The Chameleon's Limit: Investigating Persona Collapse and Homogenization in Large Language Models
Abstract: Applications based on LLMs, such as multi-agent simulations, require population diversity among agents. We identify a pervasive failure mode we term \emph{Persona Collapse}: agents each assigned a distinct profile nonetheless converge into a narrow behavioral mode, producing a homogeneous simulated population. To quantify persona collapse, we propose a framework that measures how much of the persona space a population occupies (Coverage), how evenly agents spread across it (Uniformity), and how rich the resulting behavioral patterns are (Complexity). Evaluating ten LLMs on personality simulation (BFI-44), moral reasoning, and self-introduction, we observe persona collapse along two axes: (1) Dimensions: a model can appear diverse on one axis yet structurally degenerate on another, and (2) Domains: the same model may collapse the most in personality yet be the most diverse in moral reasoning. Furthermore, item-level diagnostics reveal that behavioral variation tracks coarse demographic stereotypes rather than the fine-grained individual differences specified in each persona. Counter-intuitively, \textbf{the models achieving the highest per-persona fidelity consistently produce the most stereotyped populations}. We release our toolkit and data to support population-level evaluation of LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper asks a simple question with a big impact: If we tell AI chatbots (LLMs, or LLMs) to “act like different kinds of people,” can they really behave like a diverse group of individuals? The authors find that, too often, the answer is no. Even when AIs are given very detailed “persona” profiles (like age, country, politics, hobbies, job), many of them end up acting very similar to each other. The authors call this problem “persona collapse.”
What the researchers wanted to find out
They set out to investigate three easy-to-understand questions:
- How much of the “human variety” do AI personas actually cover?
- Do those AI personas spread out evenly across that variety, or bunch up in a few places?
- Is the variety genuinely rich, or does it just look different on the surface while actually changing along only one or two simple patterns?
They also wanted to see:
- Whether this problem is the same across different tasks (like personality surveys, moral choices, and writing self-introductions).
- Whether being very “faithful” to a persona (following its instructions closely) actually makes the overall population of AI personas more stereotyped and less diverse.
How they studied it (in everyday terms)
Think of all possible human personalities and behaviors as a giant “space,” like a big park with many paths. Each AI persona is like a person standing somewhere in that park. The team used three tools to check how the AI crowd spreads out in the park:
- Coverage: How many different areas of the park does the crowd reach? (Do we see people only on the main lawn, or also in the quiet corners?)
- Uniformity: Are people clumped into a few tight groups, or spread out fairly evenly?
- Complexity: Is their spread truly multi-directional and rich, or are they basically lined up along a few simple paths (even if they look spread out from far away)?
To measure this, they asked 10 different AI models to:
- Fill out a standard 44-question personality survey (BFI-44), which many humans have also taken. This gave a real human “map” to compare against.
- Judge 131 ethical (moral) scenarios on a 1–5 scale.
- Write three short, open-ended self-introductions as their assigned persona.
They then turned all those answers into a big “Behavioral Trait Matrix” (imagine a giant spreadsheet where rows are personas and columns are answers) and used the three tools above to assess spread and richness. They also added “item-level” checks to see where and how the collapse happens, such as:
- Effective response range: Does a model use the full range of answers, or mostly the middle (like always answering “3: neutral”)?
- Stereotype tracking: Do differences mostly follow broad categories like gender or politics, instead of the many fine-grained details in each persona?
- Attribute mention in text: When writing self-introductions, does the AI actually mention the assigned details (like age or social class), or does it skip them?
Analogy: If you tell 1,000 actors to play different roles, do they really perform differently and invent their own unique behaviors, or do they mostly use the same script with a few words swapped?
What they found (key results, simply explained)
Here are the main takeaways, explained plainly:
- Persona collapse is common. Even with detailed personas, many AIs gave similar answers, creating a population that looks alike instead of diverse.
- Spread can be misleading.
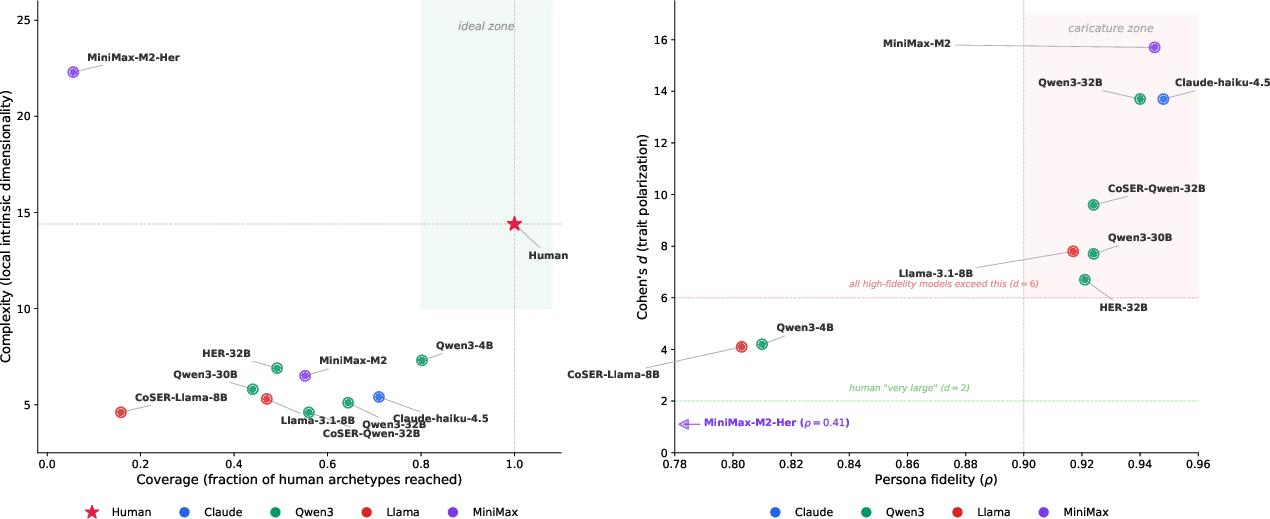
- Some models looked spread out across the “park” (good coverage) but still behaved in simple, low-variety ways (low complexity), like walking along a straight line that passes through many parts of the park.
- Other models had rich variety (high complexity) but wandered in parts of the “park” where real humans rarely are (low coverage), so they weren’t aligned with real human patterns.
- Clumping vs even spread. Several models bunched into tight clusters (poor uniformity), meaning many personas collapsed into only a few “types.”
- Vocabulary collapse on surveys. On personality questions, some models overused the middle option (“3: neutral”) or limited themselves to just a few choices, which hid differences between personas.
- Stereotypes over specifics. When differences did show up, they often matched broad categories (like gender or social class) rather than all the fine details provided in each persona. In other words, the models leaned on coarse stereotypes instead of combining many attributes in nuanced ways.
- The “fidelity trap.” Models that best followed persona instructions for each individual (high “fidelity”) often produced the most exaggerated, caricature-like differences between groups overall. So scoring well on “did this specific persona answer like it should?” didn’t mean the whole population looked realistic—it often meant more stereotyping across the population.
- Task matters a lot. A model could look very collapsed on personality questions but quite diverse on moral reasoning, or vice versa. That means judging a model on just one kind of task can give the wrong impression.
- In free text, sameness shows up as templates. Some models wrote self-introductions using the same skeleton or structure for many different personas, just swapping a few details—a different kind of collapse.
- Which details survive? In self-introductions, models most often mentioned gender and country, less often politics, and least often age and social class. That means important aspects like socioeconomic background (social class) got ignored or dropped, which can flatten diversity.
Why this matters
- For simulations and testing: Many people want to use AI agents to simulate societies, test products with “virtual users,” or run large-scale surveys. If those AI personas all behave similarly—or fall back on stereotypes—the results won’t reflect real, messy human variety.
- For fairness and representation: If models ignore certain attributes (like social class) and lean on stereotypes, they can miss or misrepresent important experiences and viewpoints.
- For evaluation: Focusing only on whether a single persona sounds “correct” can be misleading. We also need to check how the whole group of personas behaves together, to avoid the fidelity trap.
What this could change going forward
- Better tests: The paper provides a toolkit and metrics (coverage, uniformity, complexity, plus item-level checks) to evaluate population-level diversity. This helps researchers and practitioners spot collapse early.
- Better training goals: Current training often rewards being a “helpful assistant,” which can pull answers toward the center and reduce variety. Future training might include goals that encourage diversity within groups and reduce stereotyped differences.
- Broader evaluations: Models should be checked across multiple tasks (surveys, decisions, and free writing) because collapse can appear in different ways in different settings.
In short, the paper shows that AI “chameleons” can change color—but only so much. If we want truly diverse, non-stereotyped AI populations, we need to measure and train for that diversity directly, not just assume it appears when we assign detailed personas.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains unresolved or underexplored in the study, phrased to guide concrete next steps.
- Missing human baselines for moral reasoning and self-introductions: collect human judgments and writing samples under identical prompts to compute Coverage, Uniformity, and Complexity relative to humans, not just model-to-model.
- Dependence on a single human reference for BFI-44 (Twin-2K-500): replicate with multiple, culturally diverse personality datasets to assess external validity and cross-cultural robustness.
- Ordinal–interval mismatch: Euclidean distances and k-NN geometry assume interval scaling on Likert responses; test ordinal-aware distances (e.g., polychoric-based metrics) and report sensitivity of Coverage/LID/Hopkins to this choice.
- Metric sensitivity and hyperparameters: systematically vary k for k-NN, neighborhood radii, and normalization schemes to quantify robustness of Coverage and LID; pre-register thresholds for “healthy” vs “collapsed” ranges.
- High-dimensional uniformity concerns: Hopkins statistic can be unstable in high dimensions; compare against alternative dispersion metrics (e.g., Ripley’s K in projected spaces, energy distance, hyperspherical discrepancy) and report concordance.
- Embedding dependence in free-text analyses: Complexity and clustering in self-introductions depend on a chosen embedding model; repeat with multiple embedding backbones and quantify variance across encoders.
- Underpowered attribute detection in free text: keyword matching misses implicit or paraphrased mentions; replace with trained extractors (NER/RE), NLI-based attribute inference, or human annotation to obtain calibrated precision/recall.
- Incomplete coverage of the 26 persona dimensions: item-level truncation and stereotyping are analyzed for only four attributes (gender, country, politics, class); extend diagnostics to all dimensions (e.g., disability, orientation, occupation, hobbies).
- Missing interaction analyses: incremental R2 emphasizes main effects; add factorial ANOVA or mixed-effects models to test whether models capture intersectionality (attribute interactions) rather than just marginal effects.
- Prompt design confound: only one persona serialization and instruction template are tested; ablate attribute order, verbosity, formatting (JSON vs prose), and placement (system vs user) to measure effects on collapse.
- Decoding/configuration effects: all runs use API defaults; systematically vary temperature/top-p/penalties and seed to assess how sampling controls influence Coverage, Uniformity, Complexity, and ICC (with uncertainty bands).
- Limited examination of “thinking mode”: only one model is tested; extend to multiple models and reasoning prompting variants to determine whether chain-of-thought mitigates attribute truncation.
- Short-run sampling for self-introductions (3 samples/persona): increase sample count and session length to better estimate within-persona variance (ICC) and disentangle stochasticity from stable persona expression.
- Model coverage and scaling: evaluation omits larger and frontier closed models; study scaling laws and architectural differences (e.g., MoE vs dense) for their impact on collapse metrics.
- Training-stage causality: lack of controlled ablations prevents isolating contributions of pretraining, SFT, and RLHF/RLAIF; run controlled pipelines on the same base model to quantify each stage’s effect on Coverage/Uniformity/Complexity and stereotyping.
- RL objective design space: observed post-RL misalignment lacks tested mitigations; design rewards that penalize prototype extremization, preserve human Coverage, and explicitly encourage within-group variance, then evaluate.
- Domain generality: only personality, moral judgments, and self-intros are studied; extend to additional behavioral domains (risk preferences, political attitudes beyond Likert, conversational pragmatics, long-horizon planning).
- Dynamics and persistence: single-turn probes with persona prefixed each time do not test temporal stability; evaluate multi-turn, memory-enabled agents and multi-agent settings to measure persona drift and social-conformity-driven homogenization over time.
- Cross-lingual and cultural embodiment: all prompts/outputs appear in English; test personas in their native languages and with culturally localized instruments to assess whether collapse worsens across languages/cultures.
- Safety/guardrail confounds: refusals and midpoint defaults may reflect safety policies rather than collapse; quantify refusal rates, use neutral rephrasings, and include research-mode/offline models to separate guardrails from modeling limitations.
- Psychometric rigor: treating all BFI items equally ignores measurement error and factor loadings; apply IRT/GRM and factor-score estimation to assess collapse on latent traits with reliability accounted for.
- Visualization reliability: t-SNE can artifactually cluster points; corroborate with PCA/UMAP/Isomap and report stability across random seeds and parameters.
- Semantic interpretability of “misalignment”: high LID but low Coverage is labeled misaligned without semantic analysis; construct interpretable subspaces (e.g., factor-aligned, task-specific) to examine whether complex model manifolds are behaviorally coherent.
- Generalization to rare attribute combinations: the sample excludes 856/2000 personas after screening; quantify how filtering and rarity of combinations impact collapse, and test balanced factorial persona sets covering tails.
- Tool-use and multimodality: collapse is diagnosed only in text-only tasks; evaluate tool-augmented and multimodal models to see whether external tools or vision/audio inputs mitigate or exacerbate homogenization.
- Reproducibility and version drift: reliance on API defaults without full configuration logs impedes replication; release exact prompts, seeds, decoding settings, and model versions; report metric variability across runs.
- Calibration of Likert endpoints: prevalent midpoint choices may be induced by scale labeling; compare alternative anchors (verbal labels, forced choice, sliders) to test susceptibility to response-style biases.
- Governance and dual-use: the framework could optimize more convincing demographic impersonation; propose access controls and ethical guidelines to accompany release of high-resolution diagnostics.
- Mechanistic underpinnings: references to an “Assistant Axis” are not empirically probed here; conduct mechanistic interpretability (e.g., linear probes, causal interventions) to locate circuits/directions mediating attribute truncation and homogenization.
Practical Applications
Immediate Applications
Below are concrete ways to apply the paper’s diagnostics and findings today in industry, academia, policy, and daily workflows.
- Persona-simulation QA and gating in multi-agent systems
- Sector: software (agent frameworks), gaming, UX research
- What: Add Coverage–Uniformity–Complexity (LID) checks on the Behavioral Trait Matrix (BTM) as a pre-deployment gate for agent populations. Set thresholds (e.g., minimum coverage vs. human reference, Hopkins within [0.45–0.65], LID floor) to prevent releasing homogenized agents.
- Tools/workflows: Integrate the authors’ toolkit into MLOps dashboards; nightly population audits; t-SNE maps of BTM for drift; failure alerts when clusters/over-regularity detected.
- Assumptions/dependencies: Access to persona prompts and batch outputs; basic compute for kNN/LID; a suitable reference set (e.g., human data for the domain when available).
- Auditing synthetic survey respondents and market research panels
- Sector: marketing, social science, polling, product testing
- What: Use Coverage to quantify tail underrepresentation, Effective Likert to detect midpoint bias, and η²/Dom% to identify stereotyping (e.g., moral judgments dominated by gender/class).
- Tools/workflows: “Synthetic panel health” scorecards, post-stratification weighting that down-weights overrepresented clusters, acceptance sampling that targets uncovered regions.
- Assumptions/dependencies: Human reference distributions for the target domain; consistent persona schema.
- Model selection and benchmarking for role-play tasks
- Sector: AI platform teams, enterprise AI
- What: Compare models on population-level metrics rather than per-persona fidelity alone to avoid the “fidelity trap” (high ρ with extreme caricature).
- Tools/workflows: Internal leaderboard tracking Cov/Hop/LID alongside traditional win rates; procurement criteria that require population diversity KPIs.
- Assumptions/dependencies: Access to candidate model APIs/weights for batch evaluation.
- Prompt and pipeline hardening against attribute truncation
- Sector: software, creative tools, education
- What: Use item-level diagnostics (incremental R², attribute mention rates, effective response range) to spot which attributes are dropped (e.g., social class, age). Adjust persona serialization and prompts to surface underrepresented dimensions (e.g., explicit reminders, structured checklists).
- Tools/workflows: Prompt linting that flags likely truncation; template-diversity detectors that penalize repeated rhetorical skeletons; batch re-ranking to diversify underused response bins.
- Assumptions/dependencies: Ability to modify prompts and decode settings; logging to compute per-item distributions.
- Fairness and compliance audits for stereotyping risk
- Sector: HR tech, finance, healthcare, government services
- What: Report η² and Dom% across sensitive attributes to reveal when outputs track stereotypes rather than individual differences. Use as part of model/system risk assessments.
- Tools/workflows: “Stereotype dashboard” showing which attribute dominates moral or evaluative judgments; automated escalation when Dom% exceeds a policy threshold.
- Assumptions/dependencies: Governance approval to monitor sensitive attributes; careful interpretation (diagnostics reveal model behavior, not human reality).
- Agent/population design in games and simulations
- Sector: gaming, training sims, scenario planning
- What: Introduce “diversity controls” for non-player characters (NPCs) that target desired Coverage and LID, and prevent lattice-like or clumped distributions (Hopkins~0.5).
- Tools/workflows: NPC generator that samples personas to fill uncovered regions; sliders for “spread” (coverage) and “complexity” (LID).
- Assumptions/dependencies: Batch generation and metric feedback loop; content moderation guardrails.
- Academic evaluation and curricula
- Sector: academia/education
- What: Adopt BTM-based population diagnostics in LLM evaluation courses and papers; replicate domain-contingent collapse across tasks (personality vs. moral reasoning vs. free text).
- Tools/workflows: Course labs using the released code/data; mandatory population-level metrics in publications that claim persona fidelity.
- Assumptions/dependencies: Access to open datasets/models; institutional IRB guidance when extending to new references.
- Pre-/post-training audits of SFT and RLHF effects
- Sector: foundation model developers
- What: Measure how PSFT and RLHF alter Cov/Hop/LID and η²/Dom% (e.g., RL increasing complexity but harming coverage). Use to prevent drift to non-human manifolds.
- Tools/workflows: Training checkpoints audited on a fixed persona suite; early-stopping or objective adjustments when coverage collapses.
- Assumptions/dependencies: Access to training pipeline and checkpoints; cost budget for batch evaluations.
- Content moderation and brand-safety checks for persona outputs
- Sector: advertising, social media, customer support
- What: Detect when outputs collapse to stereotyped templates or extreme caricatures and route for review.
- Tools/workflows: Template re-use counters, effective Likert thresholds for opinionated content, attribute-dominance alerts.
- Assumptions/dependencies: Policy-defined thresholds; human reviewer capacity.
- Cautionary use in healthcare and education simulations
- Sector: healthcare training, education tech
- What: Use population diagnostics to flag unrealistic patient/student populations (e.g., diversity illusion with shallow coverage), preventing overreliance on biased simulators.
- Tools/workflows: Simulation intake checklists requiring Cov/Hop/LID reports; disclaimers and documented limitations when using LLM-based personas.
- Assumptions/dependencies: Access to domain-specific human references (e.g., validated patient profiles); oversight committees.
Long-Term Applications
These opportunities require further research, tooling, or changes to training regimes before widespread deployment.
- Diversity-aligned training objectives and RL
- Sector: foundation model development
- What: Introduce objectives that jointly maximize human-referenced Coverage, preserve Uniformity (Hopkins ≈ 0.5), and maintain high LID—while minimizing Dom% and η² along sensitive axes. Combine with KL terms that avoid collapse to “Helpful Assistant” attractors.
- Tools/products: “Diversity-Constrained Alignment” RL recipes; reward models that score population health; curriculum generation that fills uncovered regions.
- Dependencies: Access to base weights and RL infrastructure; scalable human or synthetic references across domains.
- Certified audits and regulatory standards for LLM simulations
- Sector: policy/regulation, public procurement
- What: Establish certification schemas (e.g., for governmental use of simulated respondents or agent-based policy testing) that require minimum Cov/Hop/LID and stereotype ceilings.
- Tools/products: Compliance test suites; third-party audit reports; procurement clauses referencing population-level metrics.
- Dependencies: Consensus on reference datasets; legal frameworks around sensitive-attribute auditing.
- Persona memory/representation architectures to prevent attribute truncation
- Sector: research, foundation models
- What: Architectures that bind multi-attribute persona states to generation (e.g., identity embeddings, attribute-conditioned planning, chain-of-perspective prompts) to keep non-salient attributes active.
- Tools/products: Persona-conditioned decoders; attention controllers that enforce attribute coverage across a session.
- Dependencies: Model access; evaluation datasets with ground-truth multi-attribute enactment.
- Population-aware decoding and re-ranking
- Sector: software tooling
- What: Batch decoding that optimizes the set of outputs for population coverage/uniformity/complexity, not just per-sample likelihood. Use knapsack-like selection to fill uncovered neighborhoods and avoid template reuse.
- Tools/products: “Population sampler” libraries for surveys, agents, and NPC creation; diversity-aware beam/reranking.
- Dependencies: Efficient vectorization of BTM estimation; latency budgets for production use.
- Synthetic population generators for ABMs and scenario planning
- Sector: urban planning, epidemiology, economics, defense
- What: Services that generate agent populations matched to human reference manifolds with tunable diversity, enabling more reliable “what-if” analyses.
- Tools/products: Coverage-constrained samplers; adaptive persona libraries that track target demographics and psychographics.
- Dependencies: Domain-specific human references; validation against real-world outcomes.
- Domain-robust persona fidelity without caricature
- Sector: foundation models, enterprise AI
- What: Multi-objective training that preserves persona adherence while capping trait polarization (Cohen’s d) and reducing stereotype tracking across tasks.
- Tools/products: Anti-caricature regularizers; domain adapters calibrated with item-level diagnostics.
- Dependencies: Task-conditional evaluation; access to per-domain references.
- Continuous “population health” monitors in multi-agent ecosystems
- Sector: agent platforms, robotics swarms (human-interaction policies), enterprise simulators
- What: Online monitoring that detects clumping or lattice patterns and triggers resampling or diversification policies.
- Tools/products: Population-health microservices; auto-remediation policies (e.g., persona mutation to fill gaps).
- Dependencies: System instrumentation; clear SLAs for diversity metrics.
- Human-in-the-loop persona map curation
- Sector: UX research, creative industries
- What: Interactive maps of the behavioral space where analysts drag/drop to augment underrepresented regions and approve/rerank candidates for campaigns, narratives, or tests.
- Tools/products: Visual analytics for BTM; semi-automated “gap-filling” assistants.
- Dependencies: Usable embeddings and interpretable factor/item maps; training for analysts.
- Cross-domain benchmark suites and references beyond Likert
- Sector: research, standards bodies
- What: Expand references to open-ended texts, task-specific behaviors, and culture-sensitive domains to make Coverage and LID meaningful outside personality scales.
- Tools/products: Community-maintained reference corpora; standardized evaluation harnesses.
- Dependencies: Data contribution pipelines; governance for sensitive attributes.
- Fairness constraints tied to Dom%/η² in downstream decision aids
- Sector: finance, hiring, content ranking
- What: Apply ceilings on attribute dominance in model-driven judgments (e.g., advice, rankings), with logging and remediation when exceeded.
- Tools/products: Fairness modules that compute Dom%/η² on live decisions; alerting and fallback policies.
- Dependencies: Legal/policy approval; careful causal interpretation to avoid over-correction.
Notes on feasibility
- Human reference distributions are crucial for meaningful Coverage; without them, use model-to-model comparisons and item-level diagnostics as proxies.
- Population metrics add compute overhead; batch evaluations and periodic audits mitigate latency in production.
- Sensitive-attribute auditing requires governance and careful communication: the metrics describe model behavior, not human truths.
- Access to model internals (training, decoding, weights) enables stronger mitigations; with closed models, focus on monitoring and post-processing.
Glossary
- Assistant Axis: A linear direction in transformer residual space associated with “helpful assistant” behavior. "a single linear direction in the residual stream, the Assistant Axis, modulates helpful-identity expression and predicts persona drift under adversarial contexts."
- Attribute truncation: The selective retention of only a few salient persona attributes while discarding others. "This attribute truncation severely degrades the behavioral richness of the simulated population."
- Behavioral Trait Matrix: A matrix where each row is a persona’s responses across behavioral items. "We represent a population of personas as a Behavioral Trait Matrix "
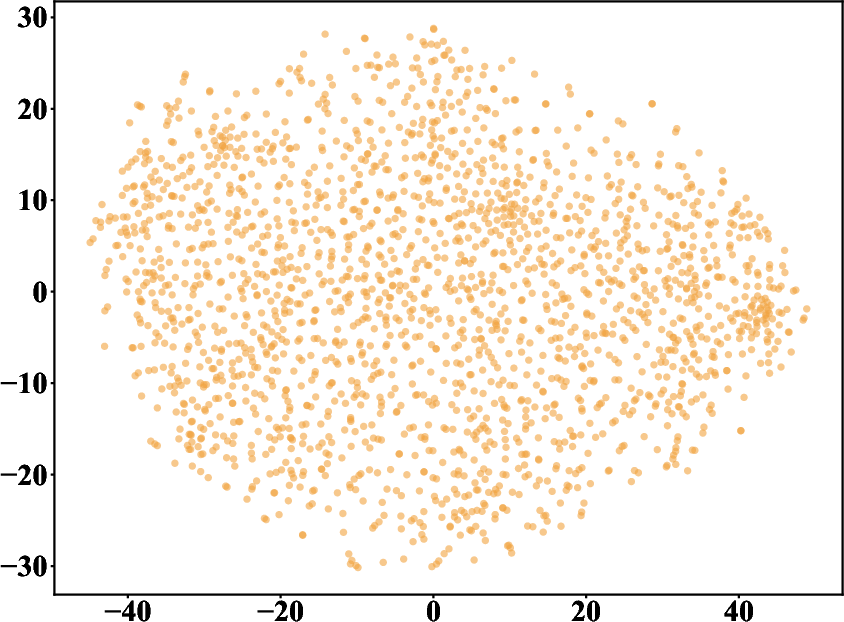
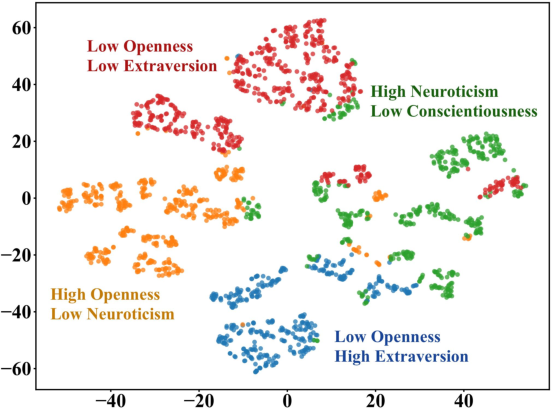
- Big Five Inventory (BFI-44): A 44-item instrument measuring five personality factors using Likert scales. "t-SNE projection of the BFI-44 personality instrument for 2{,}058 individuals."
- Cohen's d: An effect size measuring standardized mean differences between groups. "Cohen's between demographic target groups (e.g., personas assigned High vs.\ Low Extraversion) provides a complementary effect-size measure."
- Complexity (diagnostic axis): Degree to which variation is genuinely high-dimensional rather than confined to a subspace. "Complexity: Humans fill a high-dimensional volume, whereas models collapse onto low-dimensional manifolds (e.g., a line)."
- Coverage (diagnostic axis): Extent to which generated personas reach neighborhoods of a human reference distribution. "Coverage: The model concentrates in modal regions."
- Demographic clustering: Analysis of how much behavioral variation is explained by coarse demographic categories. "Demographic clustering. We test whether behavioral variation tracks coarse demographic categories rather than individual differences."
- Density (metric): Counts how many reference neighborhoods contain a generated sample, averaged over samples. "Density counts how many reference neighborhoods contain a given sample, averaged over :"
- Dom%: Share of total demographic variance explained attributable to the single strongest attribute. "We summarize this decomposition with Dom\%, the fraction of total demographic attributable to the single strongest attribute; a uniform baseline would yield 25\%."
- Effective Likert (EffL): A diversity measure of Likert responses based on the inverse Simpson index. "EffL: effective Likert (inverse Simpson; max)."
- Effective response range: Item-level diversity metric using the inverse Simpson index over response levels. "Effective response range. For each item , we compute the inverse Simpson index "
- Factor loading matrix: A matrix mapping items to latent factors with loadings. "The factor loading matrix encodes how strongly each item loads onto each of factors."
- Hopkins statistic: A test of spatial randomness used to quantify clustering vs. uniform spread. "We measure Uniformity via the Hopkins statistic~\citep{hopkins1954new}: random probe points are dropped into the behavioral space, and the test compares nearest-neighbor distances from probes versus from real personas."
- Hyperspherical uniformity: A measure of how evenly points are distributed on a unit hypersphere. "We also report hyperspherical uniformity~\citep{wang2020understanding} as a supplementary metric"
- Hyperspherical uniformity loss: A loss measuring dispersion of unit-normalized vectors on the sphere. "Hyperspherical uniformity loss. When response profiles are -normalized to the unit hypersphere , distributional regularity is measured via the loss of \citet{wang2020understanding}:"
- Incremental : Decomposition of explained variance contributed uniquely by each added attribute. "we perform incremental analysis"
- Intraclass correlation (ICC): Proportion of variance attributable to between-persona differences versus sampling noise. "and intraclass correlation (ICC), which measures the fraction of linguistic feature variance attributable to persona identity versus random sampling noise across a persona's three self-introduction samples."
- k-nearest-neighbor hyperspheres: Neighborhoods defined by distances to the k-th nearest neighbor, used for coverage. "via -nearest-neighbor hyperspheres."
- KL regularization: Regularization toward a reference policy via Kullback–Leibler divergence in RLHF-style training. "Joint reward maximization and KL regularization~\citep{ouyang2022training} create a strong attractor"
- Likert scale: An ordered categorical rating scale often with five points. "Your evaluation should culminate in a decision expressed on a 5-point Likert scale"
- Local Intrinsic Dimensionality (LID): A local estimate of manifold dimensionality based on neighbor distance ratios. "We measure Complexity via Local Intrinsic Dimensionality (LID)"
- Maximum Likelihood Estimator (MLE): Statistical estimator used here to compute LID from neighbor distances. "estimated at each point using the Maximum Likelihood Estimator over its -nearest neighbors"
- Moral Reasoning (instrument): A set of ethical scenarios rated on Likert scales to probe moral judgments. "Second, we use 131 ethical scenarios from Moral Reasoning \citep{liu-etal-2025-synthetic}."
- Persona Collapse: Structural homogenization where distinct personas converge to similar behaviors. "We term this structural homogenization Persona Collapse."
- Persona-specific supervised fine-tuning (PSFT): SFT targeted at persona/character data to improve role-play adherence. "isolates the effect of persona-specific supervised fine-tuning (PSFT) on the same base architecture"
- Precision–Recall formulations: Earlier generative evaluation approach balancing sample quality and diversity. "improving on earlier precision--recall formulations~\citep{kynkaanniemi2019improved}."
- Reinforcement Learning from Human Feedback (RLHF): RL framework aligning models to human preferences via feedback and KL penalties. "Persona collapse follows directly from RLHF's optimization geometry."
- Residual stream: The main activation pathway in transformer layers where linear directions can encode behaviors. "a single linear direction in the residual stream, the Assistant Axis, modulates helpful-identity expression"
- Separation distance: The minimum pairwise distance between personas, indicating indistinguishability if near zero. "Separation distance. The separation distance identifies the closest pair of personas:"
- Spearman fidelity (Spearman’s rho): Rank correlation-based fidelity between target persona traits and model outputs. ": Spearman fidelity (BFI only)."
- Sycophancy: Model tendency to agree with or mirror user/expected views, a sign of homogenization. "with sycophancy as one surface manifestation~\citep{sharma2025towards}."
- t-SNE: A nonlinear dimensionality reduction method for visualizing high-dimensional distributions. "t-SNE projection of the BFI-44 personality instrument for 2{,}058 individuals."
- Uniformity (diagnostic axis): Evenness of spread across occupied space, as opposed to clumping or lattice-like spacing. "Uniformity: Human distributions resemble spatial randomness (); models either overengineer populations into lattices () or degenerate into isolated clusters ()."
- V-Measure: An external clustering evaluation metric combining homogeneity and completeness. "VM: V-Measure (moral only)."
- Variance decomposition: Partitioning variance at factor/item levels to detect inflation or compression across attributes. "Variance decomposition. We compare behavioral variance between the model population and the human reference at two levels."
- η2 (eta-squared): Proportion of variance explained by categorical factors (e.g., demographics). "we compute (the proportion of variance explained) across demographic variables"
Collections
Sign up for free to add this paper to one or more collections.