- The paper finds that reasoning failures in LLMs primarily arise from a few early transition points that trigger error propagation.
- It introduces the GUARD framework, which employs entropy-based detection and targeted local branching to dynamically rectify reasoning errors.
- Empirical evaluations demonstrate GUARD's superiority over traditional methods, achieving higher Pass@1 accuracy with reduced token consumption across benchmarks.
Dissecting Failure Dynamics in LLM Reasoning
Characterization of Reasoning Failures
This paper systematically analyses the dynamics by which LLMs exhibit reasoning failures. Through granular examination of model-generated trajectories across mathematical, scientific, and coding benchmarks, key regularities emerge. The majority of failures originate from a small number of early transition points. These errors are temporally concentrated, occurring within the first 30% of the reasoning process in over 85% of cases. The subsequent reasoning remains locally coherent but propagates a globally incorrect premise, resulting in extended, syntactically plausible but ultimately invalid chains.
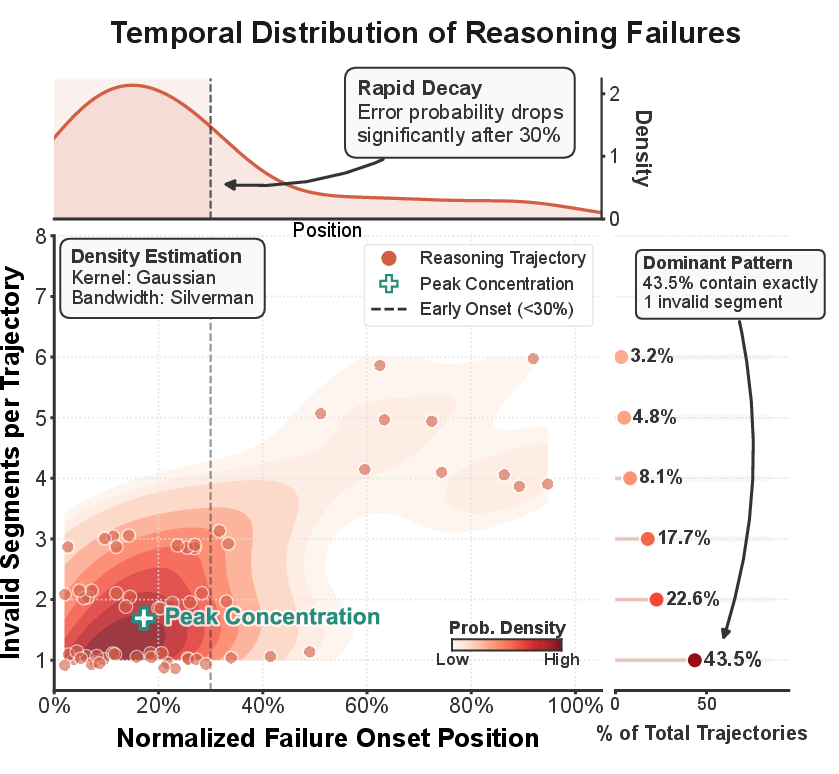
Figure 1: Early Concentration of Reasoning Failures. Most incorrect trajectories contain a single invalid segment, emphasizing error concentration.
Incorrect trajectories typically demonstrate substantial length expansion after the initial failure, forming an "epistemic spiral" where elaboration reinforces the erroneous premise without rectification. The length distribution of incorrect chains exhibits a pronounced long tail, confirming that post-onset expansion dominates the output for failed cases.
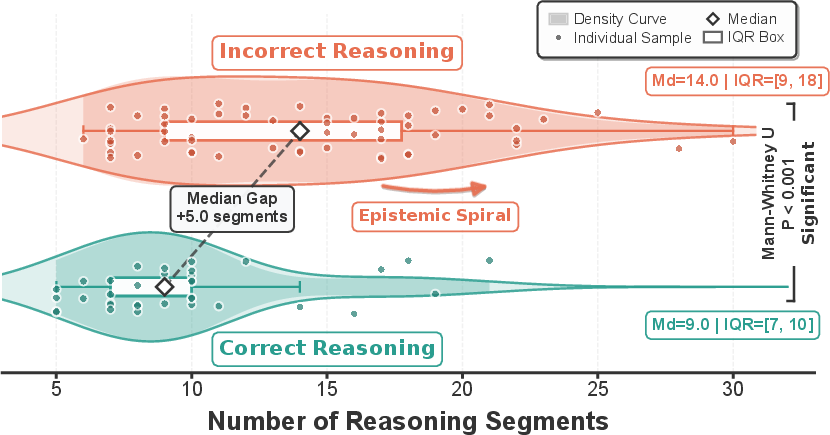
Figure 2: Segment Count Distribution for Correct and Incorrect Trajectories. Incorrect chains expand significantly after early failures.
Critical transition points are tightly coupled with localized spikes in token-wise entropy, signifying elevated model uncertainty. Invalid segments consistently display higher mean entropy and greater dispersion compared to valid ones, enabling precise identification of error onsets using adaptive uncertainty thresholds.
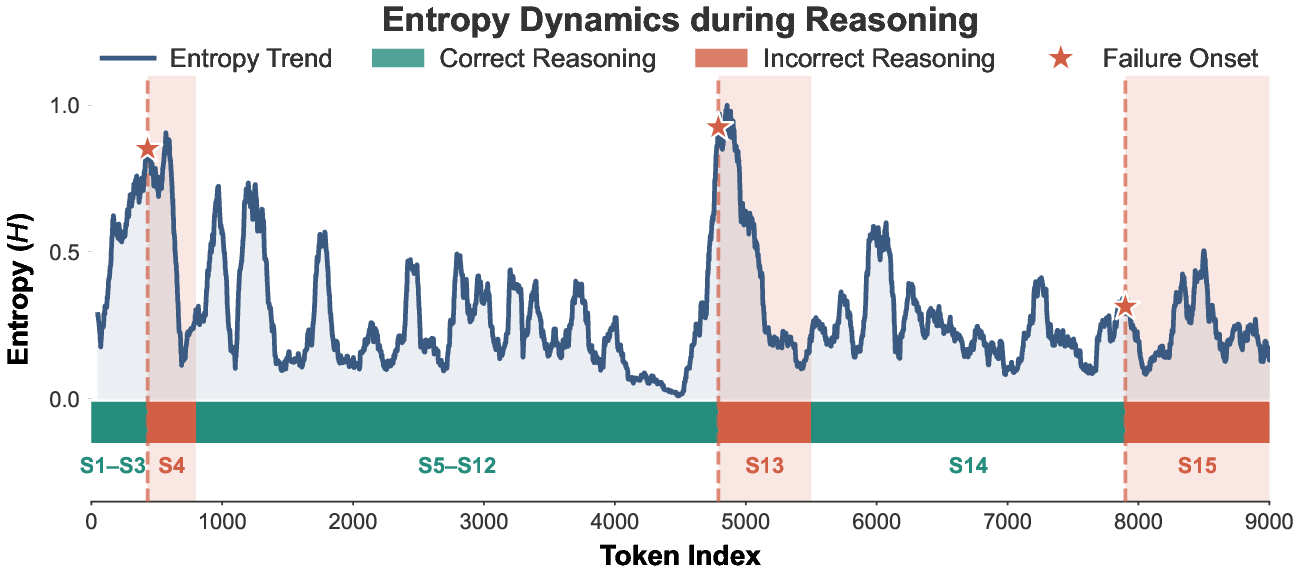
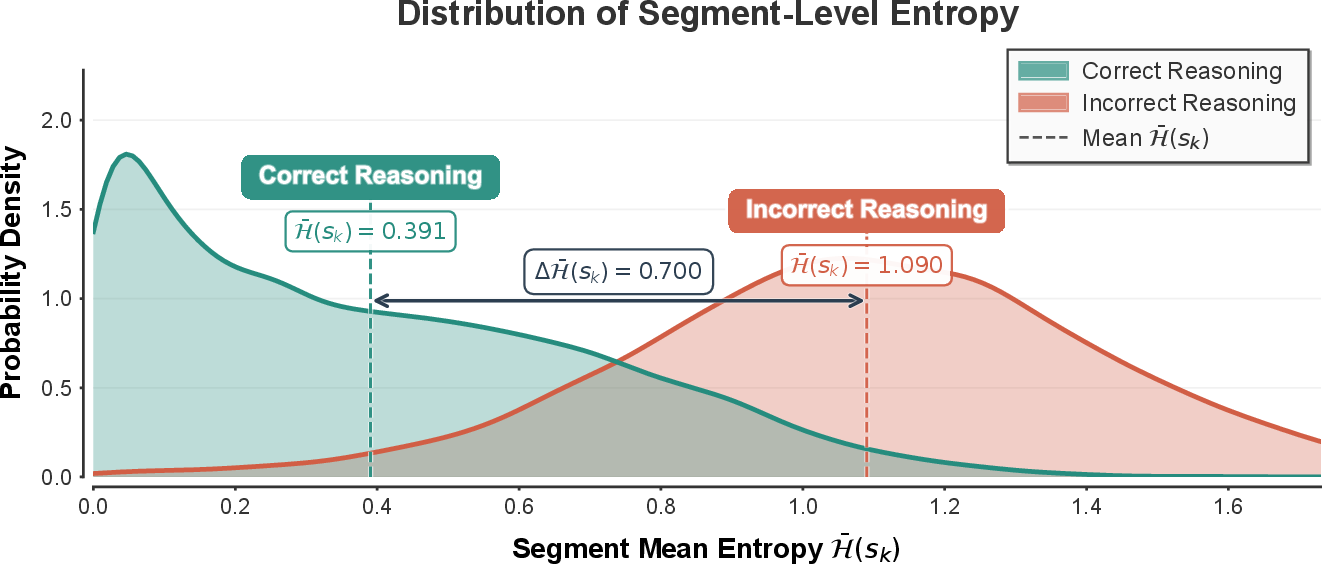
Figure 3: Entropy pattern analysis: error segments trigger distinct entropy spikes and higher average uncertainty compared to valid segments.
Importantly, a substantial subset of reasoning failures admit local recoverability; alternative continuations from the same valid prefix can yield correct solutions, indicating that many errors stem from trajectory choices rather than fundamental knowledge deficits.
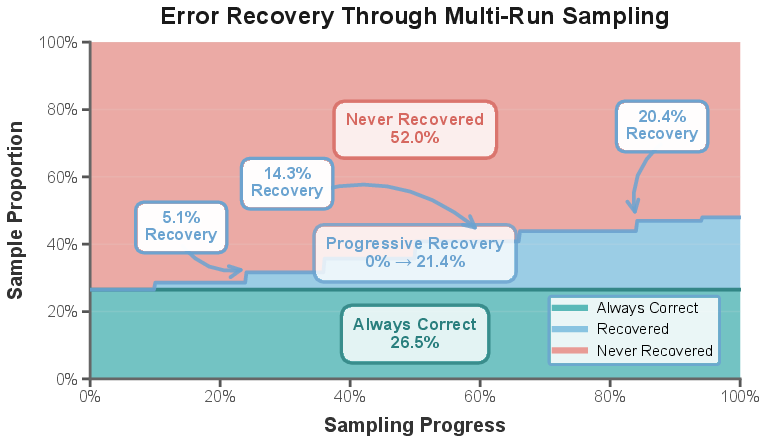
Figure 4: Recoverability analysis. A nontrivial fraction of failure cases are locally correctable from the same prefix.
GUARD: Targeted Inference-Time Rectification
Leveraging the trajectory-level insights, the paper introduces the Guided Uncertainty-Aware Reasoning with Decision control (GUARD) framework. Unlike traditional multi-path search or global scaling, GUARD operates within a single primary trajectory, interleaving local interventions only at high-risk transitions detected by adaptive entropy quantiles. When a spike is encountered at a structural boundary, GUARD initiates short-horizon parallel branching, comprising:
- Momentum branch (greedy continuation)
- Inhibitory branch (zealous interruption)
- Counterfactual branch ("Let me reconsider:" prompting logical re-framing)
The branch with minimum mean entropy is selected, and execution resumes along this revised path. Late-stage expansion is suppressed by monitoring budget exhaustion and linguistic hesitation markers, forcing termination when further deliberation yields diminishing returns.
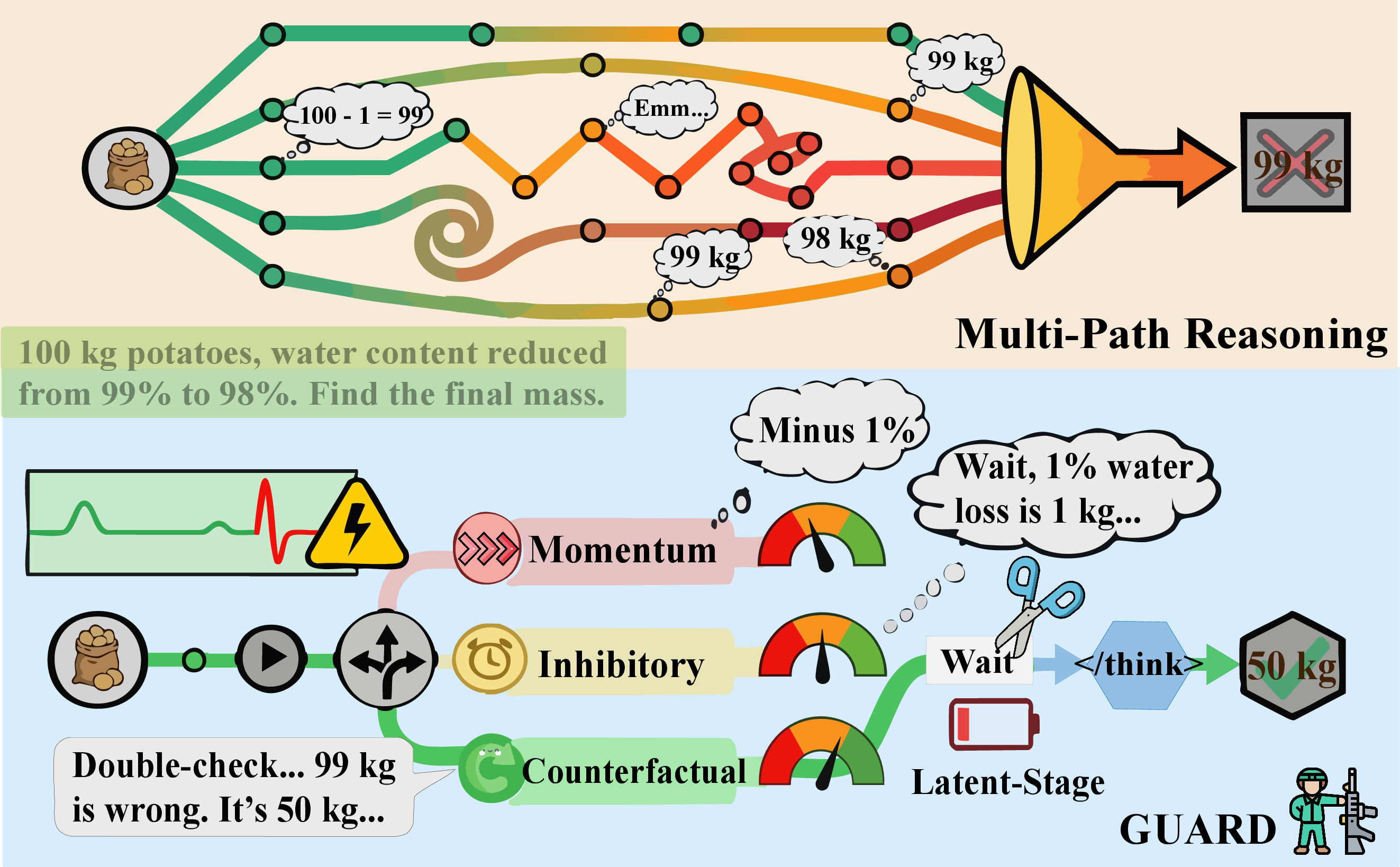
Figure 5: GUARD versus Multi-path Reasoning. GUARD avoids persistent parallel search and targets brief branching only at critical transitions.
Empirical Evaluation
GUARD's effectiveness is measured across a spectrum of benchmarks (AMC, AIME, MATH500, Minerva, OlympiadBench, GPQA) and model scales (1.5B, 7B, 32B). It consistently outperforms both single-stream optimizations and parallel search paradigms (Best-of-N, ToT, Reflexion), achieving superior Pass@1 accuracy with materially reduced token consumption. On QwQ-32B, GUARD attains 71.3% accuracy at average 7.5k tokens, compared to 68.9% for Reflexion at 9.3k tokens and 63.1% for Best-of-N at 21.8k tokens.
Ablation studies demonstrate the indispensability of each branching primitive—removal of any branch leads to absolute performance degradation (≥ 2.7%). Late-stage control is particularly critical for preventing uncontrolled epistemic spirals, with its elimination resulting in a 6.8% drop in accuracy. Hyperparameter sensitivity analysis confirms that the default configuration (q=0.9, L=200, ρmin=0.2) strikes an optimal efficiency-accuracy balance.
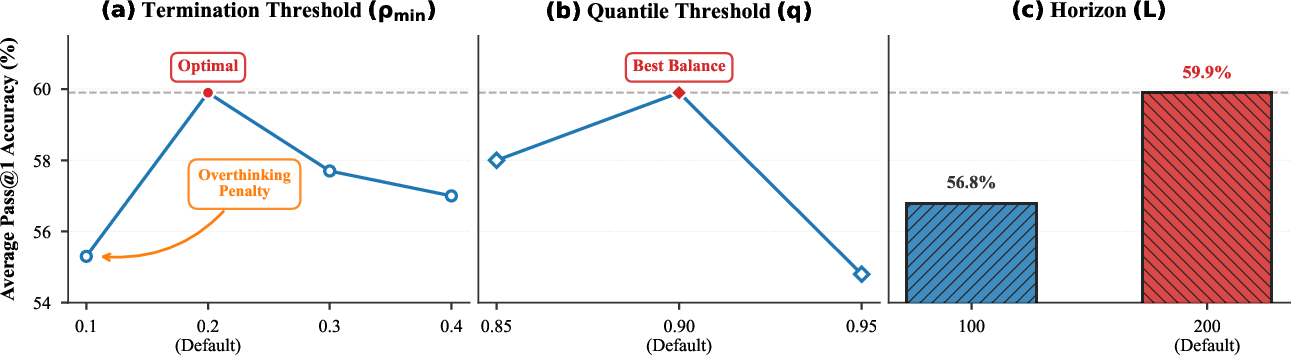
Figure 6: GUARD sensitivity and ablation. Optimal settings yield robust performance gains; omitting any branch or late-stage control materially degrades results.
Qualitative studies reveal GUARD's intervention dynamics in concrete scenarios. In high-stakes geometry, GUARD detects arithmetic-induced spirals and injects counterfactual confidence; for physics, it interrupts intuition traps with scaling-law verification; for number theory, it transforms brute-force guessing into rigorous structural proof via modular analysis.
Theoretical and Practical Implications
The findings challenge the premise that global allocation of inference-time compute (e.g., lengthy chains, persistent parallelism) uniformly improve reasoning. Instead, error origins are concentrated and recoverable, allowing targeted interventions to maximize the efficiency–performance frontier. GUARD's trajectory-level rectification complements scaling-centric approaches, mitigating redundancy and preserving solution coherence without architectural changes or additional supervision.
Practically, GUARD is a plug-in test-time mechanism, compatible with both domain-specialized and generalist instruction-tuned backbones. Its improvements are orthogonal to RL fine-tuning or entropy minimization methods, offering seamless integration across LLM paradigms. Its adaptive, data-driven uncertainty quantile trigger and in-place branching are robustly generalizable, as substantiated by transfer experiments on mathematical and wide-domain models.
Theoretically, GUARD's control-theoretic approach to cognition in LLMs expands the study of reasoning into intervention algorithms, information-theoretic detection, and dynamic trajectory repair, encouraging future work incorporating structured uncertainty models and online trajectory rectification.
Conclusion
This work establishes that reasoning failures in LLMs emerge from a limited set of identifiable, locally recoverable transition points early in the chain. GUARD intervenes at critical transitions via entropy-based detection and targeted local branching, enabling efficient correction of trajectories. Empirical and qualitative analyses demonstrate that GUARD not only improves accuracy and efficiency but also complements inference-time scaling strategies, with broad transferability across backbone types. Future research should investigate GUARD-like trajectory control mechanisms for more open-ended domains and joint training-inference integration for robust, self-correcting LLM reasoning.

