On Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
Abstract: LLMs have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the paper
1) What is this paper about?
This paper studies how well LLMs can act like “agents” that take many steps in a row to finish a task (like solving a puzzle move by move). The main idea they focus on is the task’s “horizon,” which means how many steps it takes to reach the goal. They show that longer horizons (more steps) make training unstable and much harder, even when the thinking required stays the same. They also show simple ways to shorten the number of steps during training so models learn better and still handle long tasks later.
2) What questions are the researchers asking?
They ask three main questions:
- Does making a task longer (more steps) by itself make training LLM agents fail, even if the task isn’t “harder” to think about?
- Can we reduce the number of steps during training (without changing the goal) to make learning stable and stronger?
- If we train on shorter versions of a task, will the model still work well on longer versions later (horizon generalization)?
3) How did they study it?
To keep things fair, they build “controlled” tasks where the rules and reasoning are the same, but the number of steps needed changes.
- Tasks used: text-based Sudoku and the Rush Hour sliding car puzzle. Text-only versions avoid extra complications like vision.
- Keeping thinking difficulty constant: They pick Sudoku puzzles that all use the same basic techniques. This way, the only big difference is how many moves are required (more empty cells = more moves).
- Checking raw ability: They also create a “short-horizon proxy” version where the model has to give the full solution in one shot. If the model can do this, it shows the model knows the rules and reasoning; any failures in the multi-step version likely come from the long horizon, not a lack of understanding.
- Training approach:
- First, they use supervised fine-tuning (SFT): the model copies good examples, learning basic behavior.
- Then, they use reinforcement learning (RL): the model practices by interacting and gets rewards for success.
- Simple view of RL: imagine a game where each move can lead closer or farther from the goal; the model tries moves, sees results, and updates what to try next.
- Two common RL problems they explain in simple terms:
- Exploration: trying enough different move sequences to find ones that work. In long tasks, good sequences are rare, so this gets very hard.
- Credit assignment: figuring out which steps were helpful or harmful when the reward arrives only at the end. In long tasks, this signal gets “spread thin,” making learning noisy.
- Horizon reduction tricks:
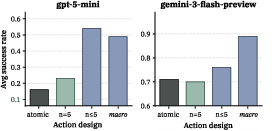
- Macro actions: let the agent take a “combo move” that does several small moves at once. Like typing several Sudoku fills in one turn, or moving a car multiple spaces in one instruction. This shrinks the number of steps.
- Subgoal decomposition: break a big goal into smaller checkpoints (e.g., finish one Sudoku subgrid at a time and give partial rewards). This shortens the learning chunks and gives clearer feedback.
4) What did they find, and why is it important?
Main findings:
- Longer horizons alone cause training to become unstable and often collapse, even when the puzzle’s thinking difficulty is unchanged. So horizon length is a true bottleneck.
- Why it collapses: exploration gets much harder (good sequences are rare), and credit assignment gets noisy (the model gets negative signals for entire long sequences, even if many steps were correct).
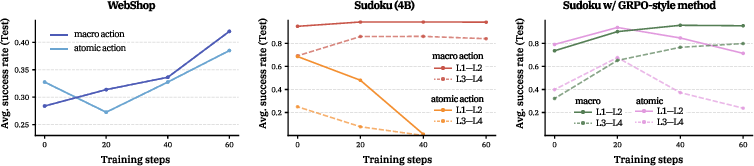
- Horizon reduction stabilizes learning and improves results:
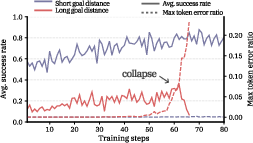
- Macro actions prevent collapse and boost performance across Sudoku and Rush Hour.
- Flexible macro actions (letting the agent decide how many small moves to bundle, up to a limit) beat fixed-length combos, which can be too rigid.
- Subgoal decomposition (giving partial, verifiable rewards) also prevents collapse and speeds learning.
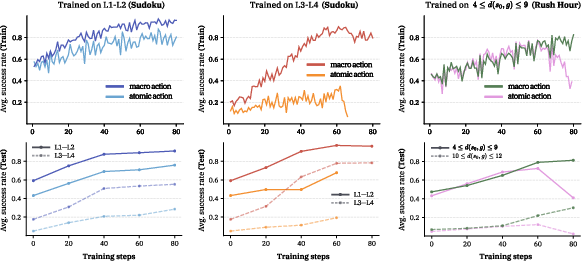
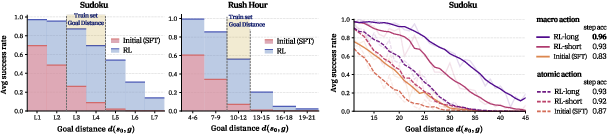
- Horizon generalization: models trained with shorter horizons often perform surprisingly well on longer horizons at test time. Two reasons:
- Higher per-step accuracy because training is more stable.
- Fewer total decision points (thanks to macro actions), so fewer chances to make a mistake.
- Robust across settings: These effects show up in different environments (like WebShop, a web task), larger model sizes, and different RL optimizers. So it’s not a fluke.
Why this matters:
- It shows that simply making tasks longer can break training, even for models that “know how” to solve the task in principle.
- It gives practical, simple tools (macro actions and subgoals) to make LLM agents more reliable on long tasks.
5) What could this change in the future?
Implications:
- Design agents to work with higher-level actions (like “combo moves”) and meaningful subgoals. This reduces the number of steps and makes training stable.
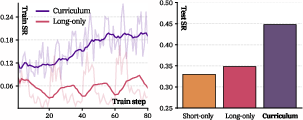
- Start with shorter horizons and use a curriculum (gradually lengthening tasks). Models can “generalize” from short to long horizons if trained well.
- Instead of only inventing more complicated RL algorithms, first reduce the effective horizon. It’s a simple, powerful lever for building dependable long-horizon agents.
- Better long-horizon agents could help with complex, multi-step real-world jobs (coding assistants, automation, scientific workflows). At the same time, stronger autonomous systems should be handled responsibly to avoid misuse.
Key terms in plain language:
- Horizon: how many steps it takes to finish a task.
- Exploration: trying different paths to find what works.
- Credit assignment: figuring out which specific steps helped or hurt the final result.
- Macro action: a “combo move” that bundles several small actions into one.
- Subgoal: a checkpoint or milestone on the way to the full goal.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of missing pieces, uncertainties, and unexplored directions that future work could address:
- Attribution of failure modes: The paper hypothesizes exploration difficulty and credit assignment as primary causes of collapse but does not disentangle or quantify their relative contributions across horizons.
- Theory of horizon scaling: No formal analysis of how gradient variance, success probability, or required step accuracy scale with goal distance or effective horizon; no bounds or scaling laws are provided.
- Token-level vs. environment-level horizons: The interaction between context length (token-generation horizon) and environment step horizon is not studied; it is unclear which dominates instability and when.
- Bias from task filtering: Filtering to instances solvable in a single step by the base model introduces selection bias; the effect of this bias on conclusions about “horizon-only” difficulty is unmeasured.
- Constancy of “reasoning complexity”: Although puzzles are verified as “basic,” there is no quantitative check that technique distributions or constraint interactions remain matched across horizons.
- Generalization beyond deterministic, fully verifiable tasks: Results center on deterministic puzzles with exact verifiers; behavior in stochastic, partially observable, or non-verifiable domains remains unclear.
- Extent of horizons tested: Evaluations cap at moderate horizons (e.g., ≤ ~45 atomic steps); behavior at substantially longer horizons (100–1000+ steps) is unknown.
- Automatic action abstraction: Macro actions are specified by design; methods to learn, discover, and refine macro actions/options automatically (and safely) are not explored.
- Safety/validity constraints for macro actions: Guarantees about preconditions, termination, and avoidance of unsafe or looping macros are not formalized or enforced.
- Trade-offs in macro design: Systematic analysis of overshooting, compounding error within a macro, and the optimal granularity/length distribution is missing.
- Subgoal discovery and verification: Subgoal decomposition relies on domain-verifiable subgoals (e.g., Sudoku subgrids); discovering subgoals and verifiers automatically in open domains is an open challenge.
- Process reward portability: The subgoal-based (process) reward design is domain-specific; how to construct transferable process rewards for tasks without programmatic checkers is unresolved.
- Horizon generalization scope: “Horizon generalization” is shown in closely related variants; transfer to tasks with different dynamics, semantics, or toolchains is untested.
- Curriculum design: Only a simple short-to-long curriculum is evaluated; optimal curricula, schedule sensitivity, and cross-task curriculum transfer remain unexplored.
- RL algorithm coverage: Experiments focus on REINFORCE-like and GRPO-style methods; whether value-based critics, advantage normalization variants, or return decomposition can mitigate horizon issues is not assessed.
- Off-policy correction robustness: The MIS/TIS scheme’s bias–variance trade-offs, clipping thresholds (C, Clow, Chigh) sensitivity, and stability regions are not analyzed or ablated.
- Reward shaping ablations: The step-level reward weight α is fixed (0.2); sensitivity to α, component-wise normalization choices, and their interaction with horizon length are unreported.
- Decoding effects: Temperature (0.8), sampling strategy, and pass@K settings may affect exploration and success; systematic decoding ablations are missing.
- Negative-advantage management: The hypothesized harmful effect of negative advantages is not tested with interventions (e.g., advantage clipping/asymmetry, filtered updates, or lower-bounding).
- Trajectory reuse and staleness: Quantitative measurement of policy staleness, reuse windows, and their impact on instability is not provided.
- Metrics for collapse detection: Reliance on “maximum-length response ratio” lacks validation; more robust early-warning indicators (entropy, KL to ref, step-error rates) are not established.
- Sample efficiency and compute: Compute cost, wall-clock efficiency, and sample efficiency across horizons and interventions are not reported, limiting practical guidance.
- Model scale and architecture: Only 1.7B/4B scales are tested; behavior at frontier scales and with architectures tailored for memory/recurrence remains unexamined.
- Memory and state abstraction: No investigation of external memory, state summarization, or plan-caching as alternative horizon-reduction mechanisms.
- Interaction budget vs. goal distance: The interplay between environment-imposed Hmax and intrinsic goal distance d(s0,g) is not systematically studied (e.g., infeasibility thresholds).
- Evaluation breadth: Success rate and pass@K are emphasized; calibration, stability under perturbations, and robustness to adversarial or noisy observations are not evaluated.
- Domain prior dependence: Sudoku leverages strong prior knowledge in LLMs; the extent to which results hold for domains with minimal prior exposure is unclear.
- Real-world tool use: Macro actions and subgoals are not validated in realistic tool-using agents (e.g., code execution with side effects, GUI automation with latency and failures).
- Option termination learning: Learning when to terminate a macro/subpolicy (rather than fixed-length or heuristic termination) is not explored.
- Joint training of abstraction and policy: Simultaneously learning action abstractions, subgoals, and control policies (e.g., hierarchical RL with learned options) is left open.
- Horizon-aware objectives: New objectives that explicitly regularize or penalize effective horizon (or reward step-accuracy at scale) are not proposed or tested.
- Formalizing action-granularity invariance: Definitions of goal distance d(s0,g) depend on atomic action choices; a horizon notion invariant across granularities is not provided.
- Failure case analysis: Qualitative error taxonomies (e.g., local constraint violations vs. global-plan drift) across horizons and interventions are not presented.
- Reproducibility assets: It is unclear whether datasets, generation scripts, macro/subgoal schemas, and verifier code are released for replication and extension.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage this paper’s findings on horizon length, horizon reduction (macro actions and subgoal decomposition), reward design, and training stability diagnostics.
- Software engineering — Stable training of code agents with macro-actions
- How it uses the paper: Apply horizon reduction by defining macro-actions such as “edit file → run tests → summarize failures” instead of step-by-step tool invocations; use subgoal decomposition for tasks like “localize bug → implement fix → add tests → refactor.”
- Potential tools/workflows:
- Macro-action schema library for common developer workflows (edit-build-test-deploy loops).
- RL post-training pipeline with off-policy REINFORCE and MIS/TIS weighting; reward decomposition into trajectory success and step-level formatting/validity.
- Training dashboard to monitor “maximum-length response ratio” as a collapse early-warning signal.
- Assumptions/dependencies: CI/test harness available; deterministic or replayable tool environment; lightweight validators for subgoal success (tests pass, linter OK).
- Web/RPA automation — More reliable multi-step browser and back-office agents
- How it uses the paper: Replace atomic click/keystroke sequences with macro-actions (e.g., “sign in,” “fill form + validate,” “check out”); add subgoal checkpoints (e.g., “cart updated,” “order submitted”).
- Potential tools/workflows:
- Macro-action compilers that translate UI/API sequences into higher-level primitives.
- Process reward hooks: DOM/state verifiers and API receipts as step-level rewards.
- Assumptions/dependencies: Stable selectors/APIs; subgoal verifiers (page title, HTTP 2xx, receipt IDs); logging for advantage estimation.
- Customer support and troubleshooting — Robust guided resolution flows
- How it uses the paper: Subgoal decomposition aligned with troubleshooting trees; macro-actions like “collect logs + parse + summarize anomalies.”
- Potential tools/workflows:
- Knowledge-backed subgoal checkers (issue reproduced, configuration validated).
- Offline RL fine-tuning with horizon curriculum (short → longer flows).
- Assumptions/dependencies: Access to diagnostic tools; reliable state checks; guardrails for escalation.
- Education — Tutors that scaffold long tasks via subgoals
- How it uses the paper: Decompose complex tasks (proofs, essays, projects) into verifiable milestones; reward models for process checks (outline, draft, revision).
- Potential tools/workflows:
- Curriculum generator that ramps intrinsic goal distance; macro-actions for “generate outline → source list → draft → review.”
- Assumptions/dependencies: Rubrics/automatic graders; plagiarism and citation checkers; teacher-in-the-loop validation.
- Healthcare operations (non-diagnostic workflow automation) — Macro-action order sets and documentation
- How it uses the paper: Horizon reduction via macro-actions (e.g., “initiate pre-op order set,” “complete discharge summary”) with subgoal verifiers (required fields, coding checks).
- Potential tools/workflows:
- EHR adapters exposing high-level APIs; step rewards based on schema validation and policy compliance.
- Assumptions/dependencies: Regulatory approval for automation scope; audit trails; clinical oversight; strict verification of subgoals.
- Finance back-office/KYC/compliance — Shorter effective horizons via checklists
- How it uses the paper: Break long onboarding/compliance processes into subgoals with verifiable criteria; macro-actions (“collect documents + OCR + validate”).
- Potential tools/workflows:
- Process reward validators (KYC checklist completion, sanction-screen pass).
- Assumptions/dependencies: Accurate document extraction; auditable logs; human review for edge cases.
- Robotics simulation and evaluation — High-level skill abstractions for stable training
- How it uses the paper: Use macro-actions (“grasp X,” “place Y”) rather than low-level controls; subgoal completion from sensor checks.
- Potential tools/workflows:
- Horizon curriculum from short pick-and-place to longer assembly sequences.
- Off-policy REINFORCE with truncated/masked IS to handle rollout reuse.
- Assumptions/dependencies: Reliable subgoal detectors; sim2real alignment; safety constraints.
- Productization infrastructure — “Horizon-aware” training and monitoring
- How it uses the paper: Standardize reward decomposition, batch-normalized rewards, importance sampling weighting, and collapse diagnostics.
- Potential tools/workflows:
- Horizon-reduction middleware that translates tool APIs into macro-actions.
- Evaluators that report effective horizon, goal distance coverage, step accuracy, and horizon generalization curves.
- Assumptions/dependencies: Telemetry for effective horizon; environment APIs supporting compound actions; reproducible sampling.
- Policy/governance in AI deployment — Horizon-aware evaluations and controls
- How it uses the paper: Add “effective horizon” and “horizon generalization” to evaluation checklists; require subgoal verifiers in long-horizon deployments; use curricula for staged rollout.
- Potential tools/workflows:
- Risk templates that flag high intrinsic goal distance without horizon reduction.
- Release gates tied to collapse indicators (e.g., long-response spikes).
- Assumptions/dependencies: Agreement on measurement protocols; low-cost evaluation suites; sector-specific compliance requirements.
- Daily life/personal productivity — More dependable assistants for multi-step tasks
- How it uses the paper: Macro-actions for “plan trip → hold flights → book hotel,” with subgoal confirmations; fewer steps reduce error accumulation.
- Potential tools/workflows:
- Checkpointed workflows with user confirmation as subgoal rewards.
- Assumptions/dependencies: API access to booking/services; explicit user approvals; reversible actions.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development (e.g., robust validators, domain standards, or broad tool support).
- Cross-domain process reward and subgoal libraries
- Vision: Curated, domain-specific subgoal ontologies and verifiers (healthcare, law, engineering) to enable dense rewards and segmented returns across complex tasks.
- Dependencies: High-precision validators, formalized schemas, and regulatory endorsement in sensitive domains.
- Marketplace and tooling for action abstraction
- Vision: Shared repositories of macro-action packs per platform (EHRs, CRMs, IDEs, ERP, browsers), enabling plug-and-play horizon reduction in agents.
- Dependencies: Stable vendor APIs; versioning and compatibility; safety and rollback mechanisms.
- Horizon-aware training standards and benchmarks
- Vision: Industry/academic benchmarks that fix reasoning difficulty while varying intrinsic goal distance; standardized metrics (effective horizon, horizon generalization, collapse risk).
- Dependencies: Community-led efforts; reproducible environments; reporting templates.
- Adaptive horizon curriculum and auto-abstraction
- Vision: Agents that learn to select macro granularity on the fly, shortening horizon when instability is detected; automatic subgoal discovery with verifiable checkers.
- Dependencies: Reliable instability signals; exploration-safe abstraction learning; verifier synthesis.
- Scientific and engineering copilots for long pipelines
- Vision: End-to-end lab/EDA/CFD workflows decomposed into verifiable subgoals with macro-actions (“run simulation batch → analyze → refine parameters”), improving stability and sample efficiency.
- Dependencies: Robust simulators and data provenance; domain checkers; compute-efficient RL pipelines.
- Operations and energy systems planning
- Vision: Control-room copilots that plan over long horizons by composing macro dispatch actions and subgoal states (stability/security constraints), benefiting from horizon generalization.
- Dependencies: High-fidelity digital twins; stringent safety verifiers; regulator-acceptable audit trails.
- Financial decision agents with horizon generalization
- Vision: Train on short-horizon proxies (e.g., intraday compliance checks) that generalize to longer workflows (portfolio transitions, stress testing), leveraging curriculum + macro-actions.
- Dependencies: Risk limits, human-in-the-loop oversight, scenario simulators; compliance certification.
- Robotics with hierarchical skills and verified milestones
- Vision: Lifelong learning stacks where skills are macro-actions and training progresses via horizon curricula; process rewards from multimodal sensors; strong transfer to longer tasks.
- Dependencies: Generalizable skill libraries; reliable subgoal detection; safety and certification pathways.
- Safety-and-governance-by-design for autonomous systems
- Vision: Policies requiring horizon reduction and subgoal verification for high-stakes autonomy; mandated reporting of effective horizon and collapse indicators pre-deployment.
- Dependencies: Standards bodies; sector-specific guidance; third-party audits.
- Multi-agent and orchestration systems
- Vision: Coordinators that reduce system-wide horizon via macro protocols (batching, contracts) and enforce subgoal alignment across agents, improving stability of long workflows.
- Dependencies: Inter-agent contracts, shared verifiers, and robust communication protocols.
Notes on Feasibility and Key Assumptions
Applying these ideas successfully depends on several common prerequisites:
- Verifiable subgoals: Availability of reliable, preferably automated validators for intermediate states (tests, checklists, schema/constraint checks, receipts, sensor validations).
- Support for macro-actions: Tooling/APIs that permit composing multiple atomic steps into higher-level primitives; safe rollback and auditing.
- Training telemetry: Ability to measure effective horizon, step accuracy, and collapse indicators (e.g., spikes in maximum-length responses).
- Compute and data: SFT seeds and on-policy/off-policy RL cycles; environments that are deterministic or have replay ability for stable credit assignment.
- Oversight and safety: Human-in-the-loop policies, especially in regulated domains (healthcare, finance); robust logging and explainability for audits.
- Generalization boundaries: Horizon generalization improves success on longer tasks with similar reasoning difficulty; large shifts in reasoning complexity or domain knowledge may still require additional data, stronger models, or domain-specific validators.
Glossary
- Advantage function: A baseline-adjusted measure of how much better or worse an action performed compared to expectation in a given state. "Defining the advantage function as , the policy gradient objective is formally expressed as"
- Action abstraction: Representing sequences of low-level actions as higher-level actions to simplify decision making and reduce horizon length. "Horizon reduction via action abstraction."
- Autoregressive LLMs: Models that generate tokens sequentially, each conditioned on previously generated tokens. "Autoregressive LLMs."
- Batch normalization: Normalizing a batch of signals to stabilize and accelerate training. "To stabilize optimization, we apply batch normalization to each component"
- Categorical distribution: A probability distribution over discrete outcomes (e.g., vocabulary tokens). "The policy defines a categorical distribution over the vocabulary "
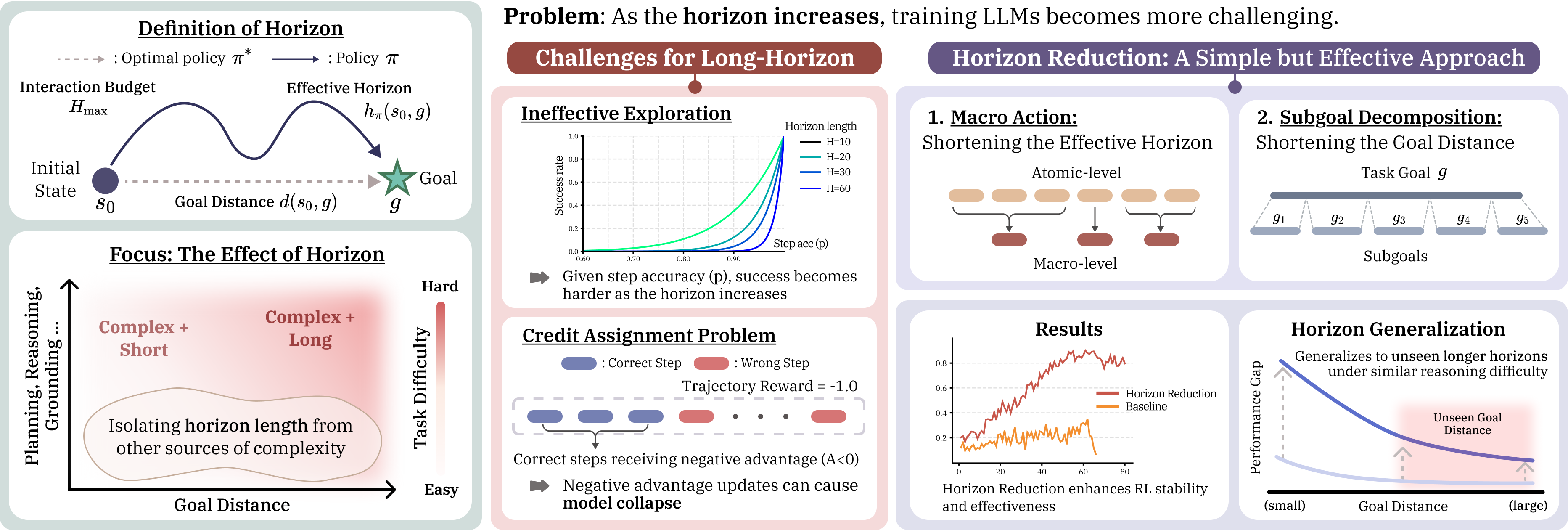
- Catastrophic collapse: A training failure mode where performance deteriorates dramatically after initial improvements. "training on L3--L4 instances leads to severe instability and catastrophic collapse."
- Credit assignment: The problem of attributing outcomes to the actions responsible for them, especially difficult with delayed rewards. "credit assignment becomes severely challenging under sparse rewards."
- Critic-free policy optimization methods: Policy optimization approaches that avoid training a separate value function (critic). "The emergence of critic-free policy optimization methods, Group Relative Policy Optimization (GRPO), has fundamentally shifted this paradigm."
- Curriculum learning: Training strategy that progresses from easier (shorter horizon) tasks to harder (longer horizon) tasks. "Curriculum learning via horizon generalization."
- Effective horizon: The number of steps a policy actually takes to reach the goal in a successful episode. "this approach aims to decrease the effective horizon "
- Goal distance: The minimum number of atomic actions needed to reach the goal under an optimal policy. "using this count as a direct proxy for the goal distance ."
- GRPO (Group Relative Policy Optimization): A critic-free RL method that uses group-relative advantages for policy optimization. "Group Relative Policy Optimization (GRPO)"
- Group-normalized advantages: An advantage scaling strategy where advantages are normalized within groups (e.g., trajectories). "a GRPO-style method with group-normalized advantages."
- Hierarchical reinforcement learning: An RL framework that decomposes tasks into hierarchical subproblems or subpolicies. "This approach aligns with hierarchical reinforcement learning,"
- Horizon generalization: The ability of a model trained on shorter horizons to perform well on longer, unseen horizons. "a phenomenon we refer to as horizon generalization."
- Horizon reduction: Techniques that shorten the effective number of decisions needed to solve a task. "We identify horizon reduction as a simple yet powerful principle"
- Importance sampling: A technique to correct for distribution mismatch between sampling and target policies during off-policy updates. "an importance sampling weighted term designed to address distribution shift"
- IS ratio: The importance sampling ratio between target and behavior policies. "where denotes the IS ratio."
- Interaction budget: The maximum number of interaction steps allowed by the environment. "Interaction Budget $H_{\max$:} The maximum number of interaction steps allowed by the environment."
- Logit: The unnormalized score (pre-softmax) associated with a token or action. "analyze how gradients propagate through the logits ."
- Macro actions: Higher-level actions composed of multiple atomic actions executed as a single step. "By allowing the policy to operate over macro actions, which compose multiple atomic actions into higher-level primitives, we can naturally reduce the horizon length."
- Markov decision process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "a stochastic policy in a token-level Markov decision process (MDP)."
- Masked Importance Sampling (MIS): An importance sampling variant that masks (filters) updates based on ratio bounds. "Masked Importance Sampling (MIS) based on the geometric mean ratio"
- Maximum-length response ratio: The fraction of outputs that hit the maximum allowed length, often signaling degenerate generations. "a sharp increase in the maximum-length response ratio, signaling a transition toward incoherent or excessively long generations."
- Off-policy: Learning from data generated by a different policy than the one currently being optimized. "Stabilizing off-policy REINFORCE."
- On-policy: Learning from data generated by the current policy being optimized. "we revisit the fundamental on-policy algorithm, REINFORCE"
- pass@: A metric measuring whether at least one of K sampled attempts succeeds. "we sample 4 trajectories per instance to report pass@ and avg@."
- Policy gradient: Methods that directly optimize a parameterized policy by ascending estimated gradients of expected return. "the policy gradient objective is formally expressed as"
- Policy staleness: The lag between the data-generating policy and the current policy parameters during training. "introduces policy staleness where the sampling policy $\mu_{\theta_\text{old}$ diverges from the current ."
- PPO: A popular policy gradient method that constrains updates via a clipped objective. "PPO~\citep{schulman2017proximal}"
- Process reward: Intermediate rewards for partial progress toward a goal, often tied to verifiable steps. "support the broader utility of process reward, which we discuss further in Section~\ref{sec:discussion}."
- REINFORCE: A foundational Monte Carlo policy gradient algorithm using returns (and optionally baselines) for updates. "we revisit the fundamental on-policy algorithm, REINFORCE"
- Reinforcement learning (RL): A paradigm where agents learn through interactions by maximizing cumulative reward. "Reinforcement learning (RL) has a long history of success across a wide range of decision-making"
- Sparse rewards: Reward structures where feedback is infrequent, often only at episode end. "credit assignment becomes severely challenging under sparse rewards."
- Stochastic policy: A policy that samples actions according to probabilities rather than deterministically. "We model a LLM parameterized by as a stochastic policy "
- Subgoal decomposition: Breaking a long-horizon goal into a sequence of shorter, verifiable subgoals. "Subgoal decomposition."
- Token-level gradient dynamics: Analysis of how gradients affect token logits during policy optimization. "Token-level gradient dynamics."
- Trajectory: A sequence of states and actions generated by agent-environment interaction over time. "The interaction between the agent and the environment generates a trajectory"
- Truncated Importance Sampling (TIS): Importance sampling with clipped ratios to reduce variance and stabilize learning. "Truncated Importance Sampling (TIS) based on the sequence-level ratio"
- Value network: A learned function estimating expected returns to reduce variance in policy gradients. "the requirement for a separate value network creates significant scalability bottlenecks."
- Variance reduction: Techniques to lower the variance of gradient estimates, improving training stability. "In classical deep RL, long-horizon challenges are typically addressed using value-based variance reduction."
Collections
Sign up for free to add this paper to one or more collections.