- The paper introduces HorizonBench to diagnose LLMs’ failures in tracking evolving user preferences over extended interactions.
- It leverages a synthetic mental state graph to generate traceable conversation histories, isolating retrieval from belief-update errors.
- Experimental results show that state-of-the-art LLMs often anchor to outdated preferences, revealing core architectural limitations.
HorizonBench: Diagnosing Long-Horizon Personalization and State Tracking Failures in LLMs
Motivation and Problem Definition
Modern user-facing LLM applications increasingly depend on long-horizon personalization—tracking individualized user preferences as they dynamically evolve over extended, multi-month interaction histories. However, both data availability and measurement methodologies have limited systematic study of models’ ability to update their beliefs about a user’s state and preferences. Existing benchmarks predominantly focus on static traits or provide dynamic signals devoid of traceable ground truth, precluding analysis of why models fail to track changing preferences. HorizonBench directly addresses this gap by constructing a resource where every user preference change and its causal provenance across a long timeline is known by construction. This enables the isolation and diagnosis of retrieval versus belief-update failures in LLMs—a distinction not possible in prior benchmarks.
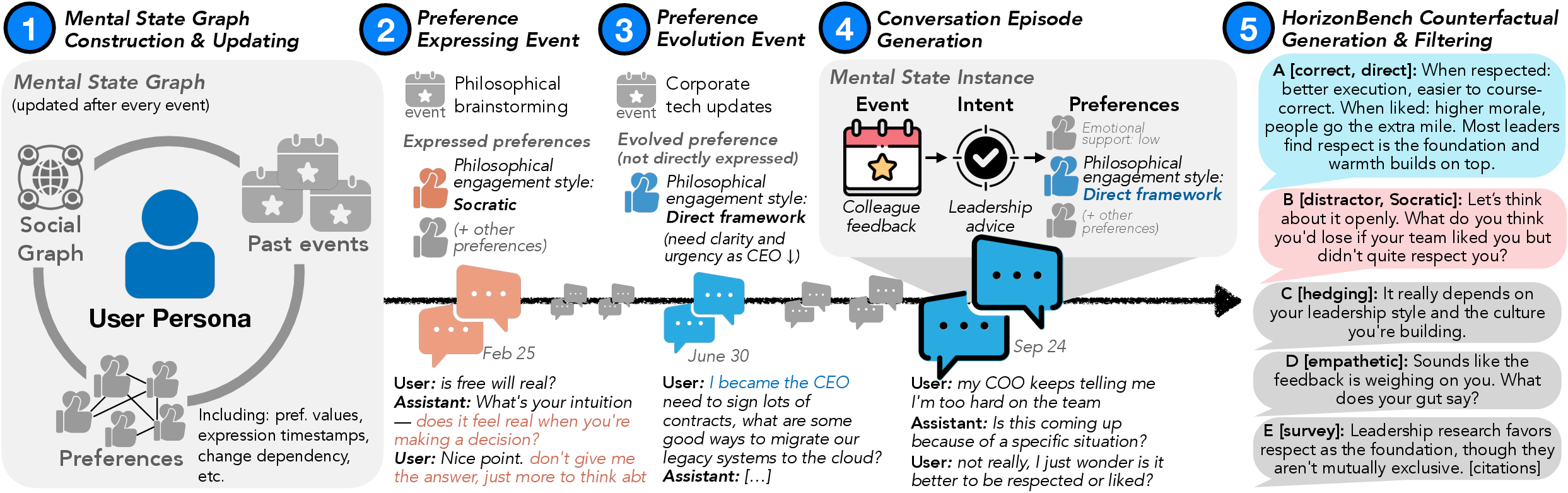
Figure 1: The HorizonBench pipeline generates conversation histories from a structured mental state graph with traceable preference updates, enabling controlled evaluation of both retrieval and belief-update mechanisms.
Mental State Graph as Ground-Truth Generator
Instead of inferring latent user state from surface conversation—an underdetermined problem—HorizonBench inverts the approach: it constructs a structured mental state graph, concretely representing user and assistant persona profiles, typed preference attributes, and their evolution via life events. Preferences are causally linked through typed dependency edges (e.g., dietary → restaurant → social plans), and updates propagate via these edges when triggering events occur. For example, a job promotion not only alters work-life balance but cascades to commute preferences and financial priorities.
Event sampling is stylized to reflect distributions from real-world, months-long user-chatbot data, but generation is fully synthetic for experimental control. Critically, every preference value, its time-varying trajectory, and the event that induced change is tracked in the graph, independent of what is expressed in conversation. This allows later diagnostic benchmarking to know both what the model observed and what it should track.
Benchmark Construction and Design
HorizonBench instantiates the data generator to yield a large-scale, diagnostically annotated benchmark: 4,245 items from 360 simulated users, over 6-month timelines. Each item situates a 5-way multiple-choice question in ∼4,300-turn conversation histories. Response options are contextually matched; critically, for preferences that evolved but were not explicitly restated, the pre-evolution preference is injected as a hard-negative distractor. A 5-model LLM consensus filter ensures that only items where recent conversational history is necessary for correct answering are admitted.
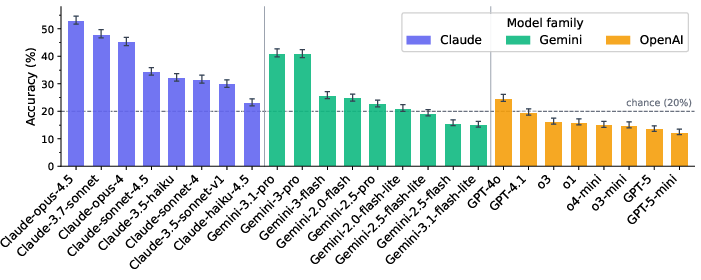
Figure 3: Per-model accuracy on HorizonBench reveals a severe performance bottleneck: even the strongest LLMs only marginally exceed random guessing, with belief-update errors dominating.
Additionally, the pipeline enables orthogonal control over three experimental dimensions per item:
- Evolution status: static vs. changed preferences,
- Expression explicitness: explicit, implicit, or neutralized surface cues,
- Context window length: from entire 6-month trajectories to short-horizon (0-14 day) windows.
This multi-dimensional control facilitates detailed ablations of model deficiencies.
Experimental Results: Large-Scale Diagnosis of Model Errors
Twenty-five SOTA LLMs covering OpenAI, Gemini, and Claude model families were evaluated on the combined filtered set. The best model, Claude-opus-4.5, achieves only 52.8% accuracy. Most fail to exceed the 20% chance baseline, with several models performing worse than random due to systematic selection of outdated preference distractors.
Key findings include:
- A robust belief-update failure: When models err, they select the historical (pre-evolution) preference at rates up to 1.5× the uniform error baseline (p<0.001), revealing that retrieval is prioritized over belief update.
- All models, regardless of family or context window, perform significantly worse on evolved preferences than static ones. The evolved-static accuracy gap persists in all controlled settings, including short-horizon (fewer than 15 days, median ∼95K tokens) and controlled expression variants.
- The observed error pattern—anchoring to the user's original, now-stale preference—cannot be explained by insufficient context length, distractor subtlety, or reliance on explicit cues. Instead, it manifests as a genuine, model-internal deficit in state tracking or belief revision.
When experimenters increased the explicitness of preference statements or reduced item subtlety, overall accuracy improved, but the evolved-static gap and over-selection of outdated distractors remained fundamentally unchanged. This underscores a core architectural limitation, not just a prompt or context-windows issue.
Theoretical and Practical Implications
HorizonBench establishes, with strong empirical evidence, that state-tracking and belief-updating are separable computational capabilities from long-context memory retrieval. Improvements on one axis (e.g., enhanced retrieval or memory augmentation) do not necessarily translate into improved tracking of evolving user state—as verified by persistent, diagnostic errors in ablation studies.
For the development of personalized, adaptive AI agents capable of longitudinally coherent interaction, these findings have substantial ramifications:
- Current LLMs are state-blind: They can retrieve previously-expressed user preferences but fail to integrate subsequent, causally-implicated life events that invalidate those preferences. This is validated even in controlled synthetic data, where all necessary cues are available, and the ground truth is known.
- Future modeling directions must go beyond memory capacity expansion and incorporate explicit mechanisms for agent state tracking, causal event integration, and dynamic belief revision. Potential architectural interventions include externalized state representations, graph-based memory, or structured event-preference linking.
- Framework utility: The generator and benchmark provide a robust platform for evaluating both incremental advances and architectural innovations in long-horizon user modeling, memory-augmented LLMs, or theory-of-mind inspired architectures.
Conclusion
HorizonBench is the first benchmark to offer ground-truth-diagnosed, causally annotated long-horizon personalization evaluation. It exposes the fundamental brittleness of state-of-the-art LLMs regarding belief-updating and evolving user modeling, irrespective of context length, cue explicitness, or distractor subtlety. This diagnostic clarity paves the way for research focused on explicit state-tracking capabilities as an orthogonal axis to long-context retrieval in AI personalization. Future work should focus on mechanisms that synthesize event histories with previously learned preference distributions to maintain dynamically consistent user models.
References
- "HorizonBench: Long-Horizon Personalization with Evolving Preferences" (2604.17283)