- The paper introduces ShredBench, a novel benchmark for assessing semantic reasoning in multimodal LLMs through shredded document reconstruction.
- The paper details an automated pipeline that synthesizes realistic document fragmentation using 3D rendering, Voronoi tessellation, and simulated deformations.
- The paper reveals that current MLLMs exhibit drastic performance degradation with increased fragmentation, highlighting significant gaps in visual and textual integration.
ShredBench: A Benchmark for Semantic Reasoning in Multimodal LLMs via Shredded Document Reconstruction
Introduction
"ShredBench: Evaluating the Semantic Reasoning Capabilities of Multimodal LLMs in Document Reconstruction" (2604.23813) introduces a rigorous benchmark for probing the semantic and cross-modal reasoning robustness of state-of-the-art Multimodal LLMs (MLLMs) in scenarios where documents are not merely noisy or blurred but physically fragmented ("shredded"). ShredBench delivers a scalable, automated pipeline for generating such benchmarks and provides detailed empirical analysis across multiple data modalities (text, code, and tables), languages, and fragmentation levels. The evaluation exposes severe deficiencies in current leading MLLMs’ ability to integrate visual and semantic cues under significant structural disruption, establishing a critical empirical baseline for future research in VRDU robustness.
The ShredBench Benchmark Design
Data Acquisition and Fragmentation Pipeline
ShredBench encompasses diverse content domains: English/Chinese news, source code (Python, C++, Java), and scientific tables. Content is synthetically "shredded" via a physically realistic 3D rendering pipeline, involving:
- High-resolution document rendering: Source text is rendered with randomized noise and fonts for realism.
- Voronoi-based tessellation: Documents are partitioned into 8, 12, or 16 irregular fragments, simulating the artifact of manual shredding.
- 3D deformation and simulation: Fragments are subjected to crumpling, lighting, and rotation via Blender, further suppressing low-level visual shortcuts.
- Task formulation: Models are tasked with reconstructing the original text sequence from the unordered, possibly rotated and occluded fragments.
The generation process is fully automated and supports integration of never-before-seen documents, enabling clean train/test splits with no data contamination.
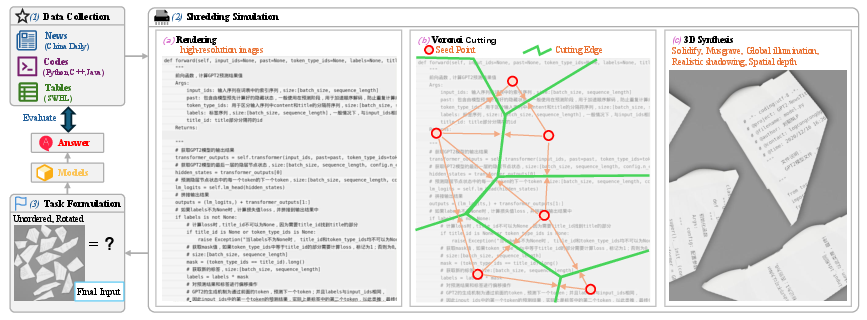
Figure 1: ShredBench’s pipeline synthesizes shredded document images from diverse content and simulates realistic physical artifacts.
The resulting dataset comprises 756 documents across four scenarios (English, Chinese, code, tables) and three fragmentation granularities, with rigorous quality control ensuring solvability by humans (Cohen's κ=0.79).
Dataset Properties
Input length distributions are balanced across domains, yielding a challenging range of real-world-like document complexities.
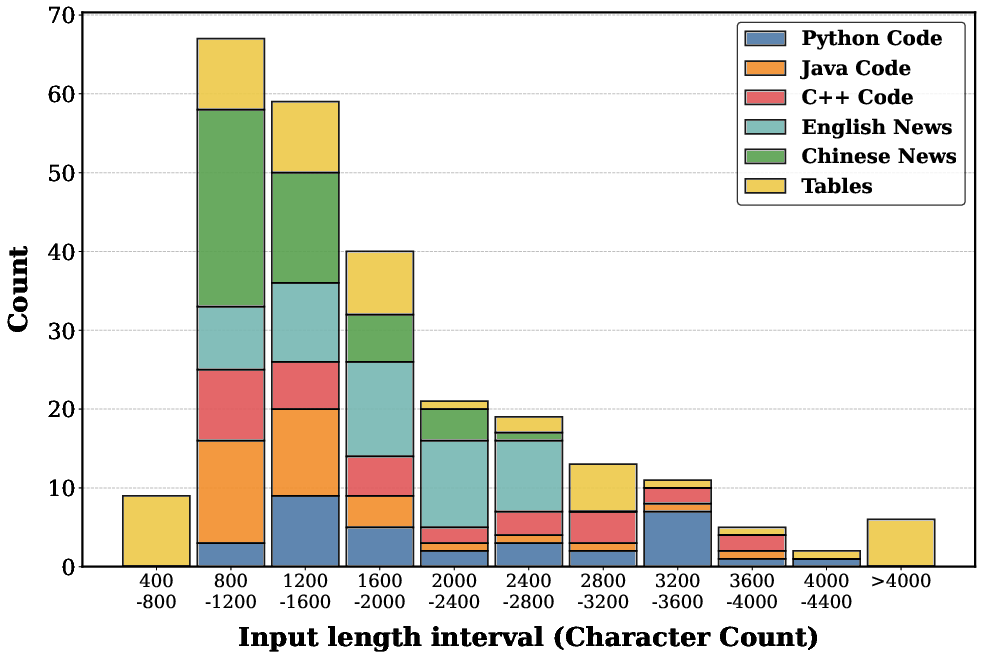
Figure 2: ShredBench dataset input lengths, indicating broad coverage across document categories.
Evaluation Metrics and Protocols
The task is formally a set-to-sequence mapping: unordered fragmented images I={f1,…,fN}→ target sequence T^. Evaluation employs:
- Normalized Edit Distance (NED): Token-level edit distance, lower is better.
- TEDS: Structure- and content-aware, mainly for tables.
- BLEU / ROUGE-L: Standard summarization metrics aligning with n-gram and sequence overlap.
- CodeBLEU: AST- and data-flow-aware, critical for precise structural assessment of code restoration.
Decoding protocols enforce zero-shot, deterministic settings, and postprocessing removes all extraneous markup and whitespace.
Empirical Results
Aggregate Model Results
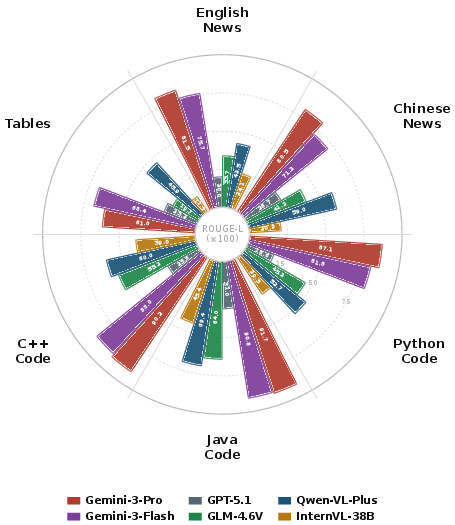
Evaluation covers 14 MLLMs (GPT-5, Gemini 3, Qwen-VL, InternVL, Mistral3-Reas, DeepSeek-OCR, etc.). Both proprietary and open-source models are evaluated across all benchmarks.
- Natural Language: Models achieve better reconstruction in English than Chinese, a consequence of logogram density and segmentation sensitivity. Minor physical tears in Chinese often obliterate semantic content, compounding metric penalties.
- Source Code: AST-aware metrics reveal even state-of-the-art models routinely fail to reconstruct logical order and indentation, especially in whitespace-dependent languages (Python). CodeBLEU scores for vendor models (e.g., Gemini 3 Pro: 0.77 in Python @ N=8) significantly exceed open-source models.
- Tables: Rigid 2D structures exacerbate model weaknesses; Gemini 3 Flash, despite inferior text performance, surpasses Pro models on tabular data.
Granularity and Robustness
Performance decays linearly with increasing fragment count for most models. However, advanced proprietary architectures show slower decay, suggesting that scaling model size and architectural complexity improve—but do not solve—long-context, cross-fragment reasoning.
Qualitative Error Analysis
Case studies reveal characteristic failure modes.
- Visual-Semantic Bridging: Success is marked by the model recovering contiguous tokens across physically bisected fragments, and partially preserving layout.
- Ordering and Layout Errors: Models misplace code lines or hallucinate paragraph boundaries based on misleading spatial gaps.

Figure 4: Example of a successful news reconstruction; minor layout segmentation error and complete token recovery across fragments.
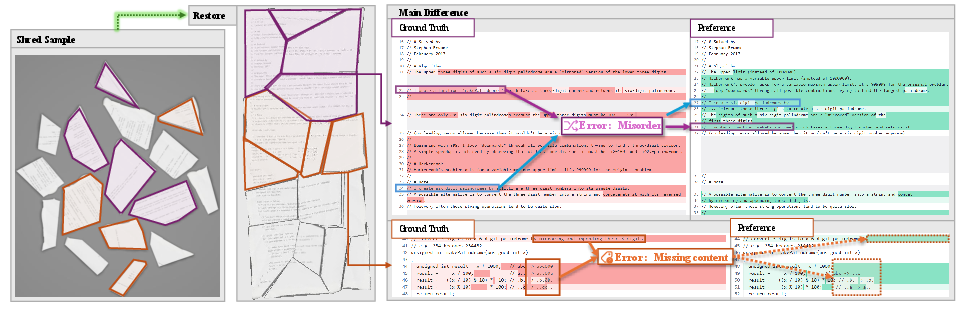
Figure 5: Code reconstruction failure; ordering errors and loss of narrow-line fragments typically discarded as visual noise.
Control Experiments: Semantic Reasoning vs. Visual Matching
Ablation tests on randomized "nonsense" text demonstrate that models’ performance collapses without semantic context (e.g., Gemini 3 Pro ROUGE drops from 0.73 to 0.33 at 16 fragments), confirming that ShredBench cannot be solved by visual jigsaw assembly alone and requires genuine semantic bridging.
Implications and Future Directions
The results illustrate a clear limitation in how MLLMs currently align local visual positional embeddings with global semantic continuity, especially when faced with non-canonical, physically disrupted inputs. This has immediate theoretical implications:
- Semantic Reassembly: The gap between human and model performance in semantic reassembly under fragmentation exposes fundamental limitations in present-day visual-textual fused architectures. End-to-end OCR-free models and recent vision-language transformers with fine-grained patch alignment do not solve the problem.
- Compositional Robustness: Recovery of logical structure (especially in 2D tables or code) remains an open challenge, suggesting the need for architectural innovations in set-to-sequence and permutation-invariant reasoning.
- Robust VRDU: Real-world document workflows (forensics, archival restoration, legal discovery) often require robust recovery from partial or physically damaged sources; current MLLMs fail badly in these critical domains.
This benchmark establishes clear empirical lower bounds and will drive research on algorithmic advances in VRDU, meta-learning for physical artifact recovery, explicit modeling of spatial syntax, and cross-modal attention mechanisms. Additionally, real-world extensions—e.g., overlapping/occluded fragments, variable lighting, and real paper textures—remain untested and represent clear opportunities for future work.
Conclusion
ShredBench defines a new standard for stress-testing the semantic reasoning capabilities of MLLMs under severe structural noise. Model performance reveals that state-of-the-art architectures—even those approaching human parity on intact document tasks—still fail at reconstructing global semantics from shredded input, especially in dense or highly structured domains. Future progress in robust document understanding will require deeper integration of permutation-invariant, context-aware, and language-prior-driven reasoning mechanisms.