- The paper introduces a schema-grounded memory framework that addresses unstructured recall issues with an iterative, validation-driven extraction pipeline.
- It details a staged architecture that decomposes memory ingestion into object detection, field extraction, and validation to reduce error propagation.
- Empirical benchmarks demonstrate significant gains in accuracy, with object-level accuracy up to 90.42% and F1 scores reaching 97.10% across diverse domains.
Schema-Grounded Memory in AI: Design, Validation, and Empirical Analysis
Motivation and Failure Modes of Unstructured Memory
The study systematically deconstructs the limitations of conventional external memory architectures in AI, particularly retrieval-augmented generation (RAG) and embedding-based search methods. The authors highlight that factual, stateful, and relational queries systematically exceed the operational guarantees of semantic recall, primarily due to the implicit and approximate nature of relevance determination. Memory workloads such as updates, deletions, aggregation, joins, explicit unknowns, and negative queries require deterministic system-of-record semantics, which text-chunk retrieval and embedding similarity cannot ensure. The paper formalizes the information-theoretic loss inherent in compression and summarization operations, noting that post-compression, I(A;Z)≤I(A;X), with irreversible loss of low-salience factual details. Scale, reranking, hybrid systems, and long-context extensions ameliorate coverage but cannot deliver explicit predicate satisfaction, completeness, or reliable state tracking.
Schema-Grounded Memory: Architectural Principles
The core proposition is that memory reliability requires explicit, enforceable schemas acting as contracts that define entities, fields, constraints, and relations. Schemas transform memory from a passive heuristic to an actively governed system, enabling mechanical detection of missing fields, constraint violations, and explicit unknowns. The schema-centric approach provides stable semantics and clear boundaries for information retention, enforcing zero compression on critical facts while aggressively pruning irrelevant narrative. Reads occur over validated, structured records, eliminating repeated inference, stochastic interpretation, or latent drift in recall.
The paper establishes the irreducible joint error problem in single-pass structured extraction. For a record with m fields, ∏i=1mqi bounds the record-level accuracy, where qi is the conditional accuracy per field. This yields exponential decay in output-level correctness, with compounding errors and context contamination. The iterative extraction pipeline decomposes memory ingestion into object detection, field detection, and field-value extraction, each guarded by validation gates and targeted retries. This staged architecture isolates errors, avoids prefix corruption, and enables local correction without recomputation. Validators act on types, formats, normalization, and explicit unknowns.
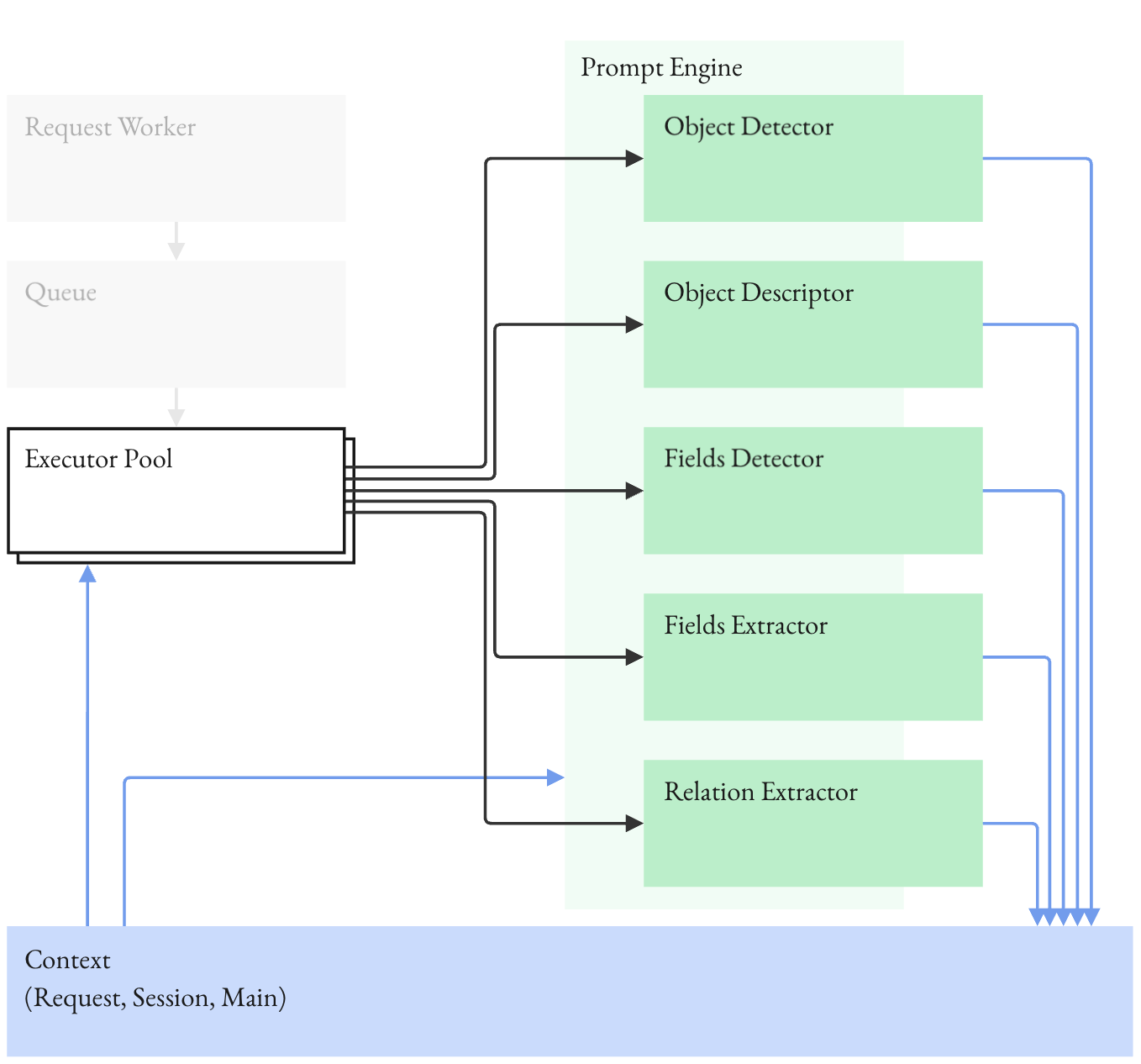
Figure 1: Iterative extraction pipeline: staged decisions with validation gates and local retries.
A schema-aware prompt engine orchestrates stateful prompts based on validated state, refines ambiguous detections, and facilitates negative constraints. Validation feedback loops are integral to the control flow, transforming generation into guided correction.
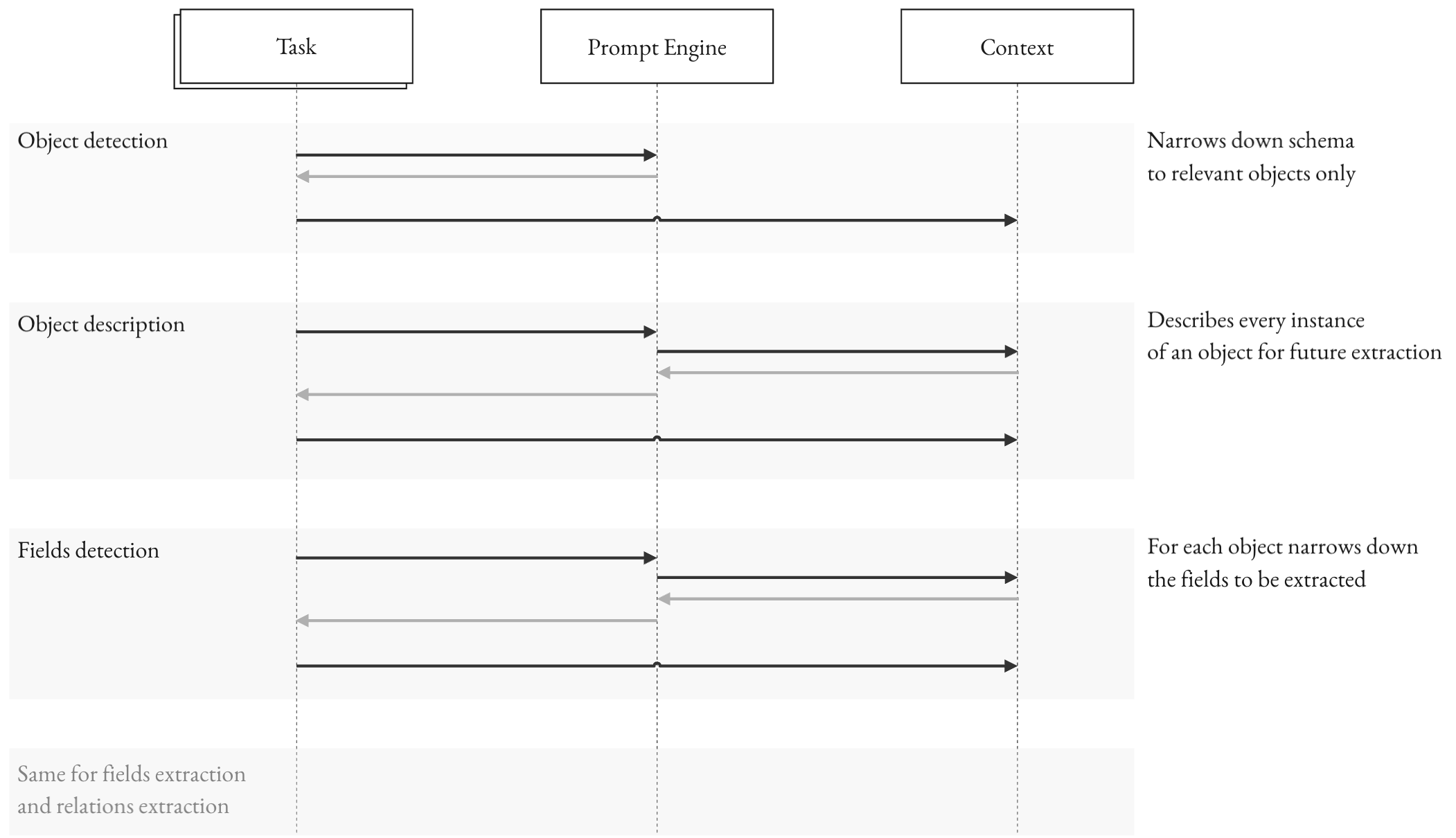
Figure 2: Prompt engine control flow: prompts evolve from extracted state, and validation feedback targets local retries rather than full regeneration.
Three memory contexts—request, session, main—partition ingestion and accumulation, supporting request-level precision, session-local object assembly, and versioned, lineage-tracked persistence.
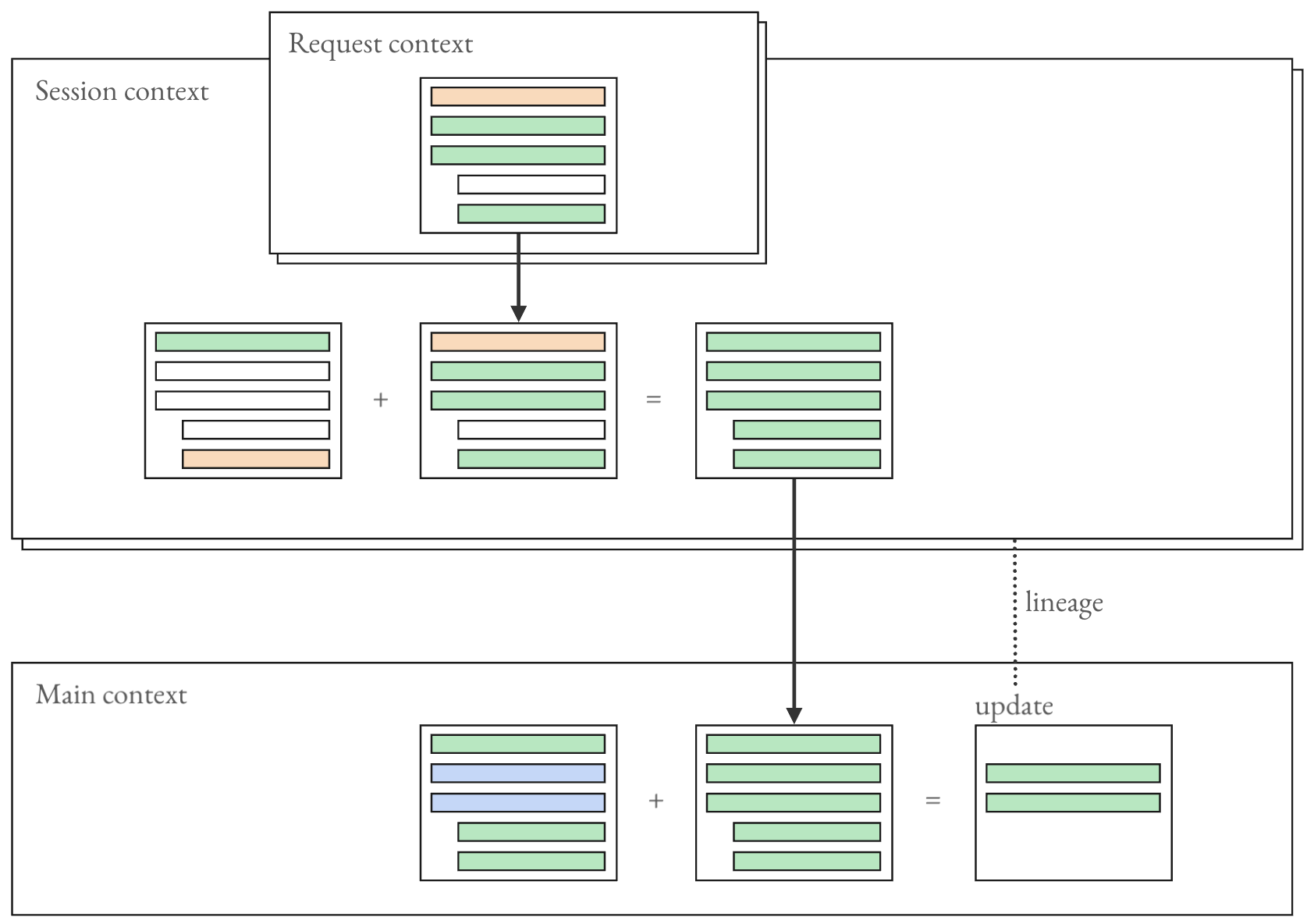
Figure 3: Three memory contexts and their merge flow: request context coordinates workers within a single write path, session context assembles partial objects across requests, and main memory persists versioned records with lineage.
Write-path complexity enables substantial reductions in token consumption and decision latency on read-heavy agents, with symbolic analysis showing that text-based systems may consume over 3x more LLM tokens per write-read cycle than schema-grounded alternatives.
Schema Lifecycle and Evolution
Practical deployment requires schema bootstrapping, agent-assisted design from intended queries, and ongoing evolution driven by observed usage, migrations, and auditability. This supports adaptive contracts that maintain answerability and long-term quality.
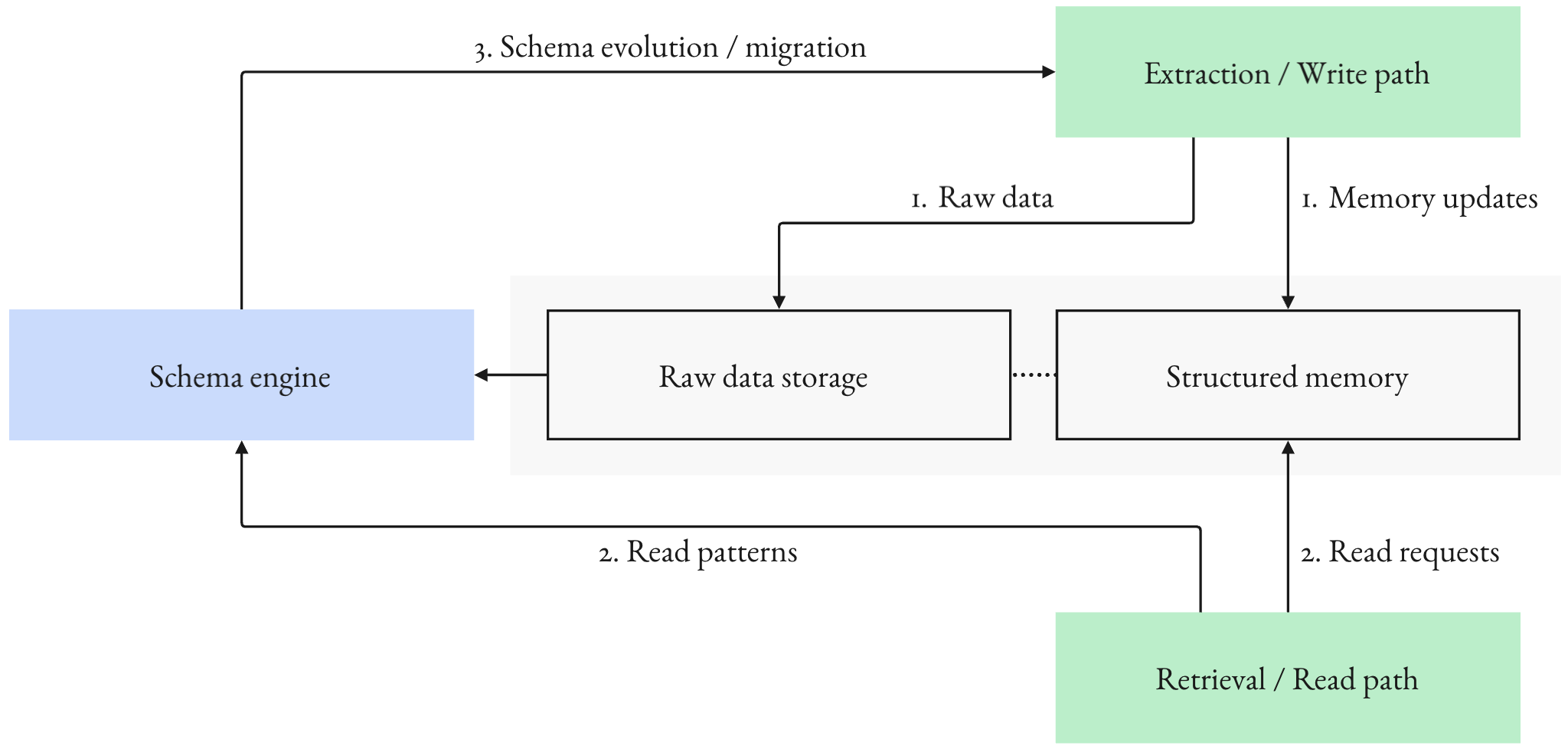
Figure 4: Schema evolution loop: observed questions and failures drive migration proposals; migrations update schema, prompts, and validators, and backfill where possible to improve long-term memory quality.
Empirical Evaluation and Results
Evaluation spans structured extraction, end-to-end memory benchmarks, and application-level workflows. On the modified Cleanlab insurance claims benchmark, xmemory reaches 90.42% object-level accuracy and 62.67% output accuracy, exceeding all tested frontier structured-output baselines. The end-to-end benchmark across four domains yields 97.10% F1, compared to 80.16%–87.24% for hybrid memory systems such as Mem0, Cognee, Supermemory, and Zep. The largest gains are observed in aggregation, state, relational, and exclusion queries.
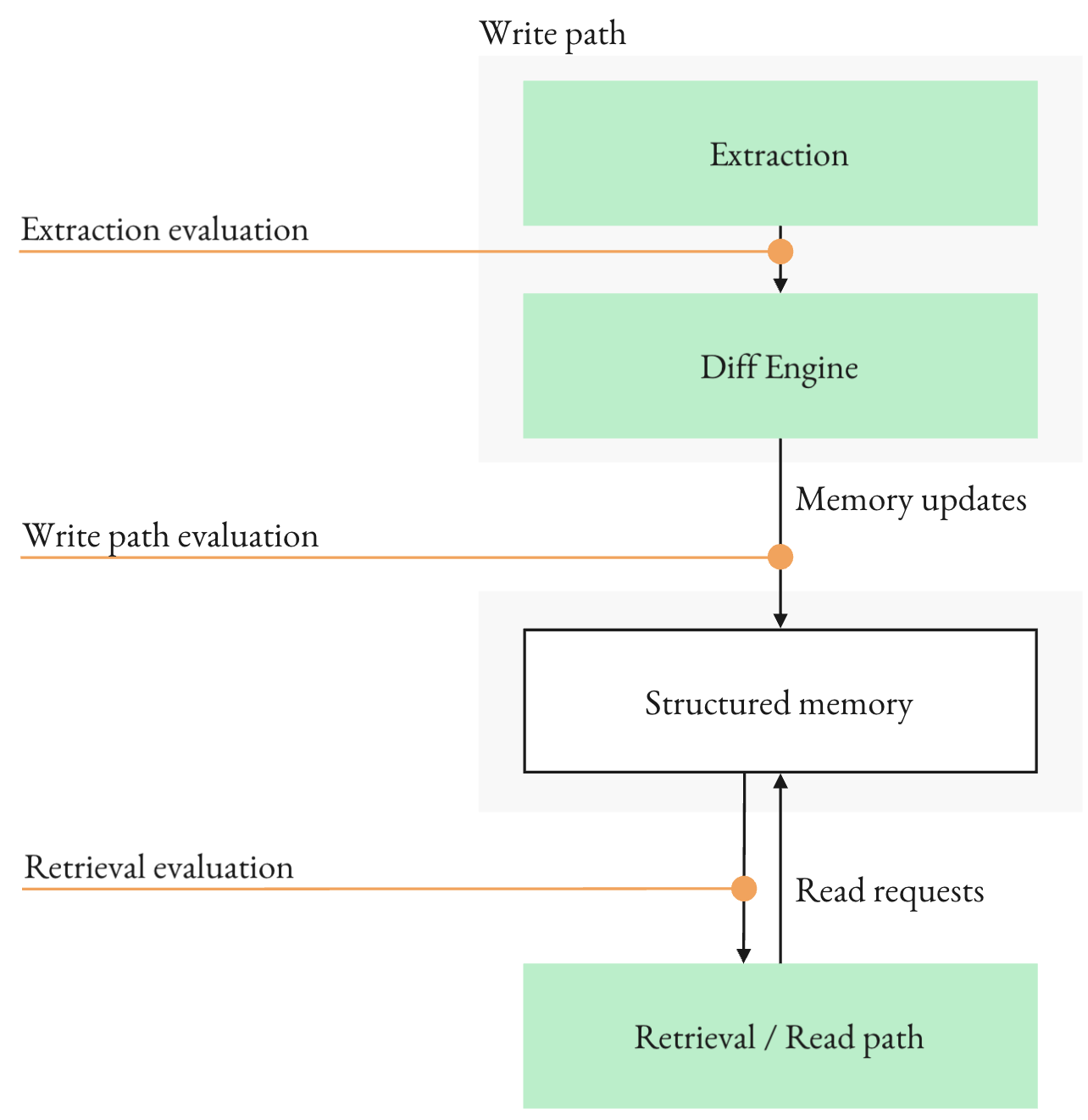
Figure 5: Measurement points in a schema-grounded memory system: write-path extraction, update and diff application, and read-path query answering.
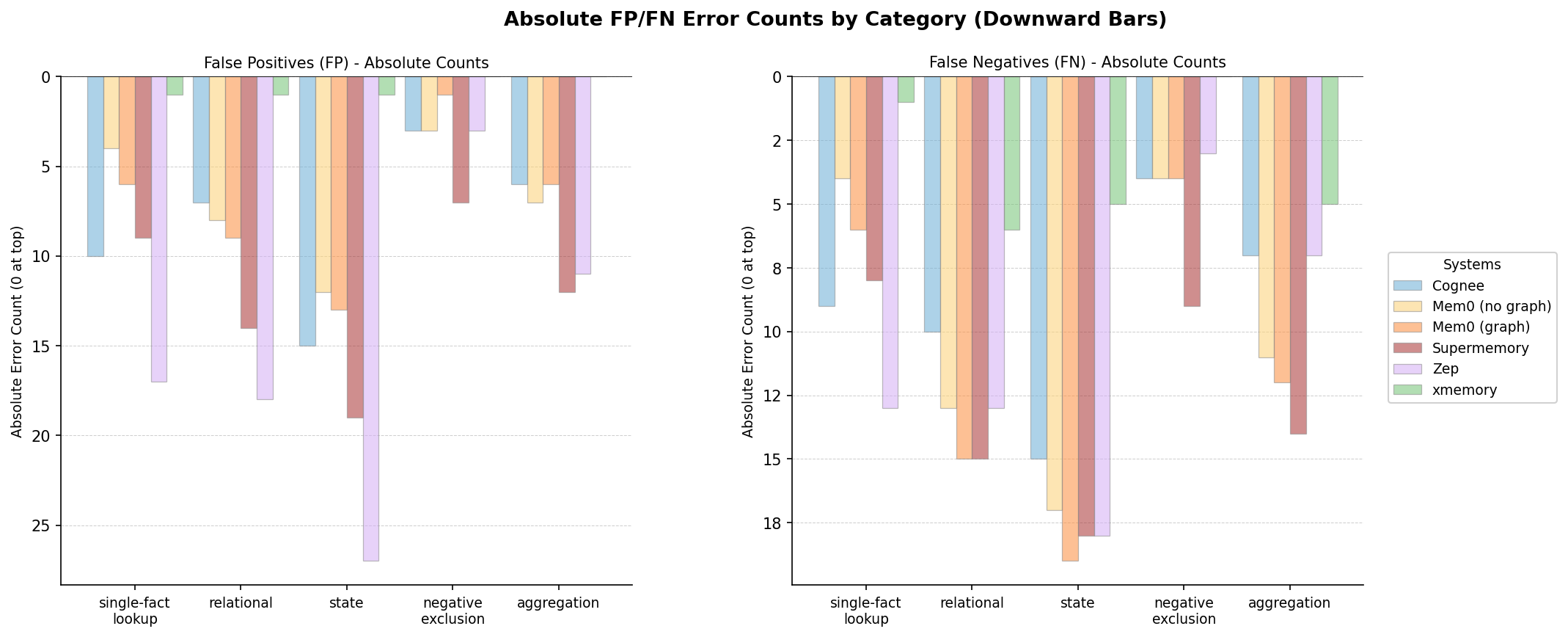
Figure 6: False positives (FP) and false negatives (FN) by query category. Bars extend downward from zero; lower absolute values indicate fewer errors. Counts reflect the number of incorrect facts across all read queries in each category.
On the Splitwise application benchmark, xmemory achieves 95.2% accuracy, outperforming both file-based Markdown harnesses and customer-facing application harnesses, supporting the claim that architecture and structure matter more than retrieval scale or model strength.
Structured extraction is framed as an entropy-reducing operation, with iterative validation and schema constraints minimizing H(Y∣X) by conditioning on detected fields and intermediate signals, shrinking plausible interpretations and preventing silent drift and corruption.
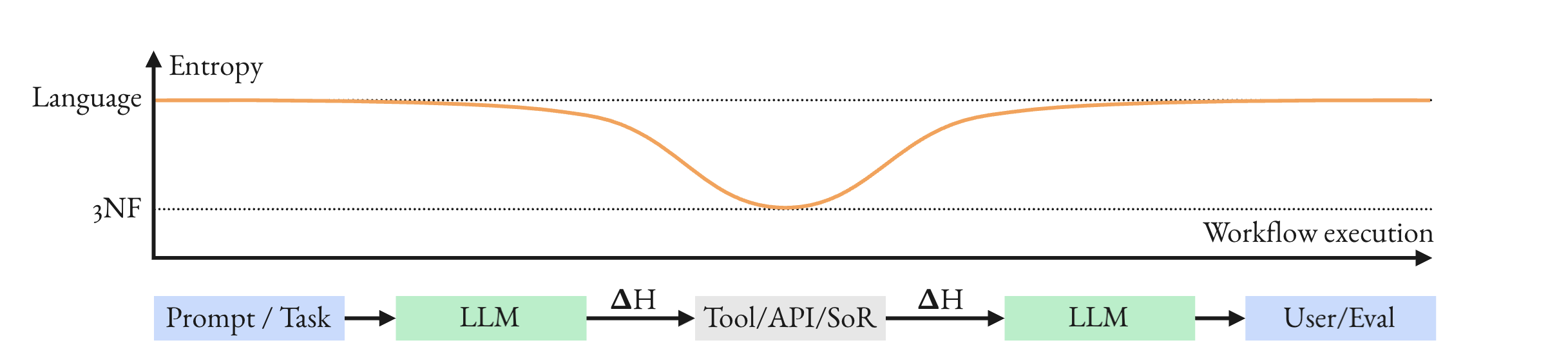
Figure 7: Entropy jump: each time a pipeline uses a tool, calls an API or queries System of Record it makes an entropy jump with potential information losses.
Implications and Prospective Directions
The findings establish that schema-grounded, iterative memory architectures provide superior correctness, stability, and debuggability in agentic production memory workloads, especially where state, aggregation, explicit unknowns, and mutation tracking are operationally critical. Strong numerical results directly contradict the widespread assumption that model upgrades or retrieval scale alone suffice for memory quality. The practical implication is that system design—specifically, interpretation on the write path—dominates architectural outcomes.
Theoretically, schema co-design for agent access presents open directions for automated schema generation, semantic migrations, conflict resolution, and structured audit. Further research should elaborate iterative extraction cost-accuracy curves, scalable schema evolution, and compositional error propagation in multi-agent settings.
Conclusion
Explicit schema-grounded memory with staged extraction, validation, and structured persistence achieves high factual correctness and operational stability in agent memory workloads, outperforming retrieval-centric and hybrid systems across multiple benchmarks. Memory quality scales with explicit structure and write-path control, not with model strength or retrieval quantity. The architecture offers concrete directions for reliable, scalable, and auditable agent memory in complex domains.