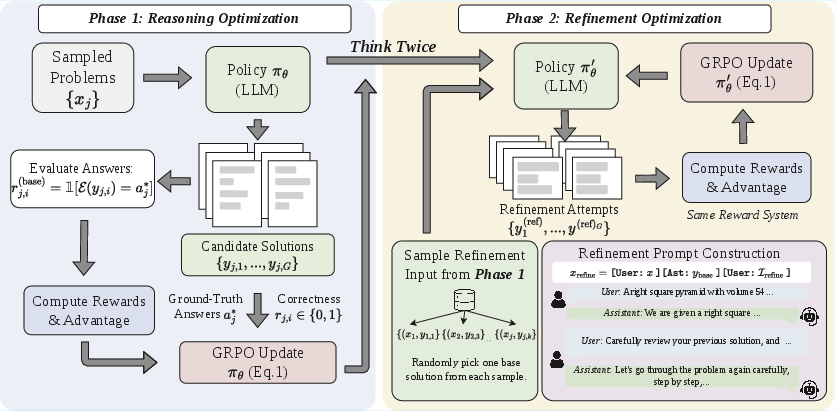
- The paper introduces a two-phase RLVR method that jointly trains a single policy for initial reasoning and subsequent self-refinement.
- It demonstrates significant gains, notably +5.1 points in direct reasoning and +11.5 points in refinement on benchmarks like AIME using Qwen3-4B.
- The approach improves efficiency with only a 3% training overhead and 16% faster convergence compared to prior methods.
ThinkTwice: Joint Optimization of Reasoning and Self-Refinement in LLMs
Introduction
"ThinkTwice: Jointly Optimizing LLMs for Reasoning and Self-Refinement" (2604.01591) introduces a two-phase RLVR methodology for LLMs, targeting mathematical reasoning and self-refinement. The framework addresses a persistent gap: while RLVR methods (e.g., GRPO, DAPO) can yield LLMs capable of complex reasoning, their outputs often contain correctable errors that single-pass optimization fails to address. Prior work on self-refinement either relies on inference-time prompting—yielding brittle, non-generalizable policies—or employs training frameworks requiring expensive and impractical intermediate supervision (e.g., critique labels, correctness signals). ThinkTwice proposes a unified, efficient solution: a single RLVR policy alternately trained for both initial problem-solving and revisiting its own answers via generic self-review, using only the final binary correctness signal, thus eliminating the need for external verifiers or additional process supervision.

Figure 1: (A) Prompt-only reflection can reduce top frontier LLM's performance on AIME24, indicating brittleness. (B) ThinkTwice compared with existing method families. (C) ThinkTwice addresses these gaps by sequentially training a shared model backbone—first solving, then reflecting—yielding significant gains (+5 points reasoning, +11 points refinement) on AIME with Qwen3-4B.
ThinkTwice is designed in contrast to both paradigm classes:
- Training-free self-refinement methods (e.g., Reflexion, Self-Refine, self-verification prompting) that operate at test time, which do not yield a reusable refinement policy and demonstrate qualitative instability on challenging mathematical datasets.
- Training-based self-refinement approaches, which require critique labels, correctness hints, or process labels for low-variance reward signals (e.g., Critique-GRPO, S2R, Self-Verify), thus relying on supervision that is often unavailable in open generative settings or for frontier LLMs.
Previous single-pass RLVR methods (e.g., GRPO, DAPO, DrGRPO) lack a way to explicit integrate multi-round reasoning and are inherently incapable of learning to robustly fix their own mistakes. ThinkTwice closes this gap by learning the refinement operator jointly during RLVR, relying on a generic review instruction and only task-verifiable final answers for training signal. Appendix Table~\ref{tab:related_work_comparison} in (2604.01591) offers a compact comparison.
Methodology
The backbone of ThinkTwice is Group Relative Policy Optimization (GRPO), a critic-free, PPO-style RL variant tailored for LLMs in the RLVR regime, where rewards are verifiable Boolean correctness signals. Each step alternates between:
Crucially, this approach does not expose the model to any signal indicating whether the base solution is correct or incorrect nor require auxiliary data (critiques, verifier outputs, or teacher demonstrations). The curriculum is emergent: in early training, refinement phase encounters more incorrect base solutions—focusing updates on error correction; later, as the model improves, refinement naturally shifts focus toward preserving and succinctly restating correct completions.
Experimental Setup
Training (on MATH), evaluation (on AIME, AMC, MATH500, MinervaMath, OlympiadBench), and reward extraction protocols conform to established RLVR benchmarks (all supervision via exact final-answer verification using Math-Verify). Core comparisons are run on Qwen3-4B and OLMo3-7B, with strong RLVR baselines (GRPO, DAPO, DrGRPO) and prominent training-free self-refinement methods included for context.
Results
Reasoning and Self-Refinement Metrics
On Qwen3-4B, ThinkTwice yields the highest average direct reasoning score (pass@4) across all benchmarks (Table 1 in (2604.01591)), outperforming GRPO by 5.1 points on AIME (44.1% vs 39.1%). For self-refinement, the ThinkTwice-trained model, when refining its own base generations, achieves an 11.5pp gain over GRPO on AIME (60.4% vs 48.9%), and 2.9pp over DAPO averaged across all datasets. These results are mirrored on OLMo3-7B.
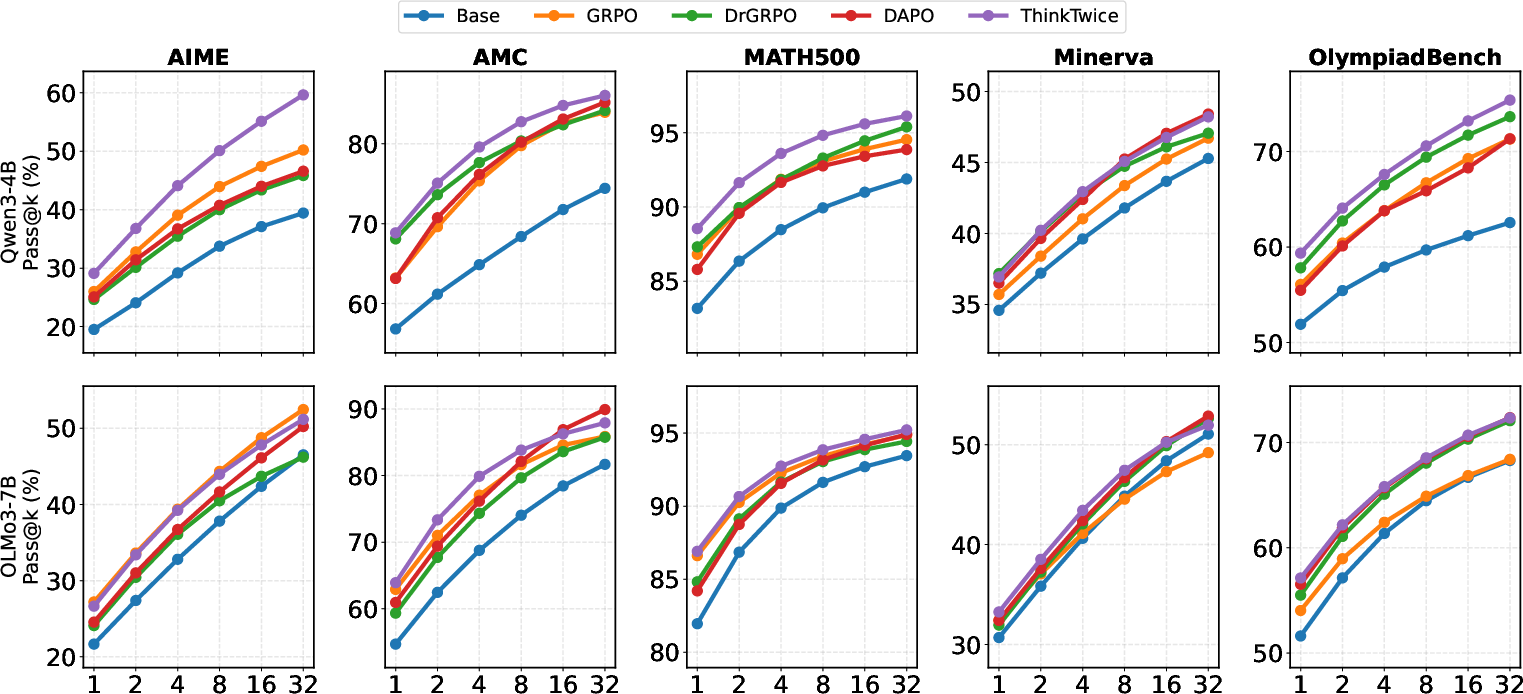
Figure 3: Reasoning pass@k curves across five mathematical reasoning benchmarks for Qwen3-4B (top) and OLMo3-7B (bottom).
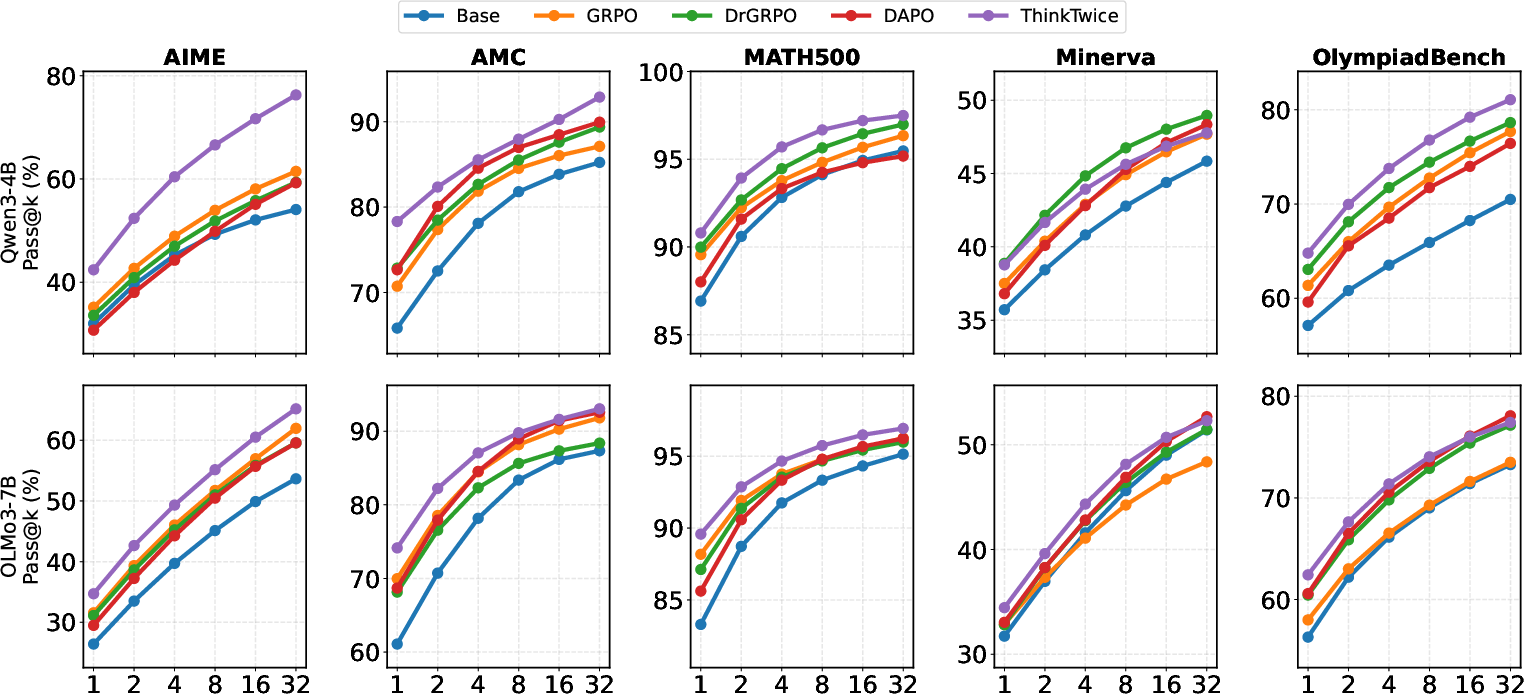
Figure 4: Self-refinement pass@k curves across five mathematical reasoning benchmarks for Qwen3-4B (top) and OLMo3-7B (bottom).
ThinkTwice not only improves the pass@k for single-turn direct reasoning but also sets new state-of-the-art results for single-step self-refinement, greatly outperforming training-free refinement pipelines (Self-Refine, Reflexion).
Cross-Model Refinement
An essential empirical finding is that the ThinkTwice-trained policy, when used only for the refinement phase and applied to base generations from other models, consistently provides the largest accuracy boost, demonstrating that its refinement operator is robust and reusable beyond distribution (Figure 5):
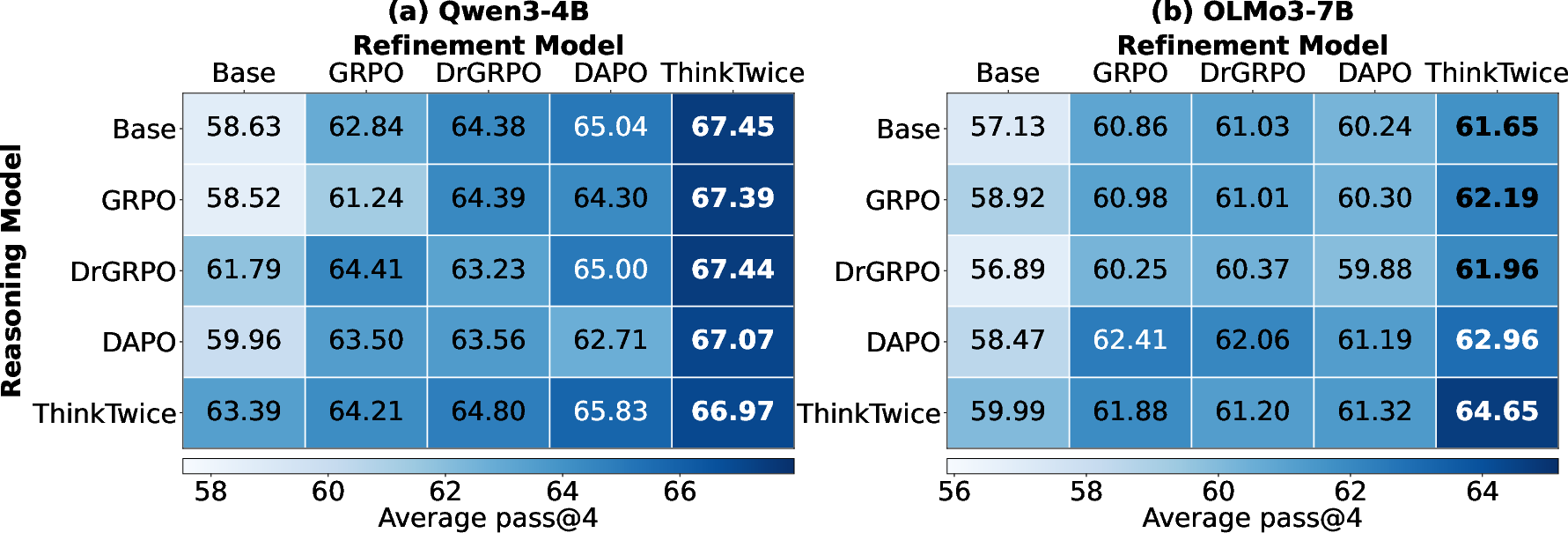
Figure 5: Cross-model refinement evaluation (average pass@4, ↑). Rows denote the backbone reasoning model; columns denote the refinement model.
Training Dynamics
ThinkTwice's two-stage optimization generates a rectify-then-fortify curriculum without explicit curriculum engineering. Early in training, the refinement step's probability of converting an incorrect base answer to a correct one ("fix-wrong rate") dominates, while the likelihood of damaging an already correct answer ("damage-correct rate") decreases monotonically over checkpoints, falling below 1% at convergence (Figure 6). Analytical metrics on solution formatting (boxed answer, length, clarity) reveal that later-stage refinements transition from error-fixing to conciseness and normalization, consistently enhancing answer formatting despite absence of formatting supervision.
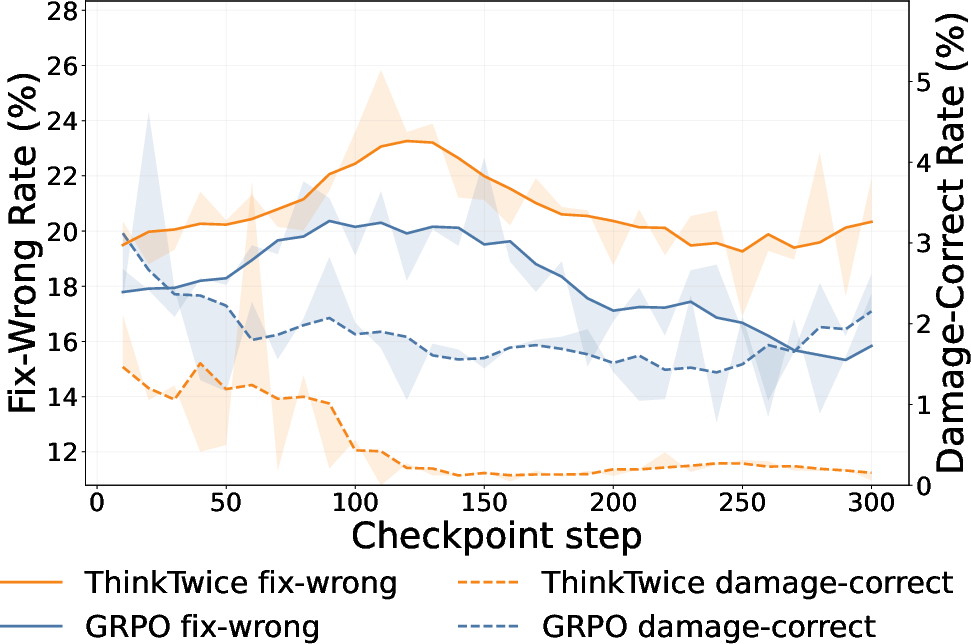
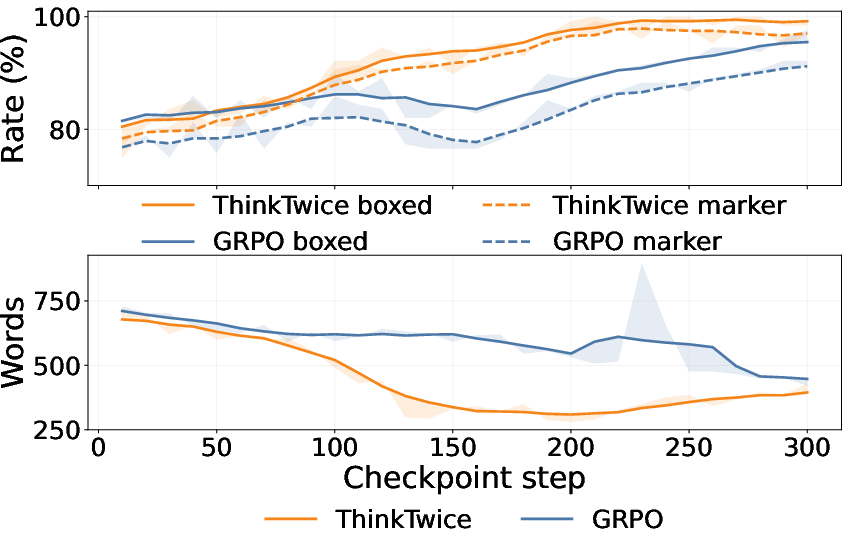
Figure 6: Training dynamics of refinement across checkpoints. The vertical dashed lines mark the best checkpoints. Left (a): transition metrics on the training set. Right (b): formatting and length metrics for self-refinement on correct-only base solutions.
Qualitative analysis (Appendix Sec. A.4) underscores several recurring behaviors: (i) route switching—refinement abandons unproductive strategies identified in base output, (ii) solution completion—unfinished or flawed base traces are repaired and properly closed, and (iii) proof exploitation—refinement compresses lengthy correct traces into direct, cleaned-up arguments.
Training Cost and Efficiency
Despite the two-step protocol, ThinkTwice adds only 3% overhead per training iteration. Due to enhanced learning signals, the policy converges in fewer total steps—best checkpoint is reached with 16% less wall-clock time compared to GRPO at similar compute scale (Figure 7).
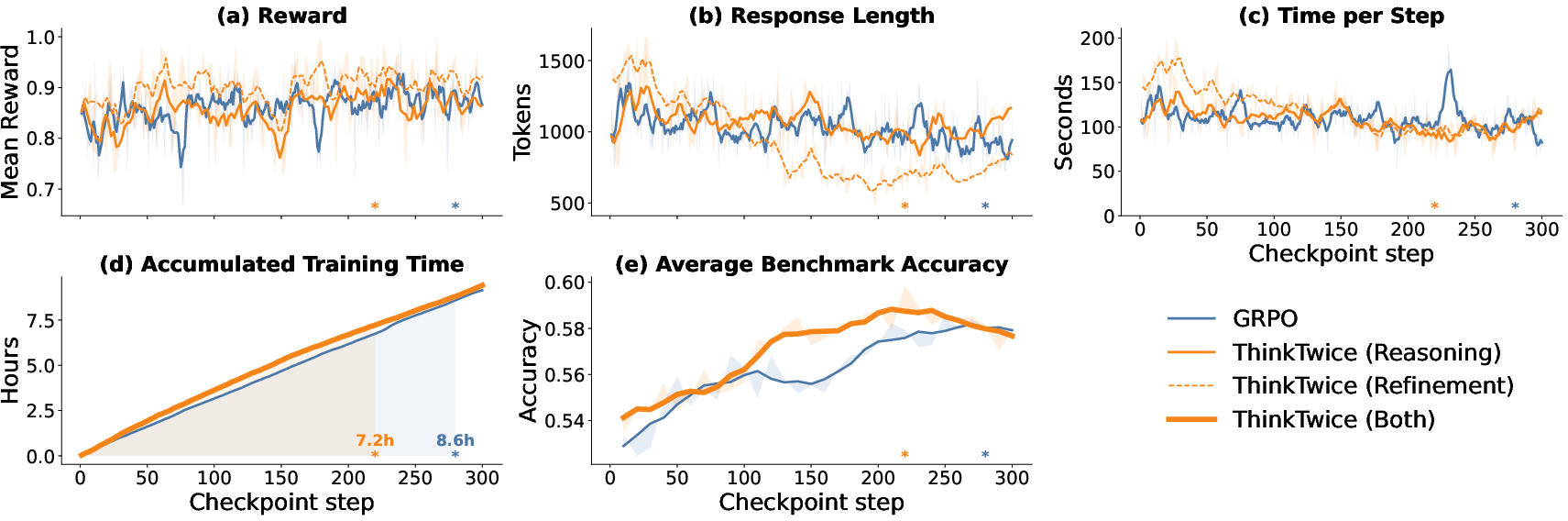
Figure 7: Training-time cost and dynamics of ThinkTwice compared with GRPO. (a) Mean reward. (b) Response length. (c) Wall-clock time per update. (d) Accumulated training time. (e) Macro average benchmark accuracy.
Implications and Future Work
Theoretical and Practical Impact
ThinkTwice closes the prior gap in RLVR: it demonstrates that high-fidelity reasoning and robust self-refinement can be learned by a single policy trained in two alternating RL phases, using only outcome-based correctness signals. The emergent rectify-then-fortify curriculum provides stable and rich gradients at all model competence levels, overcoming the reward sparsity or instability that plagues single-pass RLVR or training-only refinement in absence of critique supervision.
From a practical perspective, ThinkTwice learns a genuinely reusable refinement policy rather than brittle test-time heuristics, offering a scalable path for improved mathematical solvers, coding assistants, or scientific LLMs—any domain admitting verifiable final results.
Extensions
While experiments focus on mathematical problem-solving, the methodology is domain-agnostic subject to the availability of verifiable rewards. ThinkTwice's chat-format architecture natively accommodates multi-step iterative refinement; future work could investigate deeper multi-round refinement or generalize to settings such as code RL, scientific derivations, or complex planning.
Conclusion
ThinkTwice establishes that joint RL-based training for reasoning and self-refinement, using only the task's outcome reward, yields large gains in both initial solution quality and error recovery. The simplicity, robustness, and efficiency of this approach provide a strong blueprint for future work in scalable LLM self-correction and verifiable reasoning.