- The paper presents the first empirical study of KVCache in production, showing cache hit ratios of 54% and 62% versus >80% from synthetic benchmarks.
- It analyzes detailed token-level traces to uncover intra-session reuse patterns, with single-turn requests contributing disproportionately to cache hits.
- The study introduces a workload-aware eviction algorithm that boosts hit rates by up to 23.9% and reduces serving latency by up to 41.9%.
Characterization and Optimization of KVCache in Large-Scale LLM Serving
Introduction and Motivation
The paper "KVCache Cache in the Wild: Characterizing and Optimizing KVCache Cache at a Large Cloud Provider" (2506.02634) provides the first comprehensive characterization of real-world Key-Value (KV) cache usage in production-grade LLM serving workloads at a major cloud provider. KVCache—compact representations of token-prefix computations—is central for accelerating inference throughput and reducing latency in autoregressive transformer architectures. Despite prior work leveraging synthetic traces, KV reuse phenomena in operational contexts, particularly regarding cache lifecycle, hit ratios, and workload-specific temporal/spatial locality, were not fully understood.
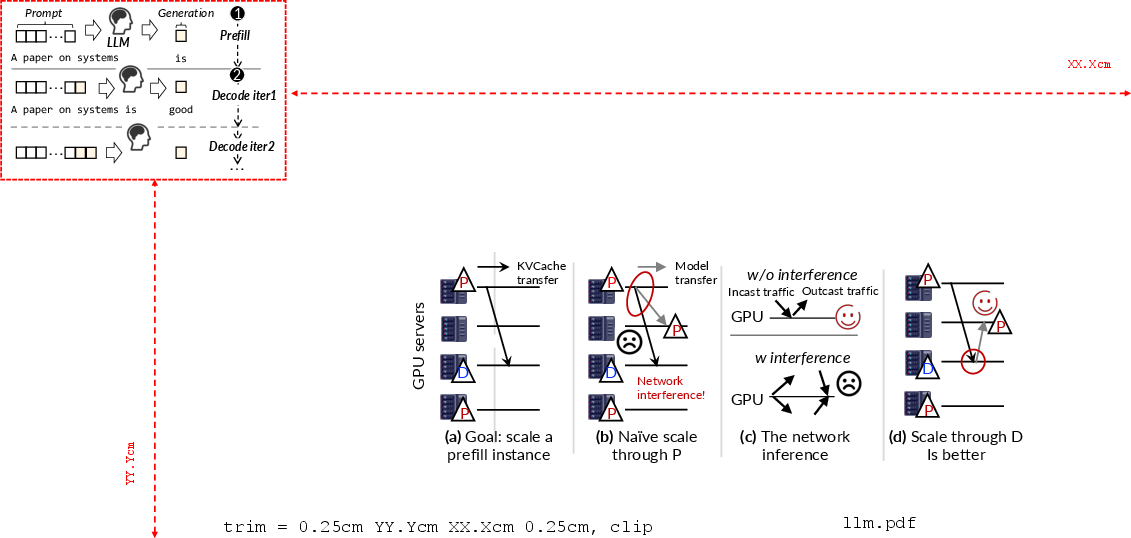
Figure 1: Illustration of the autoregressive LLM request processing workflow, emphasizing the prefill and decode phases with cached KV reuse.
Real-World Trace Collection and Analysis
The authors assembled and anonymized two distinct datasets ("Trace A": interactive human-to-cloud chatbot and multimodal/file/search; "Trace B": programmatic API calls with negligible multi-turn activity) to capture representative "to-C" and "to-B" workload mixes. Compared to prior public traces, these capture granular token-level hashes, multi-turn request linkages, request type, per-request token statistics, and user/session structure.

Figure 2: Example of detailed anonymized trace record, including timestamp, user/session metadata, request type, hashed token blocks, and conversation linkage.
Critical findings include:
- Ideal cache hit ratios in production are lower than synthetic benchmarks (e.g., 54% and 62% here vs. >80% reported with stylized traces). KV reuse propensity is heavily skewed: 10% of KV blocks contribute to 77% of observed reuse events.
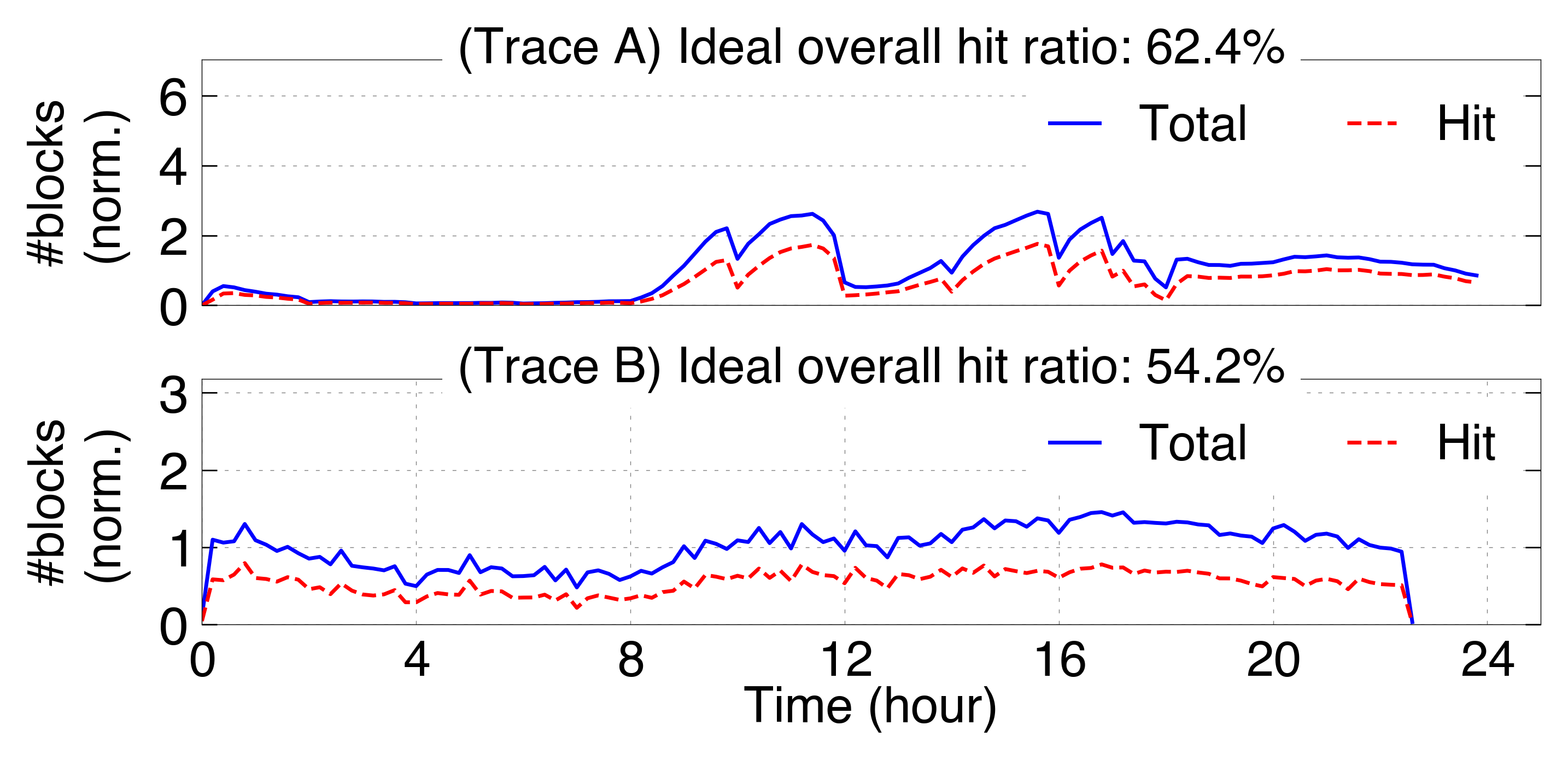
Figure 3: Ideal KV cache hit ratio under real serving workloads, showing normalized block accesses and hits per request type and workload category.
- KV reuse is dominated by intra-user, intra-session phenomena; between-user KV sharing is negligible in practice, regardless of template or library prompt adoption.
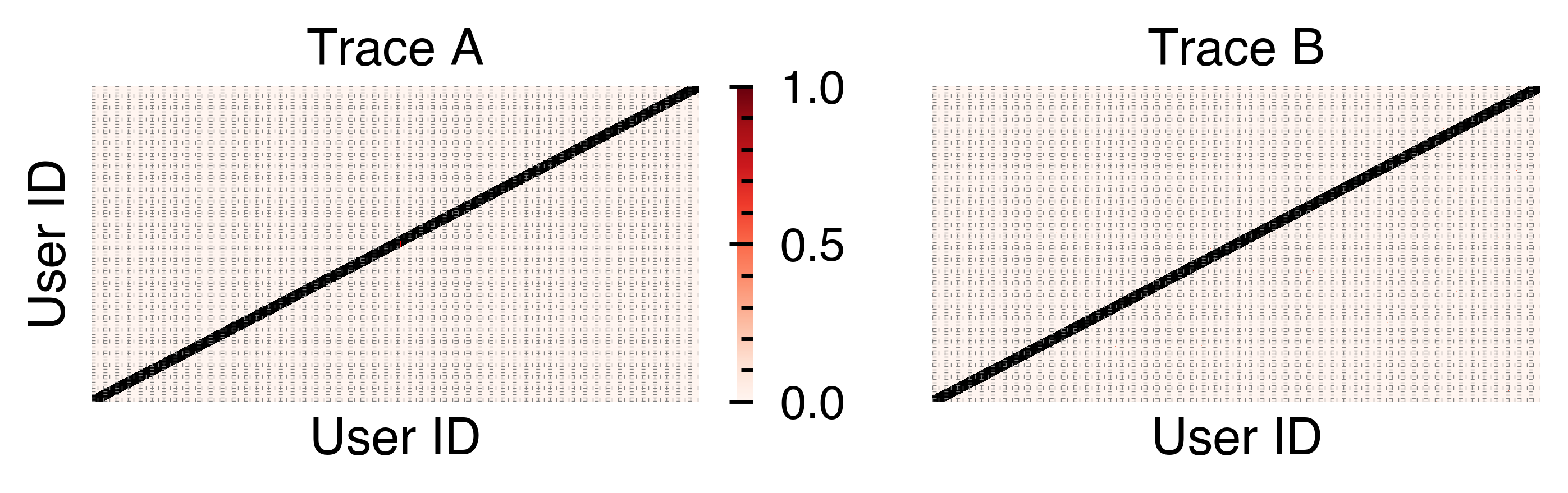
Figure 4: Heatmap showing cross-user KV cache hit frequencies; the diagonal indicates self-hit prevalence, minimal off-diagonal activity for inter-user reuse.
- Single-turn requests frequently contribute disproportionately to cache hits—not just multi-turn/conversational patterns—contrary to common assumptions in the field.
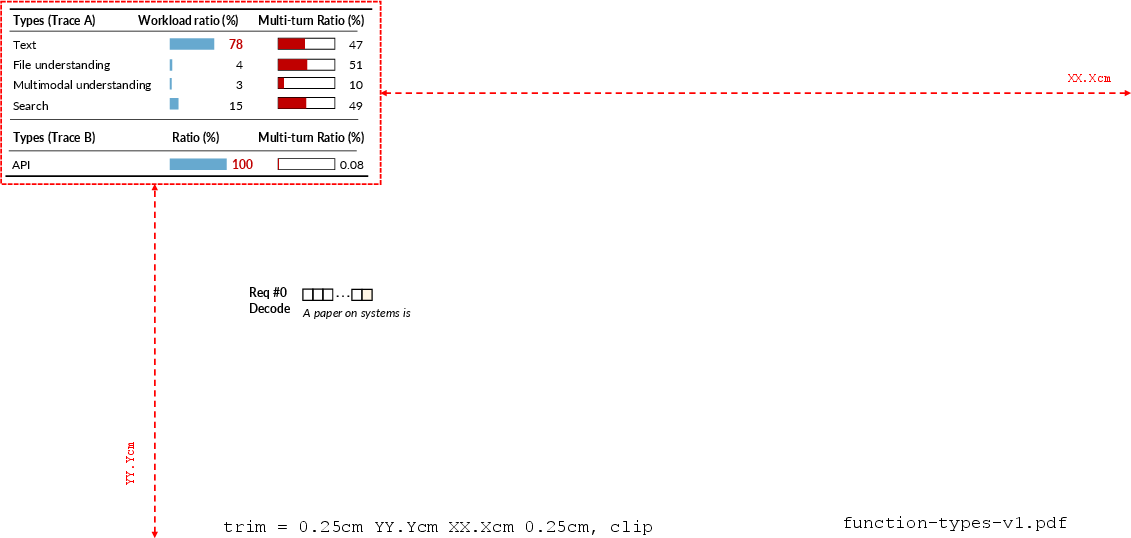
Figure 5: Distribution of functional workload types and multi-turn ratios among requests in the collected traces.
- Request load skew and user behavior: In Trace B, a small fraction of "head" users flood the serving infrastructure, resulting in pronounced usage and KV hit skew.
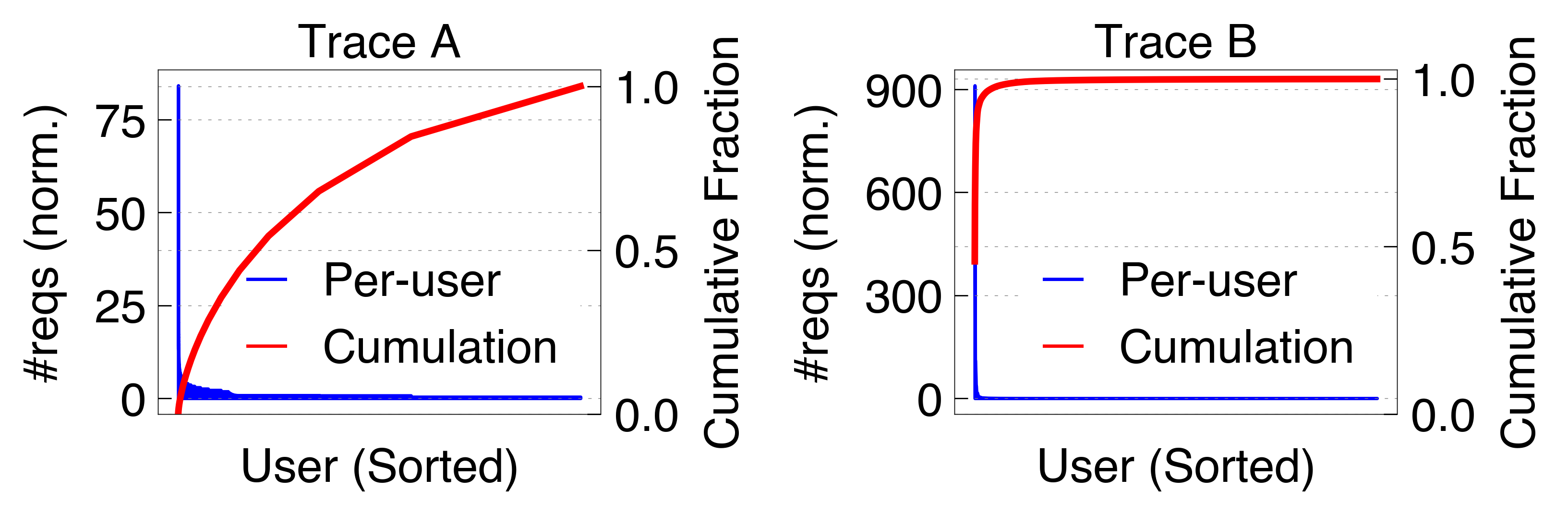
Figure 6: Normalized request count distribution across users, revealing extreme head-tail skew in API-dominated workloads.
Multi-turn Session Locality and Temporal Dynamics
Multi-turn conversational locality is highly variable both in turn-count and session engagement. The majority of sessions are single-turn, yet long-tail multi-turn sessions (up to 232 turns) drive bursty KV reuse for certain users.
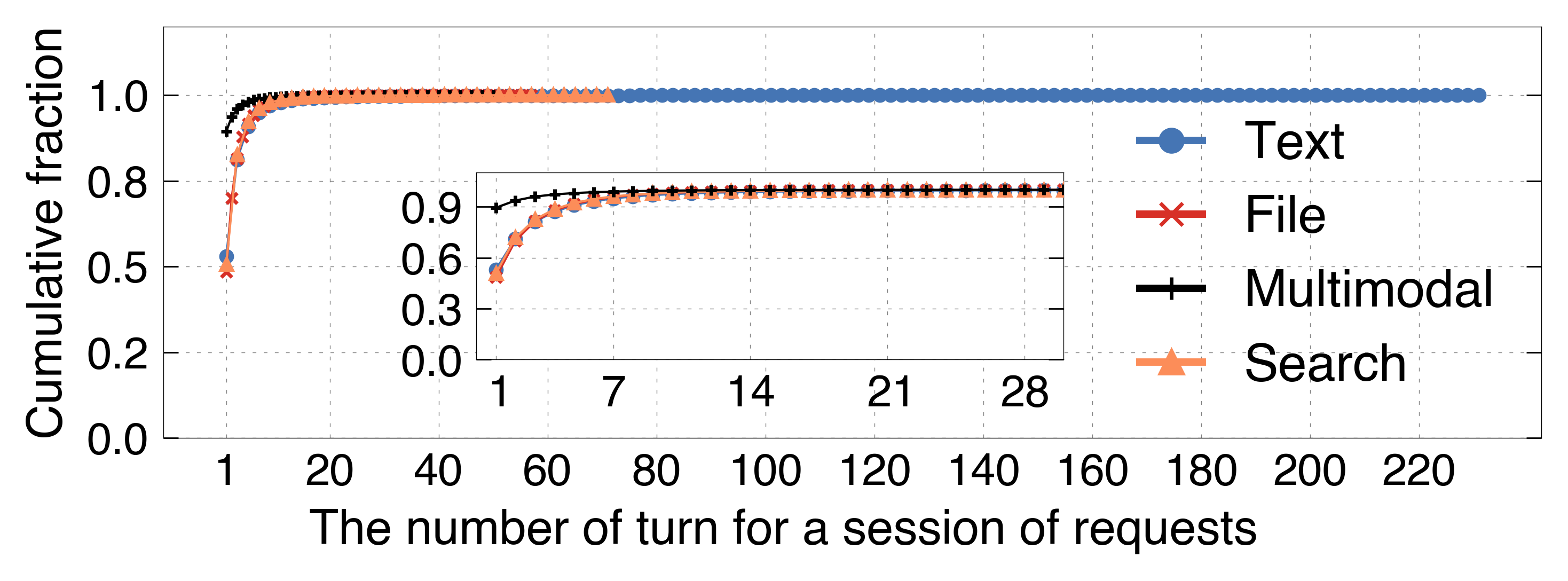
Figure 7: Distribution of turn numbers per session highlights the prevalence and variability of multi-turn behavior.
Temporal locality is request-type specific and follows an exponential decay in the reuse probability distribution for fixed categories. Short-lived KV blocks dominate, with P99 lifespan approximately 97 seconds for high-load API traces—substantially shorter than the traditional cache expectation.
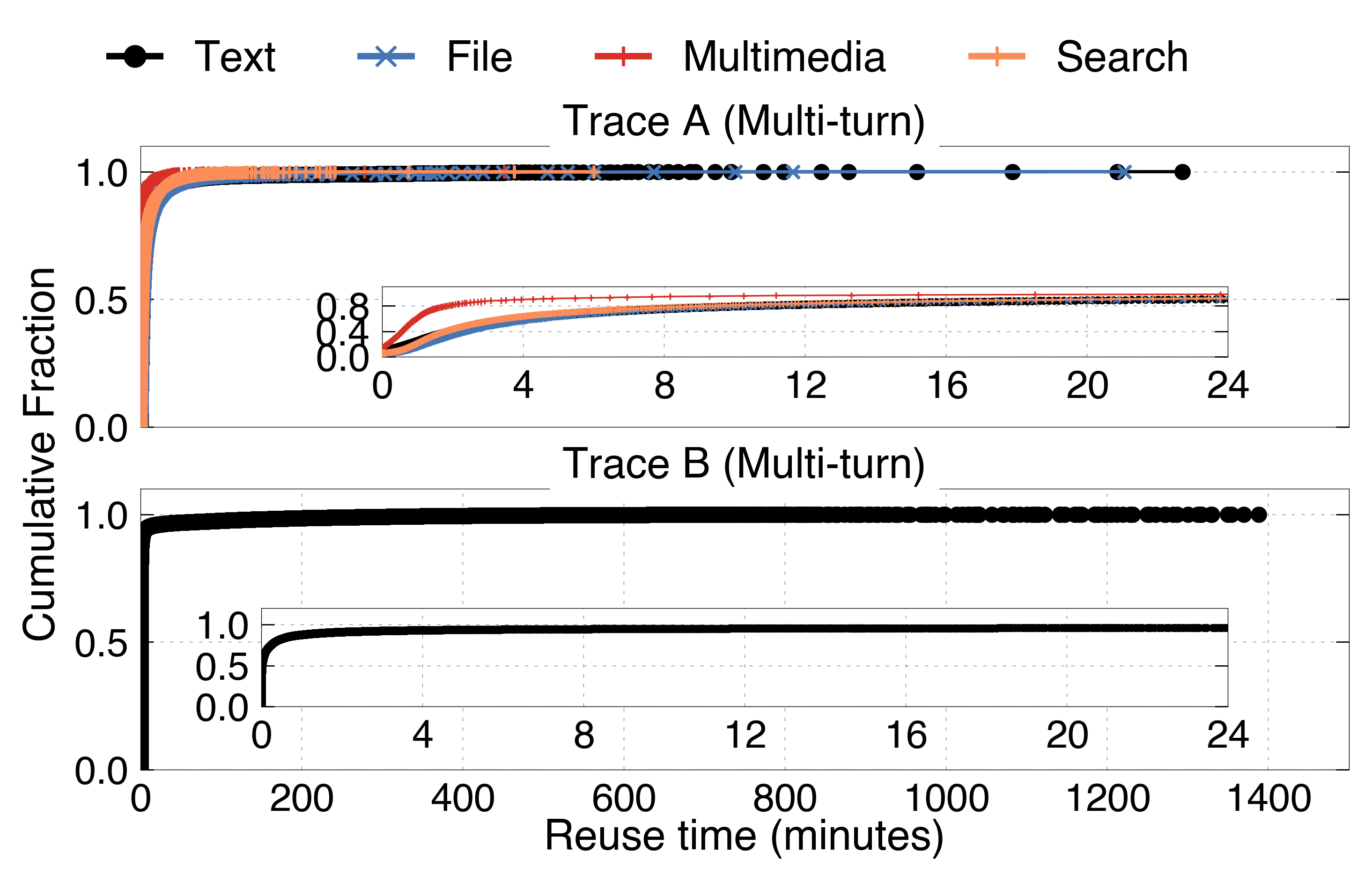
Figure 8: Distribution of KV block lifespan, for single and multi-turn requests.
Spatial locality is similarly workload dependent; prefix-token KV caching is much more effective than tail caching, with pronounced benefits for template-driven API and chat workloads.
Cache Capacity Implications
Despite moderate per-request KV size relative to GPU HBM capacity, aggregate ephemeral KV lifetime sharply restricts the required cache footprint for ideal hit ratios. For example, GQA models typically reach optimal hit rates with cache capacities only 2x that of GPU HBM, negating the need for extended CPU or SSD hierarchy in API-dominated scenarios.
Workload-Aware Eviction Policy Design
The paper proposes a novel workload-aware KV cache eviction algorithm informed by empirical reuse distributions. Unlike LRU/LFU or FIFO policies, the algorithm quantifies KV block survival using an exponential fit to the observed category-specific reuse probability, integrating both temporal decay and spatial locality factors (e.g., prefix-offset).
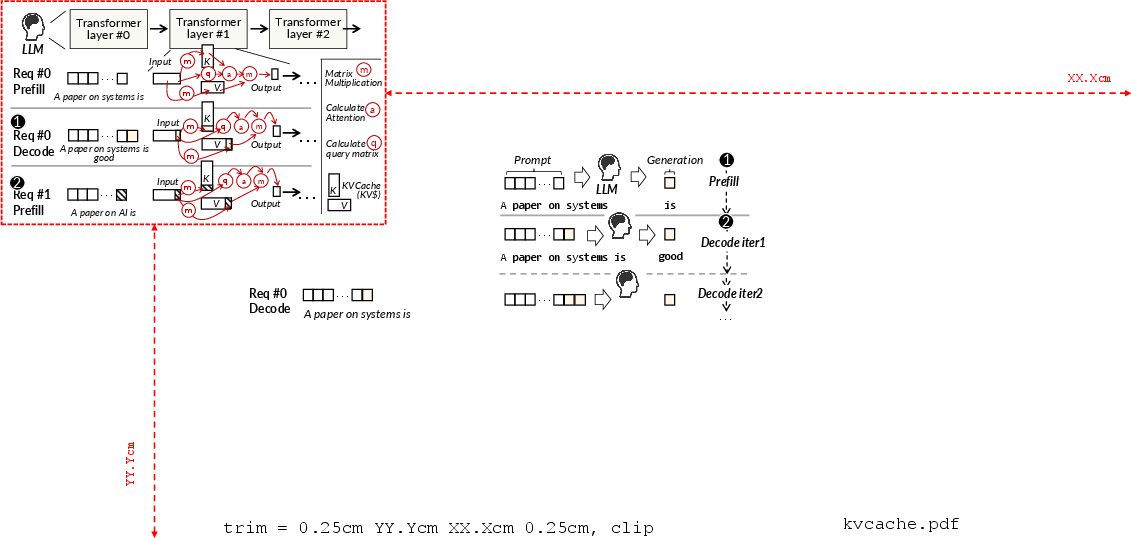
Figure 9: KVCache data flow diagram showing interleaved prefill and decode reuse across requests.
The policy performs lexicographic prioritization (reuse probability, prefix offset) and, acknowledging short-lived block dynamics, omits frequency counters to avoid dead-block cache pollution. Algorithmic implementation leverages per-category priority queues for efficient eviction candidate identification.
Figure 2: Pseudocode representation for the workload-aware cache eviction mechanism operating on trace-driven priority queues.
Experimental integration and testing using vLLM and public models (Qwen2-7B, Llama2-13B, Llama3-70B) reveal:
- Workload-aware policy increases cache hit rate by 1.5–3.9% compared to best baselines and up to 23.9% over standard LRU/LFU/S3-FIFO for specific traces.
- Serving latency reductions of 28.3–41.9% QTTFT are achieved through higher hit rate and more precise block retention under constrained cache allocations.
- Policy overhead is trivial compared to overall scheduling cost (only 1.2% increase).
Figure 3: Comparative analysis of cache hit ratio and model serving latency under different CPU cache capacities and eviction policies.
Implications, Theoretical Insights, and Future Directions
The work advances the understanding of production LLM serving, demonstrating that:
- KV reuse is driven by intra-session/user locality and template persistence, mandates separately tuning cache for single-turn and multi-turn request patterns.
- "Ideal" cache sizes are much lower than previously theorized for realistic (API-oriented) server workloads.
- Standard eviction heuristics misalign with actual KV lifespan and miss out on significant efficiency optimizations; frequency-based policies (LFU) are robustly outperformed by ephemeral-aware mechanisms due to the skewed frequency-lifespan relationship.
- Predictive, trace-driven workload adaptation has strong applicability for other LLM infrastructure layers (e.g., global scheduling, batching).
Production implementations should re-evaluate the necessity of deep cache tiers (e.g., CPU/SSD), aggressively monitor category-specific patterns, and consider fairness safeguards as the system-level policy can be manipulated by bursty head users.
Conclusion
This paper presents a fine-grained empirical characterization of KVCache usage in large-scale, heterogeneous LLM serving environments and introduces a workload-adaptive eviction strategy that merges statistical trace analysis with cache management. The implications are substantial: overall cache hierarchies can be reduced in complexity, resource and cost utilization can be matched to workload realities, and serving performance is measurably improved. This methodology is extensible to other ML inference infrastructure components and frames a new standard for cache design grounded in operational data rather than synthetic benchmarks.

