- The paper demonstrates that lower SFT learning rates serve as an implicit regularizer, minimizing catastrophic forgetting by reducing representational drift.
- It shows that higher learning rates amplify loss landscape sharpness, leading to faster feature drift as measured by the Mean Principal Angle metric.
- The study reveals that aggressive pretraining LR decay sharpens models, increasing vulnerability to overtraining and out-of-distribution performance drops.
The Role of Learning Rates in Regulating Catastrophic Overtraining in LLMs
Introduction
The paper "(How) Learning Rates Regulate Catastrophic Overtraining" (2604.13627) provides a comprehensive analysis of catastrophic forgetting and overtraining in LLM supervised finetuning (SFT), explicitly linking these phenomena to the interplay between learning rate (LR) schedules, loss landscape sharpness, and the implicit regularization properties of SGD-driven optimization. The authors focus on characterizing how LR choices during SFT and their interaction with pretraining-induced sharpness jointly mediate the preservation or destruction of general capabilities in LLMs, with significant implications for post-training strategies.
Catastrophic Forgetting and the Regularizing Effect of Learning Rate
The study begins by empirically demonstrating that lower SFT learning rates consistently mitigate catastrophic forgetting, as quantified by the out-of-distribution (OOD) performance drop post-finetuning. This is observed across multiple 1-3B parameter models (OLMo 1/2, Hubble, Gemma 3) finetuned on Anthropic-HH or Tülu 3, using a constant LR schedule to isolate the LR effect. All models experience some OOD degradation, but those trained with lower LRs exhibit a smaller gap for equivalent SFT loss values. This effect arises even when the magnitude of cumulative parameter updates is controlled.

Figure 1: SFT training loss vs OOD performance for different models and learning rates; higher LRs induce stronger forgetting at comparable SFT convergence.
To quantify how closely finetuned model representations remain aligned with their pretrained state under varying LRs, the authors introduce the Mean Principal Angle (MPA) metric between representations. They show that for fixed SFT loss values, higher LRs yield larger MPAs, indicating greater feature drift away from the pretrained features.
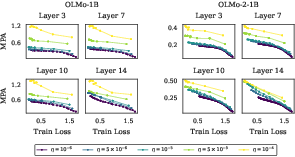
Figure 2: SFT training loss vs MPA between base and finetuned model representations; higher LRs induce greater representational rotation.
This analysis, reinforced by further results using sparse autoencoder (SAE)-induced metrics and extended to multiple architectures and datasets, robustly supports the claim that low SFT learning rates act as an implicit regularizer preserving general features, consistent with a lazy-learning regime.
Mechanistic Analysis: The Sharpness-Feature Drift Interface
To explain the observed differences in feature drift as a function of SFT LR, the authors analyze local loss surface properties during finetuning. Through interpolation and stepwise analyses, they demonstrate that the increase in MPA per unit of training loss is strongly amplified by higher LRs. This is a generic property of overparameterized networks near initialization: as confirmed via diagonal linear models, when initialized from a (possibly good) pretrained solution, high LRs favor rapid feature drift and partial forgetting, in contrast to small LRs which maintain proximity to the initialization, thereby inhabiting the lazy regime.
Additionally, the study links this behavior to sharpness of the loss landscape. Sharp models—those with high maximum eigenvalues of the Hessian—exhibit a strong sensitivity to SFT LR: for a fixed LR, finetuning from a sharper checkpoint induces more catastrophic forgetting, evidenced by larger representational rotation and performance drop for similar progress in SFT loss. The interactions observed in toy and full-scale models are explained through modern edge-of-stability theory: the stable operation of SGD depends on the LR-to-sharpness ratio, with sharper regions exacerbating the negative consequences of aggressive (higher) LRs.
Catastrophic Overtraining as a Function of Pretraining LR Decay
The analysis then turns to the origin of sharpness in pretraining. Through sharpness estimation (using the response of logits to Gaussian-perturbed parameters) along the entire pretraining curriculum, it is shown that sharpness increases markedly as the pretraining LR is decayed—especially in widely adopted schedules with warmup, constant, and cooldown/decay phases. Models adopting warmup-stable-decay (WSD) schedules display a rapid jump in sharpness coinciding with the cooldown, directly implicating LR decay as the primary factor.

Figure 3: Evolution of model sharpness throughout pretraining; sharpness grows as LR is decayed, with pronounced surges during LR cooldown.
The direct consequence is that base models obtained from later (sharper) pretraining checkpoints experience substantially greater forgetting during subsequent SFT. This is reflected in a monotonic increase in accuracy drop on OOD tasks as a function of pretraining progress, with sharp rises aligned to LR decay intervals.
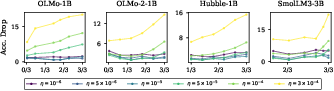
Figure 4: Dynamic of accuracy drop (OOD score difference pre- vs post-SFT) throughout pretraining; later, sharper checkpoints suffer greater forgetting.
Representational analyses via principal angles confirm that feature drift grows dramatically following the increase in sharpness, especially as the model enters the post-decay regime.
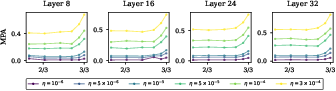
Figure 5: Principal angles between base and finetuned representations increase sharply in conjunction with LR decay during pretraining.
This establishes that catastrophic overtraining is primarily a byproduct of pretraining-induced sharpness rather than simply a function of cumulative data exposure. The work also provides evidence that the interaction is not merely correlational, as the temporal alignment of sharpness increase and forgetting is robust across diverse architectures, datasets, and initialization choices.
Theoretical and Practical Implications
The findings substantiate that both SFT and pretraining LR schedules act as highly nontrivial regularizers in the context of LLM post-training. Lower SFT LRs mitigate feature drift and help preserve emergent pretraining capabilities, while excessive pretraining LR decay moves the base model into sharp, plastic regions of parameter space, rendering it increasingly vulnerable to catastrophic overtraining and loss of generalization upon domain shift.
These insights question the default wisdom of prolonged pretraining with aggressive LR annealing, advocating instead for:
- Minimalistic SFT learning rates: Targeting the smallest LR that achieves in-distribution SFT performance can limit capability attrition.
- Cautious LR schedules during pretraining: Maintaining stable pretraining LRs or shifting LR annealing to the post-training stage may avoid unnecessarily sharpening the model before SFT.
- Joint tuning of SFT and pretraining schedules: Proper coordination is necessary to avoid creating models that are both sharp and finetuned with LRs that cross the edge of stability, leading to undesirable plasticity and forgetting.
The results align with and complement observations from concurrent work on sharpness-aware optimization and regularization [watts2026sharpness, yano2026pre]. They further suggest that model size is not the primary driver of these effects, as all phenomena were robustly seen in 1-3B models, and encourage future work on causally disentangling schedule components and investigating transfer to larger architectures.
Conclusion
This paper provides a rigorous optimization-centric account of catastrophic overtraining in LLMs, demonstrating that sharpness induced via pretraining LR decay lies at the core of increased forgetting upon SFT, and that SFT LR selection is a critical lever for capability preservation. These findings are directly actionable in LLM training pipelines and point to the necessity of principled LR schedule design at both pretraining and finetuning stages to balance instruction-following improvements with retention of general abilities.

