- The paper introduces Deterministic Projection Memory (DPM) as a stateless architecture that guarantees deterministic replay, auditability, and multi-tenant isolation in regulated enterprise settings.
- Evaluation results show that DPM significantly improves factual precision and reasoning coherence over stateful approaches, especially under tight budget constraints.
- The study demonstrates that adopting a stateless memory design reduces operational complexity and cost, aligning agent memory with stringent compliance requirements.
Stateless Decision Memory for Enterprise AI Agents: An Authoritative Review
The paper presents Deterministic Projection Memory (DPM), a deliberately minimalist agent memory architecture engineered for the requirements of enterprise AI deployment in regulated decision-making domains, including underwriting, insurance claims adjudication, and clinical review. The work identifies a persistent mismatch between the academic literature on agent memory—which has advanced a series of increasingly sophisticated stateful, path-dependent architectures—and the prevailing preference in enterprise practice for retrieval-augmented generation (RAG) pipelines. A central claim is that this preference is not explained by accuracy results, but rather by a set of underappreciated system-level properties demanded by actual regulated environments: deterministic replay, auditable rationale, multi-tenant isolation, and stateless operation at serving scale.
The exposition makes explicit that stateful memory architectures, by their nature, fundamentally violate these constraints and that retrofitting statelessness and replayability is costly and fragile. As demonstrated in (Figure 1), DPM satisfies all four properties by architectural construction, while stateful architectures incur increasing engineering debt as their sophistication grows.
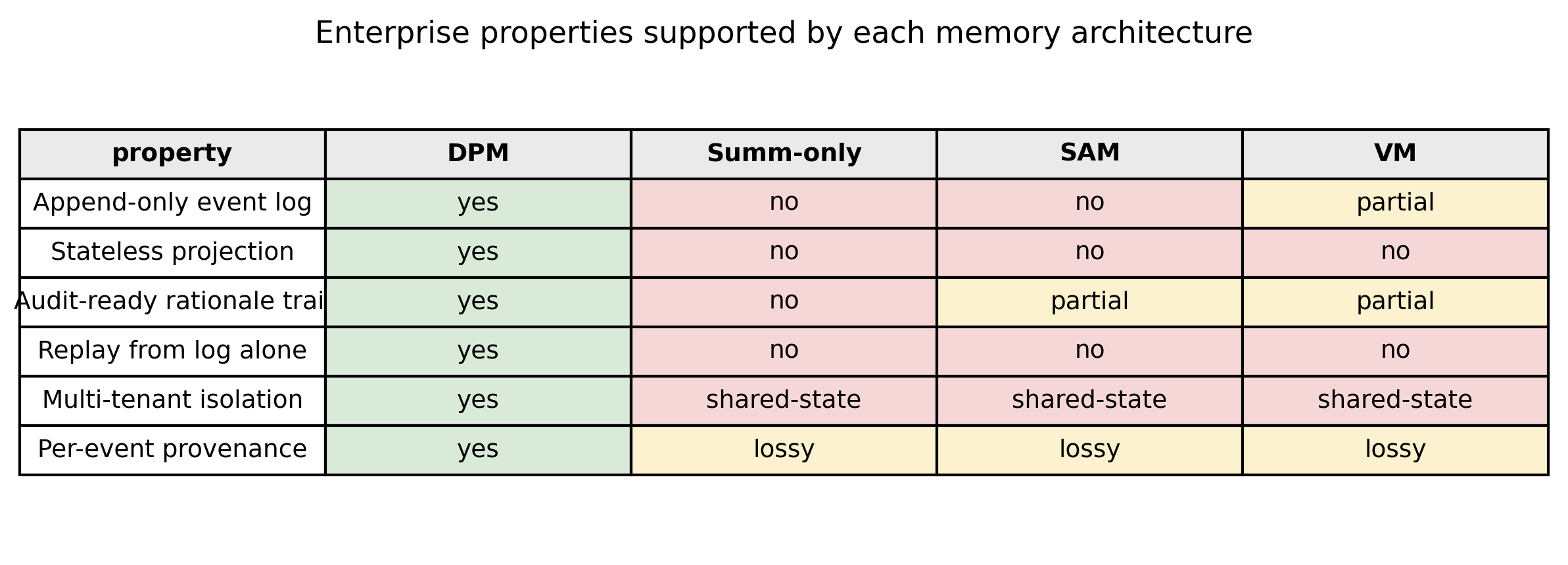
Figure 1: Enterprise properties supported by each memory architecture family. DPM satisfies all four by construction. Stateful architectures require retrofits that compound with architectural sophistication.
Deterministic Projection Memory: Design and Theoretical Properties
DPM encapsulates agent memory as an append-only, immutable event log. It defers all consolidation until decision time, at which point a single, task-conditioned projection is generated by an LLM via one temperature-zero call. The projection is structured into explicit sections: raw facts, reasoning chains, and compliance notes, with strict reference to event indices and verbatim preservation of numeric and identifier anchors. This functional, log-plus-pure-projection design is rooted in distributed systems' event sourcing and is already pervasive in high-assurance auditing domains.
By construction, DPM's statelessness ensures that the entirety of the memory required for replay, audit, or tenant isolation is encoded: (1) in the event log, and (2) as a deterministic, pure function of the log, the decision specification, and the model version. This yields a minimal audit and operations surface and enables deterministic replay modulo residual API nondeterminism, as formalized in their replay property proposition.
The architecture explicitly does not solve the general case for trajectories requiring context Windows exceeding those of current LLMs, nor does it aim to supplant corpus-level retrieval mechanisms. The design’s deliberate weakness in expressive power—eschewing deliberative edits or in-trajectory memory mutation—aligns directly with the regulated enterprise’s priorities and is not positioned as a limitation relative to retrieval or hierarchical memory systems.
Empirical Evaluation: Decision Quality, Cost, and Determinism
The empirical protocol evaluates DPM against incremental summarization-based stateful memory ("Summ-only") over two regulated decisioning domains, using LongHorizon-Bench, three budget settings, and four scoring axes: factual precision (FRP), reasoning coherence (RCS), decision accuracy (EDA), and compliance reconstruction (CRR).
The results are decisive: at moderate and loose budgets (ρ=2,5), DPM and Summ-only are statistically indistinguishable on all axes. At a tight budget (ρ=20), DPM exhibits substantial gains: FRP and RCS improve by +0.52 and +0.53 (Cohen's h above 1.1, p<0.005 for both). The interpretation is rooted in information-theoretic compounding: incremental summarization is lossy at each step, and losses accumulate with event count. DPM, as a non-compounding pure projection, avoids this degradation entirely.
The budget/architecture interaction is made explicit in (Figure 2), demonstrating that DPM's major empirical advantage is contingent on compression pressure; at loose budgets, both approaches saturate performance.
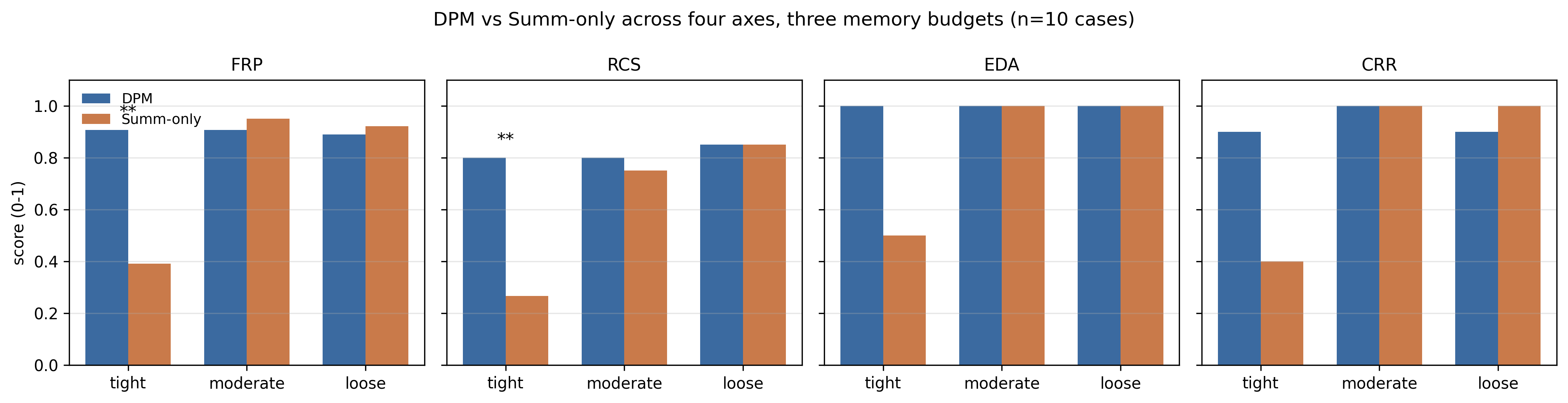
Figure 2: Decision-alignment axes by budget; significant improvement for DPM at tight budgets.
The cost analysis reveals operational implications: at tight and moderate regimes, DPM's per-decision wall-clock speed and compute cost are $7$–15× superior, since it elides per-event consolidation calls in favor of a single projection.
An auxiliary determinism study quantifies the byte-level drift under temperature-zero replay with current commercial APIs. Both approaches inherit residual stochasticity from the underlying LLM, but DPM reduces the architectural exposure from N calls (in a typical trajectory, N∼80–100) to a single call. Empirically, this is observed as unique full-surface hashes across replays—even as the prefix remains stable—and the architectural audit surface is shown to scale linearly for Summ-only but remains constant for DPM (Figure 3).
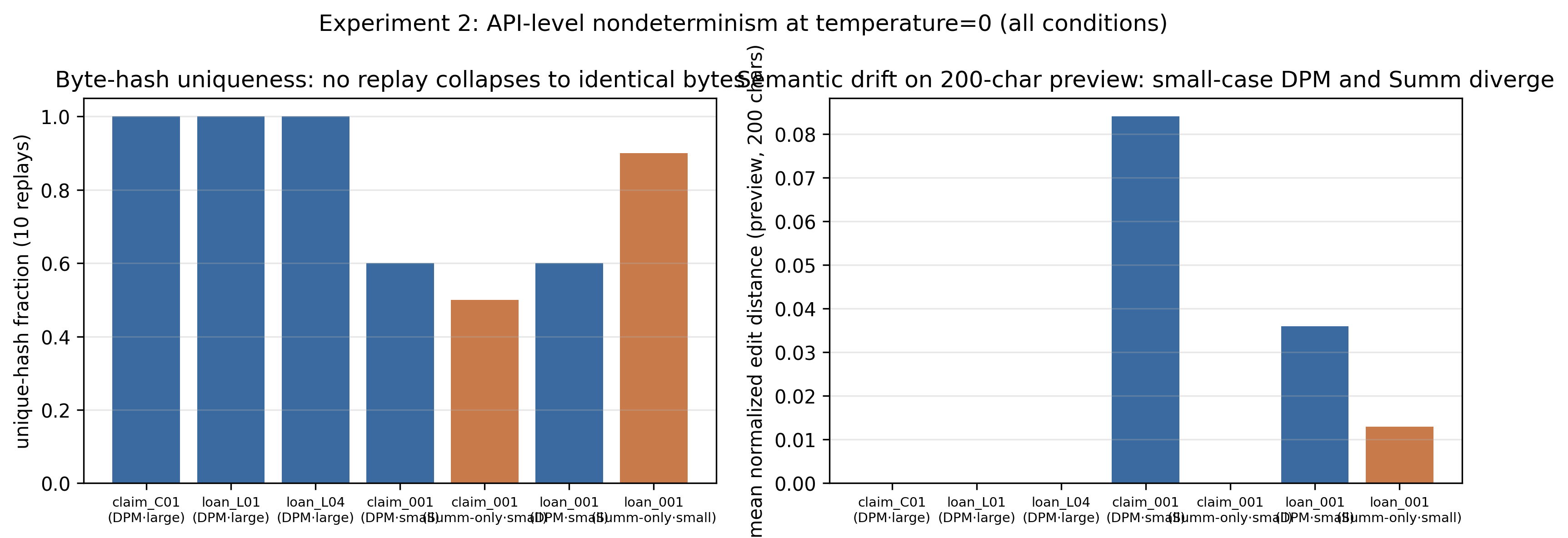
Figure 3: Byte-hash uniqueness and edit distance across replays; prefix stability is high but full-surface hashes are unique due to trailing nondeterminism.
Compression Scaling and Domain-Specific Heuristic
The compression-ratio scaling experiment confirms that DPM's decision-alignment advantage is strictly proportional to the regime where memory budget binds. At ratios below 10, differences are negligible; above that, DPM dominates on factual and reasoning metrics with effect sizes greater than one (Figure 4).
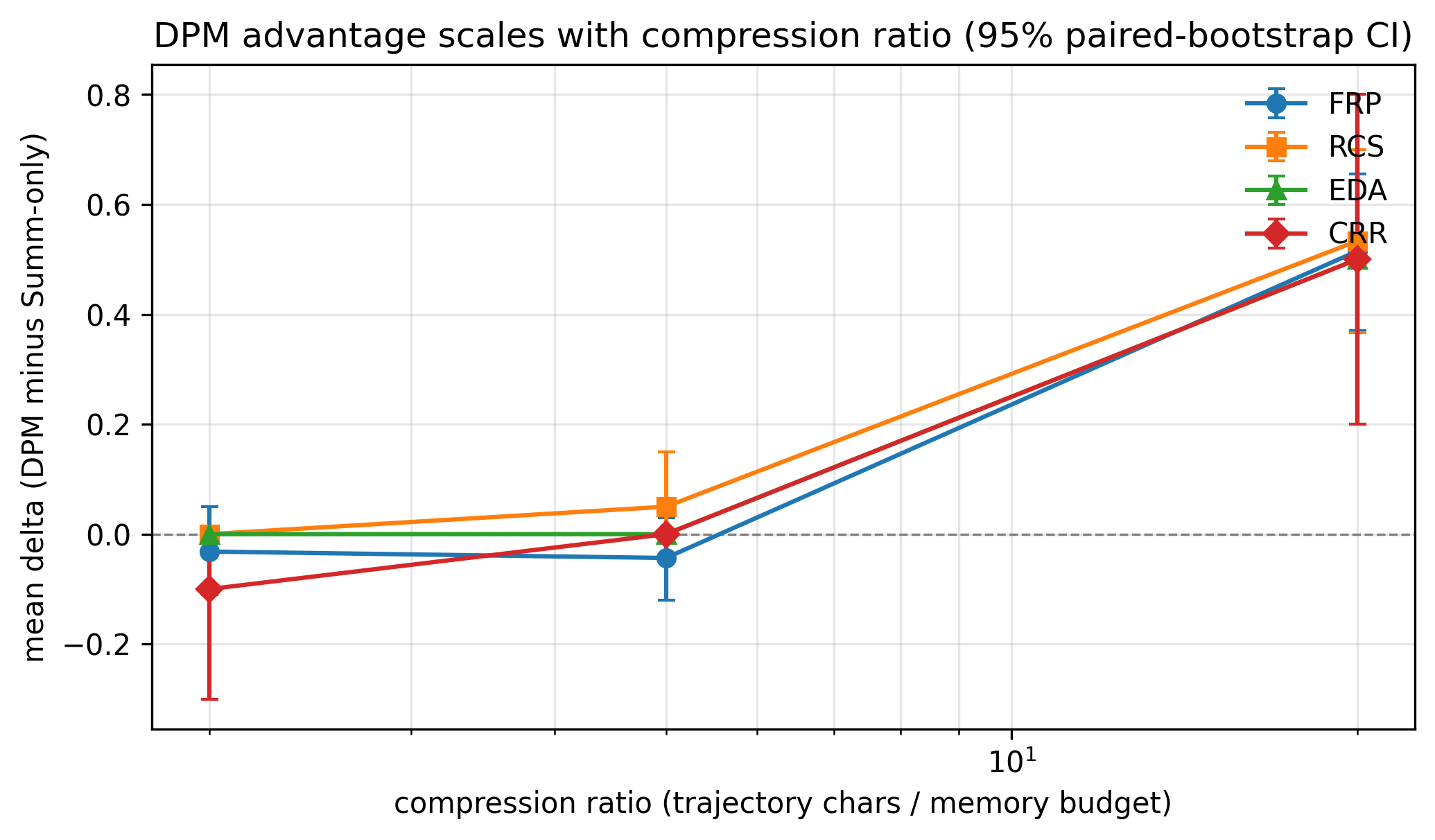
Figure 4: DPM minus Summ-only on decision-alignment axes as a function of compression ratio; DPM advantage grows at high compression.
The practitioner heuristic TAMS ("Task-Adaptive Memory Selection") is offered as a rule: DPM is strictly preferred where deterministic replay, auditability, or tight budgets are required. Otherwise, either approach suffices, and operational concerns dictate selection.
Theoretical and Practical Implications
The work’s implications are both architectural and operational. Theoretically, it establishes statelessness as a load-bearing constraint for agent memory in regulated environments—surface area, auditability, and replay are not merely implementation details but should drive architectural selection. DPM exemplifies a design that delivers exact alignment with these system constraints.
Practically, the findings indicate that organizations can eliminate substantial cost and complexity by adopting stateless, projection-based memory without sacrificing decision quality, provided their budget regime allows. These constraints, and the associated failure modes of sophisticated stateful systems (drift, replay complexity, leakage, audit burden), are cataloged in detail and instantiated with real operating costs.
Limitations and Future Directions
The DPM design is bounded by current LLM context window limitations, a focus on two regulatory domains, and evaluation with one model family. Scalability to multi-trajectory workflows and adversarial scenarios remains an open issue. The deterministic replay guarantee is strictly attainable only with a deterministic inference backend—DPM makes this practical but not automatic.
Future work should extend DPM with hierarchical projections for longer horizons, pair DPM with corpus-level retrieval or verification, conduct adversarial/robustness evaluations, and quantify long-term engineering cost savings in production-scale deployments.
Conclusion
The paper’s central contribution is to realign the agent-memory architecture debate around the dominant operational requirements of enterprise deployment: deterministic replay, auditability, multi-tenant isolation, and stateless scalability. DPM is shown to be the minimal architecture that satisfies these requirements, matching best-in-class stateful systems on decision quality except at high compression, where it excels. The implications are significant for practitioners and researchers building AI agents for regulated domains: prioritized statelessness is not only feasible, but strictly preferable under enterprise-compliance constraints, and can be achieved without incurring retrieval’s historical performance penalties.