OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
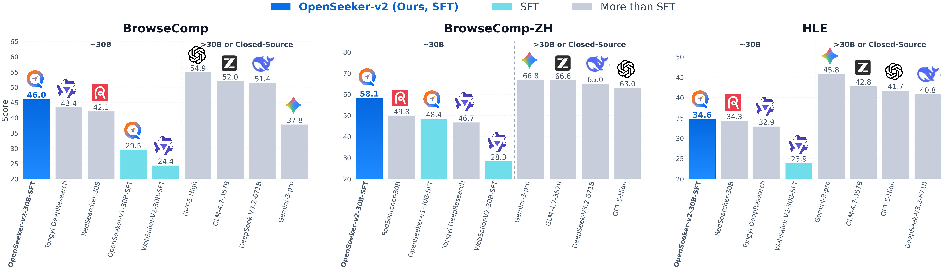
Abstract: Deep search capabilities have become an indispensable competency for frontier LLM agents, yet their development remains dominated by industrial giants. The typical industry recipe involves a highly resource-intensive pipeline spanning pre-training, continual pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL). In this report, we show that when fueled with informative and high-difficulty trajectories, a simple SFT approach could be surprisingly powerful for training frontier search agents. By introducing three simple data synthesis modifications: scaling knowledge graph size for richer exploration, expanding the tool set size for broader functionality, and strict low-step filtering, we establish a stronger baseline. Trained on merely 10.6k data points, our OpenSeeker-v2 achieves state-of-the-art performance across 4 benchmarks (30B-sized agents with ReAct paradigm): 46.0% on BrowseComp, 58.1% on BrowseComp-ZH, 34.6% on Humanity's Last Exam, and 78.0% on xbench, surpassing even Tongyi DeepResearch trained with heavy CPT+SFT+RL pipeline, which achieves 43.4%, 46.7%, 32.9%, and 75.0%, respectively. Notably, OpenSeeker-v2 represents the first state-of-the-art search agent within its model scale and paradigm to be developed by a purely academic team using only SFT. We are excited to open-source the OpenSeeker-v2 model weights and share our simple yet effective findings to make frontier search agent research more accessible to the community.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OpenSeeker‑v2, a computer “search agent” built on a LLM. A search agent is like a smart online detective: it plans steps, uses web tools (like search, open page, summarize), and pieces together information to answer complex questions. The big idea of the paper is that you can train a very strong search agent using a simple training method—if you give it the right kind of tough, informative practice problems.
What questions did the researchers ask?
- Can a search agent trained only with simple supervised practice (called SFT) become as good as, or better than, agents trained with much heavier and more expensive methods (like extra pre‑training and reinforcement learning)?
- If yes, what kind of training data makes that possible?
In short: Is “better practice” more important than “bigger training pipelines”?
How did they do it?
They focused on improving the quality and difficulty of the agent’s practice data rather than using complicated training tricks. Here’s how:
What is supervised fine‑tuning (SFT)?
Think of SFT like studying from worked examples. The model sees a question and a full, step‑by‑step solution and learns to imitate those good steps.
What is a “trajectory”?
A trajectory is the full trail the agent takes to solve a problem: its thoughts, each tool it uses (like a web search), what it sees from that tool, and how it moves to the next step—until it reaches the final answer. You can imagine it as a breadcrumb trail of a detective: think → act → observe → think → act → … → answer.
Key data improvements (the “better practice” part)
- Bigger information map (knowledge graph): Imagine giving the agent a larger map with more connected clues. By expanding the size of the information network used to create questions, the practice problems require multi‑step “hops” across different sources, not just a quick lookup.
- More tools in the toolbox: The agent gets more kinds of tools to use (for example, different ways to search, open, and process pages). This teaches it to pick the right tool for the right moment, like a mechanic with more than just a hammer.
- Filtering out easy problems (strict low‑step filtering): If a problem can be solved in just a couple of steps, it’s removed. Only problems that take a longer chain of actions are kept. This forces the agent to practice deep, careful research rather than quick wins.
They then trained a 30‑billion‑parameter model using only SFT on a relatively small but very challenging dataset: just 10.6 thousand high‑difficulty examples. The agent follows a “ReAct” style: it alternates between reasoning (“think”) and acting (“use a tool”), like a detective that plans, checks evidence, and plans again.
What did they find?
OpenSeeker‑v2 reached state‑of‑the‑art (SOTA) results among similarly sized, ReAct‑style search agents—despite using only simple SFT. On four tough benchmarks, it scored:
- BrowseComp: 46.0%
- BrowseComp‑ZH: 58.1%
- Humanity’s Last Exam: 34.6%
- xbench‑DeepSearch: 78.0%
These scores beat strong 30B‑scale competitors that used heavy, expensive training pipelines (including extra pre‑training and reinforcement learning). Two highlights:
- It outperformed Tongyi DeepResearch (which used CPT + SFT + RL) on all four benchmarks.
- It improved a lot over the team’s earlier version (OpenSeeker‑v1), showing the new data recipe really helped.
The training data itself was harder too: OpenSeeker‑v2’s practice trails averaged about 65 steps, much longer than earlier datasets. Longer trails encourage learning true long‑horizon search and reasoning—just like practicing longer math proofs helps you handle harder problems.
Why does it matter and what’s next?
- Importance: This work shows that data quality—especially informative, high‑difficulty practice—can matter more than complex and costly training tricks. That’s good news for schools, labs, and open‑source communities with fewer resources: with the right hard examples, they can train strong agents too.
- Impact: OpenSeeker‑v2 is the first academic, SFT‑only agent of its size and style to reach SOTA on these search benchmarks. The team also open‑sourced the model so others can build on it.
- What’s next: The authors plan to scale up the amount, diversity, and difficulty of their high‑quality synthetic data. If the trend continues, even stronger search agents could be trained simply by improving the “practice problems,” not by increasing training complexity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete items future work can act on:
- Data synthesis transparency: The paper omits critical details of the graph-based data generator (graph source/provenance, construction pipeline, entity/link schemas, coverage, update cadence, K expansion policy, negative sampling, deduplication), hindering reproducibility and auditability.
- Tool suite specification: The exact tool list, APIs/endpoints, capabilities (e.g., search, browse, summarization, citation), rate limits, auth requirements, and error/failure modes are not disclosed; results may be sensitive to these choices.
- Hyperparameters and training budget: SFT recipe lacks concrete settings (optimizer, learning rate schedule, batch size, tokens seen, steps/epochs, precision, gradient clipping, warmup, early stopping) and compute profile (GPUs/TPUs, hours, memory), impeding faithful replication.
- Evaluation protocol rigor: No report of decoding parameters (temperature, top-p, top-k), seeds, number of runs, or confidence intervals; no multi-run variance; significance testing versus baselines is absent.
- Cross-harness comparability: Baseline numbers are collected from different sources without normalizing tools, browsers, time limits, or environments; a controlled A/B evaluation under a shared harness is missing.
- Live-web confounds: Benchmarks depend on changing web content; there is no frozen snapshot evaluation or temporal robustness analysis to ensure results are stable over time.
- Contamination checks: The paper does not audit overlap between training data (synthetic or base-model pretraining) and benchmark items, URLs, or answers; formal contamination detection and mitigation are missing.
- Difficulty proxy validity: Using minimum step count (T_min) as a difficulty filter is unvalidated; no human review or quantitative evidence that longer trajectories correspond to genuinely harder reasoning rather than redundancy.
- Ablations on the three data modifications: No controlled study that independently varies graph expansion K, tool set size |A|, and T_min to quantify each component’s marginal contribution and interactions.
- Data scaling laws: Only a single dataset size (10.6k) is reported; the relationship between data quantity/difficulty/diversity and performance remains unknown (e.g., diminishing returns, optimal T_min/K).
- Topic and structure diversity: No analysis of topical coverage, multi-hop depth distribution, evidence dispersion, or linguistic variety across the synthetic set to verify breadth and reduce overfitting to a narrow regime.
- Search efficiency trade-offs: The approach favors long trajectories, but there is no study of efficiency metrics (steps, wall-clock time, token and tool-call costs) or Pareto frontiers balancing accuracy and efficiency.
- Stop/termination policy: The agent’s stopping criterion is unspecified and unevaluated (e.g., over-searching or premature stopping rates, calibration of “enough evidence”).
- Robustness to tool failures: No experiments on resilience to network errors, timeouts, throttling, CAPTCHAs, paywalls, JS-heavy pages, redirects, or stale links; fallback strategies and recovery behaviors are untested.
- Source reliability and misinformation: There is no assessment of source credibility filtering, cross-source verification, or defenses against SEO spam and low-quality sites.
- Prompt-injection and adversarial content: The paper does not evaluate susceptibility to adversarial web content (malicious prompts/scripts) or propose mitigations.
- Citation faithfulness: There is no measurement of grounding quality (e.g., citation correctness, coverage, quote accuracy) or mechanisms for verifiable claims.
- Generalization beyond ReAct: It is unclear whether the SFT-only, data-centric recipe transfers to other paradigms (programmatic agents, planners, tool graphs, memory-augmented agents) or multi-agent settings.
- Base-model dependence: Results are shown only for Qwen3-30B-A3B-Thinking; portability to other base models (sizes, architectures, “non-thinking” variants) is untested.
- Multilingual breadth: Only English and Chinese benchmarks are covered; performance and data synthesis for low-resource languages and cross-lingual retrieval remain unexplored.
- Memory and context management: With a 256k window, there is no study of context pruning, memory modules, retrieval strategies, or sensitivity to context length limits and ordering.
- Safety and content moderation: The paper does not evaluate unsafe content handling, privacy/PII exposure, or policy compliance during open-web browsing.
- Error analysis: No qualitative or quantitative breakdown of failure modes (planning errors, tool misuse, hallucination, citation errors, entity resolution mistakes) to guide targeted improvements.
- Tool set design principles: The impact of adding/removing specific tools, tool redundancy, and tool-choice confusion is not analyzed; an automatic tool selection or pruning methodology is absent.
- Real-user tasks and human evaluation: Benchmarks are proxy tasks; there is no human evaluation of usefulness, readability, or user satisfaction, nor user-in-the-loop assessments.
- Cost accounting: Inference-time resource usage (tokens processed, tool-call costs, latency per task) and total cost-per-correct-answer are not reported; economic viability is unclear.
- Temporal adaptation: How to maintain performance as the web evolves (model drift, re-SFT cadence, continual learning without catastrophic forgetting) is not addressed.
- Combining SFT with light RL or preference optimization: The paper does not test whether modest RLHF/RLAIF or trajectory-level rewards improve efficiency, robustness, or calibration when layered atop the high-difficulty SFT data.
- Open-sourcing of data and harness: While weights are released, it’s unclear whether the synthetic dataset, data generator, and evaluation harness (including tool backend configs) are publicly available with enough detail to reproduce results.
- Formalizing “difficulty” and “richness”: Beyond trajectory length and graph-size heuristics, the work lacks a principled metric suite (e.g., evidence entropy, path ambiguity, compositional depth) to guide future data construction.
- Ethical and legal aspects of web use: Licensing, robots.txt compliance, and jurisdictional constraints for data collection and agent operation are not discussed.
- Stopgap vs. optimal K and T_min: There is no guidance for choosing K and T_min across domains; adaptive or curriculum strategies for tuning these parameters remain open.
- Calibration and uncertainty: The agent does not report confidence or rationale quality metrics; methods for confidence-calibrated answers and abstention policies are unexamined.
- Transfer to adjacent agent tasks: It is unknown whether the learned search behaviors transfer to GUI/desktop agents, scientific workflows, or code-oriented retrieval.
- Stability under long horizons: Risks of loops, cycling, or distraction in very long sessions are not measured; safeguards (loop detection, de-duplication) are unspecified.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging the open-sourced OpenSeeker-v2 model weights, its SFT-only training recipe, and its data synthesis insights.
- Evidence-grounded research copilot for the open web
- Sector(s): software, media/journalism, consulting, education
- Potential tools/products/workflows: browser extension or desktop app that wraps OpenSeeker-v2 with a ReAct-style tool suite (web search, page fetch, summarization, citation extraction), auto-generates research memos with linked sources, and logs multi-step trajectories for auditability
- Assumptions/dependencies: stable tool-call infrastructure (search APIs, headless browsers), rate limiting/crawl policies compliance, content licensing, source citation enforcement, human-in-the-loop review for critical claims
- Enterprise knowledge navigator for internal documentation
- Sector(s): enterprise software, knowledge management
- Potential tools/products/workflows: integration with Confluence/SharePoint/GDrive and enterprise search; agent executes long-horizon multi-hop retrieval across wikis, RFCs, tickets, and emails to answer complex “how/why/where” questions; exports answer plus provenance paths
- Assumptions/dependencies: secure connectors, access control/PII policy compliance, metadata-enriched indexing, audit logs, model hosting that meets IT governance requirements
- Academic literature review assistant and systematic review scaffolding
- Sector(s): academia, healthcare research, pharmaceutical R&D
- Potential tools/products/workflows: agent chain that queries scholarly search (e.g., CrossRef, PubMed), screens inclusion/exclusion, clusters evidence across multi-hop citations, drafts PRISMA-style summaries with traceable trajectories
- Assumptions/dependencies: API access or institutional subscriptions, rigorous citation handling, bias and hallucination checks, domain prompts/templates, expert review mandates for clinical contexts
- Regulatory and policy intelligence digests
- Sector(s): public policy, compliance (finance, healthcare, energy)
- Potential tools/products/workflows: continual monitoring of regulatory portals and trusted media; multi-hop synthesis of evolving rules, enforcement actions, and guidance; weekly memos with change logs and references
- Assumptions/dependencies: curated trusted sources, change-detection pipelines, jurisdiction scoping, legal review before actioning, audit trails for decisions
- Competitive landscape and due-diligence scanning
- Sector(s): finance, venture capital, corporate strategy
- Potential tools/products/workflows: agent scans company websites, filings, product docs, patents, and news; produces feature matrices, timelines, and risk factors with linked evidence
- Assumptions/dependencies: access to structured data feeds (EDGAR, patent APIs), rigorous de-duplication and source quality filters, compliance with insider-information and market-abuse regulations
- Customer support knowledge-base “deep search”
- Sector(s): customer support, SaaS
- Potential tools/products/workflows: agent navigates long troubleshooting trees and forum posts to propose multi-step resolutions with citations; pushes updates back to KB authoring pipelines
- Assumptions/dependencies: connectors to ticketing systems and forums, content freshness and versioning, deflection analytics, safety policies for user-data handling
- Journalism fact-checking accelerator
- Sector(s): media
- Potential tools/products/workflows: multi-hop verification across primary sources; automatic claim decomposition, source cross-corroboration, and contradiction flags with evidence trails
- Assumptions/dependencies: curated source whitelists/blacklists, misinformation heuristics, editorial approval workflows, strong provenance logging
- Engineering troubleshooting and “design rationale” retriever
- Sector(s): software, hardware, robotics
- Potential tools/products/workflows: agent traverses issues, PRs, design docs, standards, and forums to explain root causes or prior decisions; outputs ranked hypotheses and cites artifacts
- Assumptions/dependencies: repo and documentation access, code/issue indexing, credentials management, IP protection
- E-commerce and consumer “deep product research”
- Sector(s): e-commerce, consumer apps
- Potential tools/products/workflows: long-horizon comparisons across manuals, reviews, certifications, and forums; generates side-by-side feature/performance summaries with source links
- Assumptions/dependencies: anti-scraping and ToS compliance, affiliate/advertising policy transparency, deduplication and review-spam filtering
- Open, low-compute training recipe for domain-specific agents
- Sector(s): AI tooling, education, small labs/startups
- Potential tools/products/workflows: replicate the paper’s SFT-only recipe with high-difficulty trajectories for niche domains (e.g., biotech IP, standards engineering); “High-Difficulty Data Synthesizer” service implementing expanded graphs, larger toolsets, and low-step filtering
- Assumptions/dependencies: domain knowledge graphs or corpora, domain tool adapters, modest compute for 30B hosting or parameter-efficient finetuning, data quality controls
- Benchmarking and agent evaluation harness
- Sector(s): AI research, MLOps
- Potential tools/products/workflows: incorporate BrowseComp/BrowseComp-ZH/HLE/xbench runs into CI pipelines; log trajectory complexity metrics (steps, tool diversity) to monitor regressions
- Assumptions/dependencies: reproducible eval setup, deterministic tool responses or caching, content masking to prevent leakage
Long-Term Applications
The following applications are promising but likely require further research, domain adaptation, scaling, or additional safeguards before reliable deployment.
- Domain-certified clinical evidence agents (systematic updates to guidelines)
- Sector(s): healthcare
- Potential tools/products/workflows: agent continuously aggregates RCTs, meta-analyses, and regulatory safety notices; drafts change proposals to clinical guidelines with uncertainty and evidence grading
- Assumptions/dependencies: stringent medical safety, expert oversight, liability frameworks, access to paywalled literature, factuality and bias guarantees, post-market surveillance integration
- Legal e-discovery and precedent synthesis at scale
- Sector(s): legal
- Potential tools/products/workflows: multi-hop search over case law, dockets, statutes, and briefs; argument maps with citations and counter-arguments; predictive relevance triage
- Assumptions/dependencies: comprehensive legal databases, privilege and confidentiality controls, jurisdiction-aware reasoning, explainability and defensibility standards
- Financial forensics and AML/KYC investigations
- Sector(s): finance
- Potential tools/products/workflows: agents trace entities across sanctions lists, corporate registries, leaks, and news; generate risk narratives and supporting evidence trees
- Assumptions/dependencies: high-precision entity resolution, regulated-data access, low false-positive rates, auditability for regulators, robust temporal reasoning over stale/updated sources
- Multimodal deep research (text + tables + figures + PDFs + video)
- Sector(s): software, education, science publishing
- Potential tools/products/workflows: tools for table extraction, chart-to-data, PDF structure parsing, and video chaptering combined with multi-hop reasoning; “evidence boards” linking modalities
- Assumptions/dependencies: reliable multimodal parsers, dataset expansion to multimodal trajectories, new tool APIs, evaluation protocols for cross-modal grounding
- Research OS: Agentic browser/workstation for long-horizon investigation
- Sector(s): productivity software, operating systems
- Potential tools/products/workflows: a “Research OS” that unifies browsing, note-taking, citation management, memory, and experiment tracking with agentic orchestration; team collaboration on shared trajectories
- Assumptions/dependencies: robust AgentOps (logging, replay, diffing), versioned memories, permissioning, cost management for long contexts, UX for human-agent co-editing
- Cross-lingual and low-resource knowledge exploration
- Sector(s): global education, journalism, international policy
- Potential tools/products/workflows: multilingual tool adapters and cross-lingual citation alignment; auto-translation pipelines for sources and queries; localized research digests
- Assumptions/dependencies: high-quality multilingual pretraining or adaptation, region-specific source curation, cultural/linguistic evaluation sets, fairness considerations
- Autonomous knowledge-graph construction and upkeep
- Sector(s): data platforms, search, enterprise intelligence
- Potential tools/products/workflows: agents that continuously mine the web and internal docs to build/refresh domain KGs; use expanded-graph synthesis to create harder training trajectories, bootstrapping better agents
- Assumptions/dependencies: deduplication, canonicalization, entity/relation validation, provenance and licensing, drift monitoring
- Collaborative agent swarms for peer review and verification
- Sector(s): academia, policy, safety
- Potential tools/products/workflows: multi-agent debate/verification where agents independently seek evidence, reconcile contradictions, and escalate to human arbitration on contentious claims
- Assumptions/dependencies: coordination protocols, diversity of tools/models to reduce correlated errors, cost controls, formal verification or consensus criteria
- Safety-first “evidence gated” generation in high-stakes workflows
- Sector(s): healthcare, legal, public administration, energy
- Potential tools/products/workflows: generation pathways that cannot produce final outputs without meeting evidence sufficiency thresholds (minimum tool-call steps, provenance coverage, contradiction checks)
- Assumptions/dependencies: policy-defined gates and thresholds, reliable source quality scoring, override/escalation mechanisms, certification processes
- Standardized trajectory-quality metrics and audits
- Sector(s): AI governance, MLOps
- Potential tools/products/workflows: industry standards for measuring trajectory difficulty (steps, branching, tool diversity), informativeness, and provenance density; audit services for agent deployments
- Assumptions/dependencies: shared benchmarks/datasets, consensus on metrics, reproducible tool environments, third-party evaluators
- Extending SFT-only recipe to other agent verticals (GUI, data analysis, cybersecurity)
- Sector(s): robotics/software UI, analytics, security
- Potential tools/products/workflows: curate high-difficulty, tool-rich trajectories (e.g., multi-app GUI automation, multi-dataset analytics pipelines, layered threat-hunting); train SFT-only agents with strict low-step filtering for long-horizon skills
- Assumptions/dependencies: domain-specific tool ecosystems and simulators, safety sandboxes, realistic and diverse trajectory synthesis, domain benchmarks
Notes on feasibility across applications:
- Core enablers from the paper: informative, high-difficulty trajectories via expanded graphs, larger toolsets, and strict low-step filtering; SFT-only training that reduces compute/data barriers; open weights for a ~30B ReAct agent with long context.
- Common constraints: tool/API reliability, content access rights, cost/latency of long trajectories, need for provenance, robustness to web drift and adversarial content, and human oversight for high-stakes domains.
Glossary
- Activated parameters: The subset of model parameters that are actually used during inference in sparsely activated architectures. "3B activated parameters during inference"
- Agentic: Describing systems or benchmarks focused on autonomous, goal-directed agents. "five challenging agentic benchmarks"
- Continual Pre-Training (CPT): Additional pre-training on new or domain-specific data after initial pre-training to adapt or extend model capabilities. "continual pre-training (CPT)"
- Context management: Techniques for organizing and controlling long or dynamic contexts during multi-step tasks. "context management"
- Context window: The maximum amount of text (tokens) a model can attend to at once. "256k context window"
- Data synthesis: The process of programmatically generating training examples or trajectories. "data synthesis modifications"
- Evidence aggregation: Combining information from multiple sources to support an answer or conclusion. "require evidence aggregation over multiple nodes"
- Evidence subgraph: A subgraph containing nodes/edges that provide supporting evidence for a query. "a larger evidence subgraph:"
- Expansion budget: A parameter controlling how far a graph is expanded around a starting node during data generation. "increase the expansion budget"
- Knowledge graph: A structured graph of entities and relations used to organize source information. "scaling knowledge graph size for richer exploration"
- Long-horizon: Involving many sequential steps of reasoning or action over extended contexts. "long-horizon search and reasoning abilities"
- Multi-hop exploration: Navigating across multiple connected nodes or sources to find and integrate information. "deep, multi-hop exploration"
- Multi-step: Involving multiple sequential actions or reasoning steps within a trajectory. "multi-step ReAct-style trajectory:"
- Observation: The output returned by a tool call that the agent perceives and uses for subsequent decisions. "observation returned by the invoked tool."
- ReAct paradigm: An agent framework that interleaves reasoning (thoughts) and acting (tool calls). "ReAct paradigm"
- Reasoning trace: The explicit chain-of-thought or rationale produced before each action. "represents the reasoning trace before each action."
- Reinforcement Learning (RL): A training approach where agents learn by receiving rewards for their actions. "reinforcement learning (RL)"
- Seed node: The initial node in a graph from which expansion or task synthesis begins. "For each seed node"
- Source graph: The original graph from which tasks and evidence are derived during synthesis. "source graph used for task synthesis."
- State-of-the-art (SOTA): The best performance achieved among comparable systems at a point in time. "state-of-the-art (SOTA) performance"
- Strict low-step filtering: A data filtering criterion that removes trajectories solvable in too few steps to ensure minimum difficulty. "Strict low-step filtering."
- Supervised Fine-Tuning (SFT): Training a model on labeled examples to mimic desired outputs. "supervised fine-tuning (SFT)"
- Tool call: An invocation of an external function or service by the agent within a trajectory. "a tool call"
- Tool-call steps: The count of actions within a trajectory that invoke tools. "too few tool-call steps."
- Tool set: The collection of available tools/actions an agent can choose from. "tool set size"
- Topological graph: A graph viewed in terms of the connectivity structure among nodes. "topological graph size"
- Trajectory: The sequence of reasoning steps, actions (tool calls), and observations leading to an answer. "The trajectory consists of tool-call steps,"
- Subgraph: A subset of a graph’s nodes and edges forming a smaller graph. "local subgraph"
Collections
Sign up for free to add this paper to one or more collections.

