- The paper introduces BEACON, a framework that partitions trajectories using observable milestones to improve credit assignment in long-horizon tasks.
- The paper leverages temporal reward shaping and dual-scale advantage estimation to boost sample efficiency and reduce erroneous credit distribution.
- Empirical results on ALFWorld and similar tasks show significant performance gains, including a 73.6% improvement over GRPO and more stable training dynamics.
Milestone-Guided Policy Optimization for Long-Horizon Language Agents
Introduction
The training of LLM agents for long-horizon tasks with compositional structures and sparse terminal rewards is impeded by two critical challenges: credit misattribution and sample inefficiency. Standard trajectory-level policy optimization approaches, such as GRPO and PPO, aggregate reward signals over full trajectories, disregarding the granular structure available in these tasks. This results in the penalization of correct early actions when later steps fail, and in a lack of learning signal from trajectories that achieve meaningful subgoals but ultimately do not succeed. "Milestone-Guided Policy Learning for Long-Horizon Language Agents" (2605.06078) introduces BEACON, a framework leveraging observable milestones to partition trajectories and anchor credit assignment, directly addressing these challenges.
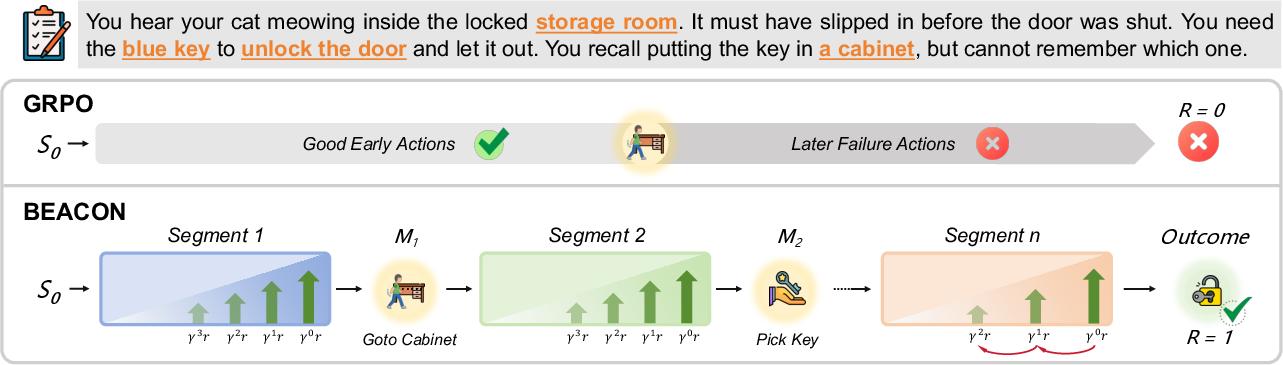
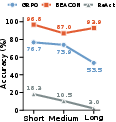
Figure 1: BEACON overview and performance preview, illustrating the difference between trajectory-level and milestone-level advantage estimation, and the robust performance scaling of BEACON compared to GRPO across task horizons.
Failures in Flat Trajectory Optimization
Conventional group-based reinforcement learning methods apply advantage estimation at the level of entire trajectories, which leads to two observable phenomena as task horizons increase:
- Sample Inefficiency: Most sampled episodes, particularly in sparse-reward environments, yield zero reward unless the terminal objective is achieved, discarding valuable experience from partial successes.
- Credit Misattribution: All actions in a trajectory share the same advantage, causing actions that were correct up to a point to be penalized if subsequent steps result in failure. Empirically, Contradictory Action Ratio (CAR) exceeds 40% on long-horizon tasks, and effective gradient signal collapses.
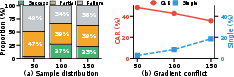
Figure 2: Failures of trajectory-level optimization: partial successes yield zero gradient and high gradient conflict, massively reducing learning signal.
The study presents a quantitative breakdown on ALFWorld, confirming that a considerable portion of trajectories (39–47%) are partial successes that do not contribute to policy improvement in traditional RL training.
The BEACON Framework
BEACON introduces a three-stage method for leveraging compositional structure:
- Trajectory Partitioning: Trajectories are segmented at milestone boundaries, such as subgoal completions, using a lightweight environment-derived indicator Φ. This segmentation is justified by the Milestone Markov Property: future segments are nearly conditionally independent given the current milestone.
- Temporal Reward Shaping: Within each segment, rewards are assigned to every action leading up to a milestone, decayed by a factor γ as the actions are further from the subgoal. This increases credit density for partial progress towards milestones and promotes efficient execution.
- Dual-Scale Advantage Estimation: Advantages are computed at two scales:
- Trajectory-level: As in standard GRPO, using the group distribution of total returns.
- Segment-level: Within milestone-matched groups, isolating local action contributions from noise seeded by future stochasticity in downstream segments. The total advantage is a combination of both, weighted by λ.
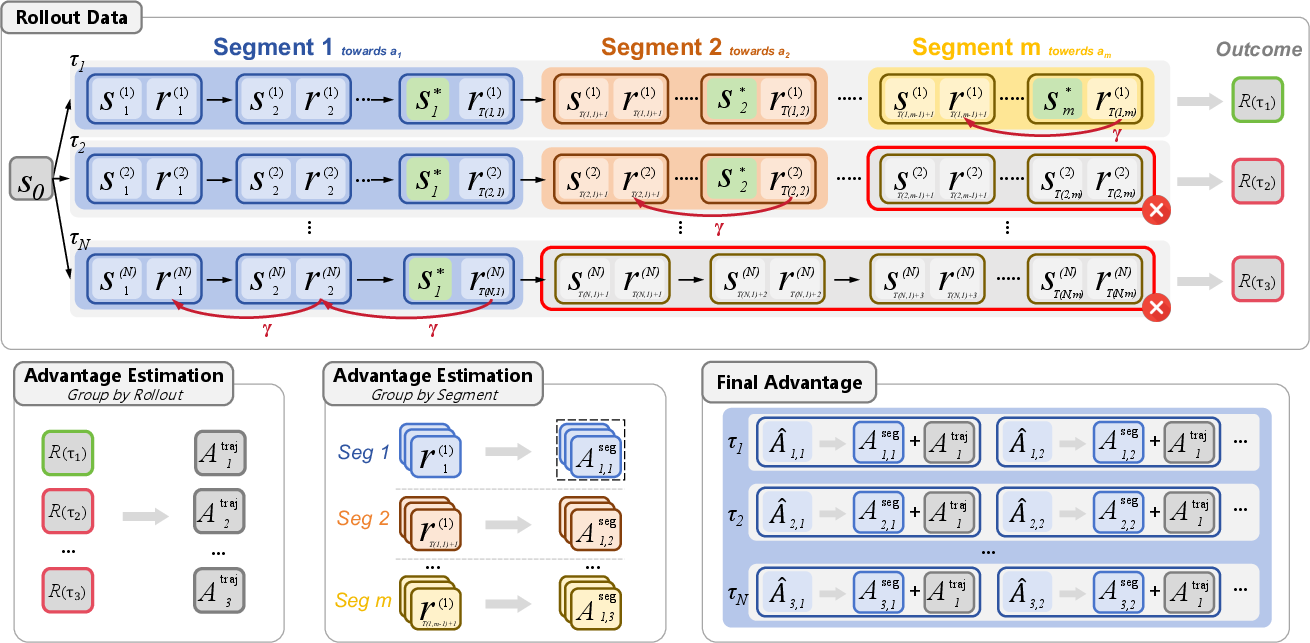
Figure 3: The BEACON framework: partitioning trajectories into segments at observed milestones, temporal decayed reward assignment, and dual-scale (trajectory, segment) advantage estimation for robust credit assignment.
Theoretically, segment-level advantage estimation isolates variance: gradient for actions in segment k is not affected by outcomes in k′>k under the Milestone Markov assumption. This results in much more precise and consistent credit assignment.
Empirical Evaluation
Experiments are conducted on ALFWorld, WebShop, and ScienceWorld, comparing BEACON to closed-source API LLMs (GPT-4o, Gemini-2.5-Pro), zero-shot/cot prompting (ReAct, Reflexion), and a suite of RL optimizers (PPO, GRPO, GiGPO, RLOO).
Main Results
BEACON achieves state-of-the-art results on all evaluated tasks and model sizes:
- ALFWorld (1.5B): 92.9% success on long-horizon tasks (vs. 53.5% for GRPO).
- Sample Utilization: Effective sample utilization increases from 23.7% (GRPO) up to 82.0% (BEACON).
- Horizon Scaling: BEACON's gains amplify with longer horizons, with a 73.6% improvement over GRPO on ALFWorld’s long-horizon set.
Analysis of Credit Assignment and Optimization Dynamics
Sample Efficiency
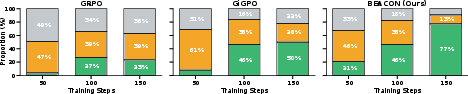
Figure 4: Distribution of trajectory types during training, showing that BEACON transforms partial successes from wasted samples into effective learning signals.
Milestone-anchored feedback allows gradients to be computed for partial successes, which constitute a significant portion of experience in long-horizon tasks.
Gradient Starvation and Horizon Scaling

Figure 5: (a) Zero-Advantage Ratio during training, rapidly reduced under BEACON; (b) Increasing performance advantage over GRPO with horizon length.
Credit assignment under BEACON dramatically reduces the fraction of samples receiving zero reward and increases effective gradient magnitudes.
Credit Distribution
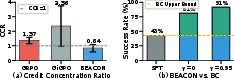
Figure 6: (a) Credit Concentration Ratios indicate BEACON’s more balanced credit allocation; (b) BEACON outperforms behavior cloning, even when oracle milestone trajectories are available.
BEACON does not simply clone behavior at milestones; its policy optimization procedure leads to more efficient and robust strategies, as evidenced by consistent outperformance of supervised finetuning.
Training Dynamics
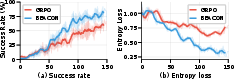
Figure 7: (a) Success rate learning curves showing BEACON’s faster convergence; (b) BEACON's policy entropy decreases smoothly, indicating stable policy refinement.
More consistent and aligned learning signals result in faster and more stable training.
Trajectory-Level Credit Case Study

Figure 8: BEACON accurately credits milestone completions, precisely penalizing errors and inefficiencies, contrary to GRPO and GiGPO.
BEACON’s local credit assignment can distinguish not only success or failure, but also penalize detours and reward efficient segment completions.
Ablations and Sensitivity
Experiments with degraded milestone detection (random partitions, milestone dropout) show that BEACON's performance remains robust when using imperfect or noisy segmentation, but the benefit stems primarily from leveraging true compositional structure. Temporal reward shaping with decay is also critical: removing it reduces performance, especially if credit is distributed uniformly.
Implications, Limitations, and Future Directions
The results yield two principal implications for RL-based agent training:
- Practical: Automated or domain-informed milestone extraction enables more efficient RL training on sparse-reward, long-horizon tasks even without dense reward engineering or expensive annotation.
- Theoretical: The Markovian assumption needed for variance isolation is generally approximately valid in compositional tasks but may be violated if resources or side effects persist across segments.
Limitations include reliance on the availability and granularity of milestones, and the potential for diminishing segment-level group sizes in highly diverse or stochastic environments. Future directions should investigate automated milestone discovery via unsupervised representation learning, application to continuous control, and hierarchical or nested milestone structures.
Conclusion
BEACON introduces a principled, compositional approach for credit assignment in long-horizon RL for language agents, partitioning on observable milestones and combining local and global feedback. This design mitigates credit misattribution and sample inefficiency endemic to existing trajectory-level optimizers. BEACON achieves significant performance and sample-efficiency gains across diverse agentic settings, establishing milestone-anchored policy learning as a dominant paradigm for training language agents in sparse-reward, compositional domains.

