- The paper presents an in-model routing mechanism, RouteLMT, that predicts the marginal gain of using a large model to improve translation quality within a fixed budget.
- It leverages the small model’s final token hidden state and integrates a LoRA-adapted routing head to efficiently allocate costly large-model calls.
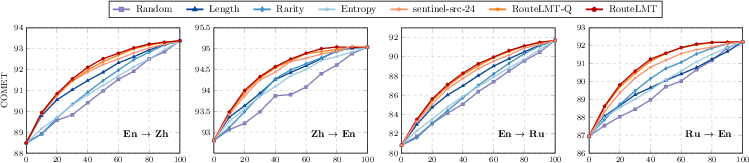
- Experimental results show that RouteLMT achieves a superior quality-cost trade-off across multiple language pairs and domains, outperforming heuristic-based methods.
Learned Routing for Cost-Efficient Hybrid LLM Translation: An Analysis of RouteLMT
LLMs substantially advance the quality of machine translation (MT), but the computational cost associated with large-scale deployment remains a primary challenge. Hybrid systems, where a lightweight translator handles most requests and a large model is invoked selectively, are a practical response. However, a central operational question emerges: under a fixed large-model budget, which instances should be routed to the expensive model to maximize overall translation quality?
Previous routing strategies use heuristics, absolute quality estimation, or external predictors, which are limited due to misaligned objectives, additional serving complexity, and increased inference latency. These approaches often fail to capture whether the large model yields a significant improvement beyond what the small model provides on individual instances.
The paper introduces a budgeted routing framework that identifies the marginal gain—the difference in translation quality between large and small models on a given instance—as the optimal signal for hybrid routing decisions. Routing is thus framed as maximizing marginal gain under a call budget constraint, prioritizing inputs where large-model invocation results in the highest incremental benefit.
The RouteLMT Approach
RouteLMT is an in-model routing mechanism that predicts the expected marginal gain of using the large model versus the small model for a given input. This prediction is derived directly from the internal representation of the small translator, specifically the hidden state of the final token of the translation prompt.
Key characteristics of RouteLMT include:
- Hypothesis-Free: No hypothesis decoding from the small model is needed for routing decisions, minimizing latency and compute overhead.
- In-Model Routing: The routing prediction head is integrated into the small translator and is parameter-efficiently trained with LoRA adaptation.
- Direction-Aware: Exploits the prompt-embedded translation direction, enabling a single routing model to operate across multiple language pairs.
- Training Objective: RouteLMT is trained by regressing the actual empirical gain, as measured by a reference-based metric, across pairs of small/large model outputs.
At inference time, RouteLMT ranks incoming requests by predicted marginal gain and allocates the limited large-model budget to the top predictions, either in batch or via a calibrated threshold for streaming scenarios.
Experimental Results and Numerical Highlights
RouteLMT is evaluated against heuristic (length, rarity, entropy) and learned (external and in-model, gain- and quality-based) baselines across four translation directions, multiple domains, and several routing budgets.
The principal findings include:
Risk and Regression Analysis
Proper routing must minimize catastrophic failures, not just maximize average gain. The paper provides a granular analysis of the impact distribution when examples are routed to the large model:
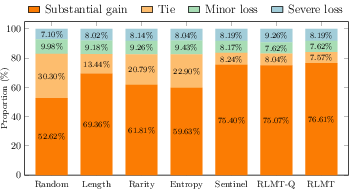
Figure 2: Gain-bucket distribution for routed-to-large requests at p=0.3, showing reduced ties and increased substantial gains under learned routing; severe losses occur at similar rates across practical policies.
RouteLMT reduces wasteful large-model calls on 'tie' cases (low gain) and reallocates budget towards instances with major quality improvements. However, the rate of severe quality regressions (e.g., incorrect entity expansions, semantic drift) remains comparable across all practical routing methods, suggesting that these failures are not predictable by standard input difficulty or even the small model's representation. The authors propose a simple guarded routing variant, adding a post-routing quality check to further reduce regression risks, at the cost of extra decoding overhead.
Theoretical and Practical Implications
By formulating routing as budgeted marginal gain maximization and demonstrating that in-model, hypothesis-free gain prediction is both effective and lightweight, this work realigns hybrid deployment objectives with measurable operational metrics. It challenges the convention of using surface heuristics or general difficulty/quality estimation as routing proxies, instead targeting improvement potential directly.
Practical implications include:
- Reduced serving complexity: No external model or pipeline is needed for routing.
- Minimal latency and compute overhead: A single forward pass through the small translator suffices for routing prediction, with no hypothesis generation required.
- Generalizability: The approach is robust across languages, domains, and model families, as internal prompt representations encode information transferably for routing.
- Risk management: Simple post-routing guards, optionally coupled with in-model prediction, allow practitioners to trade off average gain for reduced risk of severe degradation.
Future Directions
Several avenues remain for exploration:
- Extension to multi-tier and latency-aware routing: The presented framework focuses on binary small/large routing; cascading over multiple model tiers or incorporating variable latency constraints may yield further efficiency.
- Alternative gain estimation signals: While reference-based metrics underpin the current loss, human-in-the-loop or application-specific signals could enhance alignment and practical utility.
- Handling catastrophic regressions: More advanced detection and mitigation of rare but severe regressions are needed, potentially involving richer contextual features or fallback schemes.
- Integration with proactive uncertainty estimation: Combining gain prediction with token-level or sequence-level uncertainty may further refine routing and deferral policies, as considered in LLM cascade research such as "LLM Cascades: Token-Level Uncertainty And Beyond" (Ong et al., 2024).
Conclusion
RouteLMT demonstrates that routing decisions grounded in predicted marginal gain—computed efficiently from the small model's prompt representations—significantly improve the cost-quality trade-off in hybrid LLM translation systems. The approach outperforms heuristic and quality/difficulty-based learned routers on both in-domain and domain-shifted data, and it offers a scalable, practical solution for budget-constrained deployment. The separation between potential gain and simple input difficulty highlighted by this work is likely to generalize to other LLM hybridization scenarios, supporting broader adoption of learned, in-model, improvement-maximizing routing strategies.