Learning Dynamics of Zeroth-Order Optimization: A Kernel Perspective
Published 5 May 2026 in cs.LG | (2605.03373v1)
Abstract: Classical optimization theory establishes that zeroth-order (ZO) algorithms suffer from a dimension-dependent slowdown, with convergence rates typically scaling with the model dimension compared to first-order methods. However, in contrast to these theoretical expectations, a growing body of recent work demonstrates the successful application of ZO methods to fine-tuning LLMs with billions of parameters. To explain this paradox, we derive the one-step learning dynamics of ZO SGD, where the empirical Neural Tangent Kernel (eNTK) naturally emerges as the key term governing the learning behavior. Inspection of the eNTK produced by ZO SGD reveals that each element corresponds to the inner product of neural tangent vectors projected onto a random low-dimensional subspace. Thus, by invoking the Johnson-Lindenstrauss Lemma, our analysis shows that the fidelity of the ZO eNTK is governed primarily by the number of perturbations. Crucially, the approximation error depends on the model output size rather than the massive parameter dimension. This dimension-free property provides a theoretical justification for the scalability of ZO methods to LLMs finetuning tasks. We believe that this kernel-based framework offers a novel perspective for understanding ZO methods within the context of learning dynamics.
The paper demonstrates that ZO optimization’s effective kernel (ZO eNTK) is independent of parameter dimension and governed by output size and perturbation count.
It employs the Johnson-Lindenstrauss lemma to bound the approximation error, showing convergence scales as O(√(V log V / P)), which is key for LLM finetuning.
Empirical results confirm that Gaussian and Rademacher perturbations offer similar trajectory convergence, underlining the method's robustness.
Learning Dynamics of Zeroth-Order Optimization: A Kernel Perspective
Introduction and Motivation
The paper "Learning Dynamics of Zeroth-Order Optimization: A Kernel Perspective" (2605.03373) systematically revisits the theoretical and empirical foundations of zeroth-order (ZO) optimization, refuting prevailing assumptions about its inefficacy in high-dimensional parameter spaces. ZO methods, which rely solely on function evaluations for gradient estimation, traditionally bear the stigma of dimension-dependent slowdown due to the variance scaling with model size. Paradoxically, recent empirical evidence demonstrates competitive performance of ZO strategies for finetuning LLMs despite their massive parameter counts. This work resolves this discrepancy by recasting ZO optimization in terms of the empirical Neural Tangent Kernel (eNTK) and analyzing how the geometry of learning dynamics is governed not by parameter dimension d but by output vocabulary size V and perturbation count P.
Kernel-Based Characterization of ZO Dynamics
The central technical contribution is a kernel-driven analysis of ZO optimization. The paper reformulates the ZO-SGD update in function space, revealing that the effective kernel governing learning, the ZO eNTK, is a projection of the FO eNTK onto a random low-dimensional subspace defined by the perturbation vectors. The key analytical insight is that this projection aligns with the Johnson-Lindenstrauss (JL) lemma: the fidelity of the kernel approximation, and consequently the learning trajectory, is controlled by the number of perturbations P and the output size V, but is independent of the underlying parameter dimension d. This perspective rigorously decouples trajectory fidelity from the "curse of dimensionality," offering an alternative to low effective-rank Hessian explanations and providing a kernel-theoretic foundation for the observed scalability of ZO finetuning.
The derivations formalize this connection both for single and multi-perturbation updates. Empirically and theoretically, the projection incurs an approximation error ϵ∼logV/P in the kernel space, dictating the evolution of model confidence and output distributions. This is made explicit by bounding the norm discrepancy between the FO and ZO kernels using JL theory and directly connecting it to output behavior, rather than optimization in parameter space alone.
Figure 1: ZO eNTK vs. FO eNTK for pairs with high and low input similarity; ZO eNTK convergence to FO structure with increasing perturbation count P.
Empirical Analysis and Sample Complexity Insights
Extensive experiments are conducted with MNIST/LeNet and LLM finetuning tasks. Kernel heatmaps and relative errors demonstrate that as the number of perturbations increases, the ZO eNTK not only denoises but rapidly recovers the geometry of the FO eNTK, especially for input pairs with high semantic similarity.
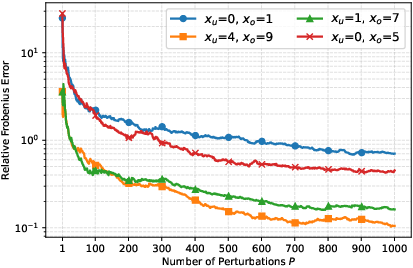
Figure 2: Convergence of Frobenius Norm Error between ZO and FO eNTK for different input pair similarities, demonstrating faster convergence for similar pairs.
Moreover, the empirical analysis reveals that for practical values, convergence rates in kernel space are effectively agnostic to parameter count, but increase as V with the output size—directly confirming JL scaling. The visualizations confirm that hard alignment tasks (disparate pairs) require larger P for equivalent fidelity.
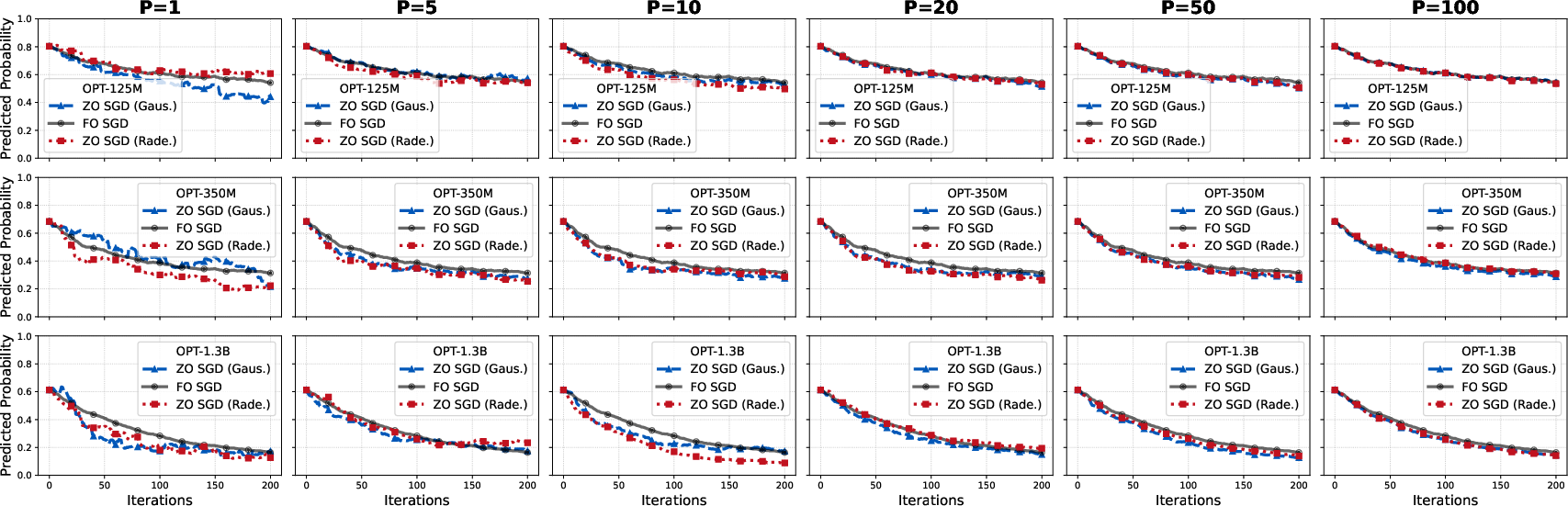
Figure 3: ZO trajectory comparisons across OPT model sizes on SST-2, validating model-dimension invariance of ZO convergence for fixed output size and perturbation count.
Distribution Robustness and Perturbation Strategies
A thorough characterization of the impact of perturbation distributions (Gaussian vs. Rademacher) shows negligible influence on trajectory convergence for moderate-to-large V0, both analytically and in practice. This is traced back to the tail behavior governing the concentration property; the empirical and JL-based theoretical analyses confirm that both distributions have comparable concentration constants, with the result that even cheap binary noise supports high-fidelity learning dynamics.
Figure 4: Comparison of Gaussian and Rademacher perturbation distributions for ZO eNTK convergence, demonstrating distribution-robust error decay.
The number of perturbations emerges as the paramount control knob, with both FO and ZO trajectories synchronizing as V1 crosses a task-specific threshold tied only to V2.
Quantitative Theoretical Claims
Key claims established and supported by both derivation and experiment are:
Convergence error between FO and ZO eNTK is provably independent of parameter dimension V3, scaling as V4.
The variance in learning dynamics across tasks is output-size dependent—larger V5 necessitates proportionally larger V6 for high-fidelity ZO finetuning, but even very large LLMs do not require increases to V7 once V8 is matched.
Common perturbation distributions (Gaussian, Rademacher) exhibit equivalent performance in high-dimensional settings, consistent with the universality of JL-projection guarantees.
Practical and Theoretical Implications
Practically, this work demonstrates why ZO optimization, long considered inefficient for high-dimensional models, is in fact highly scalable for LLM finetuning and other regimes where the Jacobian’s relevant output space is small-to-moderate. The unification of learning trajectory analysis with kernel machinery offers new design criteria for ZO hyperparameters: perturbation count V9 should be set according to output dimension P0 and task tolerance, independent of parameter count.
Theoretically, the kernel-based perspective opens multiple avenues for analysis and algorithmic improvement. The framework naturally accommodates extensions to alternative derivative-free approaches, offers principled metrics for comparing ZO and FO optimizers, and can be generalized to other non-gradient-based learning paradigms.
Trade-offs, Limitations, and Future Extensions
The primary trade-off remains compute cost: increasing P1 linearly increases forward queries, with potential memory bottlenecks when amortizing perturbations over large batches on GPU hardware. The JL-based theory does not yet capture compounding errors in multi-step or autoregressive generation tasks with growing effective output spaces. Moreover, the dimension-free property is contingent on the stability of the eNTK; in chaotic pre-training or high-feature-learning regimes, kernel drift may degrade ZO trajectory mimicry.
Future technical directions include extending the kernel approximation to non-stationary (feature-learning) regimes, developing efficient parallel architectures for large-P2 ZO, and adapting the analysis to tasks with dynamic or adaptive output spaces.
Conclusion
By reframing ZO optimization as a learning dynamics problem in function space, projected into random subspaces, this work provides theoretical and empirical clarity regarding the dimension-independence of ZO learning for LLM finetuning. The essential bottleneck is output size, and trajectory fidelity is governed by perturbation budget rather than parameter dimensionality. The kernel-based framework stands to inform both future theoretical insights and the engineering of practical, scalable derivative-free optimization methods for high-dimensional deep learning.