- The paper introduces CacheFlow, a novel multi-dimensional framework that exploits token, layer, and GPU parallelism to drastically reduce KV cache restoration times.
- It employs a batch-aware two-pointer scheduler to overlap recomputation with I/O, achieving a 10–62% reduction in Time-To-First-Token for long-context workloads.
- The study demonstrates that leveraging 3D parallelism in distributed GPU setups yields near-linear speedup and enhanced overall resource utilization.
Efficient LLM Serving through 3D-Parallel KV Cache Restoration: CacheFlow
Introduction
Key-Value (KV) cache restoration has emerged as a principal bottleneck in serving long-context LLM workloads, particularly in settings driven by multi-turn dialogue, retrieval-augmented generation, and agentic pipelines. Conventional restoration methods exhibit fundamental limitations by primarily framing restoration as a per-request dichotomy between recomputation (high computational cost, quadratic in input length due to attention complexity) and I/O transfer (bounded by bandwidth constraints). These approaches neglect inherent batch-level resource contention and underexploit parallelism across tokens, model layers, and distributed GPU deployments.
CacheFlow proposes a novel multi-dimensional scheduling framework for KV cache restoration, leveraging structured parallelism along tokens, layers, and GPU shards. The system introduces a unified 3D parallel abstraction and a batch-aware two-pointer scheduler that jointly optimizes the overlap of recomputation and I/O, substantially reducing Time-To-First-Token (TTFT) compared to prior state-of-the-art.
Background: The Bottleneck of KV Cache Restoration
Contemporary LLM workloads increasingly operate with extended input contexts, necessitating the frequent reuse and restoration of large KV caches. The KV cache size scales linearly with sequence length, often exceeding GPU memory capacity for long sequences, thereby compelling systems to offload and later reload caches from slower storage tiers or recompute them entirely.
Empirical profiles across production chat and agent workloads indicate restoration times well in excess of feasible latency targets for user interaction, with recomputation times for long contexts reaching up to 1.5 seconds and I/O-based restoration degrading under realistic bandwidth limits (~10 Gbps) common on commodity cloud instances.
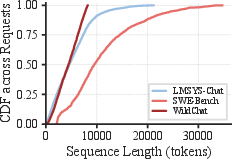
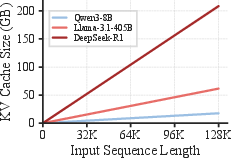
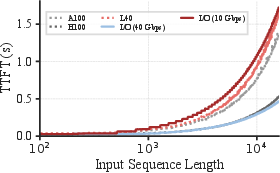
Figure 1: Real-world workloads exhibit long KV cache lengths to restore, leading to high latency and severe memory pressure.
This landscape demands a restoration paradigm that systematically exploits the problem structure and adapts to heterogeneity in request lengths and resource contention.
CacheFlow System Design and 3D Parallelism
CacheFlow's core design decomposes KV cache restoration into a parallel execution graph over tokens, layers, and pipeline-parallel GPU shards.
Token-wise and Layer-wise Parallelism: Restoration proceeds via a two-pointer, meet-in-the-middle strategy. For tokenwise parallelism, recomputation advances from the earliest tokens, while I/O-based restoration loads KV states from the end of the cached prefix, meeting at an intermediate chunk to avoid redundant work. For layerwise parallelism, forward passes recompute from lower layers upwards, while cached higher-layer states are loaded in parallel, with the optimal cutover determined by offline profiling for given hardware.
3D (Multi-GPU) Parallelism: For models split across GPU shards, CacheFlow exploits the independence of pipeline stages by leveraging boundary activations as the minimal interface. Local shard restoration is decoupled and performed in parallel, yielding theoretical linear speedup in the number of pipeline stages, subject to hardware and workload characteristics.
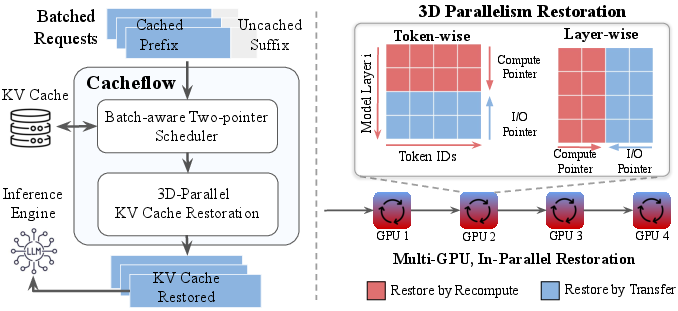
Figure 2: CacheFlow system architecture illustrating three dimensions of parallelism: tokens, layers, and GPUs.
Adaptive Scheduling with Batch Awareness
Realistic LLM serving involves concurrent batches of heterogeneous requests, contending for compute and I/O resources. CacheFlow orchestrates batch KV cache restoration through a batch-aware two-pointer scheduler. Each request maintains its individual recomputation and I/O pointers, while resource allocation is prioritized globally based on marginal reduction in recomputation cost, which is generally maximal for longer requests due to the quadratic attention cost. This policy mitigates straggler effects and maximizes aggregate throughput.
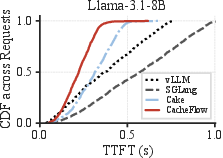
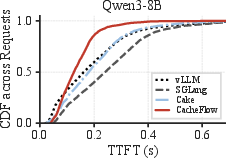
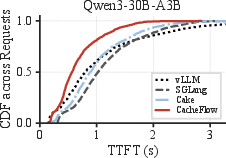
Figure 3: Distribution of request lengths and KV cache footprints in the WildChat workload, highlighting the tail of long-context requests dominating overall system cost.
Empirical Evaluation
End-to-End Latency and Resource Utilization
Across multiple LLMs (Qwen3-8B, Qwen3-30B-A3B, Llama-3.1-8B), CacheFlow achieves a 10–62% reduction in TTFT compared to vLLM (recomputation-only), SGLang/HiCache (hybrid cache loading), and LMCache (I/O-heavy). The improvements are most pronounced for workloads with long-context prefixes and in the tail distribution (P90–P99), substantiating the practical benefit of the batch-aware scheduler.
CacheFlow achieves superior resource utilization by overlapping compute with I/O. While pure I/O-based systems underutilize GPU and recomputation-only approaches underutilize bandwidth, CacheFlow demonstrates high simultaneous utilization for both resource classes.
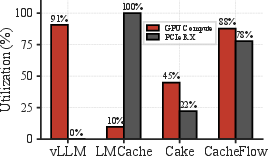
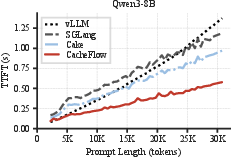
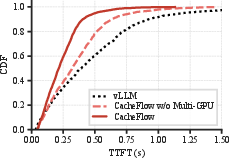
Figure 4: (Left) CacheFlow maintains high utilization for both GPU and I/O during KV restoration, (Center) TTFT scales gracefully in input length, and (Right) multi-GPU 3D parallelism yields substantial latency reduction relative to 2D approaches.
Ablation Studies
Length Sensitivity: The two-pointer design bounds the superlinear TTFT growth for long requests, outperforming per-request strategies as the performance gap widens with context length.
3D Parallelism: Disabling multi-GPU parallelism increases average restoration latency by 38%, affirming the necessity of distributed coordination.
Bandwidth and Hardware: CacheFlow scales efficiently with improvements in I/O bandwidth (e.g., 1.7× speedup at 40 Gbps relative to baselines), and adapts robustly over a range of hardware (L40S, A100, H100), consistently outperforming alternative methods.
Batch Size: Larger batch sizes accentuate CacheFlow's performance advantage, confirming the benefit of batch-coordinated scheduling.
Theoretical Analysis
The optimal split point for two-pointer restoration along either tokens or layers is determined by balancing compute and I/O so as to minimize maximal completion time, with the theoretical lower bound given by their harmonic mean. When generalized to S pipeline-parallel stages, restoration time obtains a further $1/S$ scaling factor, underlining the import of 3D parallelism for scaling serving workloads.
CacheFlow addresses a problem orthogonal to recent advances in KV cache compression (e.g., quantization, pruning [diffkv-sosp25, btp-neurips25, rkv-neurips25]), which primarily reduce GPU memory footprint but do not optimize restoration latency under heterogeneous resource constraints. Prior proposals for offloading and hybrid restoration (e.g., LMCache, HCache, MoonCake) do not exploit fine-grained parallelism or batch-aware scheduling, limiting their end-to-end efficiency in high-load, multi-GPU deployments.
Implications and Future Directions
CacheFlow's abstraction of multi-dimensional scheduling for KV restoration establishes a blueprint for efficient resource orchestration in large-scale LLM serving. Integrating adaptive profiling for hardware characteristics and request patterns further enables dynamic optimization in production. Extending the 3D abstraction to hierarchical and compositional model architectures, heterogeneous clusters, and alternative attention mechanisms (e.g., sparse or linear attention) constitutes an immediate research avenue. Moreover, co-design with emerging memory and interconnect technologies (e.g., CXL fabrics) stands to amplify CacheFlow’s benefits.
Conclusion
CacheFlow fundamentally reframes KV cache restoration as a multi-dimensional scheduling problem, exploiting structural parallelism across tokens, layers, and GPUs, coordinated by a batch-aware two-pointer scheduler. Empirical and theoretical analysis illustrate substantial reductions in serving latency and improved resource efficiency under broad conditions. The proposed methods set a new baseline for responsive, large-scale LLM serving systems and highlight the necessity of system-level co-design tailored to modern model and workload characteristics.