KLong: Training LLM Agent for Extremely Long-horizon Tasks
Abstract: This paper introduces KLong, an open-source LLM agent trained to solve extremely long-horizon tasks. The principle is to first cold-start the model via trajectory-splitting SFT, then scale it via progressive RL training. Specifically, we first activate basic agentic abilities of a base model with a comprehensive SFT recipe. Then, we introduce Research-Factory, an automated pipeline that generates high-quality training data by collecting research papers and constructing evaluation rubrics. Using this pipeline, we build thousands of long-horizon trajectories distilled from Claude 4.5 Sonnet (Thinking). To train with these extremely long trajectories, we propose a new trajectory-splitting SFT, which preserves early context, progressively truncates later context, and maintains overlap between sub-trajectories. In addition, to further improve long-horizon task-solving capability, we propose a novel progressive RL, which schedules training into multiple stages with progressively extended timeouts. Experiments demonstrate the superiority and generalization of KLong, as shown in Figure 1. Notably, our proposed KLong (106B) surpasses Kimi K2 Thinking (1T) by 11.28% on PaperBench, and the performance improvement generalizes to other coding benchmarks like SWE-bench Verified and MLE-bench.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces KLong, a new open-source AI “agent” built to handle extremely long tasks, like reading a full research paper, writing code to recreate its results, and running long experiments. These tasks can take many hours and hundreds of steps, which is hard for most AI models. KLong is trained with a special recipe so it can remember important parts, plan across many steps, and improve through practice.
Goals
The paper asks a simple question: How can we train an AI to successfully complete very long, complicated tasks that:
- take a lot of time and many back-and-forth actions, and
- are longer than the AI can “fit” into its memory at once?
The main goal is to make the AI better at:
- reproducing machine learning research papers (reading, coding, running experiments),
- fixing software bugs,
- writing and running code in a computer terminal, and
- tackling security-related coding tasks.
How They Did It
To help readability, here are the main parts of their approach, explained in everyday language.
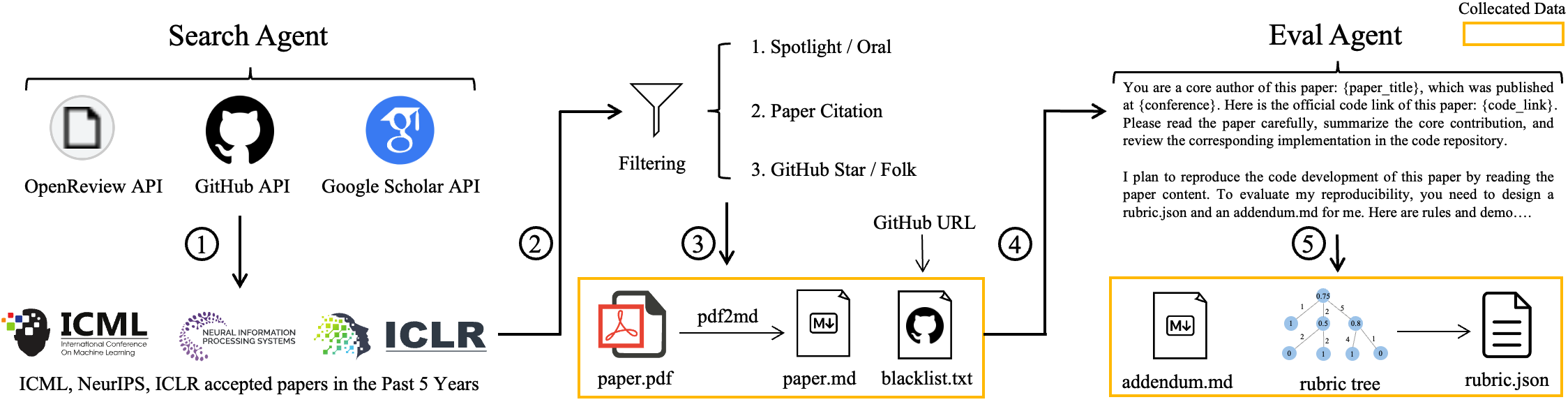
Building the training data: Research-Factory
- Imagine a factory that gathers lots of high-quality homework tasks. The team built “Research-Factory,” an automated pipeline that:
- collects papers from top conferences (like ICML, NeurIPS, ICLR),
- filters them for quality,
- converts the PDFs into a friendly text format,
- creates a grading checklist (a “rubric”) for each paper, and
- blocks the official GitHub code so the AI can’t just copy answers.
- They then used a strong model (Claude 4.5 Sonnet, Thinking mode) to produce thousands of example solution paths for these tasks. Think of these as “gold standard” study guides showing how to read the paper, plan, code, and test.
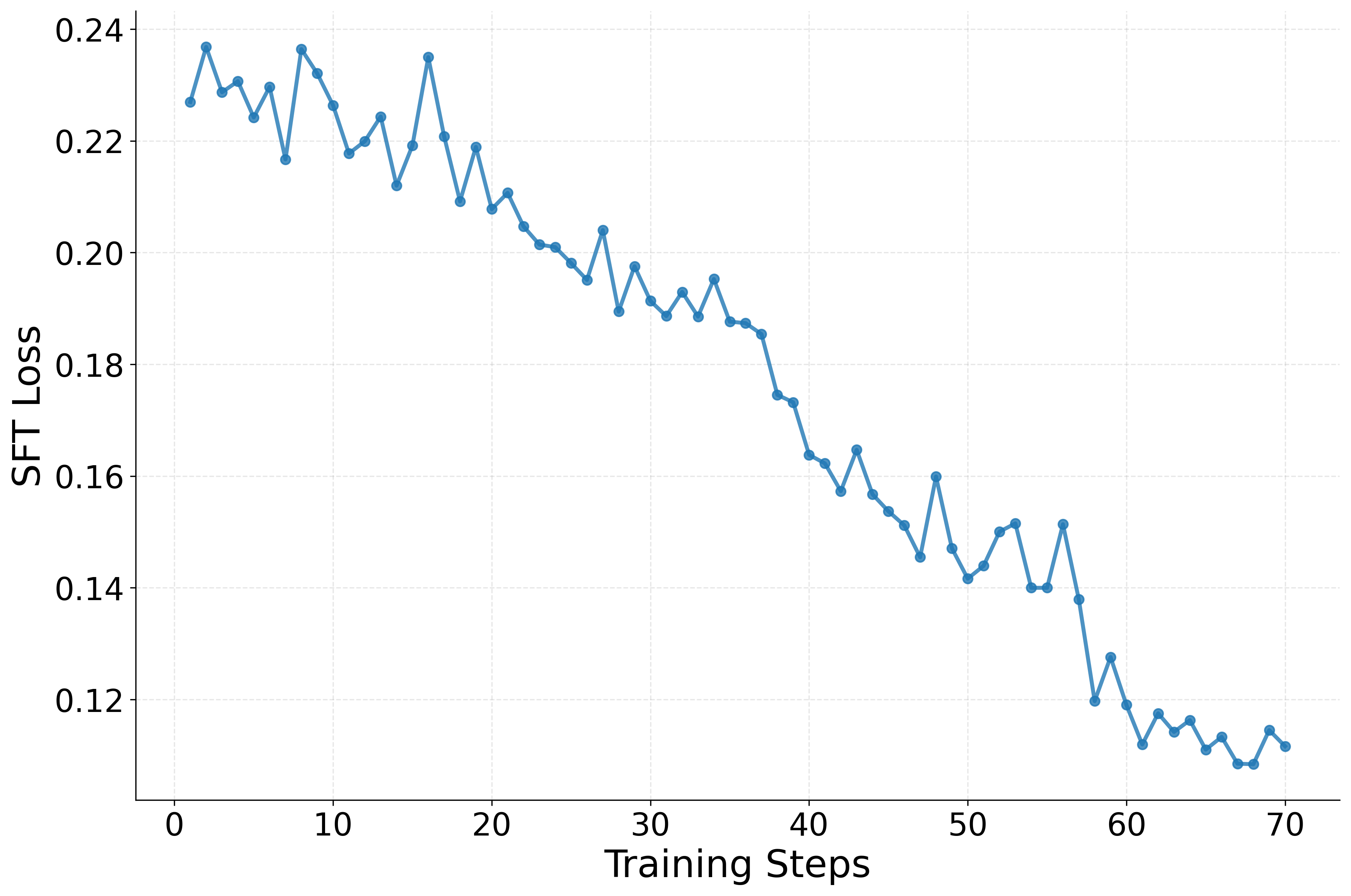
Teaching the model basic skills: Supervised Fine-Tuning (SFT)
- First, they give KLong a “starter course” using SFT. This is like having a teacher show many examples of correct answers in:
- general knowledge,
- coding,
- math, and
- online search.
- This step helps KLong learn basic skills before tackling very long tasks.
Handling long tasks: Trajectory-splitting SFT
- AI models have a limited “context window”—like a memory buffer. Very long tasks don’t fit.
- Their trick: split the long task into overlapping chunks, like breaking a long movie into episodes with small recaps between them.
- They always keep the “paper reading and task description” pinned at the start of each chunk (so the AI remembers the big picture).
- They then include overlapping slices of later steps, so the story flows smoothly between chunks.
- This lets the AI train on very long processes without forgetting the important early parts.
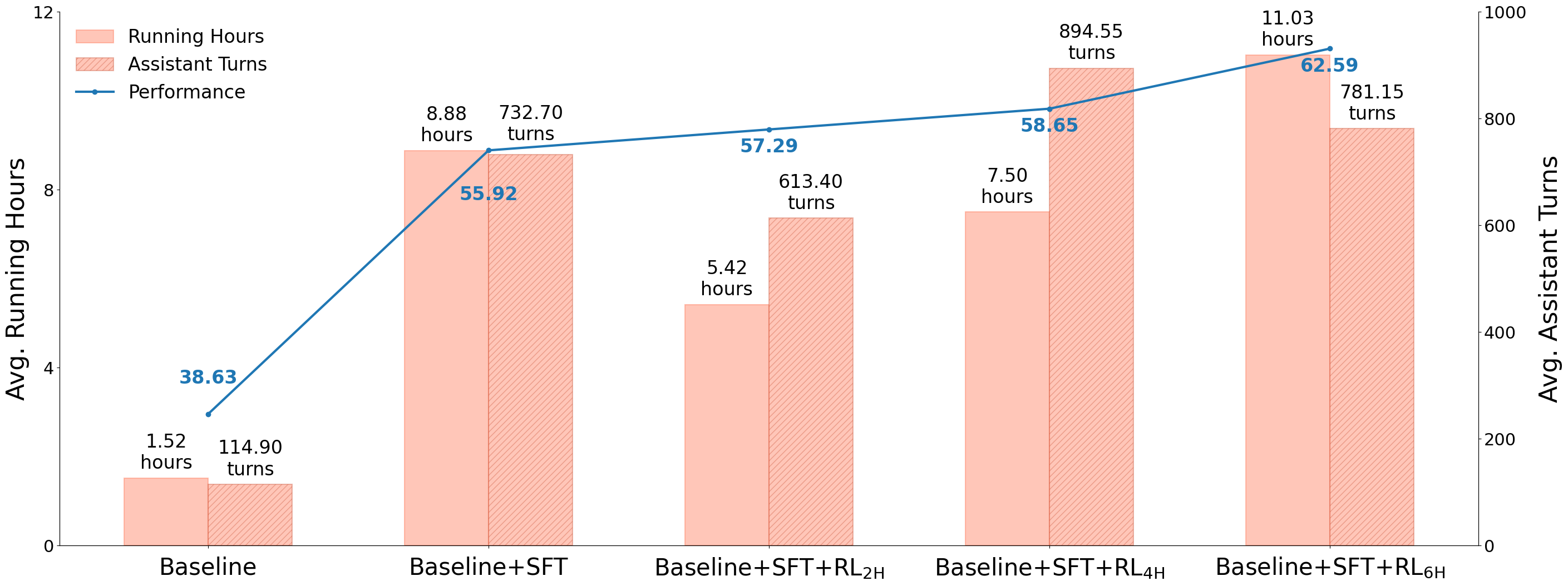
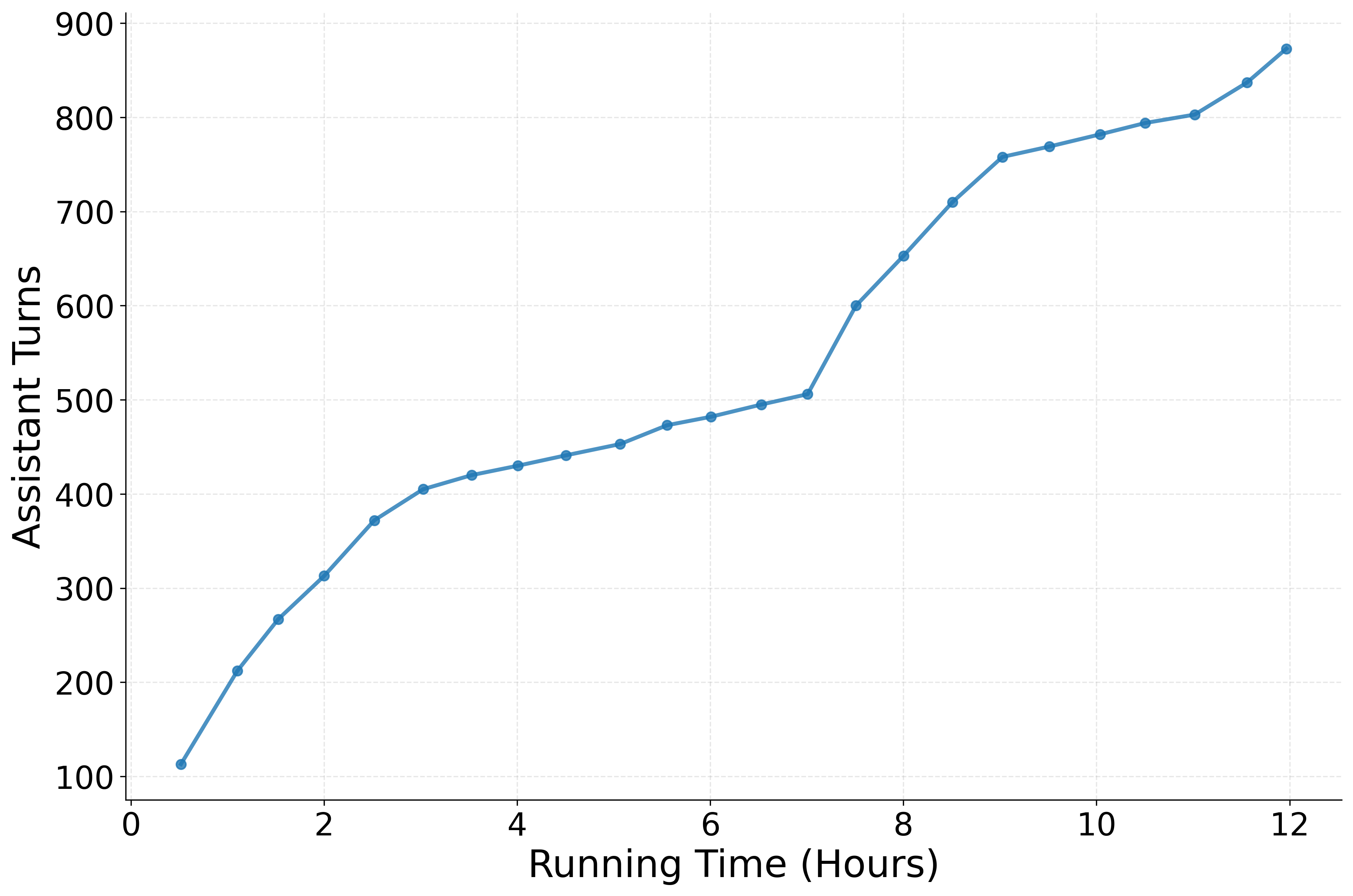
- Result: the AI handled many more “assistant turns” (steps). In numbers, average steps went up from about 115 to about 733, showing much longer, sustained work.
Making the model better with practice: Progressive Reinforcement Learning (RL)
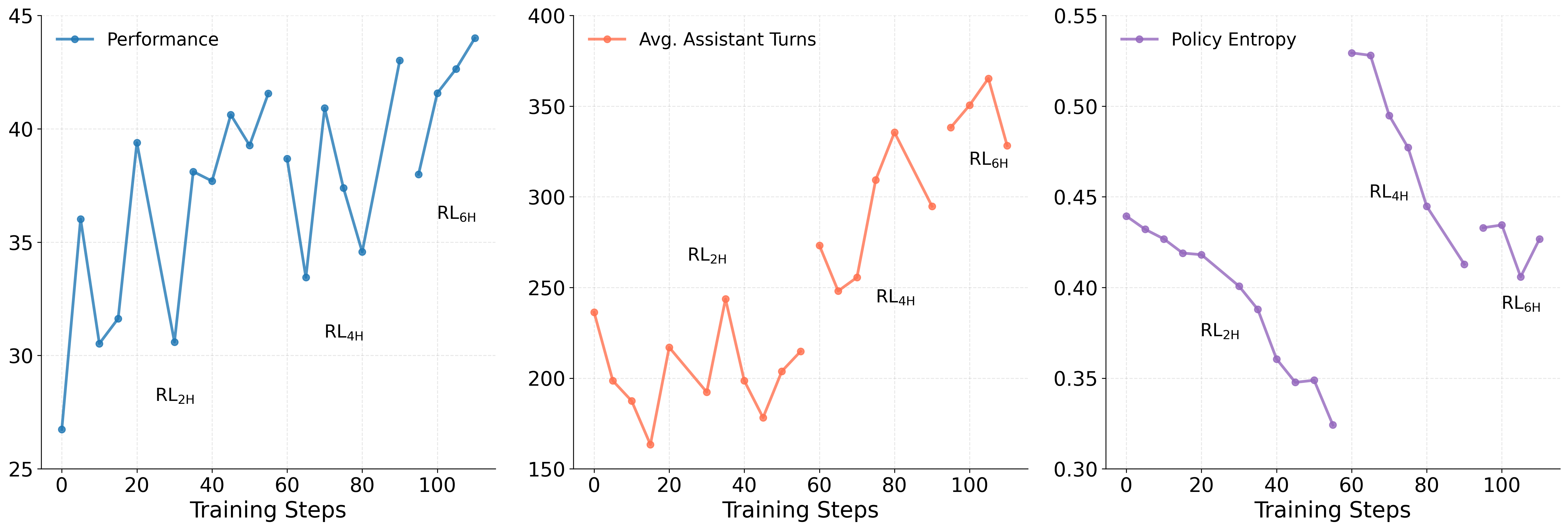
- Reinforcement Learning is like practicing a video game and getting points based on how well you do, then adjusting your strategy.
- The team used “progressive RL,” which slowly increases time limits for each practice session:
- Start with shorter timeouts (e.g., 2 hours), then move to longer ones (e.g., 4 hours, 6 hours).
- This reduces frustration from very long, hard tasks and helps the AI learn steadily.
- They also split these long practice runs into chunks (like before) and used a “judge” to score results based on the rubric.
- This boosted performance further—about +6.67% improvement after RL versus SFT-only.
Engineering improvements to make it work
- Sandbox: a secure, scalable computer environment to run code at large scale, with popular ML packages pre-installed.
- Better scaffolding: rules and tools that make the AI read the paper first, handle long text safely, and avoid “ending early.”
- Smarter training pipeline: avoid traffic jams when many practice runs finish at once by staggering evaluations and using priority queues so important checks get done first.
- Cost-saving judge: they used a strong open-source judge model during training to score progress and avoid overfitting to the official benchmark.
Main Findings
- On PaperBench (a challenge where AI must recreate the results of real AI papers), KLong performed best among open-source models. It beat Kimi K2 Thinking (a much larger model) by 11.28% on average, even though KLong is smaller.
- KLong’s improvements also carried over to other tasks:
- SWE-bench Verified (bug fixing): higher pass rate,
- Terminal-Bench Hard (command-line coding): higher success rate,
- SEC-bench (software security tasks): better overall success,
- MLE-bench (ML competitions): stronger results, including Above Median, Bronze, and even Gold medals in some competitions.
- Training tricks mattered:
- Trajectory-splitting SFT enabled much longer multi-step behavior.
- Progressive RL further improved performance and stability over longer time horizons.
Why This Is Important
- Real-world work is rarely a one-shot question. It’s long, messy, and multi-step—like building a project, doing research, or debugging complex software. KLong shows how to train AI to handle that kind of work.
- The method (splitting long tasks into overlapping chunks and gradually extending practice time) gives a practical recipe other teams can use.
- Because KLong is open-source, researchers and developers can study, improve, and adapt it for their own long, complex tasks.
- In the big picture, this helps move AI from quick answers to sustained problem-solving—reading deeply, planning carefully, and finishing tough jobs end-to-end.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, articulated as concrete, actionable directions for future work.
- Data provenance and teacher bias: The method distills thousands of trajectories from Claude 4.5 Sonnet (Thinking), but the paper does not quantify coverage, diversity, or bias of these trajectories. Evaluate how teacher choice affects learned behaviors (e.g., style imitation, tool-use patterns, failure modes) via ablations with multiple teachers and mixed-teacher datasets.
- Decontamination rigor: The paper states “careful decontamination” to avoid test-set papers but provides no methodology. Detail exact decontamination checks (title/author/code URL matching, semantic similarity, time cutoff), false positive/negative rates, and publish audit scripts to ensure benchmark integrity.
- Rubric construction inconsistency: The text alternately claims rubrics are “written by original authors” and “constructed by an evaluation agent analyzing official code.” Resolve this inconsistency by specifying the exact rubric source per task, the proportion of human-authored vs agent-generated rubrics, and measure inter-rater reliability or human validation quality.
- Risk of rubric leakage/overfitting: Using official code to construct rubrics may seed task-specific implementation details into the evaluation signal. Study whether training rewards inadvertently reflect privileged knowledge and whether models learn to exploit rubric patterns. Include controls where rubrics are derived solely from papers without code inspection.
- Trajectory-splitting hyperparameters: No ablation is provided on segment length L, overlap O, or prefix p size. Conduct sensitivity analyses to quantify trade-offs between contextual continuity, compute overhead, and learning stability, and recommend default settings per context window.
- Credit assignment under splitting: Splitting long trajectories into overlapping sub-trajectories may break long-range dependencies. Evaluate credit assignment fidelity on synthetic tasks with known delayed rewards and on real tasks where early decisions affect late outcomes. Compare to alternatives (e.g., hierarchical credit assignment, memory-augmented policies).
- Inference-time state management: Training uses trajectory splitting to fit the context window, but the paper does not describe how inference maintains state across 700+ turns without sophisticated memory/context management. Detail the inference-time state strategy (buffering, retrieval, external memory) and quantify its impact on success rates and latency.
- Progressive RL schedule design: The choice of timeouts (2H, 4H, 6H) is heuristic and not justified. Explore principled schedule design (e.g., curriculum based on observed return/variance, adaptive timeout setting), include a 12H stage to match task horizons, and compare to asynchronous RL baselines optimized for long tasks.
- RL algorithm details and ablations: The paper uses a PPO-like loss with group-relative advantage, but does not report epsilon, KL coefficient β, rollout count n, or stage-specific Km. Provide full hyperparameters, ablations on advantage normalization schemes, and stability metrics (variance, KL drift) to enable reproducibility and principled tuning.
- Reward hacking and judge dependency: Rewards are assigned by a single judge model (gpt-oss-120b) using constructed rubrics. Assess susceptibility to reward hacking by testing across multiple independent judges (including o3-mini), human-in-the-loop verification on a subset, and cross-judge correlation analyses across all tasks (not just 3 models).
- Statistical rigor: Results lack uncertainty estimates, multiple seeds, and significance testing. Report per-task confidence intervals, seed variability, and effect sizes to establish robustness, especially for small improvements on SWE-bench Verified and Terminal-Bench Hard.
- Compute, cost, and efficiency: The paper does not disclose training compute, GPU-hours, parallel rollout counts, or cost. Provide end-to-end efficiency metrics (tokens processed, wall-clock time, energy/cost), and analyze the trade-off between increased assistant turns/running hours and performance gains.
- Scalability beyond 6-hour horizons: Progressive RL tops out at 6H while tasks can run 12H+. Investigate feasibility and stability of training at 12H+ horizons, and whether additional stages yield diminishing or compounding returns.
- Generalization breadth: Evaluation focuses on ML/code-heavy tasks. Test on other extremely long-horizon domains (web/GUI agents, scientific workflows beyond ML, multi-modal environments) to characterize domain generality and identify gaps in tool use or planning.
- Overfitting to scaffolding/harness: Training is “tailored to PaperBench” with custom scaffolding. Measure how performance transfers to alternative scaffolds (e.g., OpenHands variants, Terminus configurations, different tool contracts) to assess harness-specific overfitting.
- Partial rollout continuation and priority queue bias: The infrastructure prioritizes evaluation-set requests in a judge queue and continues partial rollouts across iterations. Analyze whether these policies skew training distribution, induce evaluation-set overfitting, or bias sample selection; consider randomized scheduling and fairness checks.
- MLE-bench failure analysis: Many competitions show “-” (no validated submission). Perform systematic failure-mode analysis (dataset availability, network limits, environment mismatch, timeouts) and quantify how Research-Factory and training affect submission validity rates.
- Impact of tool bans and scaffold rules: The paper bans the end_task tool early and imposes mandatory paper reading. Ablate these constraints to evaluate whether rules vs learned behavior drive performance, and identify minimal scaffold interventions for portability.
- Base model dependency: The approach is instantiated on GLM-4.5-Air-Base (106B) without comparison to other bases (e.g., Qwen, Llama). Study portability and how foundation model priors (context length, tokenizer, tool-use training) interact with splitting SFT and progressive RL.
- Scaling laws across model sizes: The paper contrasts 106B vs a 1T closed model but does not report internal scaling behavior. Produce scaling curves (e.g., 7B/34B/70B/106B) to characterize parameter-efficiency of long-horizon training and identify optimal size-cost regimes.
- Long-term memory retention and forgetting: Assistant turns increase dramatically, but the paper does not measure retention of early information or systematic forgetting. Introduce diagnostics (e.g., recall probes, dependency tracking) to quantify information persistence across hundreds of turns.
- Dataset release and quality controls: Trajectory dataset construction uses rejection sampling by judge scores, but thresholds and diversity controls are unspecified. Document acceptance criteria, balance across task types, and release artifacts (prompts, rubrics, trajectories) for community verification.
- Safety, ethics, and licensing: Distillation from proprietary models and analysis of official code for rubric creation raise licensing and ethical questions. Clarify usage rights, document safety measures in sandboxed execution (e.g., package vulnerabilities, network policies), and assess potential misuse or leakage risks.
- Comparison to alternative long-horizon methods: The paper does not benchmark against context-folding, memory-augmented agents, or large-scale asynchronous RL. Include head-to-head comparisons to isolate gains from trajectory-splitting SFT and progressive RL versus state-of-the-art training-free and training-based baselines.
Practical Applications
Immediate Applications
Below is a set of actionable use cases that can be deployed now, grounded in KLong’s methods (Research-Factory, trajectory-splitting SFT, progressive RL) and infrastructure optimizations (Kubernetes sandbox, scaffolding, rollout/judge scheduling).
- Reproducibility Assistant for AI/ML Papers
- Sector: Academia, R&D in Industry
- What it does: Semi-automated reproduction of published ML papers (reading, implementation, experiment runs, rubric-based judging).
- Tools/workflows: Research-Factory (paper collection, PDF→Markdown, decontamination, rubric tree construction), KLong agent, Kubernetes sandbox, rubric-based judging (gpt-oss-120b or equivalent).
- Assumptions/dependencies: Access to papers/datasets; accurate rubric design; reliable judge model; sufficient compute/time windows; legal/privacy compliance for data use.
- ML Engineering Autopilot for Experiments
- Sector: Software/ML, Academia, Competitive ML (e.g., Kaggle)
- What it does: Builds baselines, tunes hyperparameters, runs long experiments end-to-end; participates in competitions (MLE-bench tasks).
- Tools/workflows: Preinstalled sandbox environments (torch, TensorFlow, scikit-learn, einops), trajectory-splitting SFT-enabled agent; experiment tracking; timeout scheduling.
- Assumptions/dependencies: GPU/CPU availability; dataset licensing; long-running job orchestration; reliable package management.
- Bug-Fixing and Issue Triage Bot
- Sector: Software Engineering
- What it does: Multi-hour debugging and patching across repositories; triage issues that require extended exploration and tests.
- Tools/workflows: SWE-bench Verified scaffolding (e.g., OpenHands), KLong agent, CI/CD integration, test harnesses.
- Assumptions/dependencies: Repository access and tests; guardrails for code changes; organizational approval for agent-driven commits.
- SecOps Vulnerability Hunter
- Sector: Cybersecurity
- What it does: Long-horizon CVE triage, reproducing OSS-Fuzz cases, generating patches; sustained multi-step codebase exploration.
- Tools/workflows: SEC-bench scenarios; sandbox isolation; rubric-based evaluation of exploitability/fix quality.
- Assumptions/dependencies: Secure execution environments; access to vulnerable code and reproduction steps; policy-approved remediation workflows.
- TerminalOps Automation
- Sector: DevOps/IT Operations
- What it does: Extended terminal interactions for environment setup, log analysis, data processing, and infrastructure maintenance.
- Tools/workflows: Terminus 2 scaffolding; Kubernetes sandbox; prompt caching; improved context-length error handling.
- Assumptions/dependencies: Appropriate credentials and access control; rate limits; stable connectivity; reliable audit logs.
- Deep Research Assistant for Knowledge Work
- Sector: Enterprise/Consulting
- What it does: Long-run literature search, synthesis, and method replication to support decisions and due diligence.
- Tools/workflows: Research-Factory’s search/evaluation agents; rubric trees; trajectory-splitting context handling for lengthy sessions.
- Assumptions/dependencies: Source access (papers, code); quality rubrics; accurate judges; policies for handling proprietary materials.
- Long-Horizon Agent Training Toolkit
- Sector: AI/ML Engineering (Industry and Labs)
- What it does: Adopts trajectory-splitting SFT and progressive RL schedules to upgrade existing agents for long-horizon tasks.
- Tools/workflows: Prefix pinning, overlapping sub-trajectories, staged timeouts, group-relative advantage PPO, partial rollouts and priority judge queues.
- Assumptions/dependencies: Base model availability; high-quality trajectories; compute budget; reliable judges; careful reward design.
- Secure Agent Execution Platform (Sandbox-as-a-Pattern)
- Sector: Platform/MLOps
- What it does: Production-ready, Python-accessible, Kubernetes-based ephemeral sandbox with sidecar image management and scalable environments.
- Tools/workflows: Ephemeral use-and-destroy containers; 25k+ Docker images management; environment preinstalls; prompt caching; tool bans.
- Assumptions/dependencies: Cluster provisioning; cost control; isolation and observability; image maintenance pipeline.
- Course Repro Labs and Auto-Grading
- Sector: Education
- What it does: Instructor-ready “reproduce-a-paper” labs with rubric-driven auto-grading of students’ replication attempts.
- Tools/workflows: Research-Factory rubrics; sandboxed execution; KLong agent for assistance and evaluation.
- Assumptions/dependencies: Curated paper sets; fairness and anti-cheating measures; compute quotas; accessible datasets.
- Compliance and Audit for AI Claims
- Sector: Policy/Enterprise Governance
- What it does: Rubric-based reproducibility checks for vendor claims (models/papers), producing documented evidence for compliance audits.
- Tools/workflows: PaperBench-style rubrics; independent judge models; standardized reports; audit logs from sandbox.
- Assumptions/dependencies: Organizational buy-in; legal frameworks for verification; access to artifacts; reproducibility standards.
- Long-Context Augmentation for Existing Agents
- Sector: AI Product Development
- What it does: Drop-in training approach to extend agents’ effective horizons without expanding model context windows.
- Tools/workflows: Trajectory splitting (prefix pinning, progressive truncation, overlap), staged RL timeouts, partial rollouts.
- Assumptions/dependencies: Availability of long trajectories; logging tooling; careful decontamination; data provenance.
- RL Pipeline Resource Optimization
- Sector: MLOps/Infrastructure
- What it does: Reduces idle nodes and judge congestion via partial rollouts and priority queues for evaluations.
- Tools/workflows: Rollout scheduling, priority judge queues, carry-over of unfinished rollouts, monitoring dashboards.
- Assumptions/dependencies: RL orchestration platform; concurrency management; reliable evaluator throughput.
Long-Term Applications
The following use cases require further research, scaling, standardization, or cross-domain integration (e.g., multi-modal data, regulated environments, organizational adoption).
- Autonomous R&D Agent (Read → Reproduce → Extend → Innovate)
- Sector: Academia, Industrial R&D
- What it could do: Systematically reproduce results, propose variations, run ablations, and generate new research contributions.
- Tools/workflows: Expanded Research-Factory across disciplines; longer timeouts; asynchronous RL; multi-modal ingestion (figures/data).
- Assumptions/dependencies: Access to lab resources and datasets; author cooperation; robust multi-modal reasoning; institutional acceptance.
- Continuous Software Modernization Agent
- Sector: Software/Enterprise IT
- What it could do: Repository-scale upgrades (framework migrations, dependency refactors), sustained CI fixes over days/weeks.
- Tools/workflows: Long-horizon planning; code-review integration; staged deployment; rollback safety nets.
- Assumptions/dependencies: Organization-wide change management; comprehensive test coverage; strict guardrails; human-in-the-loop governance.
- Reproducibility Certification Program
- Sector: Policy/Standards, Publishing
- What it could do: Standardized reproducibility scoring for publications/products; badges/certifications mandated by journals/regulators.
- Tools/workflows: Community-maintained rubric trees; independent evaluator pools; registry (PaperBench-like) of certified artifacts.
- Assumptions/dependencies: Consensus on standards; funding and governance; cross-institution interoperability; transparency requirements.
- Secure Multi-tenant Agent Cloud (Sandbox-as-a-Service)
- Sector: Platform/Cloud
- What it could do: Public service for long-horizon agent execution with strong isolation, compliance, and auditability.
- Tools/workflows: Hardened Kubernetes patterns; policy-enforced tool bans; tenant isolation; cost-aware scheduling.
- Assumptions/dependencies: Regulatory compliance (e.g., SOC2/ISO); cost models; demand aggregation; SLAs for long-running jobs.
- Healthcare Protocol Verification and Data Pipeline Automation
- Sector: Healthcare
- What it could do: Agent-driven reproducibility checks for clinical ML papers; validation of guidelines; long-run ETL and cohort building.
- Tools/workflows: Domain-specific rubric trees; privacy-preserving sandboxes; secure EHR connectors; audit trails.
- Assumptions/dependencies: HIPAA/GDPR compliance; stakeholder buy-in; curated medical ontologies; multi-modal medical data support.
- Energy System Modeling and Grid Simulation
- Sector: Energy/Utilities
- What it could do: Long-horizon simulations for grid planning, demand forecasting, and policy impact analysis.
- Tools/workflows: HPC integration; domain datasets and model libraries; trajectory-splitting for simulation logs.
- Assumptions/dependencies: Access to high-fidelity models; compute scaling; safety and resilience requirements.
- Robotics Experiment Orchestration
- Sector: Robotics/Automation
- What it could do: Multi-day experiment sequences in simulation and real-world; parameter sweeps; sustained evaluation loops.
- Tools/workflows: Real-time control integration; safety constraints; multi-modal (vision/sensor) inputs; asynchronous RL extensions.
- Assumptions/dependencies: Hardware access; strict safety governance; real-time constraints and fail-safes.
- Financial Risk Modeling Audit and Backtesting
- Sector: Finance
- What it could do: Reproducible audit trails for strategies; long-horizon backtests; regulatory reporting generation.
- Tools/workflows: Market data ingestion; rubric-based validation; secure sandbox; compliance controls.
- Assumptions/dependencies: Licensed datasets; regulatory approval; strict traceability; controlled release processes.
- MOOCs and University Programs with Auto-Graded Long Projects
- Sector: Education
- What it could do: Scalable grading of multi-week agentic projects (research reproduction, system builds) with transparent rubrics.
- Tools/workflows: Rubric trees; sandbox orchestration; evaluator pools; fairness audits.
- Assumptions/dependencies: Budget for compute; robust anti-cheating measures; bias mitigation in judging; inclusive access policies.
- Training-as-a-Service for Long-Horizon Agents
- Sector: AI Industry
- What it could do: Managed service offering trajectory-splitting SFT, progressive RL, data distillation, and evaluation pipelines.
- Tools/workflows: Dataset generation (Research-Factory), staged timeout coaching, priority evaluation queues; benchmark suites (PaperBench, MLE-bench, SWE-bench).
- Assumptions/dependencies: GPU clusters; licensing for distilled data; client-specific domain rubrics; security/compliance.
- Government Reproducibility Watchdog for AI
- Sector: Public Policy/Regulation
- What it could do: Independent verification of AI claims, standardized scoring, and public registries of reproducible artifacts.
- Tools/workflows: Certified rubrics; standardized judge models; trusted execution environments; reporting APIs.
- Assumptions/dependencies: Legal mandate; vendor cooperation; funding; protections against benchmark gaming.
- Scientific Publishing with Executable Rubrics and Pre-Publication Replication
- Sector: Academia/Publishing
- What it could do: Authors submit rubric trees and replication bundles; agents verify claims prior to acceptance; readers reproduce results post-publication.
- Tools/workflows: Author-facing rubric tooling; journal-integrated agent pipelines; artifact registries; DOI-linked reproducibility records.
- Assumptions/dependencies: Editorial policy changes; tooling adoption; shared repositories; incentives for authors and reviewers.
Glossary
- Addendum: Supplementary material appended to a paper or rubric to clarify evaluation criteria or constraints. "the evaluation agent designs the addendum and the rubric tree"
- Agentic abilities: Capabilities of an LLM agent to plan, use tools, remember, and act autonomously in multi-step tasks. "activate basic agentic abilities of a base model"
- Assistant turns: The number of agent responses or actions in a multi-turn interaction or trajectory. "assistant turns, 114.90732.70."
- Context management: System-level methods to select, compress, and retrieve relevant context to handle long sequences beyond model limits. "context management"
- Context window: The maximum number of tokens a model can attend to in a single input. "extremely long-horizon tasks inevitably exceed the context window"
- Credit assignment: In RL, attributing returns or rewards to actions taken earlier in long sequences. "due to sparse rewards, high variance, and unstable credit assignment."
- Decontamination: Removing test-set or benchmark content from training data to prevent leakage and overfitting. "We conduct careful decontamination to avoid including the papers in the test set."
- Distillation: Training a model or creating data by imitating or extracting behavior from a stronger model. "long-horizon trajectories distilled from Claude 4.5 Sonnet (Thinking)."
- Ephemeral use-and-destroy model: An infrastructure pattern where instances are short-lived and destroyed after use to improve scalability and security. "With an ephemeral use-and-destroy model, it efficiently supports 10,000+ concurrent instances."
- Frontier judge model: A state-of-the-art evaluator model used to score outputs according to a rubric. "a frontier judge model is used judge the replicated code based on the rubric tree "
- Group-relative advantage: An advantage estimate normalized across a group of trajectories to stabilize policy updates. "is the group-relative advantage across all trajectories"
- Judge model: The evaluation model that scores agent outputs against specified criteria or rubrics. "The official judge model of PaperBench is the closed-source o3-mini."
- Kubernetes: A container orchestration platform for deploying and scaling workloads across clusters. "using Kubernetes"
- KL regularization: Penalizing divergence between current and reference policies via Kullback–Leibler divergence to stabilize RL. "$\beta \, \mathbb{E}_{t} \Big[ \mathrm{KL} \big( \pi_\theta(\cdot \mid s_t) \,\|\, \pi_{\theta_{\mathrm{ref}(\cdot \mid s_t) \big) \Big]$" and "β weights the KL regularization."
- Likelihood ratio: In PPO-style RL, the ratio of current policy likelihood to reference policy likelihood for an action. " is the likelihood ratio"
- Long-horizon tasks: Tasks that require many steps, extended interactions, and sustained reasoning. "Long-horizon tasks, such as bug fixing"
- Overlapping sub-trajectories: Trajectory segments that share context to preserve continuity when splitting long sequences. "overlapping sub-trajectories for contextual continuity."
- Partial rollouts: Truncated RL episodes used to reduce synchronization bottlenecks and improve resource utilization. "We mitigate this issue via partial rollouts and a priority-based judge queue."
- Policy entropy: A measure of uncertainty in a policy’s action distribution; lower entropy indicates more confident actions. "assistant turns increase, and policy entropy decreases"
- Prefix: A fixed initial context included at the start of each sub-trajectory to preserve global information. "we fix a prefix containing the task specification and paper-reading content"
- Priority queue: An evaluation scheduling mechanism that processes higher-priority items first to avoid failures. "we introduce a priority queue to ensure that evaluations on evaluation set are processed with higher priority."
- Progressive reinforcement learning: A training strategy that gradually increases task timeouts across stages to stabilize learning on very long tasks. "we propose a novel progressive reinforcement learning by gradually increasing the task timeout during training."
- Reference policy: The previous or fixed policy used as a baseline in KL regularization and likelihood ratios. "$\pi_{\theta_{\mathrm{ref}$ is the reference policy from the previous training iteration"
- Rejection sampling: Filtering generated trajectories by quality or score thresholds to keep only high-quality samples. "We conduct rejection sampling by checking the quality and judge scores of trajectories."
- Rollouts: Executions of the agent policy in the environment that produce trajectories for training or evaluation. "Each rollout is split into overlapping sub-trajectories"
- Rubric tree: A structured hierarchy of evaluation criteria used to judge research reproduction quality. "rubric tree "
- Sandbox environment: An isolated, secure environment where the agent runs code and tools safely. "Within the sandbox environment, agent iteratively plans"
- Scaffolding: The auxiliary framework of tools and procedures that structure an agent’s interactions and workflows. "Scaffolding. We build on the basic scaffolding provided by PaperBench"
- Sidecar container pattern: A deployment design where a helper container runs alongside the main application to provide auxiliary functions. "A sidecar container pattern manages 25,000+ Docker images"
- Supervised fine-tuning (SFT): Training a model on input–output pairs to imitate desired behavior before RL. "standard supervised fine-tuning (SFT)"
- Timeout: A maximum allowed duration for a task or rollout after which it is forcibly terminated. "a 12-hour timeout"
- Trajectory-splitting SFT: An SFT technique that splits long trajectories into overlapping chunks with a fixed prefix to fit within the context limit. "we propose a new trajectory-splitting SFT"
- Wall-clock time: Real elapsed time measured externally (not steps or tokens), used to bound training or task duration. "bounds the maximum wall-clock time allowed for a task at stage ."
Collections
Sign up for free to add this paper to one or more collections.