- The paper presents a concern-level diagnostic framework that shifts evaluation from binary verdicts to detailed, actionable concern mapping.
- It uses a semantically annotated match graph to quantify alignment between human and AI critiques, highlighting calibration errors and non-uniform model effects.
- Empirical findings reveal that over-escalation and diluted prioritization in AI-generated reviews may undermine trustworthiness and review quality.
Concern-Level Diagnostics for AI Peer Review: An In-Depth Analysis of "What Makes a Good AI Review?"
Introduction
The paper "What Makes a Good AI Review? Concern-Level Diagnostics for AI Peer Review" (2604.19998) presents a structured and technically rigorous framework for interrogating the quality of AI-generated peer reviews in the context of machine learning research. Conventional metrics focus on verdict agreement (accept/reject accuracy) between human and AI reviews; this work critiques such reductionism and introduces the notion of concern alignment—a multi-level diagnostic approach that shifts evaluation granularity from review-level verdicts to concern-instance identification, prioritization, and decision relevance. The study encompasses four public AI reviewer systems across six configurations and leverages data from 48 papers drawn from top-tier ML venues, using a well-annotated and independently validated procedure.
Framework: Concern-Level Alignment and the Diagnostic Ladder
The primary technical innovation is the concern alignment framework, centered on the "match graph": a bipartite, semantically annotated mapping between official (human) concerns and those surfaced by the AI system (Figure 1). Each node carries severity, provenance, and decision-weight signals, while edges encode precise semantic relationships (exact, partial, related), establishing a concrete reference for downstream quantitative analysis. This design enables nuanced evaluation beyond raw recall or verdict accuracy, facilitating fine-grained analysis of both coverage and calibration error modes.
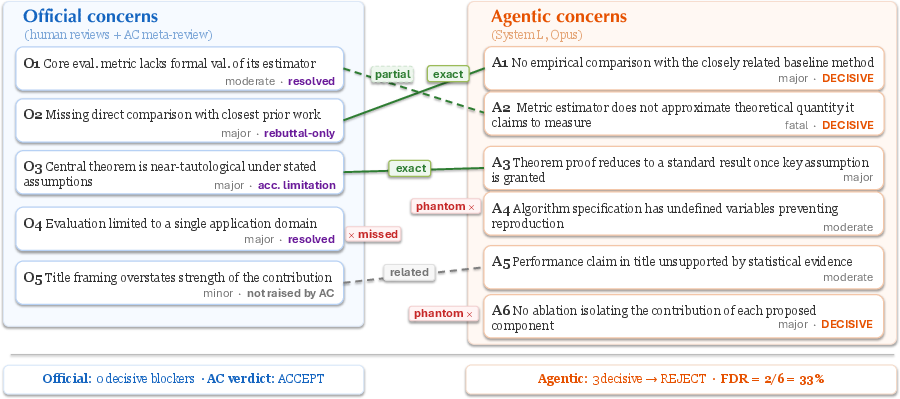
Figure 1: Match graph for an accepted paper illustrating precise matches, partial overlaps, and phantoms along with severity and post-rebuttal AC treatment markers.
Building on the match graph, the diagnostic ladder operationalizes review quality evaluation at five stratified levels:
- Verdict agreement (binary correctness),
- Concern-set alignment (coverage and phantom rates),
- Verdict-stratified metrics (behavioral shifts between accepted/rejected subsets),
- Decision-aware calibration (false decisive rate, resolved concern escalation),
- Rebuttal-aware decomposition (concern attention by AC treatment class).
This sequential breakdown makes visible the error modes and behavioral profiles that verdict aggregation inevitably masks (Figure 2).
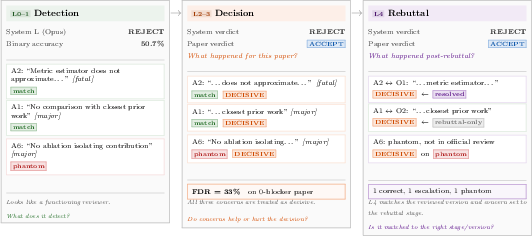
Figure 2: Progressive reveal of concern-level diagnostics exposing hidden miscalibration and escalations that verdict-level assessment ignores.
Pilot Study: Systems, Metrics, and Empirical Findings
The framework is deployed on four prominent AI reviewer paradigms:
- System L (single-shot),
- System A (iterative reflection),
- System O (structured pipeline),
- System M (multi-agent panel).
Each is instantiated on Anthropic Claude Opus and/or OpenAI GPT-4o, enabling disentanglement of model versus method effects. The core dataset comprises 48 papers focused on AI safety/alignment, ensuring substantive concern depth and rich reviewer discourse.
Notable concern-level metrics operationalized include:
- Concern recall (strict match rate),
- Phantom rate (unmatched agentic concerns),
- False decisive rate (FDR): proportion of decisive marks on concerns in accepted papers (should be zero if calibration is perfect),
- Decisive recall/precision: correct detection of true decisive blockers in rejections,
- Resolved-escalation rate: how often previously resolved concerns are re-escalated as critical by the system.
Empirical results challenge assumptions about the sufficiency of verdict- or recall-level metrics. For example, Systems L and A (Opus) present identical concern recall on rejected papers (∼44%) and decisive blocker recall (∼66–68%), but System L's FDR on accepted papers is significantly higher (0.49), flagging almost half of non-blocking issues as critical (Figure 3). System M's low FDR (0.10) appears superficially superior, but top-K decomposition reveals this arises from concern dilution rather than informed prioritization.
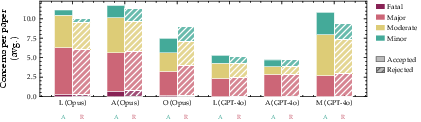
Figure 3: Average concern count by severity shows that Opus systems generate more critical concerns, but System M's lack of fatal outputs impacts both FDR and recall.
These findings are crystallized in K-ranked analyses of concern prioritization (Figure 4), which demonstrate that even high recall can co-occur with severe over-escalation when the calibration step is not explicit or aligned.
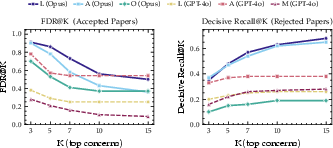
Figure 4: FDR on accepted papers (left) and decisive recall on rejected papers (right) as a function of concern list truncation. System M's FDR increases with prioritized subset, implying dilution beyond prioritization.
Model Effects, Calibration, and Error Decomposition
Pairing architectures with different underlying models exposes significant non-uniform shifts. When System L is run on GPT-4o instead of Opus, accepted-paper accuracy swings from 2.8% to 63.9%, and FDR is cut in half, but decisive recall on rejections also drops sharply. Model effects are inconsistent and interact nonlinearly with method, undermining single-number comparisons. Slope analyses of model transitions confirm the non-uniform, system-dependent interaction between model and calibration (Figure 5).

Figure 5: Model effect slopes for Systems L and A reveal non-monotonic and cross-cutting shifts in calibration and recall metrics.
Error decomposition via concern alignment supports further insights:
- Flat severity profiles across accepted/rejected papers signify models that cannot modulate concern weight by paper quality, contradicting the premise that detection alone yields useful reviews.
- System O shows the highest phantom rate and low recall, with most decisive suggestions being hallucinated or over-severe.
- Case study match graphs and adjudicated audits expose errors predominantly due to "scope inflation" rather than false positives or negatives.
Validation, Robustness, and Limitations
Comprehensive measurement validation includes independent re-audits (GPT-5.4 Pro), inter-annotator agreement (κ>0.91), structured calibration with exemplars, and rigorous extraction/QC procedures on both official and agentic concern inventories. Despite possible residual circularity—AI-based analysis of AI system output—the methodology's bias is mitigated via multi-model cross-validation and human adjudication.
Acknowledged limitations are:
- The study's evidence is necessarily restricted to one topic area (AI safety), a modest number of papers, and a non-exhaustive set of systems—precluding population-level benchmarking.
- Decision calibration relies on AC judgments, which serve as an operational anchor but not as a gold standard.
Implications and Future Directions
The concern alignment framework demonstrates that system-level verdict agreement is not only unstable but may positively reward systems that over-reject or over-produce concerns indiscriminately. Prioritization and decision weight assignment emerge as binding constraints on review usefulness, with existing LLM-based systems frequently failing at the calibration step. For research communities exploring AI-assisted science, publication workflows, or risk/critiquing agents in deployment, these findings recommend the adoption of concern-level diagnostic ladders as an auditing substrate.
Future research directions should include:
- Expanding to broader scientific domains and venues,
- Integrating native calibration mechanisms into LLM reviewers,
- Developing training objectives and architectural choices explicitly targeting not just detection coverage but alignment with human prioritization and post-rebuttal rationale,
- Building comprehensive, versioned concern-alignment datasets to drive model innovation.
Conclusion
Verdict-level agreement is an inadequate proxy for diagnostic validity in AI-generated reviews. This work's concern alignment framework anchors evaluation in the actionable unit of peer review—concrete, weighted concerns tied to the final decision rationale. Concern-level metrics expose failure modes invisible to aggregate metrics: verdict-blind severity, over-escalation, notable non-uniform model effects, and gaps between detection and prioritization. The framework contributes both a methodological advance and a set of reproducible artifacts for the critical evaluation of AI in scientific assessment—a precondition for trustworthy, actionable, and interpretable AI feedback pipelines.