- The paper's primary contribution is the introduction of VLAJS, a framework that uses sparse, transient vision-language-action guidance to bootstrap reinforcement learning for robotic manipulation.
- It integrates PPO with a directional alignment loss and reward-based annealing to address long-horizon tasks and sparse rewards efficiently.
- Empirical evaluations on simulation and a real Franka Panda robot demonstrate significantly improved sample efficiency and robustness under challenging conditions.
Vision-Language-Action Jump-Start Regularization for RL in Robotic Manipulation
Motivation and Context
Robotic manipulation tasks employing on-policy RL suffer from sample inefficiency, particularly in settings characterized by long horizon tasks or suboptimal, sparse reward signals. Existing approaches either rely on rich reward shaping, intensive exploration, or dense expert guidance, all of which are computationally or practically restrictive. Recent advances in Vision-Language-Action (VLA) models offer semantic priors and high-level reasoning across manipulation tasks, but their native use in closed-loop, high-frequency control is hampered by low inference rates and dependence on direct demonstrations. The "Jump-Start Reinforcement Learning with Vision-Language-Action Regularization" (2604.13733) proposes Vision-Language-Action Jump-Starting (VLAJS), a unified framework that leverages VLA models as sparse, transient sources of auxiliary guidance to bootstrap RL agents without constraining their long-run optimality.
Methodological Framework
The VLAJS methodology targets two distinct but overlapping RL bottlenecks: poor credit assignment in long-horizon tasks, and inefficiency under sparse or imperfect reward. The approach augments PPO with a reward-based, adaptive schedule for VLA teacher queries, employing a directional action-consistency loss for transient guidance.
VLA teacher actions are queried at sparse intervals during early RL training and linearly discretized across a limited set of control steps. This generates auxiliary targets that are incorporated into PPO updates through a cosine alignment loss penalizing directional mismatch but ignoring magnitude, circumventing the rigidity and brittleness of MSE-based distillation. Guidance is progressively annealed using a reward-trend signal, with permanent deactivation once reliable policy improvement is detected.
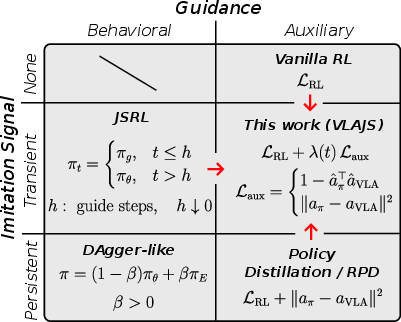
Figure 1: Comparison of guidance strategies in RL, contrasting persistent behavioral imitation (DAgger), persistent auxiliary distillation, transient guidance (JSRL), and VLAJS directional auxiliary regularization.

Figure 2: ManiSkill simulation benchmarks employed for evaluation and real-world deployment setup on a Franka Panda robot across language-specified tasks.
Empirical Evaluation
VLAJS is validated on six ManiSkill manipulation tasks encompassing pick-and-place, peg operations, poking, and pushing, with experiments on both simulation and zero-shot deployment to a real Franka Panda robot. Performance metrics include success rate at task-specific step budgets (SRt∗) and area under the success curve (AUC). The experimental protocol distinguishes between long-horizon scaling (where teacher query frequency is computationally prohibitive) and reward sparsity (where suboptimal reward shaping is deliberately introduced).
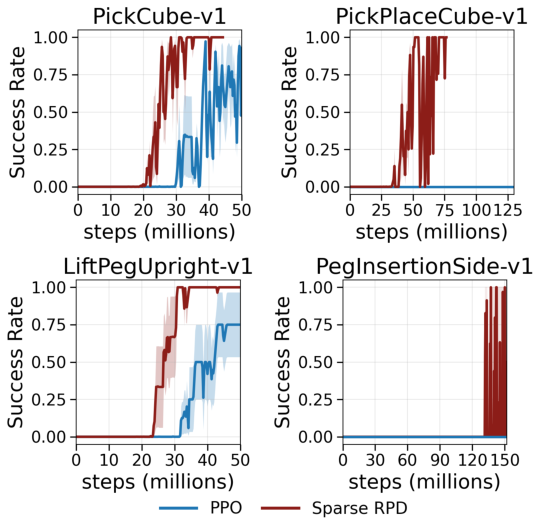
Figure 3: Learning curves for long-horizon tasks. Sparse RPD accelerates convergence compared to PPO, validating sparse auxiliary guidance as computationally tractable.
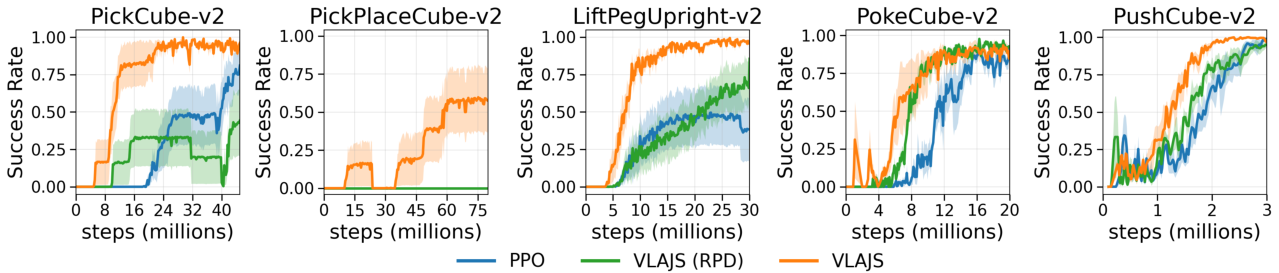
Figure 4: Learning curves for suboptimal reward tasks. VLAJS achieves higher sample efficiency and sustained policy improvement after guidance is deactivated.
Numerical results demonstrate that sparse RPD outperforms PPO in extended-horizon scenarios, achieving macro-averaged SRt∗ of 40.3% and AUC 37.6%, compared to negligible success for PPO. Under suboptimal rewards, VLAJS dominates, with macro-average SRt∗=78.1% and AUC 78.4%, and exhibits continual policy improvement post-guidance deactivation. Notably, VLAJS achieves >50% reduction in required environment interactions for several ManiSkill tasks.
Real-world deployment results highlight VLAJS's robustness to clutter, visual perturbations, and object variation, maintaining task completion rates under conditions where VLA-only policies fail.
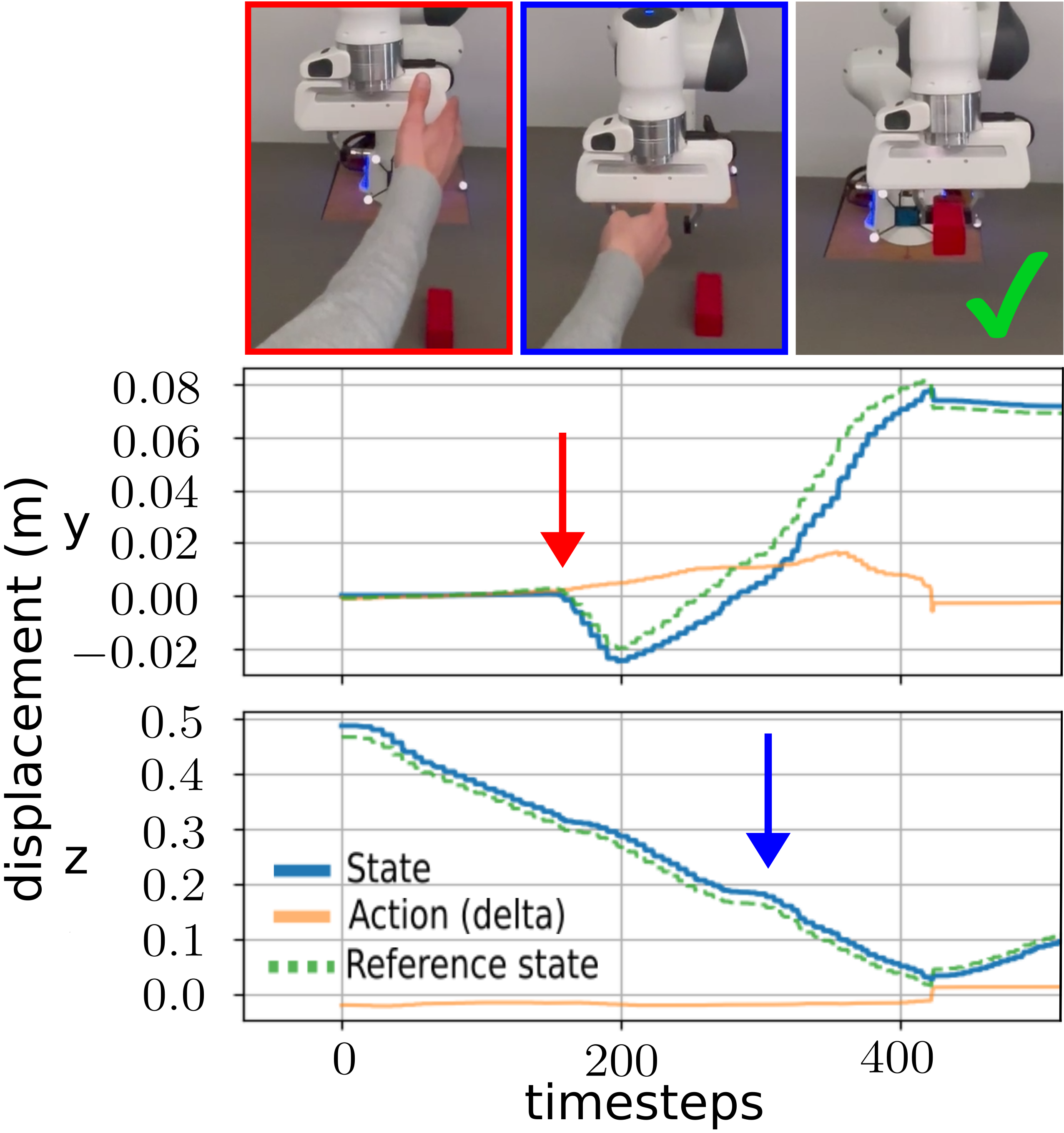
Figure 5: Policy robustness comparison under external perturbations. VLAJS sustains performance in the presence of clutter, unlike VLA-only policies.
Design Considerations and Ablations
The directional consistency loss is shown to be crucial: VLAJS (RPD), which uses MSE matching, fails to match the sample efficiency and final performance of the weak directional alignment loss. Transient guidance and reward-based annealing allow the RL policy to exceed teacher performance and adapt to task stochasticity.
Extensive ablations show VLAJS's insensitivity to teacher quality and task-specific camera placement, demonstrating compatibility with weak or OOD VLA teachers.
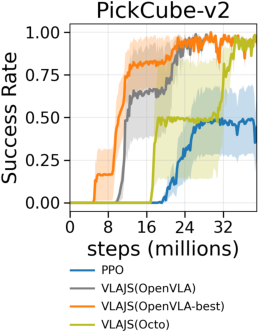
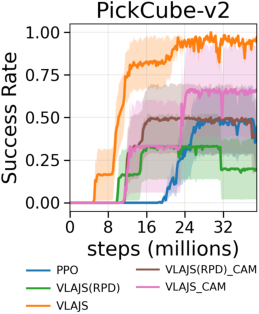
Figure 6: Success rates across tasks with varying VLA teacher performance (OpenVLA, Octo) and fine-tuning levels.
Implications and Future Directions
Practically, VLAJS offers a scalable route for leveraging large VLA foundation models to improve RL sample efficiency where dense reward engineering and demonstration collection are infeasible. Its transient auxiliary guidance mechanism reduces dependence on demonstration datasets and teacher inference, supporting direct sim-to-real policy deployment. Theoretically, the framework reframes the RL-expert synergy: teacher supervision becomes a sparse directional prior rather than persistent action constraint, permitting unconstrained policy improvement.
Future directions include the reduction of teacher overhead through adaptive or uncertainty-based query schedules, integration with vision-based RL architectures for broader manipulation and navigation contexts, and direct real-world fine-tuning with VLA models.
Conclusion
VLAJS addresses critical inefficiencies in RL for robotic manipulation by integrating vision-language-action models as transient, sparsely applied sources of auxiliary guidance. Through reward-aware annealing and directional action regularization, the approach achieves substantial gains in sample efficiency and policy robustness across simulation and real-world benchmarks. The results support the practical viability of RL-jump-starting with foundation-model priors, unlocking opportunities for scalable, semantically rich control in complex, real-world environments.