- The paper provides the first explicit theoretical mechanism for delayed loss spikes in batch-normalized linear regression.
- It derives sharp conditions for the onset and self-stabilization of instability based on effective learning rates and directional alignment.
- Synthetic experiments validate that batch normalization delays initial instability while triggering transient loss spikes in training.
Mechanisms of Delayed Loss Spikes in Batch-Normalized Linear Models
Introduction and Context
The paper "A Mechanism Study of Delayed Loss Spikes in Batch-Normalized Linear Models" (2604.16809) presents a refined analysis of the phenomenon of delayed loss spikes—distinct sudden increases in empirical loss that appear after a prolonged phase of seemingly stable gradient descent—specifically in batch-normalized linear networks. While existing work on step size-induced instability, oscillations near the edge of stability (EoS), and the implicit bias of normalization layers has advanced the understanding of neural optimization, none provide a comprehensive, theorem-level description of delayed instability that accurately mirrors the empirical patterns seen in large-scale training. This work offers the first explicit theoretical mechanism for such delayed-onset instability in a tractable linear setting with batch normalization, filling an essential gap in the analytic literature.
Theoretical Framework and Model
Batch-Normalized Linear Model
The authors study linear models equipped with batch normalization, reformulated as
logit(xi;w,α)=α∥w∥Σ⟨xi,w⟩,
where w is the parameter vector, α is a learned scale, and ∥⋅∥Σ is a data-dependent norm. Two loss regimes are addressed: square loss (least squares regression) and logistic loss (binary classification).
Gradient Dynamics
The optimization proceeds via gradient descent with separate learning rates for w and α, exploiting the scale invariance of the normalization. The parameter update is
wt+1←wt−η∇wRt,αt+1←αt−ηα∂α∂Rt,
with emphasis on the directional relationship between the current iterate wt and the reference direction w^ (least squares solution or max-margin direction).
Main Theoretical Results
Delayed Loss Spikes: Whitened Linear Regression
The centerpiece result is a complete, explicit mechanism for delayed-onset loss spikes in whitened batch-normalized linear regression (covariance Σ=I). The authors derive sharp conditions under which the directional misalignment
w0
(w1 is alignment with w2, w3 orthogonal deviation) stays small for a long period before suddenly exhibiting a "rising edge," i.e., a rapid directional divergence that drives the loss up. Crucially, instability is not immediate when w4 is large; batch normalization self-tunes the effective learning rate upward throughout the stable phase, and only once a critical threshold is crossed does the instability manifest. The rising edge is further shown to self-stabilize: negative feedback induced by normalization suppresses runaway growth, forcing a return to the stable (falling edge) regime in finite steps.
The square loss is decomposed as
w5
making the spike mechanism directly interpretable via the sudden rise and subsequent decline of w6.
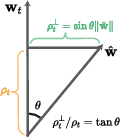
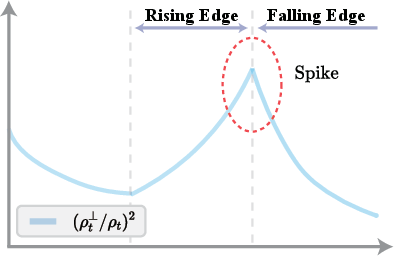
Figure 1: Left: Geometric meaning of alignment and orthogonal deviation under batch normalization. Right: Long, stable descent (falling edge), sudden instability (rising edge), and eventual self-stabilization in the trajectory of w7.
Explicit Onset and Transience Conditions
The main theorem gives explicit no-spike and delayed-spike criteria in terms of the effective learning rate
w8
relative to w9, initial alignment, and normalization rate. The onset is logarithmically delayed in the degree of alignment, explaining why spikes can occur after long periods of stable decreasing loss. The paper quantifies the maximum duration and magnitude of the rising edge, ensuring that the process is non-explosive.
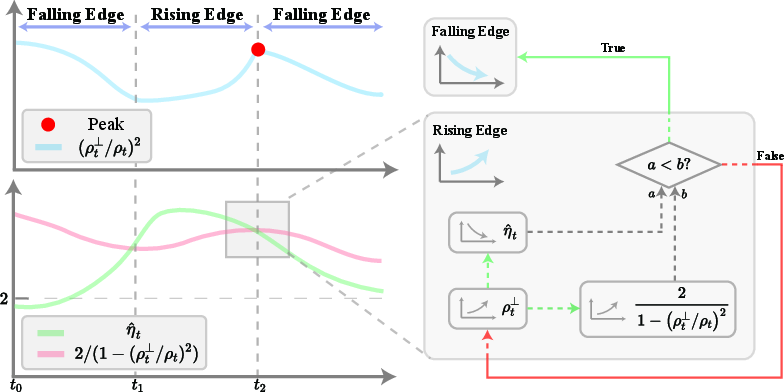
Figure 2: Schematic loss, effective learning rate, and sharpness trends in synthetic experiments, clearly exhibiting the theorem-backed delayed loss spike in the square-loss, batch-normalized regime.
Directional Analysis for Logistic Loss
The logistic case is inherently more restrictive: using strong geometric assumptions (e.g., all training points exactly on the max-margin boundary), the authors prove only that a similar directional precursor regime exists. That is, after an extended contraction phase, the dynamics can enter a short segment of instability, but explicit loss spike theorems as in the quadratic regime are not available. Entry and exit thresholds for this regime are spelled out in terms of data-dependent condition numbers, margin, and learning rate scalings.
Mechanism and Proof Roadmap
The technical engine is a direction-contraction/divergence lemma for scale-invariant models under gradient descent. For the square loss, the interaction between α0 and α1 yields a low-dimensional dynamical system: during stable alignment, the effective learning rate increases, and when instability is triggered, normalization rapidly damps the divergence by expanding α2, thus restoring stability. This feedback loop is both necessary and sufficient for the observed spike-and-recovery pattern.
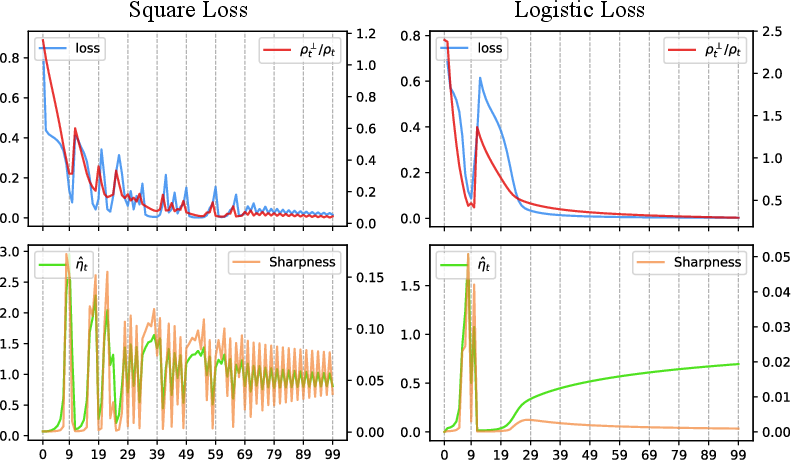
Figure 3: Synthetic illustration of the delayed-rising-edge mechanism in the square-loss regime and stylized logistic loss; rising effective learning rate triggers instability, which is then bounded by normalization-induced feedback.
Empirical Illustration
Synthetic experiments on ill-conditioned, overparameterized data sets confirm the qualitative predictions of the theoretical analysis. Batch-normalized linear models under controlled settings display clear, delayed loss spikes coinciding with directional divergence and subsequent self-stabilization.
Strong Claims and Contrasts
- Explicit sufficient and necessary conditions for delayed and self-stabilized loss spikes are proven for whitened batch-normalized linear regression.
- The logistic regression case does not, in general, support a similarly strong theorem: only a finite-horizon directional precursor is proved, under highly special data conditions.
- Contrasts with prior EoS and large-step-size linear theory are drawn: in unnormalized models, instability is always prompt; batch normalization alone can shift the onset deep into training.
Implications and Future Directions
From a practical standpoint, the paper clarifies why normalization layers can both stabilize initial optimization and yet create susceptibility to late instability, providing guidance for the tuning of step sizes and normalization parameters in large-scale training. Theoretically, the results isolate the precise normalization-driven pathway to instability, advancing the understanding of optimization in overparameterized, normalized networks.
However, the analysis is deliberately stylized; generalization to non-whitened data, multi-layer or nonlinear architectures, and the full complexity of deep learning remains open. The concrete mechanism isolated in this work sets the groundwork for extending delayed-instability analysis to more general and realistic settings.
Conclusion
This paper provides a rigorous, explicit mechanism for delayed loss spikes in batch-normalized linear regression, uniquely characterizing both onset and self-stabilization phases with theorem-level precision. While extensions to logistic and nonlinear settings remain restricted, the work marks a significant methodological advance in charting the nuanced optimization instability introduced by normalization in modern training—offering both an analytic tool for theorists and practical insight for large-model trainers.
Reference:
"A Mechanism Study of Delayed Loss Spikes in Batch-Normalized Linear Models" (2604.16809)