GenericAgent: A Token-Efficient Self-Evolving LLM Agent via Contextual Information Density Maximization (V1.0)
Abstract: Long-horizon LLM agents are fundamentally limited by context. As interactions become longer, tool descriptions, retrieved memories, and raw environmental feedback accumulate and push out the information needed for decision-making. At the same time, useful experience gained from tasks is often lost across episodes. We argue that long-horizon performance is determined not by context length, but by how much decision-relevant information is maintained within a finite context budget. We present GenericAgent (GA), a general-purpose, self-evolving LLM agent system built around a single principle: context information density maximization. GA implements this through four closely connected components: a minimal atomic tool set that keeps the interface simple, a hierarchical on-demand memory that only shows a small high-level view by default, a self-evolution mechanism that turns verified past trajectories into reusable SOPs and executable code, and a context truncation and compression layer that maintains information density during long executions. Across task completion, tool use efficiency, memory effectiveness, self-evolution, and web browsing, GA consistently outperforms leading agent systems while using significantly fewer tokens and interactions, and it continues to evolve over time. Project: https://github.com/lsdefine/GenericAgent
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces GenericAgent (GA), a smart computer helper built on top of LLMs like ChatGPT. GA’s big idea is simple: because the model has limited “short-term memory” (called a context window), it should keep only the most important information in front of it at any time. By packing more useful information into the same small space, GA solves longer, more complicated tasks with fewer mistakes and less cost.
Think of it like packing a small backpack for a long trip: if you pack the right essentials and keep them organized, you get further, faster.
The main questions the paper asks
- How can an AI agent stay smart and accurate over long tasks when its “attention span” is limited?
- How can it learn from experience so it doesn’t repeat the same mistakes next time?
- Can we do all this while using fewer tokens (the tiny pieces that make up text for AI), which makes the system faster and cheaper?
How GA works (with everyday analogies)
First, a few simple ideas:
- Token: like a chunk of a word. AI reads and writes in tokens, and there’s a limit per turn.
- Context window: the AI’s short-term memory for the current task.
- Hallucination: when the AI makes something up because it lost track of the facts.
GA is designed around “context information density,” which means keeping the most decision-helpful info in the small space the AI can actually use. It does this with four connected parts:
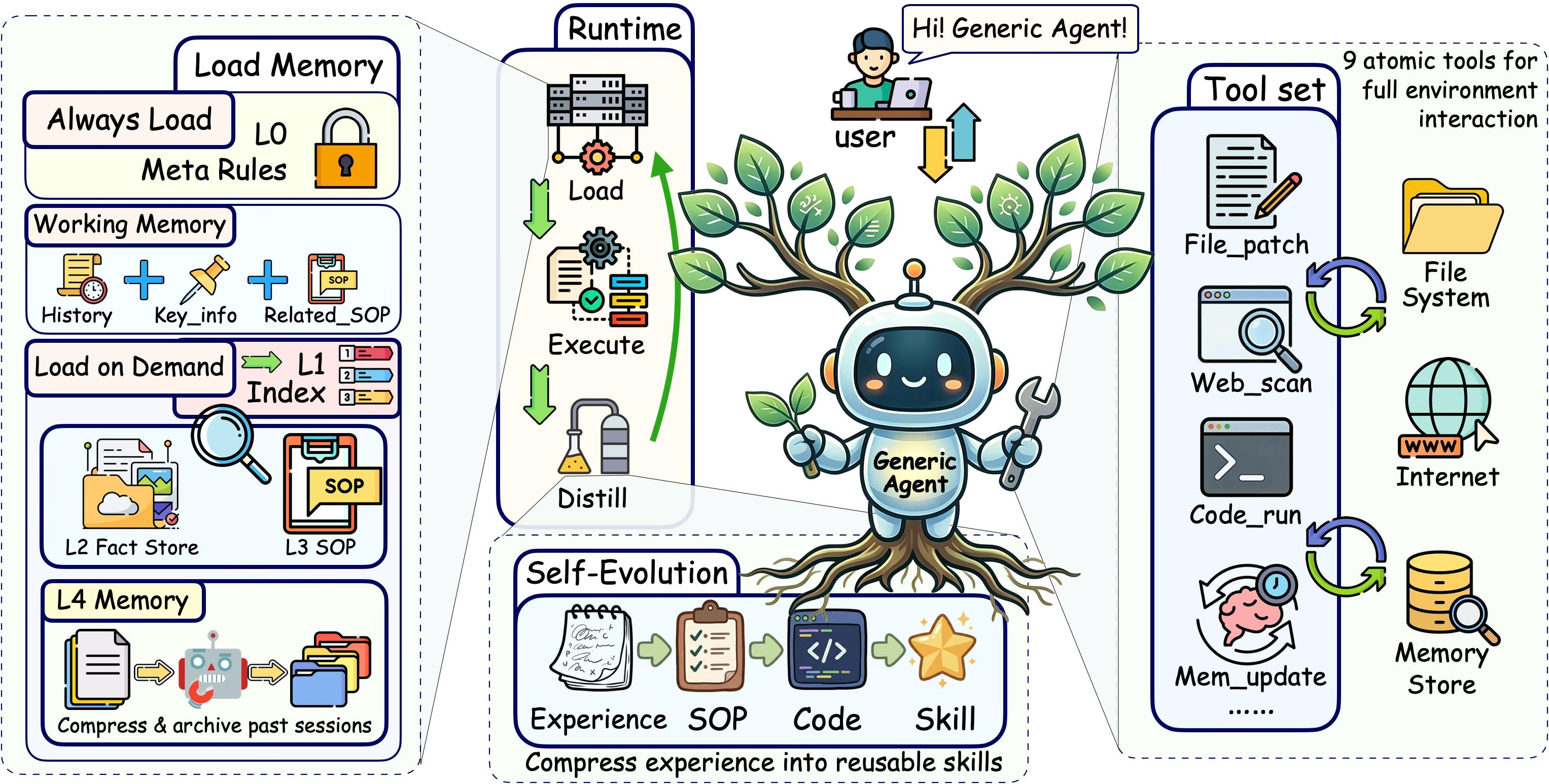
- Minimal tools: Instead of giving the AI dozens of complicated tools, GA gives it a tiny set of simple, “Lego-like” tools that can be combined to do many things. Fewer tools means less clutter and fewer wrong choices.
- Hierarchical memory: Imagine a bookshelf with layers:
- L1: A tiny index card that points to where things are (always visible).
- L2: Important facts that stay true over time.
- L3: SOPs (Standard Operating Procedures)—like recipes for tasks that worked well before.
- L4: The full history archive, saved but not shown unless needed.
- Only the index card (L1) stays in front of the AI all the time. The deeper layers are fetched only when needed.
- Self-evolution: When GA finishes a task successfully, it writes down what actually worked as a clear recipe (SOP) or small reusable code. It ignores guesses and dead ends. Over time, it builds a cookbook of reliable strategies.
- Smart context trimming: As conversations get long, GA doesn’t just keep everything. It:
- Shortens long tool outputs (keeps the beginning and end).
- Compresses old details that aren’t needed right now.
- Removes the oldest messages when space runs low.
- Keeps a small “anchor” card with key progress so nothing critical is lost.
Two extra practical details:
- GA can browse the web efficiently by reading only the meaningful parts of a page (not all the messy code behind it).
- GA runs as a simple command-line program with a very small codebase, which makes it easy to maintain and combine with other processes (it can even start a “subagent” just by calling itself).
What the researchers did
The team built GA and tested it on many tasks that require using tools, working with files, browsing the web, remembering past work, and improving over time. They compared GA to other well-known agent systems. They measured:
- Task success (did it finish the job?)
- Token efficiency (how much text did it need?)
- Memory quality (did it remember the right things?)
- Self-evolution (did it get better over time?)
- Web browsing effectiveness (did it extract useful info without wasting space?)
They also carefully designed tool rules, memory layers, and the “trim-and-compress” steps so GA stays focused and avoids costly mistakes.
The key findings and why they matter
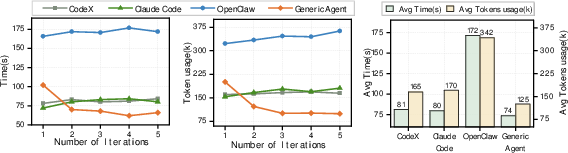
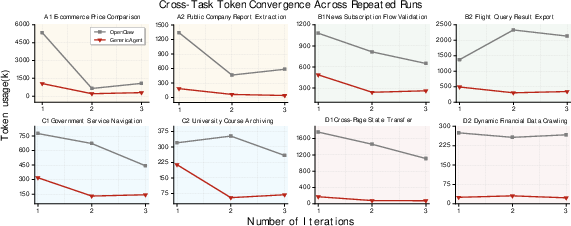
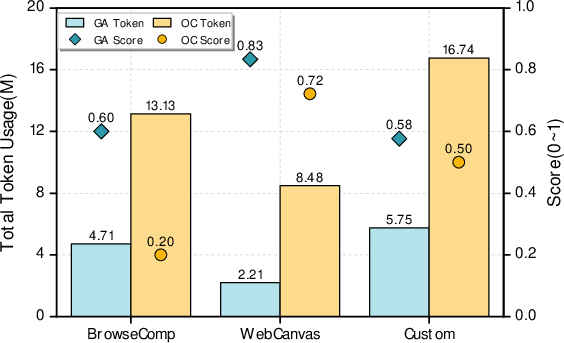
- GA solved more tasks while using fewer tokens. In other words, it was both smarter and thriftier.
- It needed fewer back-and-forth steps to finish work, saving time and cost.
- Its memory actually helped (it didn’t just hoard logs); verified successes were turned into reusable recipes and small scripts.
- Over time, GA improved by reusing what worked before, instead of relearning everything from scratch.
- Browsing and tool use were more reliable because outputs were cleaner and better organized.
Why this matters: Many AI agents slow down or get confused as tasks get longer because their “short-term memory” fills up with junk. GA shows that carefully controlling what the AI sees—and turning wins into simple “recipes”—can make long, real-world work both accurate and affordable.
What this could change in the future
- Smarter personal assistants: GA’s layered memory can remember your preferences and workflows without cluttering every conversation.
- Reliable automation: Turning successful steps into SOPs and small scripts makes repeat tasks faster and safer.
- Lower costs: Using fewer tokens and fewer steps means cheaper AI systems.
- Safer operation: Clear tool boundaries, “ask the user” when needed, and a step-by-step error recovery plan reduce risk.
- Scalable learning: As GA handles more tasks, it builds a compact, reusable knowledge base that helps it start future tasks strong.
A simple way to remember GA’s approach
- Pack smart, not heavy: Keep only the most useful info in view.
- Build with Lego blocks: A few simple tools can do a lot when combined.
- Write the recipe after you cook: Turn proven steps into reusable SOPs.
- Clean your desk as you work: Trim, compress, and anchor key info so the AI doesn’t drown in details.
By treating the AI’s context like a small but valuable workspace—and constantly keeping it tidy—GA shows how an agent can stay sharp, learn from experience, and get better over time without wasting effort.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide future research.
Theoretical foundations and metrics
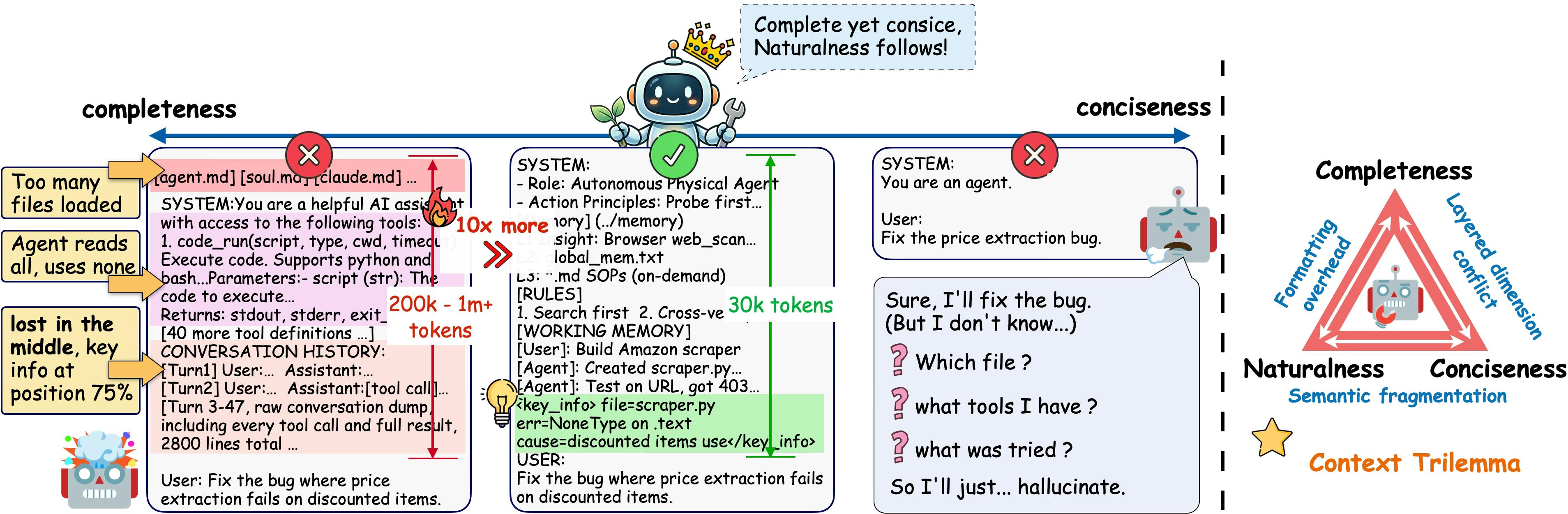
- Lack of a formal, measurable definition of “context information density” and how to optimize it; no standardized metric to quantify completeness/conciseness/naturalness trade-offs during agent execution.
- No theoretical guarantees or analysis linking the proposed truncation/compression policies to reductions in hallucination or improvements in decision quality across models.
- The claim that L1 “approaches the Kolmogorov complexity of the categorical structure” is not operationalized or empirically validated; criteria to bound L1 growth and failure cases when minimal pointers are insufficient are missing.
Context budgeting and compression
- Character-to-token approximation (α≈3) is crude and language-dependent (e.g., CJK); no adaptive or tokenizer-aware budgeting method, nor safeguards for multilingual settings and mixed content.
- FIFO message eviction may remove early but critical context; no exploration of salience-aware or learned eviction policies that preserve high-value information.
- Compression parameters (e.g., 800-character windows, 20 one-line summaries, every-5-turn compression) are heuristic; absent ablations to find robust or task-adaptive settings.
- No validation that tag-level and head–tail compression reliably preserve decision-critical details; lack of automated fidelity checks for compressed content.
- “Hallucination-free context length” is asserted (~30k tokens) but not methodologically defined or measured across models and tasks.
Hierarchical memory design and maintenance
- Criteria for promoting content to L2 (facts) and L3 (SOPs) remain informal; no explicit verification protocols, tests, or decay/expiry policies for stale facts and procedures.
- No mechanisms for conflict resolution, versioning, or rollback when previously “verified” knowledge becomes outdated or inconsistent across sessions/users.
- Scalability under long-term growth: retrieval latency/accuracy, index structures for L1 routing, and guardrails against L1 bloat are not evaluated.
- Memory contamination and drift are only informally addressed; no adversarial tests for prompt injection, tool-output poisoning, or corrupted long-term memory.
- Multitenancy and personalization: how to isolate user-specific facts/SOPs while enabling reuse; missing policies for per-user or per-project namespaces and access control.
Self-evolution and reuse
- “No Execution, No Memory” may discard valuable negative examples (failure modes, anti-patterns); strategies for retaining and leveraging failed trajectories as warnings are not explored.
- Applicability detection: no rigorous method for matching new tasks to existing SOPs or for parameterizing and composing SOPs for task variants.
- Quality control and regression testing for evolved code/SOPs are unspecified (e.g., automated tests, static analysis, sandbox checks, performance benchmarks over updates).
- Risk of accumulating brittle or environment-specific scripts (code rot); versioning, dependency management, portability, and reproducible environments are not addressed.
- Longitudinal evaluation of self-evolution (retention vs. forgetting, compounding error, net performance over months) is absent.
Tool minimality and capability coverage
- When and how to introduce new tools beyond the minimal set remains unclear; criteria quantifying the break-even between composing primitives vs. adding a specialized tool are not provided.
- The one-invocation-per-turn limit for code_run may hinder workflows needing pipelined or parallel actions; exploration of safe multi-invocation regimes is missing.
- Coverage vs. robustness: relying on code_run for everything risks fragility and security exposure; no comparison of developer effort, latency, or error rates across tool configurations.
- Model-agnostic claims conflict with API differences (e.g., tool schema elision not available on some providers); impact on performance and portability is unquantified.
Web interaction and perception
- Robustness of web_scan to modern web features (shadow DOM, iframes, dynamic content, canvas, lazy-loading, cross-origin restrictions, consent walls/anti-bot) is untested.
- No evaluation of prompt-injection and content-poisoning risks in web environments; missing mitigations for adversarial markup or deceptive UIs.
- Generalization to mobile and multimodal interfaces (screenshots, OCR, mouse/keyboard, ARIA/accessibility semantics) is not empirically assessed.
Safety, security, and governance
- Security model for code_run, file_patch, and web_execute_js (sandboxing, permissions, network/filesystem isolation, secret handling, egress controls) is not specified or evaluated.
- Data governance for L4 raw logs: retention limits, anonymization/PII handling, encryption, and compliance considerations are not discussed.
- Failure escalation could still loop or oscillate; formal stop conditions, human escalation policies, and user burden metrics are not defined.
- Human-in-the-loop (ask_user) calibration (when to ask, how to present, minimizing interruptions) and UI integration beyond CLI are unspecified.
Evaluation methodology and reproducibility
- Benchmark details, tasks, datasets, baselines, and statistical rigor are not provided in the excerpt; reproducibility (scripts, seeds, logs, and prompts) remains unclear.
- No component ablations isolating the contributions of tool minimality, hierarchical memory, self-evolution, and compression to the reported gains.
- Wall-clock latency and compute cost are not analyzed; token efficiency may trade off with increased on-agent computation (e.g., DOM processing, consolidation steps).
- Cross-model robustness (Claude vs. GPT vs. Gemini), multilingual performance, and OOD generalization are not systematically evaluated.
Systems concerns and deployment
- Subagent dispatch via CLI lacks controls for recursion, resource contention, runaway processes, and scheduling; policies for concurrency and cost caps are needed.
- Integration beyond a single-host CLI (cloud, multi-tenant services, orchestration frameworks) and observability (tracing, metrics, audit trails) are not described.
- Applicability to non-desktop domains (robotics, sensors, enterprise systems) and to richer multimodal inputs remains unexplored.
These gaps suggest concrete next steps: define and measure context-density metrics; develop tokenizer-aware budgeting; implement salience-driven retention; formalize memory promotion/expiry/versioning; create SOP applicability detection and testing; harden security/sandboxing; and conduct rigorous ablations and longitudinal studies across models, languages, and domains.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now using the paper’s methods (minimal atomic tools, hierarchical memory, self-evolution into SOPs/code, and context truncation/compression). Each item lists potential tools/products/workflows and key assumptions/dependencies.
- Token‑efficient developer CLI copilot for long-running coding tasks [software]
- What: Automate code reading, precise patching, test authoring, refactoring, and script execution with audit trails.
- How:
file_read,file_patch(unique-match editing),file_write,code_run(one invocation per turn), L3 SOPs for recurring dev workflows. - Products/workflows: Terminal/VScode integration; CI/CD “agent runner” that reuses SOPs across repos; PR auto-fix assistant.
- Assumptions/dependencies: High-quality LLM; sandboxed execution; repo permissions; reliable unit tests; org acceptance of auto-edits.
- Runbook automation and incident response (watchdog/cron) [IT ops/DevOps]
- What: Encode runbooks into L3 SOPs and trigger them via Reflect Mode (watchdog) for log anomalies, service restarts, backups, and configuration drift fixes.
- How: Reflect Mode triggers;
code_runfor shell actions; working-memory anchors for state continuity; L4 archives for forensics. - Products/workflows: “Agent runbook daemon” for on-call; scheduled maintenance jobs; escalation via
ask_user. - Assumptions/dependencies: Access controls; rollback paths; credential management; human-in-the-loop for high-risk steps.
- Browser RPA and enterprise workflow automation [RPA/enterprise software]
- What: Automate internal web apps (dashboards, forms, approval workflows) with structured page understanding and minimal token usage.
- How:
web_scan(layout-aware DOM pruning) +web_execute_js(action+page-change feedback); L3 SOPs per workflow. - Products/workflows: Headless browser agent; HR/finance portal automations; QA smoke tests replayable from SOPs.
- Assumptions/dependencies: Stable selectors; anti-bot policies; identity/auth flows (MFA handling via human step); headless browser driver availability.
- Cost-optimized web research and data collection [marketing, finance, academia]
- What: Long-horizon information gathering (news, filings, papers) with token-efficient page parsing and reusable search SOPs.
- How:
web_scantoken reduction; SOPs for source lists, query strategies, de-duplication; L2 facts for verified findings. - Products/workflows: Competitive intelligence digests; earnings call extractors; literature triage pipelines.
- Assumptions/dependencies: Site ToS compliance; captchas/MFA handling; reliable source verification rules.
- Knowledge base and SOP consolidation with traceability [enterprise ops]
- What: Transform successful task trajectories into L3 SOPs and small reusable scripts; keep L4 archives for audits; maintain compact L1 index for routing.
- How: Self-evolution pipeline (“No Execution, No Memory”); triggered commits to L2/L3; L1 pointers for on-demand retrieval.
- Products/workflows: SOP repository + runner; “agent knowledge pack” per team; audit dashboard over L4.
- Assumptions/dependencies: Curation and approval workflows; storage governance; naming/versioning conventions.
- Customer support triage and resolution assistant [customer service]
- What: Suggest and execute SOP-based remediation steps on tickets; browse KBs; escalate via
ask_user. - How: L3 SOPs from historical fixes;
web_scanfor KB;file_read/writefor artifacts; working-memory anchor to persist ticket context. - Products/workflows: Ticket-resolution copilot; standardized recovery playbooks; automatic log attachment and summaries.
- Assumptions/dependencies: Access to ticketing/KM systems; PII handling/compliance; human review for customer-facing communication.
- What: Suggest and execute SOP-based remediation steps on tickets; browse KBs; escalate via
- Personal digital admin and scheduling [daily life]
- What: Automate recurring tasks: file organization, backups, bill pay reminders, price watches, travel planning routines.
- How: Reflect Mode for event triggers;
web_scan/web_execute_jsfor portals; L3 SOPs reflecting personal preferences;update_working_checkpoint. - Products/workflows: Personal “agent cron”; preference-aware booking flow; monthly financial housekeeping.
- Assumptions/dependencies: Credentials storage security; consent and review steps for payments; site stability.
- Education and research pipelines [education, academia]
- What: Literature discovery, annotation, and replication SOPs; maintain long-term memory of research questions and datasets.
- How:
web_scanfor papers; L2 facts for validated findings; L3 SOPs for analysis pipelines; L4 for reproducibility logs. - Products/workflows: Paper triage assistant; lab-method SOP generator; student study routines that evolve over time.
- Assumptions/dependencies: Access to paywalled sources or proxies; dataset permissions; human validation of scientific claims.
- QA and end-to-end UI testing [software QA]
- What: Recordable/replayable test flows with DOM-aware scanning and JS execution; store as SOPs for regression suites.
- How:
web_scan+web_execute_js; L3 test SOPs; working-memory anchors for test state; L4 run logs for failure analysis. - Products/workflows: Agent-driven smoke/regression tests; flaky test triage assistant.
- Assumptions/dependencies: Stable test environments; fixture data; headless execution support; CI integration.
- Compliance and audit trails by design [finance, healthcare admin, public sector]
- What: Use L4 archives and selective memory promotion for traceable, reproducible automations; minimize prompt bloat for safer reasoning.
- How: Context truncation pipeline (stages 1–4); L4 durable session archives; controlled L2/L3 promotion.
- Products/workflows: Automated audit packet generation; change logs for policy execution; reproducible compliance routines.
- Assumptions/dependencies: Retention policies; redaction for sensitive data; legal review for automation scope.
Long-Term Applications
These opportunities require further research, scaling, safety frameworks, or ecosystem development before broad deployment.
- Autonomous enterprise process orchestration across systems [enterprise software]
- What: Organization-wide SOP catalogs with cross-app, cross-team automations; subagent dispatch for parallel workflows.
- How: Standardized L3 SOP schemas; subagent spawning via CLI; shared L1 routing with role-based access.
- Tools/products/workflows: “AgentOps” platform with SOP marketplace, approval gates, and execution graphs.
- Assumptions/dependencies: Enterprise auth, RBAC, change management; robust rollback; organizational alignment.
- Regulated-domain task automation (e.g., EHR admin, prior authorization) [healthcare]
- What: Automate multi-step administrative workflows while ensuring safety and compliance (HIPAA, GDPR).
- How: L3 SOP validation gates; strict
ask_usercheckpoints; L4 audit and redaction pipelines; sandboxed, policy-aware tools. - Tools/products/workflows: Health admin agent with integrated compliance engine; prior auth packet builder.
- Assumptions/dependencies: Legal approval; vendor/EHR integrations; rigorous human oversight; incident response plans.
- Finance operations and reporting agents [finance]
- What: End-to-end reporting/prep workflows, regulatory filings, reconciliation, low-latency monitoring agents.
- How: SOPs for data pulls and controls;
web_scan/API hybrids; escalation thresholds; conservative memory promotion. - Tools/products/workflows: Close-of-business agent; filings assistant; supervisory dash with kill-switches.
- Assumptions/dependencies: Compliance regimes; segregation of duties; high-availability infra; latency SLAs.
- Formal verification and safety-graded SOPs [software safety, AI governance]
- What: Verified SOP/code artifacts with typed preconditions/postconditions and automatic checks prior to execution.
- How: Extending L3 with contracts/tests; pre-execution simulators; policy engines; formal methods integration.
- Tools/products/workflows: SOP verifier; “safe-to-run” gates; policy-as-code overlays for sensitive steps.
- Assumptions/dependencies: Tooling maturity; institutionally accepted safety standards; model reliability on formal prompts.
- Cross-device/on-device agents with tight compute/context budgets [mobile, edge]
- What: Persistent agents operating on-device using GA’s compression to fit small context windows and intermittent connectivity.
- How: Aggressive truncation/compression; minimal L1 footprints; compact SOPs; delayed sync to central L4.
- Tools/products/workflows: Mobile task agents; offline-first personal assistants.
- Assumptions/dependencies: Efficient local models; secure storage; energy constraints; OS sandboxing.
- Multi-agent organizational patterns with dynamic subagent hierarchies [software, robotics-like orchestration]
- What: Hierarchical delegation of tasks to specialized subagents; coordination via SOP contracts and shared memory maps.
- How: CLI-based subagent spawning; L1 routing; L4 shared logging; watchdog/scheduler orchestration.
- Tools/products/workflows: Agent orchestration layer; team-of-agents for complex projects.
- Assumptions/dependencies: Resource isolation; inter-process communication standards; conflict resolution protocols.
- Public-sector service delivery automation [policy/government]
- What: SOP-driven workflows for benefits processing, permit issuance, and public information updates with traceability.
- How: Codified policy->SOP translation; L4 transparency logs; mandatory human checkpoints; web portal automations.
- Tools/products/workflows: Digital clerk agents; public audit portals for transparency.
- Assumptions/dependencies: Legal mandates; citizen data privacy; procurement and vendor integration; accessibility standards.
- Federated/self-evolving knowledge networks with privacy guarantees [enterprise, research]
- What: Share de-identified SOPs and L2 facts across units to accelerate learning while preserving confidentiality.
- How: Differentially private memory promotion; federated L1 indices; SOP templating and parameterization.
- Tools/products/workflows: Federated SOP exchange; compliance filter pipelines.
- Assumptions/dependencies: Privacy tech; governance frameworks; metadata standards for SOPs.
- Model- and training-time integration of information-density principles [AI research]
- What: Train or fine-tune models with objectives aligned to effective context use, positional robustness, and compression-friendly prompts.
- How: Data pipelines emphasizing completeness/conciseness; loss functions for context salience; tool-use supervised signals.
- Tools/products/workflows: Benchmarks for hallucination-free context length; datasets for SOP/code distillation.
- Assumptions/dependencies: Access to training; evaluation consensus; safety in deployment.
- Human-computer interaction via robust GUI perception/control [software, assistive tech]
- What: Extend web automation to arbitrary GUIs using screen-based perception and structured action plans.
- How: Integrate vision models; SOPs encoding UI flows; more resilient selectors/anchors beyond DOM.
- Tools/products/workflows: Desktop RPA agent; accessibility assistants for users with disabilities.
- Assumptions/dependencies: Reliable screen OCR/UI detection; permission models; OS automation APIs.
Notes on Cross-Cutting Assumptions and Dependencies
- Underlying LLM capability: All applications rely on sufficiently strong reasoning and tool-use fidelity; model choice and prompt-caching materially impact cost and performance.
- Security and sandboxing:
code_runand file tools require strict sandboxes, permissions, and secrets management to prevent misuse. - Token/character budget heuristics: The char/token conversion heuristic has edge cases (e.g., CJK scripts); production systems should add tokenizer-aware budget checks.
- Tool adapter availability: Stable browser drivers, OS automation hooks, and API connectors are required for reliable execution.
- Compliance and ethics: Regulated sectors need human oversight, approvals, redaction, and auditing via L4; automation scope must respect organizational and legal constraints.
- Change management: SOP evolution should include reviews, versioning, and rollback; memory pollution is mitigated by the “No Execution, No Memory” rule but still needs governance.
Glossary
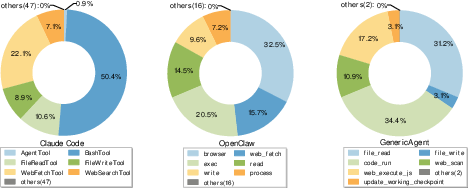
- Atomicity: In tool design, restricting each tool to a single, irreducible capability to reduce overlap and complexity. Example: "In practice, tool selection must satisfy two conditions: atomicity, which constrains each tool to an irreducible primitive capability, and compositional generalization, which allows complex behaviors to be realized through sequences of such primitives."
- Character-domain heuristic: A practical method for managing context length by approximating token budgets using character counts. Example: "context budget management uses a character-domain heuristic."
- Compositional generalization: The ability to achieve complex behaviors by sequencing simple primitives rather than adding specialized tools. Example: "In practice, tool selection must satisfy two conditions: atomicity, which constrains each tool to an irreducible primitive capability, and compositional generalization, which allows complex behaviors to be realized through sequences of such primitives."
- Context explosion: Rapid growth of prompt/context content over long interactions, degrading reasoning and efficiency. Example: "The first challenge is context explosion."
- Context truncation and compression: Mechanisms that shorten and condense historical context to keep it decision-relevant within a finite budget. Example: "GA introduces a context truncation and compression mechanism."
- Contextual information density maximization: The design principle of maximizing decision-relevant information per unit of context. Example: "built around a single principle: context information density maximization."
- Dispatcher: An execution router that maps structured tool calls to actual executors and manages their I/O. Example: "represents each tool as a verifiable schema contract and routes execution through a unified dispatcher."
- Document Object Model (DOM): A structured representation of a web page’s elements used for analysis and interaction. Example: "clones the live Document Object Model (DOM)"
- Effective context length: The portion of the context window a model can actually use reliably, which is smaller than the nominal window. Example: "the effective context length of LLMs falls far short of their nominal window size"
- Failure escalation: A staged mechanism for handling repeated errors by progressively stronger corrective actions. Example: "How the evolutionary trajectory is maintained: failure escalation."
- FIFO (First-In, First-Out): An eviction policy that removes the oldest items first when pruning context. Example: "removes the oldest messages (FIFO order)"
- Hallucination-free context length: An empirical upper bound on context size beyond which hallucinations significantly increase. Example: "We refer to the effective ceiling as the hallucination-free context length"
- Head-tail policy: A truncation strategy that preserves the beginning and end of long outputs while eliding the middle. Example: "Tool outputs are first truncated with a head-tail policy"
- Hierarchical memory: A layered memory organization that keeps minimal always-on information while retrieving deeper content on demand. Example: "A hierarchical memory mechanism selectively retains only verified and task-relevant knowledge"
- Human-in-the-loop: Designating points where the agent requests user input or decisions during execution. Example: "The Human-in-the-loop class is ask_user"
- JSON Schema: A machine-readable specification format used to define tool parameters and validate structured calls. Example: "parameters described by JSON Schema"
- Kolmogorov complexity: A theoretical measure of the minimal description length of information, used here to bound the index layer. Example: "the overall description length of L1 approaches the Kolmogorov complexity of the categorical structure of the knowledge set."
- Meta-memory: A global layer that defines memory organization, rules, and update boundaries for the system. Example: "GA introduces a global meta-memory layer."
- Message eviction: Removing older messages (often FIFO) from the conversation history when budget limits are exceeded. Example: "Stage 3: Message eviction."
- Monolithic prompt assembly: A prompting strategy that aggregates extensive scaffolding and history into a single, large prompt. Example: "Existing agent frameworks that rely on monolithic prompt assembly"
- On-demand retrieval: Fetching deeper memory content only when needed, rather than keeping it always in the prompt. Example: "deeper memories enter the active context through on-demand retrieval"
- Permission hierarchy: Structured limits on what each tool can do (read, patch, execute), improving safety and controllability. Example: "GA enforces a clear permission hierarchy via the injected toolset."
- Positional bias: A tendency of models to weight information differently depending on its position in the context, often disadvantaging mid-context content. Example: "models exhibit pronounced positional bias when processing long sequences"
- Prompt-cache: A caching mechanism that reuses unchanged portions of prompts to reduce compute and latency. Example: "prompt-cache hits in roughly 80% of turns."
- Retrieval-augmented memory: A memory approach that supplements the prompt by retrieving stored information at inference time. Example: "Even when retrieval-augmented memory is introduced"
- Self-evolution: The process of converting validated experience into reusable procedures and code over time. Example: "self-evolution mechanism that turns verified past trajectories into reusable SOPs and executable code"
- SOP layer: A memory tier dedicated to reusable procedural knowledge and workflows. Example: "(3) L3: SOP layer."
- Standard Operating Procedures (SOPs): Reusable, structured procedures distilled from successful executions to guide future tasks. Example: "Self-evolution pipeline compresses interaction trajectories into reusable Standard Operating Procedures (SOPs), code, and skills"
- Subagent Dispatch: Spawning and coordinating additional agent instances via the CLI to parallelize or modularize tasks. Example: "Subagent Dispatch."
- Tag-level compression: A compression pass that truncates or replaces low-value tagged content (e.g., reasoning traces) in older messages. Example: "Stage 2: Tag-level compression."
- Tool proliferation: The growth in the number of tools that increases prompt overhead and decision ambiguity. Example: "Tool proliferation introduces system-level costs at two levels:"
- Tool-output truncation: Limiting the size of individual tool outputs before adding them to history. Example: "Stage 1: Tool-output truncation."
- Tool-schema elision: Omitting unchanged tool definitions from prompts and replacing them with brief reminders to save tokens. Example: "Auxiliary: tool-schema elision."
- Verifiable schema contract: A formal, checkable specification for each tool’s interface to ensure correct invocation and results handling. Example: "represents each tool as a verifiable schema contract"
- Watchdog pattern: An event-driven mechanism that monitors for conditions and triggers tasks automatically. Example: "analogous to the watchdog pattern described later."
- Working-memory anchor prompt: A repeatedly injected summary that preserves critical state across turns despite eviction. Example: "Stage 4: Working-memory anchor prompt."
Collections
Sign up for free to add this paper to one or more collections.

