GPUOS: A GPU Operating System Primitive for Transparent Operation Fusion
Abstract: Modern deep learning workloads often consist of many small tensor operations, especially in inference, attention, and micro-batched training. In these settings, kernel launch overhead can become a major bottleneck, sometimes exceeding the actual computation time. We present GPUOS, a GPU runtime JIT system that reduces launch overhead using a persistent kernel architecture with runtime operator injection. GPUOS runs a single long-lived GPU kernel that continuously processes tasks from a host-managed work queue, eliminating repeated kernel launches. To support diverse operations, GPUOS uses NVIDIA NVRTC to just-in-time compile operators at runtime and inject them into the running kernel through device function pointer tables. This design enables operator updates without restarting the kernel or recompiling the system. GPUOS introduces four key ideas: (1) a persistent worker kernel with atomic task queues, (2) a runtime operator injection mechanism based on NVRTC and relocatable device code, (3) a dual-slot aliasing scheme for safe concurrent operator updates, and (4) transparent PyTorch integration through TorchDispatch that batches micro-operations into unified submissions. The system supports arbitrary tensor shapes, strides, data types, and broadcasting through a generic tensor abstraction. Experiments show that GPUOS achieves up to 15.3x speedup over standard PyTorch on workloads dominated by small operations, including micro-batched inference and attention patterns. GPUOS improves utilization while remaining compatible with the PyTorch ecosystem.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces GPUOS, a new way to run lots of tiny tasks on a GPU much faster. Instead of starting a new “mini program” (called a kernel) for every small operation—something that wastes time—GPUOS starts one long‑running program once and then feeds it a steady stream of tiny tasks. It also lets developers add new GPU “tools” on the fly without stopping the system.
In plain terms: if a GPU is like a factory, most systems keep stopping and restarting the machines for every little job. GPUOS keeps the machines running and hands them new jobs instantly, which saves a lot of time.
The main goals and questions
The paper focuses on simple, practical questions:
- How can we avoid the repeated start-up cost every time the GPU runs a small operation?
- Can we keep the flexibility to run many different kinds of operations without restarting the GPU program?
- Can this work seamlessly with popular tools like PyTorch?
- Does this actually make real workloads faster and more efficient?
How it works (explained simply)
Here are the core ideas, explained with everyday analogies:
- Persistent kernel (always-on workers): Instead of launching a new GPU program for each small task, GPUOS launches one program once and keeps it running. Think of an assembly line where workers stay at their stations, ready to grab the next item—no repeated clock-in/clock-out.
- A shared to-do list (ring buffer): The CPU (your computer’s main brain) writes tasks into a simple “to-do list” that the GPU can see. GPU workers pick up tasks one by one. This avoids the slow “Hey GPU, please start!” back-and-forth for every tiny task.
- A toolbox that can be updated live (operator table): Each task says which “tool” (operation) to use—like add, multiply, softmax, or attention. These tools live in a device-side “phonebook” of function pointers (a list of addresses pointing to the right functions). GPUOS can safely swap in new tools while the assembly line is running—no shutdown needed.
- Just-in-time (JIT) “tool making”: If you need a new tool, you don’t rebuild the whole factory. You compile that single tool on the fly (using NVIDIA’s NVRTC), load it, and publish it into the toolbox. It’s like 3D-printing a new wrench and handing it to the worker without stopping the line.
- Safe updates (no half-finished swaps): GPUOS uses a version flip and a dual-slot aliasing trick to make sure workers never see a half-updated toolbox. Updates happen atomically, so every worker either sees the old set of tools or the new one—never something broken in between.
- Plays nicely with PyTorch: GPUOS plugs into PyTorch so your normal code can keep working. It automatically routes small, overhead-heavy operations through the GPUOS path while leaving big, heavy computations alone (so it doesn’t get in the way).
What they did to test it
The team evaluated GPUOS on common hardware and compared it against:
- Standard PyTorch (eager mode)
- PyTorch’s JIT/TorchScript
- CUDA Graphs (a way to bundle many operations into one launch)
They ran:
- Synthetic tests with lots of tiny element-wise operations
- Attention-heavy decoding (like generating text token-by-token)
- Mixed, realistic inference pipelines with variable shapes and control flow
They measured speed (how fast), latency (how long each token/operation takes), and energy use.
Key results and why they matter
- Much faster on small operations:
- Up to 15.3× faster for workloads full of tiny ops (on an NVIDIA H100).
- Big wins happen because GPUOS removes the “start-up” cost that used to be repeated hundreds of times.
- Faster attention decoding:
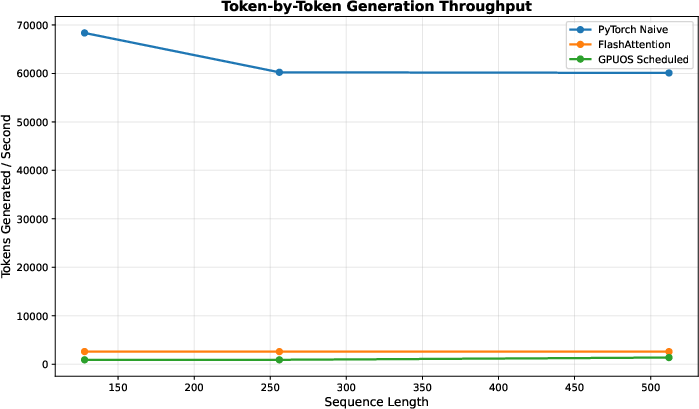
- Up to 8.7× faster for token-by-token attention patterns (common in chatbots and LLMs).
- This cuts per-token waiting time, improving response speed.
- Big improvements in realistic pipelines:
- Up to 23.1× faster in mixed inference tasks with lots of small steps between big matrix multiplies.
- Saves energy:
- 20–22% less energy used, because the GPU spends less time idle and less time starting/stopping kernels.
- Works with the real world:
- Handles dynamic shapes and branching logic (where CUDA Graphs often struggle).
- Coexists with tools like CUDA Graphs, MPS (multi-process sharing), and MIG (GPU partitioning).
- Keeps PyTorch compatibility and provides debugging tools and safety checks.
In short: The big gain isn’t magic math—it’s removing a fixed cost that happens too often.
Why this is useful (simple implications)
- Faster, smoother AI services: User-facing systems (like text generation or recommendations) can respond quicker because tiny GPU tasks no longer pay a big “start-up tax.”
- Flexibility without downtime: Teams can add new GPU operations while the system is running. No rebuilds, no restarts.
- Complements, doesn’t replace, existing tools: GPUOS shines when there are lots of small, dynamic operations. For large, long-running kernels, or when graphs fit perfectly, existing methods still work great. GPUOS fills the gap where dynamism and tiny tasks make launches costly.
- Practical path forward: The approach is realistic for production: it’s integrated with PyTorch, has safety/observability features, and supports different data shapes and types.
Takeaway
GPUOS changes where scheduling happens: instead of asking the CPU to start a new GPU kernel over and over, it keeps a single, always-on GPU program that quickly “calls” the right operation for each task. That simple shift—don’t launch, just call—cuts overhead dramatically, speeds up modern AI workloads, and reduces energy use, all while staying flexible and compatible with today’s ML tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored, phrased so future researchers can act on it:
- Queue design and correctness: The paper describes a “lock-free, single-producer-single-consumer” ring buffer while multiple warps (consumers) poll concurrently; the multi-consumer (and multi-producer on the host) algorithm, atomic claim protocol, and correctness under high contention are not specified or evaluated.
- Dependency semantics and ordering: How inter-operator dependencies are enforced (e.g., per-request FIFO, DAGs, barriers) is unclear—especially when multiple warps execute tasks concurrently and when tasks from different requests touch shared tensors.
- Interaction with CUDA stream semantics: The paper does not explain how persistent in-kernel execution respects or replaces CUDA streams/events ordering, or how it interoperates with existing stream-based dependencies in PyTorch.
- Autograd and training support: While integration is said to occur at the autograd engine level, there is no treatment of backward pass semantics, gradient accumulation, checkpointing, or training-time micro-batching; evaluation is inference-only.
- Heuristic filter policy: The criteria, thresholds, and adaptivity for deciding which ops route through GPUOS (and the cost of misclassification) are not detailed or ablated; there is no dynamic tuning strategy or sensitivity analysis.
- JIT compilation latency: First-use NVRTC compile and PTX load overheads are not measured or modeled; impact on tail latency and strategies for background/warm-up compilation are missing.
- Code cache and memory management: There is no policy for module cache growth, eviction, or unload; long-term memory footprint of many injected operators and fragmentation risks are not quantified.
- Device function pointer update protocol: The “dual-slot aliasing” and version-gated update mechanism lacks formal correctness details (e.g., cross-SM visibility, ordering guarantees, and how store-release/load-acquire are realized on GPU architectures).
- In-flight execution safety: Behavior when updating an operator while some warps execute the old version is unspecified; module unload hazards and the decision to keep modules resident (and its memory cost) lack bounds and failure-handling procedures.
- Host–device memory model: The paper relies on release/acquire semantics for queue commits across CPU–GPU but does not specify which CUDA atomics/memory scopes are used or validate correctness across interconnects (PCIe vs NVLink) and architectures.
- Power/latency trade-offs for polling: Quantitative analysis of spin-poll vs backoff strategies (idle power, latency jitter, and tail behavior) is absent; only aggregate energy savings are reported.
- Co-scheduling interference: The persistent kernel’s impact on large GEMMs/CUBLAS/CUDNN (occupancy, SM residency, cache interference) is asserted to be minimal but not quantified across diverse kernels and loads.
- QoS and prioritization: There is no policy for prioritizing tasks or isolating tenants/requests (e.g., SLO-aware scheduling, head-of-line blocking prevention, per-request queues).
- Handling long-running operators: The system does not address preemption or chunking of long device functions that could cause head-of-line blocking within the persistent executor.
- Multi-producer submission: PyTorch may submit from multiple host threads; the ring buffer/API appears SPSC. A thread-safe MPSC path, lock contention, and throughput scaling under many producers are not designed or evaluated.
- Multi-GPU and distributed setups: Coordination across multiple GPUs (model/tensor parallel, pipeline parallel) and consistency of operator injection/versioning across devices are not addressed.
- Operator coverage and correctness: Claims of “arbitrary shapes/strides/dtypes/broadcasting” are not backed by a conformance test suite or numerical parity results with PyTorch across corner cases (e.g., non-contiguous tensors, mixed dtypes).
- Robustness and backpressure: Queue overflow behavior, backpressure to the framework, admission control, and fairness across requests under bursty load are unspecified.
- Fault tolerance and recovery: There is no plan for restarting a crashed persistent kernel, draining/replaying in-flight tasks, or achieving idempotent recovery after failures.
- Security model and enforcement: Guidance is provided (templates, logging), but a concrete threat model, code-signing/attestation, integrity checks, and runtime isolation guarantees (beyond MIG) are not implemented or evaluated.
- Memory safety of injected ops: Mechanisms to prevent out-of-bounds writes or validate descriptor parameters (beyond bounds-checking op IDs) are not specified; no static or runtime safety checks are described.
- Portability and vendor lock-in: The approach depends on CUDA-specific features (NVRTC, device function pointers, relocatable device code); applicability to ROCm/AMD and the plan for portability are not discussed.
- Compatibility with CUDA Graphs/NCCL: While coexistence is claimed, concrete constraints, best practices, and measured interactions (e.g., mixing with graphs, collectives, or stream-captured segments) are absent.
- Evaluation methodology rigor: Hardware descriptions are inconsistent (e.g., “RTX 5090”, “GB10”), and the paper lacks details on measurement setup (energy instrumentation, confidence intervals, warm-up, variance); reproducibility artifacts are not provided.
- Attention results vs specialized kernels: The claim of outperforming FlashAttention lacks shape regimes, kernel configs, and methodological details to explain when persistent dispatch beats highly fused specialized kernels.
- Dispatch overhead measurement: The cited “<100 ns” device-call dispatch is not methodology-validated (timer source, in-kernel measurement technique, compiler inlining control) or reported across architectures.
- Integration overheads: The cost of TorchDispatch hooks, Python–C++ boundary crossings, and pass-through overhead for ineligible ops is not quantified.
- Memory footprint accounting: The device/host memory overhead for the ring buffer, trace buffers, operator tables, and module cache is not reported or tuned under large models.
- Instrumentation overhead: The runtime cost of tracepoints, counters, and Nsight markers in the hot path is not evaluated or shown to be negligible under heavy load.
- Driver/toolchain constraints: Required CUDA versions, minimum compute capability, and stability of device function pointers across driver updates/PTX JIT changes are not specified.
- OS/environmental limits: Constraints under WDDM/Windows, data center schedulers, or time-slicing GPUs (preemption, watchdogs) are not discussed.
- Dtype/template specialization explosion: Potential code-size growth and compile latency from supporting many dtypes/shapes via templates are not analyzed; strategies (e.g., partial specialization, MLIR, LTO) are not explored.
- Mixed execution ordering: When GPUOS falls back to traditional launches (e.g., queue full or ineligible op), how cross-path ordering and correctness are maintained is not described.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now using the paper’s methods (persistent kernel, runtime operator injection with NVRTC, device-side function-pointer tables, and PyTorch TorchDispatch integration). Each item includes potential tools/products/workflows and key assumptions/dependencies that affect feasibility.
- Low-latency LLM and generative AI inference (software/cloud, consumer apps)
- What: Cut per-token latency for chatbots, code completion, search ranking, and recommendation by routing small ops (activations, layernorms, softmax, KV-cache updates) through a persistent kernel while leaving GEMMs on vendor libraries.
- Tools/workflows: PyTorch plugin (TorchDispatch interposition); Triton Inference Server backend or custom backend; canary release and kill-switch for new operators; Nsight-compatible observability.
- Dependencies: NVIDIA GPUs with CUDA Driver API and NVRTC available; ops dominated by small kernels; RBAC and code-signing for operator templates; GPUOS queue capacity sizing; PyTorch 2.x.
- Micro-batched online serving in production (software/cloud)
- What: Improve throughput and tail latency for micro-batch inference (token-by-token decoding, streaming ASR/TTS) by eliminating repeated kernel launches.
- Tools/workflows: GPUOS fused submissions; per-request batching at TorchDispatch; dashboarding for ring-buffer saturation and operator dispatch mix.
- Dependencies: Eager/dynamic execution paths; stable integration with existing batching layers; fallback to standard kernels for big ops.
- Hot-patching and A/B testing of GPU operators without downtime (MLOps/DevOps)
- What: Deploy custom ops (e.g., new activation or attention variant) via runtime injection and safely roll forward/back using versioned operator tables and kill switches.
- Tools/workflows: CI/CD pipeline that compiles curated CUDA templates with NVRTC, signs artifacts, publishes to module cache; audit logs; canarying and rollback.
- Dependencies: Organizational policy for code signing and approvals; template library curation; production NVRTC availability and driver compatibility.
- Energy and cost reduction for latency-sensitive services (cloud/data center operations)
- What: Reduce idle gaps between small kernels to save 20–22% energy in applicable workloads; translate into lower $/QPS.
- Tools/workflows: Power/throughput dashboards; capacity planning that exploits higher utilization from persistent scheduling.
- Dependencies: Workloads where launch overhead dominates; power measurement instrumentation; PUE-aware savings validation.
- Coexistence in multi-tenant GPUs using MPS/MIG (cloud providers, platform teams)
- What: Run GPUOS within MPS clients or in MIG slices to maintain isolation while accelerating small-op pipelines.
- Tools/workflows: Kubernetes operator/DaemonSet for GPUOS runtime; MIG-aware resource requests; per-tenant operator tables and quotas.
- Dependencies: MIG-enabled clusters; clear tenancy boundaries and security posture; monitoring for fairness and head-of-line blocking.
- Robotics and industrial control loops (robotics/edge)
- What: Lower inference and perception loop latency where many small GPU ops (pre/post-processing, reductions) gate control frequency.
- Tools/workflows: GPUOS as a ROS2 node component; pre/post-processing op templates; on-device profiling with Nsight Systems.
- Dependencies: NVIDIA Jetson/embedded GPUs with NVRTC support (or precompiled PTX cache); thermal/power constraints; predictable real-time scheduling.
- Healthcare inference pipelines (healthcare)
- What: Accelerate pre/post-processing and small-kernel steps around large CNNs/transformers (e.g., windowing, normalization, NMS) to reduce overall latency for interactive tools.
- Tools/workflows: Template catalog for common medical image ops; signed operator cache; change control and audit logging.
- Dependencies: Regulatory and change-management policies (e.g., IEC 62304); strict template curation; fallbacks to validated kernels; GPU confidentiality features where required.
- Real-time media and vision analytics (media/telecom)
- What: Speed up streaming pipelines by moving augmentation, normalization, and small reductions into the persistent kernel; sustain FPS under dynamic inputs.
- Tools/workflows: Integration into GStreamer/Triton-based pipelines; operator templates for common CV pre/post ops; latency SLO alerts.
- Dependencies: Pipeline stages identifiable as small ops; co-scheduling with large kernels; careful power/perf tuning.
- Fraud detection and low-latency scoring (finance)
- What: Improve p99 latency for models with many small layers/features in real-time scoring paths.
- Tools/workflows: GPUOS plugin in model servers; A/B testing with hot-swapped scoring ops; audit trails for model governance.
- Dependencies: Compliance requirements for runtime code loading; secure operator template process; deterministic execution checks.
- Academic research and teaching on GPU runtimes (academia)
- What: Use GPUOS as a platform to study persistent kernels, device-side scheduling, and dynamic operator injection with full observability.
- Tools/workflows: Course labs and microbenchmarks; tracepoint analysis; comparison with CUDA Graphs and CDP.
- Dependencies: Access to NVIDIA hardware; permissions for driver-level APIs; reproducibility harnesses.
- Irregular/HPC graph workloads with small kernels (academia/enterprise HPC)
- What: Apply persistent scheduling to graph analytics or other irregular apps where kernels are short and frequent.
- Tools/workflows: Adapt task descriptors for graph primitives; integrate with Gunrock-like frameworks; profiling of queue contention.
- Dependencies: Porting effort to wrap ops as device functions; care with memory footprints and warp scheduling.
Long-Term Applications
These opportunities require additional research, ecosystem work, or hardware/vendor support before they become broadly deployable.
- Vendor-agnostic support across AMD/Intel GPUs (software/cloud)
- What: Extend persistent-kernel and hot-injection primitives to ROCm/HIP and SYCL ecosystems.
- Potential products: HIP/SYCL-based GPUOS; cross-vendor operator template catalogs.
- Dependencies: JIT compilation and device function-pointer support on other vendors; stable driver APIs.
- Hardware-assisted persistent runtimes (semiconductor/accelerator design)
- What: Architectural support for device-side jump tables, low-latency task queues, and secure code injection to further collapse overheads.
- Potential products: “GPUOS-ready” hardware features; firmware-level queues and isolation.
- Dependencies: GPU ISA changes, security model for runtime code, vendor roadmaps.
- First-class integration in ML frameworks (frameworks/tooling)
- What: Automatic partitioning between CUDA Graphs, persistent kernels, and library calls; compiler passes that tag micro-ops for GPUOS.
- Potential products: PyTorch/TensorFlow/JAX plugins; torch.compile passes; TVM backends targeting GPUOS.
- Dependencies: Framework API evolution; correctness guarantees for autograd; robust fallbacks.
- Cluster- and multi-GPU orchestration (cloud/HPC)
- What: Distribute GPUOS queues across multiple GPUs or nodes; enable cross-device work stealing and collective-aware micro-op scheduling.
- Potential products: GPUOS controller/operator for Kubernetes/Slurm; GPUDirect/RDMA-enabled device-visible queues.
- Dependencies: GPUDirect Async/networking maturity; NCCL-friendly scheduling; backpressure and fairness controls.
- Secure, verifiable multi-tenant operator sandboxing (cloud/security)
- What: Per-tenant operator tables with strong isolation, signed artifacts, and attestation (e.g., H100 CC mode) for runtime code injection.
- Potential products: Code-signing PKI, policy engines, attestable operator caches.
- Dependencies: GPU confidential computing features; organizational security certifications; tenant isolation via MIG/contexts.
- Automatic operator template synthesis from graphs (compilers)
- What: Generate device-callable micro-ops from FX/MLIR graphs on the fly and route them through GPUOS.
- Potential products: Graph-to-template compilers; learned cost models to select persistent vs. graphed execution.
- Dependencies: Stable IRs, robust codegen for small ops, runtime correctness validation.
- Edge and automotive deployment with offline compile caches (edge/automotive)
- What: Use precompiled PTX/SASS caches signed and shipped with builds to avoid NVRTC on constrained devices; still enable hot swaps within certified templates.
- Potential products: OTA update workflows for operator caches; automotive-grade release processes.
- Dependencies: Deterministic builds; safety certification pipelines (ISO 26262); strict change control.
- SLO-, priority-, and energy-aware scheduling (cloud/platform)
- What: Policy layers that prioritize tasks by latency SLOs and energy targets within the persistent runtime.
- Potential products: SLO controllers integrated with service meshes; energy-aware autoscaling.
- Dependencies: Accurate runtime metrics; preemption/fairness models; coordination with other GPU jobs.
- Unified CPU–GPU micro-op aggregation (systems research)
- What: Extend the queueing model to co-schedule tiny CPU and GPU ops for minimal coordination overhead across devices.
- Potential products: Heterogeneous micro-scheduler; NUMA-aware shared-memory queues.
- Dependencies: Zero-copy/shared memory interfaces; unified tracing and backpressure across devices.
- Domain operator marketplaces and standards (ecosystem/policy)
- What: Curated, signed catalogs of operator templates for sectors (healthcare, robotics, finance) with compliance metadata.
- Potential products: Industry-standard registries; compliance badges and SBOMs for GPU operators.
- Dependencies: Community governance; legal/compliance frameworks for runtime-loaded GPU code.
- Safety-critical certification and deterministic modes (healthcare/automotive)
- What: Deterministic scheduling options and certified operator sets for regulated systems.
- Potential products: “Deterministic GPUOS” builds; certified template packs; audit-grade logging.
- Dependencies: Formal verification of runtime behaviors; deterministic memory and timing models; regulator engagement.
- WebGPU/browser analogs for micro-op batching (web/edge)
- What: Conceptual transfer of persistent-execution ideas to WebGPU for client-side ML pre/post-processing.
- Potential products: WebGPU libraries that amortize submission overheads for tiny ops.
- Dependencies: Browser API evolution; security sandbox constraints; lack of device-side dynamic code loading.
Each long-term item benefits from the paper’s core innovations—persistent kernels, runtime operator injection, versioned function-pointer tables, and transparent framework integration—but requires ecosystem, hardware, security, or standardization advances to reach production at scale.
Glossary
- Atomic operations: Low-level read-modify-write primitives used to synchronize concurrent threads safely. "The ring buffer uses atomic operations for synchronization"
- Autograd engine: PyTorch’s component that schedules and executes operations for automatic differentiation. "dispatch interposition at the autograd engine level."
- Broadcasting semantics: Rules that define how tensors with different shapes are expanded to perform element-wise operations. "arbitrary tensor shapes, strides, data types, and broadcasting semantics"
- CUDA Driver API: Low-level CUDA interface for loading modules, resolving symbols, and managing execution without the runtime. "via the CUDA Driver API."
- CUDA Graphs: A CUDA feature that captures a DAG of operations for efficient replay to reduce launch overhead. "CUDA Graphs address this problem directly by moving preparation out of the hot path."
- Directed acyclic graph (DAG): A graph with no cycles, often representing dependencies between GPU operations. "a directed acyclic graph (DAG) of work"
- Dynamic operator injection: Adding or updating GPU operators at runtime without restarting the persistent kernel. "dynamic operator injection: new operators can be compiled at runtime, loaded safely, and made callable without restarting the persistent kernel or interrupting in-flight work."
- Dynamic Parallelism: CUDA capability allowing kernels to launch other kernels from the device. "Dynamic Parallelism enables device-launched kernels, allowing a running kernel to spawn additional work"
- Eager execution: Immediate execution of operations as they are called, rather than building a static execution graph. "GPUOS retains the semantics of eager execution while reaping the performance gains of persistent scheduling."
- FlashAttention: An optimized attention kernel/algorithm designed to improve performance and memory efficiency. "outperforming both FlashAttention~\cite{dao2022flashattention} and PyTorch compiled mode."
- Function pointer table: An array of device function addresses used to dispatch operations indirectly on the GPU. "dispatch to the appropriate operator through a function pointer table"
- GEMM: General Matrix-Matrix Multiply, a core linear algebra primitive. "large GEMMs still launch traditionally"
- GPUOS: A GPU runtime system using a persistent kernel and runtime operator injection to remove kernel launch overhead. "We present GPUOS, a GPU runtime JIT system that reduces kernel launch overhead through a persistent kernel architecture combined with runtime operator injection."
- Host-to-device handshake: The coordination and submission path between CPU (host) and GPU (device) that incurs overhead. "where the very properties that once made the host-to-device handshake negligible now make it dominant."
- Hot-swapping: Replacing GPU operators live without restarting the kernel or recompiling the system. "hot-swapping of GPU operators without kernel restarts or system recompilation."
- JIT compilation: Just-in-time compiling code at runtime for flexibility and specialization. "just-in-time compile new operators at runtime"
- Jump table: A table of function addresses enabling indirect calls and fast operator dispatch. "an updatable jump table of device function pointers"
- Kernel launch overhead: The fixed cost of preparing and launching a GPU kernel, including driver and synchronization work. "reduces kernel launch overhead"
- Kill switches: Mechanisms to immediately disable problematic operators at runtime for safety and debugging. "Kill switches enable instant disabling of misbehaving operators by replacing their table entries with stubs that fail quickly and surface errors on the host."
- Load-acquire semantics: A memory ordering guarantee ensuring that subsequent reads/writes observe prior writes before a load. "load-acquire semantics"
- Micro-batched inference: Serving small batches (often near per-request) to reduce latency, which increases launch overhead sensitivity. "micro-batched inference (up to 8.7x utilization)"
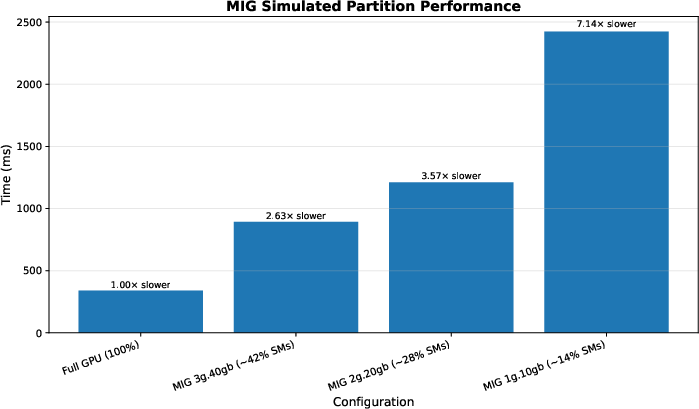
- MIG (Multi-Instance GPU): Hardware partitioning of a GPU into isolated slices with dedicated resources. "MIG (Multi-Instance GPU) takes a different approach by partitioning a GPU into isolated slices"
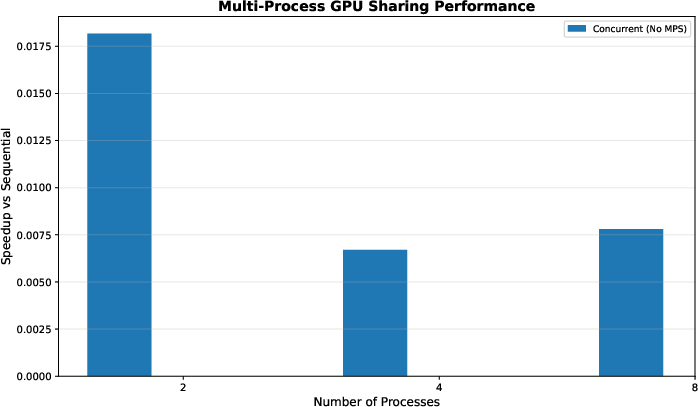
- MPS (Multi-Process Service): NVIDIA service allowing multiple processes to share a GPU context to improve utilization. "MPS (Multi-Process Service) raises utilization by allowing multiple client processes to submit work cooperatively"
- NVRTC: NVIDIA’s runtime CUDA compiler used to compile CUDA code to PTX on-the-fly. "we leverage NVIDIA's NVRTC to just-in-time compile new operators at runtime"
- Null kernel: A kernel that performs no useful work, used to measure the minimal launch overhead. "Even a null kernel---one that does no useful work---clocks in around 3--7 microseconds"
- Persistent kernel: A long-lived GPU kernel that continuously processes tasks from a queue instead of relaunching for each operation. "A single persistent kernel launches at process startup and never exits."
- Persistent threads: A scheduling paradigm where threads remain resident and repeatedly fetch work from a queue. "Persistent threads offer a different approach."
- PTX (Parallel Thread Execution): NVIDIA’s virtual ISA to which CUDA code is compiled before JIT to machine code. "to PTX (Parallel Thread Execution)"
- Ring buffer: A circular queue structure for single-producer/single-consumer communication with minimal synchronization. "a ring buffer visible to device threads that never sleep."
- Rotary positional embedding: A positional encoding technique used in attention mechanisms. "a custom rotary positional embedding with a parameterization"
- Store-release semantics: A memory ordering guarantee ensuring that all prior writes become visible before a store. "store-release semantics"
- Streaming multiprocessor (SM): The fundamental parallel compute unit on NVIDIA GPUs that schedules and runs warps/blocks. "streaming multiprocessor (SM)"
- Task descriptor: A compact record describing the work to execute (operator ID, tensor pointers, sizes, flags). "task descriptors"
- TorchDispatch: A PyTorch dispatch mechanism used to intercept and route operations. "via TorchDispatch"
- TorchScript: PyTorch’s JIT/tracing IR and execution mechanism for optimized or static execution. "TorchScript: Traced execution with PyTorch's JIT compiler."
- TVM: An open-source deep learning compiler stack for graph and kernel optimization. "Compiler stacks like TVM and the PyTorch~2.0 toolchain"
- Warp: A group of threads (typically 32) that execute in lockstep on an SM. "Each warp in the persistent kernel independently polls the ring buffer"
- Work queue: A device-visible queue from which persistent threads fetch tasks to execute. "work queue"
Collections
Sign up for free to add this paper to one or more collections.