Governed Memory: A Production Architecture for Multi-Agent Workflows
Abstract: Enterprise AI deploys dozens of autonomous agent nodes across workflows, each acting on the same entities with no shared memory and no common governance. We identify five structural challenges arising from this memory governance gap: memory silos across agent workflows; governance fragmentation across teams and tools; unstructured memories unusable by downstream systems; redundant context delivery in autonomous multi-step executions; and silent quality degradation without feedback loops. We present Governed Memory, a shared memory and governance layer addressing this gap through four mechanisms: a dual memory model combining open-set atomic facts with schema-enforced typed properties; tiered governance routing with progressive context delivery; reflection-bounded retrieval with entity-scoped isolation; and a closed-loop schema lifecycle with AI-assisted authoring and automated per-property refinement. We validate each mechanism through controlled experiments (N=250, five content types): 99.6% fact recall with complementary dual-modality coverage; 92% governance routing precision; 50% token reduction from progressive delivery; zero cross-entity leakage across 500 adversarial queries; 100% adversarial governance compliance; and output quality saturation at approximately seven governed memories per entity. On the LoCoMo benchmark, the architecture achieves 74.8% overall accuracy, confirming that governance and schema enforcement impose no retrieval quality penalty. The system is in production at Personize.ai.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Big Idea: What this paper is about
Think of a company that uses many helpful bots (called “agents”) to do different jobs—writing emails, answering support questions, updating records, doing research. All these bots talk about the same people and companies, but they don’t share a common memory or a common set of rules. This causes mix-ups, repeated work, and mistakes.
This paper introduces “Governed Memory,” a shared brain with built‑in rules. It lets all the bots remember the same facts, follow the same policies, and avoid stepping on each other’s toes.
What the authors wanted to fix
In simple terms, they aimed to solve five everyday problems:
- Each bot keeps its own notes, so useful info gets trapped in separate “silos.”
- Different teams use different rules and tones (brand, legal, support), so guidance is inconsistent.
- Memories are messy paragraphs, not neat fields, so they’re hard to search, sort, or use in tools like a CRM.
- Bots repeat the same rules at every step, wasting space and attention.
- There’s no feedback loop to catch when memories go stale or wrong until it’s too late.
How their solution works (with everyday analogies)
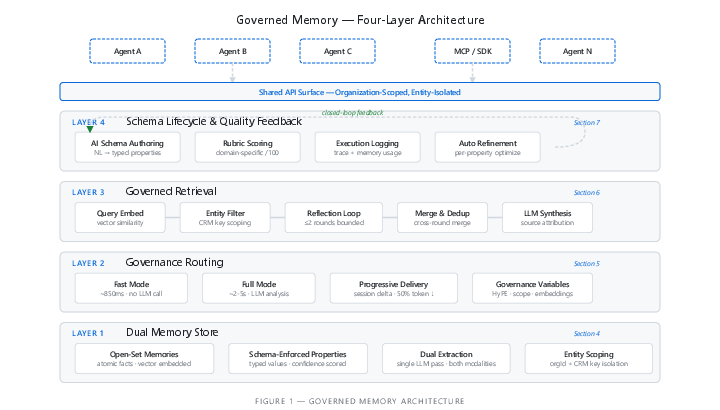
The system has four main parts. Imagine running a school project with many classmates and a shared notebook:
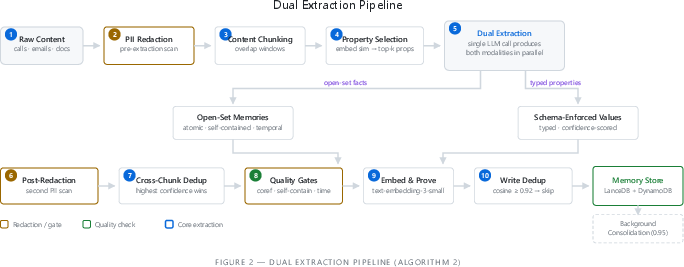
- Dual Memory (two kinds of notes)
- Open-set facts: Like sticky notes with short, clear facts (“The CTO is considering 3 vendors”) saved for easy searching by meaning.
- Schema-enforced properties: Like filling out a form with typed fields (date, number, yes/no) so tools can filter and sort (“Deal value: $450,000”).
- Why both? Free-text captures rich details; forms make data easy to use in other systems. Together, you don’t lose either.
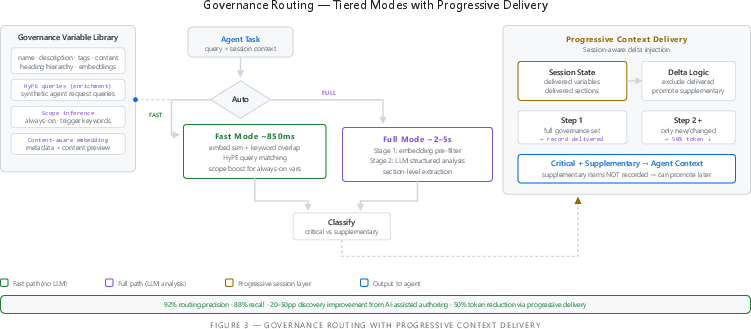
- Governance Routing (right rules at the right time)
- The system picks which rules and guidelines to include for a task (brand voice, legal policy, support tone).
- Fast mode: quick matching without using a big AI call.
- Full mode: smarter, slightly slower analysis with an AI.
- Progressive delivery: It remembers what rules a bot already saw in this session, and only adds new ones next step. This avoids repeating the same rules over and over.
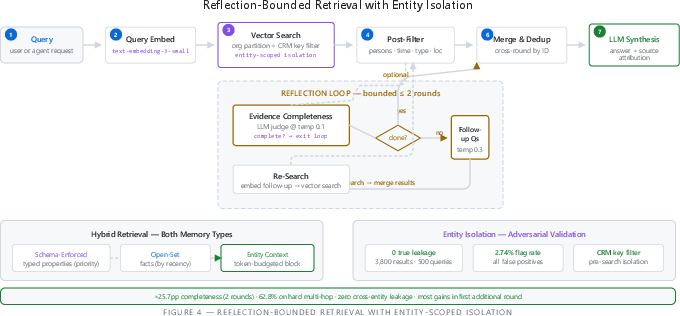
- Reflection-Bounded Retrieval (ask a couple of smart follow-up questions)
- If the first search doesn’t find enough evidence, the system asks 1–2 follow-up questions to fill gaps, but only for a small, fixed number of rounds to keep things fast.
- Entity isolation: Like checking ID cards—results are strictly limited to the right person/company so info doesn’t “leak” across different records.
- Schema Lifecycle and Feedback (keep the forms improving)
- An assistant helps you design and improve your “form” (schema) over time.
- The system scores how well extractions are working, logs what was used, and suggests targeted fixes per field when accuracy drops.
They tested these parts with controlled experiments (synthetic datasets with known answers), a public benchmark (LoCoMo), and real production use at Personize.ai.
What they found and why it matters
Here are the highlights, explained simply:
- Very high fact capture: About 99.6% of facts were correctly remembered in tests. This means the shared brain reliably stores what matters.
- Better rule delivery: The system picked the right rules for tasks about 92% of the time, and progressive delivery cut repeated context roughly in half. Bots focus more on the new task instead of rereading old rules.
- No mix-ups across people/companies: In adversarial tests, there was zero true “memory leakage.” That’s like never confusing two students with the same first name.
- Strong safety/compliance: In tricky, rule‑bending scenarios, the system stayed 100% compliant. This helps legal and brand teams sleep at night.
- Two-note system is genuinely better: Some info only fits as free text; other info only works well as structured fields. Using both caught more than either alone, and makes data usable by other tools (like CRMs and analytics).
- Smart follow-ups help, within limits: Asking a couple targeted follow-up queries found more of the needed info—especially when answers were scattered—without slowing things too much.
- Good external score: On a well-known long‑term memory test (LoCoMo), the system scored 74.8% overall, showing that adding governance and structure didn’t hurt retrieval accuracy.
- Practical tip: Quality improvements level off once you store about seven well‑governed memories per entity. That’s a useful “sweet spot” for teams.
Why this is useful in the real world
- Fewer “silo” headaches: All agents share the same, up-to-date memories, so a discovery in support helps sales, and vice versa.
- Consistent rules, everywhere: Brand voice, legal policies, and support tone are pulled from one source of truth and delivered just-in-time.
- Data your tools can use: Structured fields make it easy to filter, route, sync to a CRM, and run analytics—no manual parsing of messy paragraphs.
- Lower cost and better focus: Not repeating the same rules every step saves space and money and helps models pay attention to what’s new.
- Continuous quality: Built-in scoring and automatic schema fixes catch problems early, so quality doesn’t quietly decline.
In short, Governed Memory is like giving all your company’s AI helpers a shared, well-organized notebook and a consistent rulebook. It keeps facts clear, prevents mix-ups, delivers the right guidance at the right time, and improves itself over time—making AI in real workplaces more accurate, safer, and easier to manage.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research and engineering work:
- Real-world generalization beyond synthetic data: The core extraction and routing results rely heavily on synthetic datasets with embedded ground truth; systematic evaluations on diverse, noisy, real-world corpora across multiple organizations and domains are missing, along with public logs and error analyses.
- Statistical rigor and uncertainty reporting: The experiments lack confidence intervals, significance testing, power analyses, and variance reporting across runs/models; metrics (e.g., precision/recall thresholds for routing, “memory density” saturation) are not accompanied by uncertainty quantification.
- Benchmark ablations isolating contributions: LoCoMo scores are reported without ablations that isolate the effects of governance routing, schema enforcement, and reflection; it remains unclear which mechanisms drive observed gains (or deficits in multi-hop/temporal).
- Cross-organization external validity: No evidence that results hold across organizations with different content distributions, governance cultures, schema maturity, and tool stacks; portability and robustness of governance variables and schemas are untested.
- Multi-hop and temporal reasoning deficits: Multi-hop (51.7%) and temporal (64.6%) categories lag; concrete methods to close these gaps (e.g., better query decomposition strategies, temporal indexing, temporal reasoning prompts/models) are not developed or evaluated.
- Progressive context delivery impact on task quality: Token savings (≈50%) are shown, but there is no rigorous measurement of downstream task performance, error profiles, or user-centric metrics attributable to progressive delivery versus full re-injection.
- Session semantics and staleness: Progressive delivery assumes a 24-hour TTL and relevance persistence; staleness detection, automatic invalidation, and cross-session sharing (multi-agent hand-off) are not specified or evaluated.
- Governance routing drift and versioning: How policy changes propagate, how conflicting versions are resolved, and how to audit/evaluate routing drift over time are not specified; no formal mechanisms for policy precedence, rollback, or compatibility across versions.
- Governance router explainability: The router’s decisions (fast vs. full, critical vs. supplementary) are not accompanied by human-interpretable rationales or auditable traces suitable for compliance review.
- Concurrent write conflicts in multi-agent settings: The system does not handle concurrent writes from multiple agents on the same entity (acknowledged); no design or evaluation of conflict detection/resolution (e.g., CRDTs, OCC, causal ordering, transactionality).
- Consistency semantics and transactional guarantees: The architecture’s consistency model (eventual vs. strong), isolation levels, idempotency guarantees, and failure recovery semantics for reads/writes are unspecified.
- Dual-memory coherence: Mechanisms to ensure consistency between open-set facts and schema-enforced properties (e.g., when a property contradicts a fact or vice versa), cross-modality deduplication, and promotion of recurring open-set patterns into schema are not formalized.
- Quality gate calibration: Heuristic gates (coreference/self-containment/temporal anchoring) lack calibration against human judgments, domain adaptation strategies, and multilingual support; false-negative/false-positive trade-offs are unknown.
- Redaction robustness and privacy risks: Regex-based PII redaction may miss obfuscated or context-dependent PII; there is no evaluation of redaction recall/precision, no NER-backed or ML-augmented redaction in production, and no analysis of embedding leakage risks when using external vector stores.
- Security posture details and tests: Beyond tenant and entity scoping, there is no empirical validation of cross-tenant isolation, access control (RBAC/ABAC), encryption at rest/in transit, key management, or penetration testing results.
- Data subject rights and lifecycle: Practical workflows for GDPR/CCPA rights (access, rectification, erasure), global propagation of deletions across embeddings/backups/logs, and audit trails are not specified or evaluated.
- Poisoning and prompt-injection resilience: While adversarial governance is tested, there is no evaluation of data poisoning (maliciously injected memories), prompt-injection embedded in stored content, or memory corruption resilience.
- Source reliability modeling: The ranking pipeline lacks mechanisms to incorporate source credibility, provenance weighting, contradiction resolution by reliability, and per-source trust calibration beyond recency decay.
- Identity resolution and dedup across systems: The design assumes robust CRM keys; procedures for entity resolution (merging/splitting duplicates, cross-system identity mapping, conflicting identifiers), and its impact on isolation and recall are not addressed.
- Multilingual and cross-lingual support: The system’s behavior on non-English or code-switched content, cross-lingual embeddings, redaction in other languages, and schema/property localization remain untested.
- Retrieval stack breadth: The current system centers on vector search; hybrid retrieval (keyword lanes, BM25, learned sparse retrieval, reciprocal rank fusion) is proposed but not implemented or evaluated.
- Temporal indexing and expiration policies: Beyond exponential recency decay, there is no per-property TTL, freshness guarantees, or policies for automatic expiry/archival of stale or low-confidence memories.
- Model dependence and portability: Results depend on unspecified LLMs/embeddings; robustness across providers/models, calibration portability for confidence scores, and graceful degradation on smaller/cheaper models are not studied.
- Cost modeling at scale: Aside from token reduction, there is no end-to-end cost/performance analysis (LLM calls, embeddings, storage, routing overhead), nor guidance for operating points under varying budgets and latency constraints.
- Impact of heuristic thresholds: Fixed cosine thresholds (0.92/0.95) for deduplication and similarity-based selection are empirically set; there is no adaptive strategy tuned to content type, domain, or noise level, nor sensitivity analyses.
- Memory density “saturation” generality: The claim that quality saturates around seven governed memories per entity is not generalized across tasks/domains, nor analyzed for causal drivers; an algorithm for choosing memory budgets is absent.
- Open-set long-tail coverage vs. schema actionability: While modality complementarity is shown, there is no systematic pipeline for converting high-value open-set facts into robust, high-precision schema properties with monitored regression tests.
- Evaluation bias in self-judgment: Although mitigations are noted (rubric-first prompting, cross-model scoring), there is no quantitative estimate of residual bias, inter-rater agreement with human adjudication, or calibration protocols.
- Downstream system integration and conflict resolution: Detailed strategies for synchronizing schema-enforced properties with CRMs/ERPs (authoritative source selection, bidirectional sync conflicts, partial failures) are not specified.
- Latency under load and SLOs: Reported routing latencies are per-call averages; there is no load testing, tail-latency analysis, or end-to-end SLOs (p95/p99) for high-concurrency, multi-agent workloads.
- Observability overhead and privacy of traces: Execution logging’s storage/throughput overhead, retention policies, privacy controls on traces, and methods to redact sensitive content in logs are not detailed.
- Modalities beyond text: Handling of images, audio (beyond transcripts), and structured files (spreadsheets, PDFs with complex layouts) is not described or evaluated.
- Fairness and policy bias auditing: The effect of organizational schemas/governance on fairness (e.g., biased outreach or support decisions), and auditing/mitigation procedures, are not addressed.
- Automated schema expansion: While refinement is described, the system lacks a validated method for proposing new properties from repeated open-set patterns, with human-in-the-loop review and guardrails against schema sprawl.
- Query strategy learning for reflection: The gap between manual multi-hop and API-managed reflection indicates missing learning/adaptation of query decomposition strategies; no method to learn from past queries or user feedback is provided.
- Explainable ranking for conflicts: Conflict handling currently relies on recency decay; there is no interpretable justification combining recency, source reliability, and confidence, nor UI/APIs to surface conflict rationale for review.
- Robustness to non-stationary environments: Adaptive mechanisms for sudden content shifts (e.g., new product lines, policy overhauls), automatic threshold tuning, and rapid schema migrations with rollback are not designed or tested.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now using the paper’s mechanisms (dual memory, governance routing with progressive delivery, reflection-bounded retrieval, and closed-loop schema lifecycle). Each item includes sectors, potential tools/products/workflows, and feasibility assumptions/dependencies.
- Unified customer memory across distributed GTM workflows
- Sectors: Software/SaaS, B2B sales, Marketing, Support
- What: Centralize entity-scoped memories so sales, marketing, support, and success agents operate on the same, governed customer profile (e.g., deal size as a typed property + qualitative insights from calls).
- Tools/Workflows: MCP/SDK integration with Salesforce/HubSpot; “Entity Context Injection” endpoint; CRM sync job mapping schema-enforced properties to CRM fields.
- Assumptions/Dependencies: Clean CRM keys/IDs; initial schema definition; org buy‑in to a single memory layer.
- Brand, legal, and compliance propagation across agents
- Sectors: Finance, Healthcare, Legal, Regulated industries
- What: Tiered governance routing injects relevant policies (brand voice, tone, KYC/AML, HIPAA) to every agent flow; session-aware progressive delivery reduces token bloat by ~50% while maintaining compliance.
- Tools/Workflows: Governance Variable Library; Fast/Full router modes; session “delta injector.”
- Assumptions/Dependencies: Well-authored governance variables (authoring quality raises discovery by 20–50pp); policies must be versioned and tagged.
- Safer multi-tenant SaaS assistants with hard entity isolation
- Sectors: SaaS platforms, Cloud providers
- What: CRM-key prefiltering ensures zero cross-entity leakage in retrieval under adversarial conditions; supports multi-tenant AI features safely.
- Tools/Workflows: Entity-scoped vector search; tenant partitions; audit logs.
- Assumptions/Dependencies: Robust identity resolution; strict partition enforcement; privacy reviews.
- Cost- and accuracy-optimized autonomous agents
- Sectors: Software engineering, Ops automation, RPA
- What: Progressive context delivery avoids reinjecting unchanged governance/context each loop, saving tokens and improving attention to new instructions.
- Tools/Workflows: Session state store for delivered context; router in “Auto” mode; prompt budgets.
- Assumptions/Dependencies: Agents that invoke router at each step; long-context models.
- Structured data extraction for downstream systems (beyond prompt augmentation)
- Sectors: Analytics, RevOps, Support Ops, BI
- What: Dual extraction captures typed properties for direct use in rules, filters, and dashboards, plus open-set insights for recall and summarization.
- Tools/Workflows: Schema authoring UI; per-property confidence; type validation; ETL connectors to BI/warehouse.
- Assumptions/Dependencies: Initial schema and iteration loop; mapping to downstream tables and metrics.
- Closed-loop quality monitoring and schema refinement
- Sectors: Any org operating agent systems at scale
- What: Rubric-based self-evaluation with execution traces detects drift and per-property accuracy; automated per-property optimization improves extraction over time.
- Tools/Workflows: Quality Gates Dashboard (coreference/self-containment/temporal); rubric presets; change logs; per-property refinement pipeline.
- Assumptions/Dependencies: Teams can define rubrics and tolerate LLM-as-judge mitigations; instrumentation in place.
- Governed email/personalization generation
- Sectors: Sales, Marketing
- What: Email/pitch generation with shared memory and governance shows +6–7 points improvement on sales rubrics; governance adds refinement on tone and policy adherence.
- Tools/Workflows: “Entity Context Injection” + Governance Router pre-step; templates with typed property placeholders.
- Assumptions/Dependencies: Adequate memory density (~7 governed memories per entity saturates gains); template discipline.
- Support copilots with compliant recall and auditability
- Sectors: Customer support, CX
- What: Reflection-bounded retrieval and entity isolation provide accurate, current customer context; governance prevents unsafe responses; full trace and memory usage logs support audits.
- Tools/Workflows: Low-temperature completeness checks; recency-decayed ranking; governance guardrails.
- Assumptions/Dependencies: Redaction pipeline meets policy; recency decay tuned to domain.
- Knowledge management with queryable and retrievable memory
- Sectors: Enterprise KM, Product, Research
- What: Store free-text facts for discovery alongside typed knowledge for querying (e.g., “all accounts in active evaluation stage with >$100K potential”).
- Tools/Workflows: Property-based filters; embedding search; hybrid “Properties + Observations” context blocks.
- Assumptions/Dependencies: Schema coverage of key operational concepts; property confidence thresholds.
- Evaluation-as-monitoring templates for RAG/agent teams
- Sectors: Software/AI platform teams, Academia
- What: Adopt proposed metrics (routing precision/recall, schema discovery, context defect rate, memory density curves) and provided datasets to continuously monitor production health.
- Tools/Workflows: CI pipelines that replay extraction and scoring; incident alerts on metric drift.
- Assumptions/Dependencies: Teams commit to running small, frequent tests with fixed seeds; dataset maintenance.
- Framework-agnostic agent integration
- Sectors: Software/Dev Tools
- What: Standard MCP interface and SDK let any agent framework read/write governed memory without bespoke integration.
- Tools/Workflows: SDK adapters; API quotas; versioned schemas and governance libraries.
- Assumptions/Dependencies: Adoption by platform owners; stable API SLAs.
- Privacy-first personalization for individuals and SMBs
- Sectors: Productivity apps, Personal assistants
- What: Store preferences (typed) and contextual notes (open-set) with session-aware injection; strict entity isolation and redaction reduce privacy risks.
- Tools/Workflows: Local/tenant-scoped memory store; PII redaction pre/post extraction; opt-in controls.
- Assumptions/Dependencies: Regex redaction limits; consent UX; smaller teams may need hosted offerings.
Long-Term Applications
These opportunities require additional research, scaling, domain adaptation, or regulatory work. Each item notes expected dependencies and blockers.
- Healthcare clinical agents with governed longitudinal memory
- Sectors: Healthcare
- What: Use schema-enforced properties for vitals, meds, diagnoses; open-set notes for qualitative observations; governance routes HIPAA and clinical protocols.
- Dependencies: ML-augmented redaction (beyond regex); EHR integration; clinical schema standards; regulatory validation.
- Financial advisory and operations with policy-first memory
- Sectors: Finance, FinTech, Insurance
- What: Governed KYC/AML policies injected into workflows; typed risk scores and suitability captured; audit trails for decisions.
- Dependencies: Regulator-approved controls; high-accuracy extraction on financial docs; model governance and change control.
- Robotics and industrial operations memory
- Sectors: Manufacturing, Robotics, Field service
- What: Multi-agent robots share governed world-state and SOPs; typed properties for configuration/maintenance; governance for safety.
- Dependencies: Multimodal extension (vision/sensor), concurrent write conflict resolution, real-time constraints.
- Energy and utilities maintenance copilots
- Sectors: Energy, Utilities
- What: Governed safety policies + equipment properties; reflection to gather multi-hop maintenance history; isolation across sites/tenants.
- Dependencies: Domain schemas (assets, work orders); offline/edge deployments; incident response integration.
- Supply chain planning with conflict-aware, governed memory
- Sectors: Logistics, Retail, Manufacturing
- What: Entity-scoped supplier/shipments data; temporal conflict resolution (fresh vs. stale info); rule-driven routing (e.g., cold-chain exceptions).
- Dependencies: Data harmonization across ERPs; adaptive conflict/consistency models; SLA-aware governance.
- Education “student digital twin” with FERPA-aware governance
- Sectors: Education, EdTech
- What: Typed academic progress and preferences; open-set tutor notes; governance routes curriculum standards and privacy constraints.
- Dependencies: Consent frameworks; bias and fairness audits; institution-wide schema alignment.
- Government and public sector knowledge governance
- Sectors: Public administration, Defense, Justice
- What: Cross-agency policy routing; schema-enforced properties for cases, permits, assets; entity isolation per citizen/case; full auditability.
- Dependencies: Data classification (CUI/FOUO), procurement and ATO, inter-agency interoperability.
- Concurrent-write conflict resolution for multi-agent memory
- Sectors: Any org with many agents
- What: Move from sequential temporal conflict handling to robust concurrent update models (e.g., CRDTs, merge policies, human-in-the-loop).
- Dependencies: Transaction models, provenance weighting, UI for conflict adjudication.
- Automated schema discovery and expansion
- Sectors: Enterprise KM, Data engineering
- What: Propose new properties from recurring patterns in open-set memory; rank by utility; semi-automatic promotion to schema.
- Dependencies: Reliability of pattern mining; operator review; versioning impact on downstream consumers.
- Advanced retrieval orchestration (query-adaptive reflection and hybrid lanes)
- Sectors: RAG/IR systems, Search
- What: Query-adaptive round bounds; hybrid semantic/keyword/RRF lanes to improve multi-hop and temporal performance.
- Dependencies: IR research integration; latency budgets; per-domain tuning.
- Cross-organization governance and schema marketplaces
- Sectors: Platform ecosystems
- What: Share vetted governance packs (e.g., SOC2, HIPAA, brand kits) and domain schemas; organizations subscribe and customize.
- Dependencies: Standard formats/APIs; licensing/compliance validation; update propagation.
- Federated or privacy-preserving governed memory
- Sectors: Healthcare, Finance, Government
- What: Federated retrieval with tenant isolation and governance enforcement; insights without moving raw data.
- Dependencies: Federated embeddings/search, differential privacy, secure enclaves.
- Multimodal governed memory and redaction
- Sectors: Media, Robotics, Healthcare
- What: Extend quality gates/redaction to images/audio/video; typed properties from multimodal sources; policy-aware injections.
- Dependencies: Transformer-based NER/PII for multimodal, storage and compute scaling, new evaluation rubrics.
- Standards and policy frameworks for governed memory
- Sectors: Policy, Standards bodies
- What: Define formats for governance variables, schema lifecycle, audit traces; certify compliance for agent platforms.
- Dependencies: Industry consortia participation; regulator engagement; reference implementations.
Notes on feasibility across applications:
- Quality depends on LLM and embedding performance, prompt engineering, and memory density; the paper’s synthetic datasets show upper bounds that may be modestly lower in noisy production environments.
- Governance routing efficacy relies on high-quality, well-tagged governance artifacts; poor authoring sharply reduces discovery.
- Current PII redaction is regex-based; sensitive sectors should adopt ML-augmented redaction before production.
- Real-time or safety-critical deployments require additional verification, latency control, and fail-safe designs.
- Scaling requires cost controls (via progressive delivery, deduplication) and operational monitoring (proposed metrics and dashboards).
Glossary
- adversarial governance compliance: The ability of a system to enforce organizational policies even under intentionally hostile or trick inputs designed to bypass rules. "100\% adversarial governance compliance"
- adversarial queries: Inputs crafted to provoke failures such as data leakage or cross-entity contamination in retrieval systems. "zero cross-entity leakage across 500 adversarial queries"
- AI-assisted authoring: Using AI tools to help design or refine schemas, guidelines, or other governance artifacts. "AI-assisted authoring"
- always-on variables: Governance items that should be applied to all tasks by default, regardless of query specifics. "whether the variable is always-on"
- Auto mode: A router setting that automatically chooses between fast and full governance routing based on library characteristics. "Auto mode (default)."
- closed-loop schema lifecycle: A governance process that continuously evaluates and refines schemas based on observed performance and feedback. "a closed-loop schema lifecycle"
- content-aware embedding: Vector representations derived from both metadata and content previews to improve retrieval and routing. "content-aware embedding computed from metadata and content preview"
- content chunking with overlap: Splitting documents into overlapping segments to improve extraction and retrieval robustness. "content chunking with overlap"
- coreference resolution: Identifying when different expressions refer to the same entity to make extracted facts self-contained. "coreference resolution"
- cosine similarity threshold: A cutoff value for cosine similarity used to detect and skip near-duplicate embeddings. "cosine similarity threshold (default: 0.92)"
- CRM-key-based entity scoping: Restricting memory operations to a specific entity using unique CRM identifiers to prevent cross-entity contamination. "CRM-key-based entity scoping"
- cross-entity leakage: Improper retrieval or use of information from entities other than the one targeted by a query. "zero cross-entity leakage across 500 adversarial queries"
- document-expansion-by-query-prediction: A retrieval technique that augments documents with predicted queries at index time to improve matching. "adapting the document-expansion-by-query-prediction approach"
- dual extraction pipeline: A process that extracts both open-set facts and schema-enforced typed properties in a single pass. "dual extraction pipeline"
- dual memory model: An architecture combining open-set (unstructured facts) and schema-enforced (typed properties) memories in a unified store. "dual memory model"
- embedding pre-filter: An initial narrowing step that uses embedding similarity to reduce candidate sets before heavier analysis. "embedding pre-filter reducing candidates"
- embedding similarity: Measuring closeness between vectors to rank or select relevant items for extraction or routing. "using embedding similarity between content and property metadata"
- entity context injection: An API endpoint that compiles and injects per-entity properties and observations into prompts within a token budget. "entity context injection endpoint"
- entity-scoped isolation: A hard boundary ensuring retrieval and memory operations are limited to the targeted entity. "entity-scoped isolation"
- exponential recency decay: A ranking technique that downweights older facts exponentially to prioritize more recent information. "exponential recency decay (half-life = 38 days)"
- governance routing: Selecting and injecting the appropriate organizational policies and guidelines into an agent’s context for a task. "governance routing"
- governance scope inference: Using an LLM to determine when a governance variable should always apply and to infer trigger keywords. "governance scope inference"
- guardrail activation rate: The frequency with which predefined safety or policy mechanisms trigger during adversarial tests. "guardrail activation rate"
- half-life: The time period over which a score (e.g., recency weight) decays by half in ranking functions. "half-life = 38 days"
- HyDE: A method that generates hypothetical documents for a given query to improve retrieval; referenced as a naming inspiration. "naming inspired by HyDE"
- HyPE (Hypothetical Prompt Enrichment): Generating synthetic queries for governance variables to improve discoverability and routing. "Hypothetical Prompt Enrichment (HyPE)"
- LLM-as-judge: Using LLMs to evaluate outputs rather than relying solely on reference answers or token overlap. "LLM-as-judge"
- LoCoMo benchmark: A benchmark for evaluating long-term conversational memory systems across multiple categories. "LoCoMo benchmark"
- memory primitives: Low-level capabilities for storing and retrieving atomic facts that underlie higher-level governance features. "memory primitives"
- multi-tenant isolation: Architectural separation ensuring different organizations’ data and policies remain strictly segregated. "multi-tenant isolation"
- open-set memories: Atomic, self-contained facts extracted from unstructured inputs and stored as embeddings. "Open-set memories are atomic, self-contained facts"
- per-property schema refinement: Automated updating of individual schema properties based on evaluation feedback to improve extraction. "per-property schema refinement"
- PII redaction: Removing personally identifiable information before and/or after LLM processing to protect privacy. "pre-extraction PII redaction"
- progressive context delivery: Session-aware injection of only new or changed governance/context items across an agent’s multi-step execution. "progressive context delivery"
- provenance metadata: Stored details about origin, model, chunk position, and other attributes that describe how a memory was created. "provenance metadata"
- reciprocal rank fusion: A method for combining ranked lists from different retrieval lanes to improve overall ranking. "reciprocal rank fusion"
- reference-free evaluation: Assessing output quality without relying on gold references, often via rubric-driven judgments. "reference-free evaluation"
- reflection-bounded retrieval: A retrieval process that iteratively checks completeness and issues follow-up queries within a fixed number of rounds. "reflection-bounded retrieval with entity-scoped isolation"
- reflection loop: The iterative cycle in which an LLM evaluates evidence completeness and proposes targeted follow-up queries. "reflection loop"
- Retrieval-Augmented Generation (RAG): A paradigm where generation is grounded in retrieved evidence from external knowledge stores. "RAG is a retrieval primitive"
- rubric scoring: Evaluating outputs against weighted, domain-specific criteria to produce normalized quality scores. "criteria-based rubric scoring"
- schema-enforced memories: Typed property values extracted under a defined schema with validation and confidence scores. "Schema-enforced memories are typed property values"
- schema lifecycle management: Processes and tooling that support authoring, evaluation, logging, and iterative improvement of schemas. "Schema lifecycle management"
- section-level extraction: Selecting and injecting only specific sections of governance variables deemed relevant to a task. "section-level extraction capability"
- session-aware delta delivery: Tracking what guidance has already been injected in a session to deliver only new or newly relevant context. "session-aware delta delivery"
- token-budgeted context block: A compiled context for an entity that is sized to fit within a predefined token limit. "token-budgeted context block"
- two-stage pipeline: A routing mode that first filters candidates by embeddings and then applies structured LLM analysis. "Two-stage pipeline"
- vector similarity search: Retrieving relevant memories by comparing query and memory embeddings within a vector space. "Vector similarity search"
- write-side deduplication: Skipping insertion of near-duplicate items at write time based on similarity thresholds. "write-side deduplication"
- quality gates: Heuristic checks (e.g., coreference, self-containment, temporal anchoring) applied to extractions to filter low-quality entries. "quality gates"
- temporal anchoring: Explicitly associating facts with time references so their validity can be compared over time. "temporal anchoring"
Collections
Sign up for free to add this paper to one or more collections.

