- The paper develops an open, end-to-end data and RL training recipe for building robust multimodal search agents.
- It introduces a scalable data curation pipeline that synthesizes high-quality multi-hop VQA trajectories using both visual and textual cues.
- OpenSearch-VL achieves significant accuracy improvements over prior models by leveraging tool-interleaved, agentic reasoning strategies.
OpenSearch-VL: An Open Recipe for Frontier Multimodal Deep Search Agents
Introduction and Motivation
OpenSearch-VL targets a key bottleneck in the development of high-performance multimodal search agents: the lack of transparent, reproducible, and high-quality data and training recipes for agentic multimodal reasoning systems. Existing state-of-the-art models for knowledge-intensive visual question answering (VQA) and web-based multimodal reasoning have largely relied on proprietary datasets, closed tool trajectories, and private codebases, limiting the community's ability to replicate, analyze, or extend these frontier systems. OpenSearch-VL proposes an open, end-to-end training recipe that systematically addresses these gaps by releasing datasets, agentic RL training protocols, and code, with demonstrated state-of-the-art performance on complex multimodal deep search tasks.
Data Curation Pipeline
The core of OpenSearch-VL is its scalable data curation pipeline, which synthesizes high-quality, multi-turn, multi-hop VQA trajectories tailored to tool-demanding reasoning over both visual and textual evidence. The pipeline proceeds through three key stages:
- Multi-hop VQA Instance Construction: Starting from the Wikipedia hyperlink graph, the system samples constrained entity paths, generates canonical and fuzzified question–answer pairs by rewriting entity mentions to prevent shortcut retrieval, and grounds anchor entities with CLIP-filtered representative images. This design enforces a compositional reasoning requirement, explicitly suppressing single-hop shortcut solutions and encouraging multi-hop, tool-interleaved behavior.
- Filtering and Visual Enhancement: The instance pool is refined through staged filtering to eliminate trivial, perceptual, or parametric-knowledge answerable samples. An enhancement subset is synthesized by degrading source images—via blur, distortion, and downsampling—and pairing them with image restoration tool-based solutions, incentivizing the agent to engage in “think-with-image” behavior under real-world visual imperfections.
- Trajectory Synthesis: Expert multi-turn trajectories are generated by rolling out Claude Opus 4.6 against the constructed environment, invoking all tools as required. Trajectories are then passed through a two-stage rejection filtering: final-answer correctness (via GPT-4o) and a process-level judge (via GPT-5.4) scoring logical, tool-use, and non-repetitive behavior.
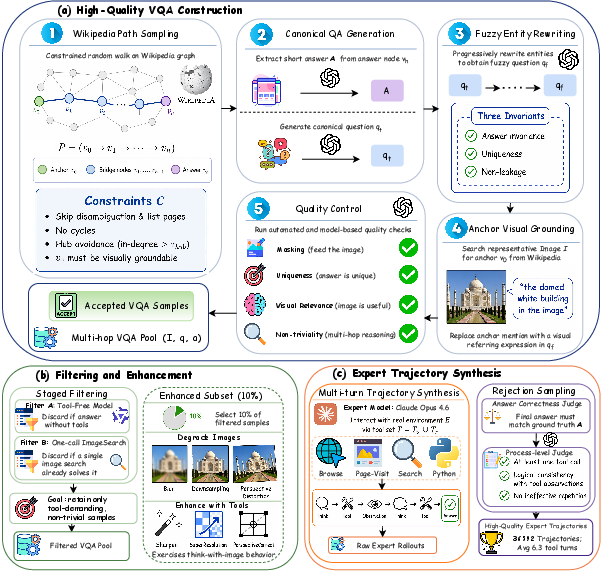
Figure 1: Overview of the data curation pipeline, illustrating the construction of high-quality multi-hop VQA data, staged filtering, and trajectory synthesis in a real tool environment.
Two primary datasets result: SearchVL-SFT-36k (for supervised fine-tuning) and SearchVL-RL-8k (for RL-based exploration).
One distinctive strength of OpenSearch-VL is its unified, extensible tool suite, which supports agentic, iterative reasoning strategies that span both visual and textual input spaces. The tool environment is partitioned into three modality families:
- Retrieval Tools: TextSearch (web search with summarization) and ImageSearch (reverse image search and entity recognition) for explicit knowledge acquisition.
- Image Enhancement Tools: Sharpen, SuperResolution, and PerspectiveCorrect to address real-world image noise, blurring, low resolution, and perspective errors.
- Attention & Parsing Tools: Crop (for spatial localization) and OCR (for layout-aware text extraction).
This environment empowers agents to go beyond pure retrieval. They can actively repair, manipulate, and parse images before attempting knowledge-based queries, addressing inherent limitations of prior retrieval-focused agentic architectures.
Training Algorithm: Fatal-Aware Multi-turn RL
OpenSearch-VL introduces a novel multi-turn Group Relative Policy Optimization (GRPO) algorithm, specifically adapted for long-horizon, multi-tool agentic interaction with a real multimodal environment. This RL protocol incorporates several vital innovations:
- Composite Multi-turn Reward: The RL reward integrates final-task accuracy (via LLM judge), process-level search quality (GPT-5.4), and strict format compliance, providing dense, credit-assigned feedback for both successful and partially-successful rollouts.
- Fatal-Aware Masking: To prevent noisy gradient signals from cascading execution failures (e.g., repeated tool errors), a fatal-aware token mask truncates the learning signal at the point of sustained failures, preserving only the valid prefix of reasoning and tool-use steps before fatality.
- One-Sided Advantage Clamping: Unlike hard-masking/trajectory-drop baselines, one-sided clamping ensures that viable pre-failure prefixes can still yield positive gradient updates if their normalized reward exceeds the group mean, avoiding unnecessary suppression of productive partial behaviors.
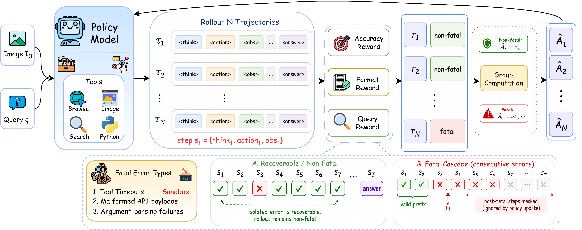
Figure 2: Overview of the RL training pipeline, sampling trajectories, applying composite rewards, and using fatal-aware masking for stable multi-turn policy optimization.
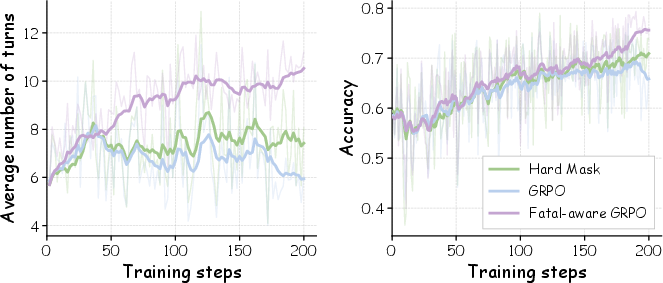
Figure 3: Training dynamics over the RL phase. Fatal-aware GRPO sustains a higher number of turns and reaches higher accuracy compared to alternatives.
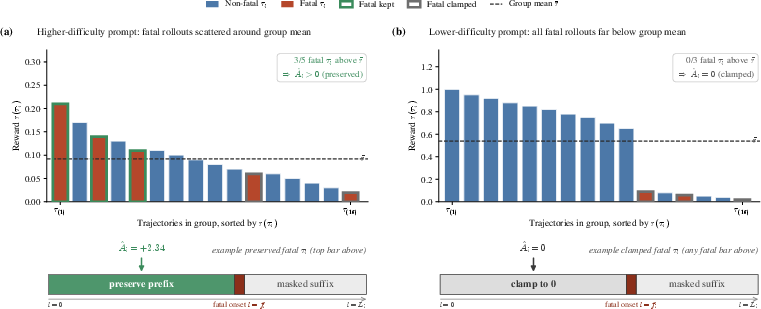
Figure 4: Fatal-aware masking with one-sided clamping illustrated on rollouts. Productive prefixes of fatal trajectories are positively reinforced when group-normalized rewards are high.
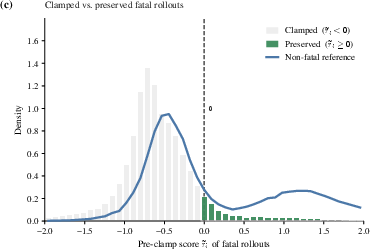
Figure 5: Aggregate distribution showing that most fatal rollouts are clamped to zero, while those with high partial rewards are preserved, mirroring successful non-fatal rollout behavior.
Numerical Results and Ablation
Comprehensive evaluation across seven challenging multimodal deep search benchmarks demonstrates robust, scalable improvements for OpenSearch-VL, including:
- Qwen3-VL-30B-A3B model improves average accuracy from 47.8 to 61.6 (a +13.8 point margin over the prior strongest open source agent) and achieves individual gains of +13.3 (VDR), +24.5 (MMSearch), +10.2 (FVQA), and +16.2 (InfoSeek).
- The largest model, OpenSearch-VL-32B, attains 63.7 average accuracy, exceeding both direct-reasoning baselines and competing with leading proprietary commercial systems.
Extensive ablation studies on the SFT data pipeline and RL recipe show:
- Removal of core data pipeline stages (fuzzy rewriting, source-anchor decoupling, staged filtering) causes large performance drops (−8 to −14 points), demonstrating that both search chain compositionality and tool requirement are critical.
- Replacing fatal-aware GRPO with vanilla RL or hard-masking suppresses the benefits of partially successful exploration, validating the importance of the proposed RL objective.
Agent Trajectory Case Study
An illustrative OpenSearch-VL trajectory demonstrates compositional, tool-interleaved reasoning answering “In what year did this bridge open?”:
Theoretical and Practical Implications
OpenSearch-VL offers a comprehensive, open recipe for developing frontier multimodal deep search agents, providing both the data generators and RL training APIs needed for scalable, reproducible research. The ablation findings and benchmark performance underline that advanced multimodal search capability depends on i) staged, shortcut-minimizing, tool-demanding data; and ii) long-horizon RL algorithms robust to cascading failures and partial success.
Practically, OpenSearch-VL establishes a transparent reference for future studies into agentic reasoning, RL-driven tool use, and search-based retrieval under visually noisy and knowledge-intensive scenarios. Theoretically, it enables systematic analysis of how data, tool orchestration, and reward design interact to produce emergent agentic search behavior in large multimodal models.
Future Directions
Despite its strengths, OpenSearch-VL still contends with issues such as external tool reliability, judge-dependence for reward assignment, and challenges in exact experimental reproducibility owing to third-party API drift. Continuous work is warranted on fully open reward models, internalized perception-retrieval pipelines, robustness to tool malfunctions, and scaling (in both model and tool diversity). The open nature of the released data, code, and models is intended to catalyze broad community research on next-generation agentic multimodal systems.
Conclusion
OpenSearch-VL advances the standard for open development of multimodal search agents by delivering both substantive engineering (data generation, tool APIs, RL algorithms) and empirically-strong, carefully-validated results. Its release lowers the entry threshold for systematic research and benchmarking, powering progress in agentic multimodal intelligence for complex, visually-grounded retrieval and reasoning (2605.05185).
