests (Software/DevTools)
- Use case: Improve code generation and bug-fixing by using unit/integration test pass/fail as the binary reward; distill reviser behavior into the generator to produce higher-quality code with fewer tokens.
- Potential tools/products/workflows: SD-Zero–powered CI/CD modules that collect on-policy attempts and self-revision traces; IDE plugins that run local tests and perform on-policy self-distillation nightly.
- Assumptions/Dependencies: Reliable, representative tests; stable sandboxes/runtimes; guardrails against train–eval contamination; compute to perform on-policy sampling.
- SQL and data transformation with schema validation (Data/ETL, Analytics)
- Use case: Generate SQL queries or transformation scripts and validate with schema checks, constraints, and small sample tests; pass/fail feedback drives dense self-supervision.
- Potential tools/products/workflows: “Binary2Dense” SDK wrappers for dbt/Spark pipelines; dashboards that track token-length reduction and accuracy after self-distillation.
- Assumptions/Dependencies: Accurate validators and representative test datasets; clear extraction/formatting rules.
- Document conversion and structured form filling (Enterprise automation)
- Use case: Convert unstructured documents to structured formats (e.g., invoices, claims) using JSON Schema or regex validators for binary rewards.
- Potential tools/products/workflows: RPA connectors that collect self-revision traces; validators-as-a-service integration for claim/invoice schemas; automated teacher synchronization as accuracy climbs.
- Assumptions/Dependencies: High-coverage validators; PI/PHI safeguards; versioning to avoid feedback loops with production data.
- Math tutoring and assessment generation (Education)
- Use case: Improve step-by-step math solutions using correctness of final answers as reward; distill reviser feedback into concise, proactive explanations.
- Potential tools/products/workflows: LMS plugins that auto-generate and revise practice solutions; analytics for token-level error localization to explain “where the reasoning went wrong.”
- Assumptions/Dependencies: Ground-truth answers; alignment with curriculum; controls to prevent memorization of assessments.
- Agentic tool use with verifiable outcomes (Software/Agents)
- Use case: Train agents to plan/call tools (e.g., API requests) by rewarding HTTP status codes, contract tests, or JSON schema validations.
- Potential tools/products/workflows: Tool-use harnesses that log attempts, outcomes, and revision traces; on-policy distillation in orchestration frameworks (e.g., LangGraph).
- Assumptions/Dependencies: Deterministic/verifiable tool outcomes; robust retry policies to avoid exploiting flaky signals.
- Grammar/style enforcement with linters (Content, Documentation)
- Use case: Use linter checks (pass/fail) to refine writing style and formatting; distill revisions into the generator to produce compliant content directly.
- Potential tools/products/workflows: CI linter hooks that double as SD-Zero rewarders; content QA dashboards showing token-efficiency gains.
- Assumptions/Dependencies: Well-specified style/lint rules; alignment between linter strictness and editorial standards.
- Administrative coding and claims consistency (Healthcare operations)
- Use case: Improve ICD/cpt code assignment or claim structuring using format/consistency checks (binary); not for clinical decision-making, but for administrative correctness.
- Potential tools/products/workflows: Claim validators integrated with SD-Zero post-training; HIPAA-compliant logging of on-policy traces.
- Assumptions/Dependencies: High-precision validators; privacy-preserving data handling; restricted to non-diagnostic tasks.
- Low-cost post-training in research labs (Academia, Open-source)
- Use case: Labs without access to stronger teachers can push small/medium models on verifiable tasks (math/code) using only final-answer or test-based rewards.
- Potential tools/products/workflows: Open-source SD-Zero training recipes; token-level localization heatmaps for analysis; easy teacher-sync utilities for iterative improvement.
- Assumptions/Dependencies: Availability of verifiable benchmarks; modest compute for on-policy sampling.
- Training-efficiency upgrades to existing RL pipelines (MLOps)
- Use case: Replace or complement GRPO/RLHF in verifiable domains to cut sample/generation budgets while improving performance and shortening responses.
- Potential tools/products/workflows: SD-Zero modules in training platforms; automated budget calculators; mixed pipelines (RFT for data bootstrapping + SD-Zero for densification).
- Assumptions/Dependencies: Comparable compute budget; careful budget normalization; monitoring to prevent mode collapse.
Long-Term Applications
These require further research, scaling, or development beyond current constraints.
- Extension to “thinking” models with long chains-of-thought (AI research, Education, Software)
- Use case: Distinguish productive exploration from genuine mistakes to apply dense supervision in long-form reasoning.
- Potential tools/products/workflows: Trajectory-level credit assignment, segment-level reviser teachers, mixed local/global rewards.
- Assumptions/Dependencies: New reward shaping that goes beyond local tokens; metrics for productive exploration; stable training heuristics.
- Non-verifiable domains via meta-cognitive rewards (General-purpose AI)
- Use case: Use self-consistency, uncertainty calibration, self-critiques, or debate-based signals as pseudo-rewards to densify supervision where ground-truth isn’t available.
- Potential tools/products/workflows: Meta-reward services (consistency/agreement checkers); critique-to-dense pipelines; confidence-aware revisers.
- Assumptions/Dependencies: Reliability of proxy rewards; robust defenses against reward hacking; validation protocols.
- Robotics and embodied agents (Robotics, Autonomy)
- Use case: Use simulator pass/fail or task completion checks as binary rewards to densify planning policies; refine language planners for task sequences.
- Potential tools/products/workflows: SD-Zero integrated with simulators; reviser modules that localize plan errors and replan segments.
- Assumptions/Dependencies: High-fidelity simulators; stable sim-to-real transfer; safety constraints; substantial engineering.
- Safety-critical decision support (Healthcare, Finance, Legal)
- Use case: Couple SD-Zero with rigorous validators (e.g., medical dosage calculators, regulatory rules) and human oversight to improve reasoning under verifiable constraints.
- Potential tools/products/workflows: Human-in-the-loop review with token-level localization; tiered deployment where only admin/format constraints are automated initially.
- Assumptions/Dependencies: Expert-approved validators; governance and audit trails; regulatory approvals and risk management.
- Continual, self-evolving production systems (MLOps, Enterprise AI)
- Use case: Deploy iterative teacher synchronization in production to keep models improving from live binary signals (e.g., test outcomes, schema checks).
- Potential tools/products/workflows: “Self-Evolution” schedulers for periodic teacher refresh; drift detection + rollback; alignment monitoring for unintended behaviors.
- Assumptions/Dependencies: Strict data governance (no leakage from evaluation to training); safe-on-policy logging; robust monitoring/observability.
- Multi-agent and cross-model self-revision (AI systems, Collaboration tooling)
- Use case: Have one model act as generator and another as reviser across domains; compose dense feedback from multiple specialized validators.
- Potential tools/products/workflows: Cross-model distillation orchestrators; validator/critic ensembles feeding token-level guidance.
- Assumptions/Dependencies: Stable inter-model interfaces; arbitration among conflicting feedback; increased compute/latency management.
- Regulatory and sustainability frameworks (Policy, Energy)
- Use case: Encourage verifiable-reward post-training (like SD-Zero) to reduce compute and improve auditability; create standards for reward logging and training transparency.
- Potential tools/products/workflows: Compliance reporting for reward sources; energy and carbon accounting tied to sample-efficient methods; certification of validators.
- Assumptions/Dependencies: Policy adoption; accepted benchmarks for “verifiable training”; standardized logging formats.
- Security and secure coding assistance (Cybersecurity)
- Use case: Use binary vulnerability checks (e.g., static analyzers, exploit tests) as rewards to improve secure code generation and remediation suggestions.
- Potential tools/products/workflows: SD-Zero plus SAST/DAST integrations; token-level localization to explain insecure patterns.
- Assumptions/Dependencies: High-precision security checkers; safe datasets; mitigation of adversarial reward exploitation.
In summary, SD-Zero is immediately valuable wherever binary, verifiable rewards are available (tests, schemas, validators). Its longer-term promise lies in generalizing dense self-supervision to non-verifiable domains, long-form reasoning, and continuously evolving systems—contingent on new reward designs, stronger safeguards, and robust MLOps practices.
Glossary
- Ablation studies: Systematic experiments that remove or vary components to assess their individual contribution to performance. "Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization."
- avg@8: An evaluation metric that averages accuracy (or similar performance) over up to 8 generated attempts per problem. "Performance comparison of SD-Zero and SFT Phase (Self-Revision Training, Phase~1) against baseline post-training methods on math and code reasoning benchmarks, reported as avg@8."
- compute equalized: A comparison setting where all methods are run under matched compute budgets to ensure fairness. "All methods are compute equalized (see Appendix \ref{app:compare-budget} for more details)."
- DAPO: An improved variant of Group Relative Policy Optimization (GRPO) used for reinforcement learning with LLMs. "We use DAPO (\citet{yu2025dapo}), an improved and commonly used variant of GRPO."
- Generate-then-Revise evaluation: A two-step assessment where the model first generates an answer and then revises it conditioned on reward to measure self-revision capability. "To measure directly, we run a Generate-then-Revise evaluation on 1K AIME24 questions using Qwen3-4B-Instruct:"
- Generator: The role of the model that produces an initial response to a prompt before any revision. "SD-Zero{} trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response."
- GRPO: Group Relative Policy Optimization, a reinforcement learning algorithm that optimizes policies using groups of sampled trajectories. "On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero{} improves performance by at least over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget."
- in-distribution: Data that is drawn from the same distribution as the training set, used here for fair evaluation splits. "For the two in-distribution datasets we hold out 500 test questions each."
- iterative self-evolution: A training loop where the improved student periodically becomes the new teacher, enabling continued self-improvement. "SD-Zero enables iterative self-evolution through regular teacher synchronization."
- KL divergence: A measure of divergence between two probability distributions, used as a token-level loss to align student and teacher distributions. "The model is trained to match this distribution via KL divergence loss."
- meta-cognitive signals: Signals about the reasoning process itself (e.g., self-consistency or self-correction) that can serve as rewards when correctness is not directly verifiable. "One promising direction is to define rewards using meta-cognitive signals \citep{didolkar2024metacognitive,didolkar2025metacognitive,shao2025dr}, such as consistency or self-correction."
- next-token distribution: The probability distribution over the next token produced by a LLM at each step. "The Phase 1 reviser, conditioned on the model's response and whether it was correct, produces a next-token distribution at each token position."
- on-policy distillation: Distillation where the teacher provides supervision on the student’s own generated trajectories rather than on fixed off-policy data. "On-policy distillation methods \citep{agarwal2024onpolicy,gu2024minillm,boizard2024uld,minixhofer2025cross,lu2025onpolicydistillation} assume access to an external stronger teacher that can provide token-level feedback on the student's responses."
- on-policy self-distillation: A distillation setup where the model distills its own teacher (a prior snapshot/role) using data generated by the current student policy. "We then perform on-policy self-distillation to distill the reviser into the generator, using the reviserâs token distributions conditioned on the generatorâs response and its reward as supervision."
- outcome-conditioned self-revision: Revising a response conditioned on whether the initial attempt was correct or incorrect, guiding either rephrasing or correction. "Comparison of outcome-conditioned self-revision capability on AIME24, Qwen3-4B-Instruct."
- pass@8: The probability of achieving a correct solution when allowed up to 8 independent attempts, commonly used in code evaluation. "We also report pass@8 results in \Cref{tab:pass8_results}."
- Rejection Fine-Tuning (RFT): Fine-tuning on self-generated solutions filtered to include only correct ones. "On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero{} improves performance by at least over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget."
- Reinforcement learning (RLVR): Reinforcement learning in verifiable settings where rewards are derived from outcome correctness (e.g., binary rewards). "Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training."
- Reviser: The role of the model that, given an initial response and its reward, produces an improved (or rephrased) response. "SD-Zero{} trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response."
- Self-Distillation Fine-Tuning (SDFT): A self-distillation approach that relies on high-quality demonstrations (often from an external source) to supervise the model. "On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero{} improves performance by at least over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget."
- self-distillation: Training a model to match its own teacher’s (often a previous snapshot or alternate role’s) token distributions, providing dense supervision without external teachers. "Self-Distillation phase distills the reviserâs behavior back into the generator, so that the model can internalize revision and produce more compact and well-directed responses."
- self-localization: The model’s ability to localize feedback to specific tokens that contributed to an error, despite receiving only a binary outcome. "token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward"
- self-revision: The process by which the model critiques or rephrases its own initial attempt based on outcome feedback. "we collect 6K outcome-conditioned self-revision traces by sampling an initial response from the base model, prompting the model to self-revise its incorrect response, and keeping the correct self-revision."
- Self-Revision Training (SRT): The phase that strengthens the model’s reviser ability by training on successful self-revision traces. "SRT Outperforms Training on Expert Solutions or Filtered Self-Generations"
- student policy: The parameterized distribution over responses produced by the student model during training. "Let denote the student policy with parameters , which generates a reasoning response for input according to ."
- teacher synchronization: Periodically updating the teacher with the current student to continue improving via self-distillation. "Iterative Self-Evolution: Teacher Synchronization Enables Continued Gains"
- token-efficient: Achieving equal or better performance while generating fewer tokens, improving inference efficiency. "Self-Distillation Enables Stronger, Token-Efficient Generations."
- token-level supervision: Supervision provided at the granularity of next-token distributions rather than only outcome-level signals. "Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations."
- Token KL Reward: A token-wise signal derived from the KL/log-probability gap between student and teacher that highlights where to correct. "We define Token KL Reward at token as: $\log \pi_\theta(y_t \mid x, y_{<t}) - \log \pi_{\theta_{SFT Phase}(y_t \mid x, y, P_r, y_{<t})$."
- verifiable settings: Task domains where correctness can be automatically checked to provide rewards (e.g., math and coding). "Reinforcement learning (RL) has become the dominant approach for post-training LLMs on reasoning tasks in verifiable settings such as math and coding"
Collections
Sign up for free to add this paper to one or more collections.