- The paper demonstrates that transformers with softmax attention can exactly implement normalized gradient descent for in-context logistic regression, converging to a maximal margin classifier.
- It establishes a theoretical framework linking each self-attention layer to a gradient descent step, with empirical validations showing rapid convergence and structured parameter evolution.
- The study provides rigorous trainability analysis and out-of-distribution generalization guarantees, underscoring the practical benefits of increased transformer depth.
Transformers Implementing In-Context Logistic Regression via Normalized Gradient Descent
Theoretical Framework and Key Contributions
The paper provides a rigorous theoretical analysis establishing that transformers with softmax attention can explicitly perform in-context logistic regression through normalized gradient descent (NGD). Specifically, the authors construct a class of deep (multi-layer) transformers where each self-attention layer corresponds exactly to one step of NGD on an in-context loss over the prompt data. This construction is highly expressive: the hidden states at each layer precisely track the iterates of NGD, and as the network depth increases, the output converges directionally to the maximum-margin separator for the context dataset.
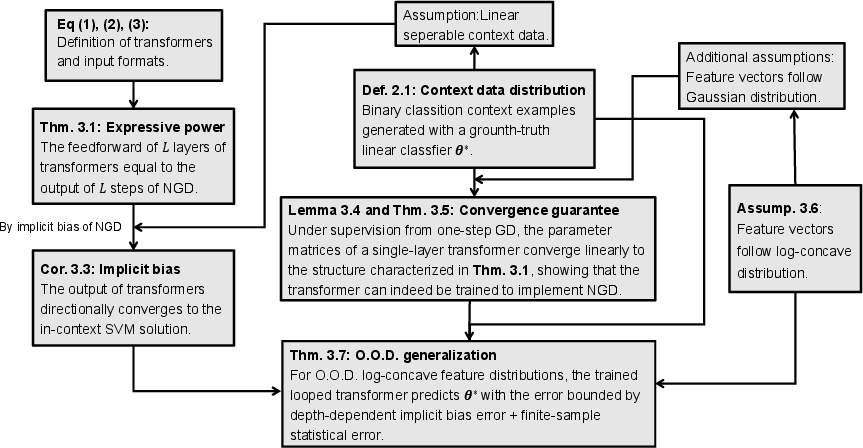
Figure 1: High-level roadmap of the theoretical framework, illustrating the assumptions, main results, and logical flow underlying expressivity, implicit-bias, trainability, and O.O.D. generalization guarantees.
These guarantees are formalized in Theorem 1, which characterizes a parameterization of transformer weight matrices such that the forward computation transparently implements NGD for the exponential loss typically considered in logistic regression. When the context data is linearly separable, this means the transformer output approaches the maximal margin linear classifier as the depth increases, and convergence rates are derived. Notably, the correspondence is exact (with no approximation error) and only requires single-head softmax attention with standard architectures and input embeddings.
Beyond expressivity, the authors analyze the trainability of transformers in this regime. They introduce a training protocol where a single attention block is supervised by a one-step gradient descent teacher and show—via a substantial new analysis—that the SGD dynamics converge linearly to a unique local minimizer in the parameter space. The resultant parameters give rise to a layer that, when applied recurrently (yielding a looped transformer), realizes the NGD update mechanism in practice. The analysis leverages new proof techniques, including careful non-asymptotic approximations, use of the Newton–Kantorovich theorem to show local uniqueness, and derivation of a Polyak-Łojasiewicz (PL) inequality to guarantee linear convergence.
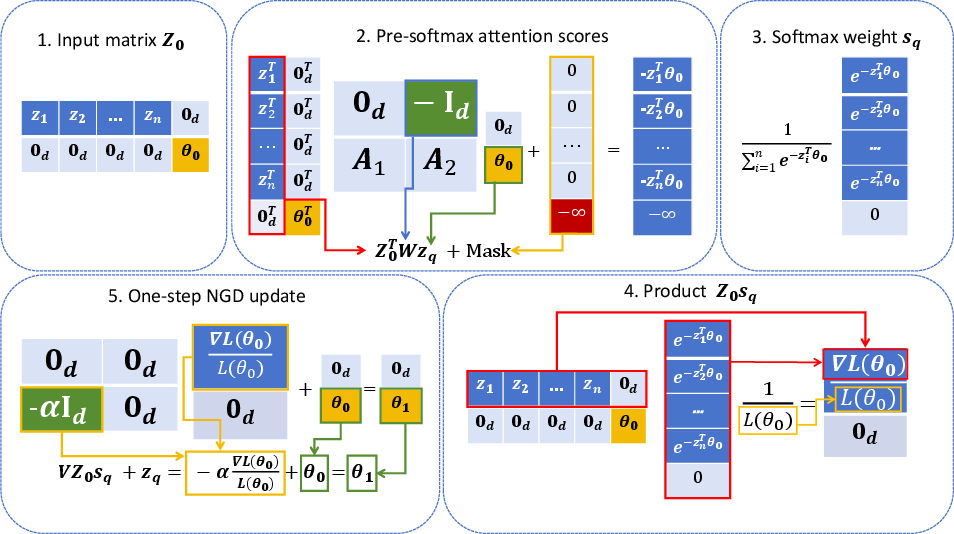
Figure 2: Illustration of the one-step mechanism—each softmax attention layer constructs the normalized-gradient direction and implements a step of NGD on the context loss.
Out-of-Distribution Generalization Guarantees
A particularly strong result is the derivation of out-of-distribution (O.O.D.) generalization guarantees for looped transformers obtained via the described training regime. Under mild log-concavity assumptions on the distribution of context features, the authors prove high probability error bounds for directional prediction on new context datasets, which scale as O~(d/n) (matching PAC lower bounds) plus an additional bias term inversely proportional to the number of layers. This is a pointwise guarantee—holding for any input—rather than an in-expectation bound.
These theoretical findings directly relate the network's sample complexity and generalization properties to those of classical statistical learning with maximum-margin classifiers. The results also highlight a concrete computational and statistical benefit of increasing transformer depth in the context of in-context learning.
Empirical Results
Experiments are presented in three main regimes: training single-layer transformers (to validate the NGD learning dynamics), recurrent application of trained layers (to build deep looped transformers and explore O.O.D. generalization), and direct end-to-end training of deep looped transformers. The empirical findings substantiate the theoretical predictions:
- Training curves for single-layer transformers show rapid and stable convergence, with loss decay rates consistent with theory.
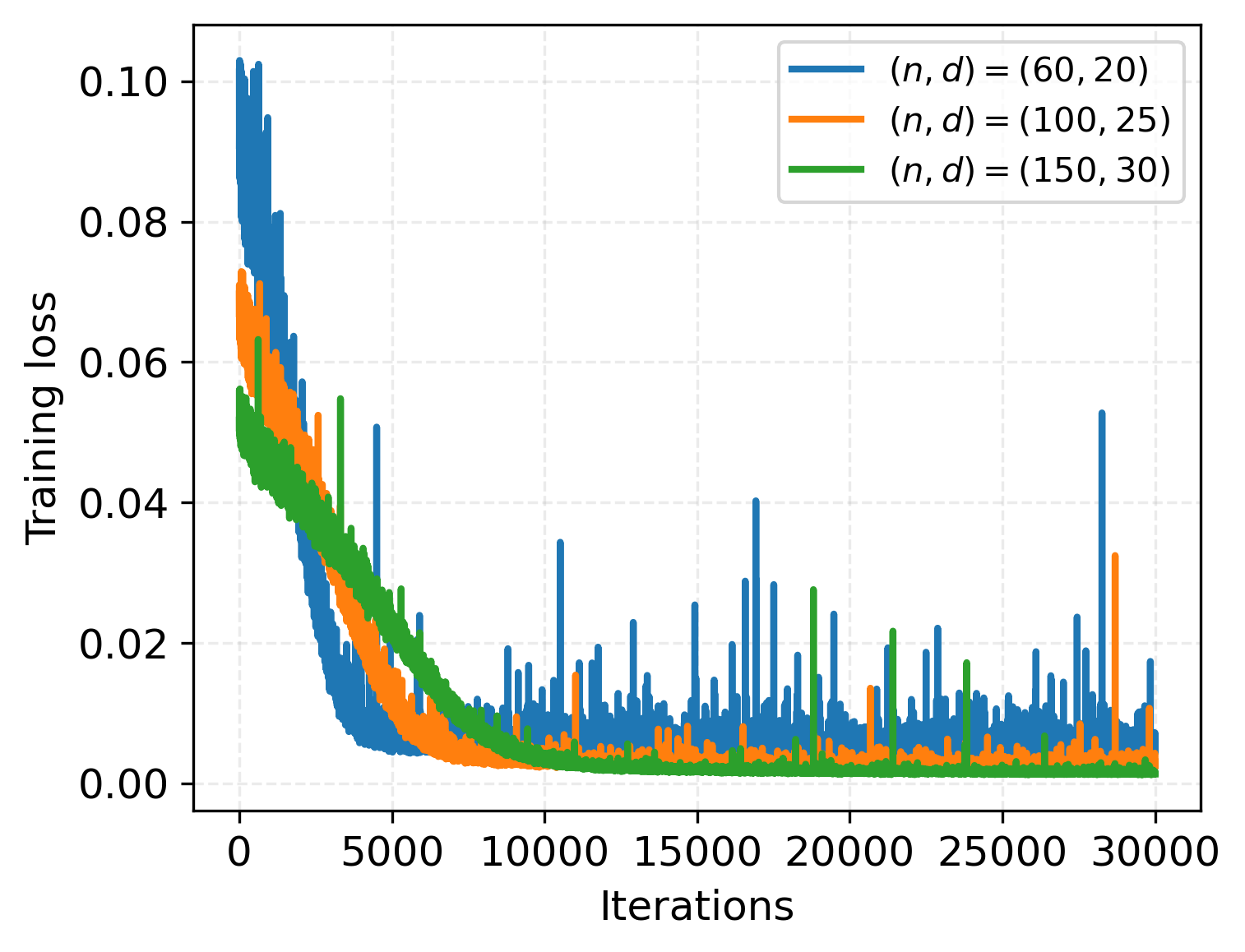
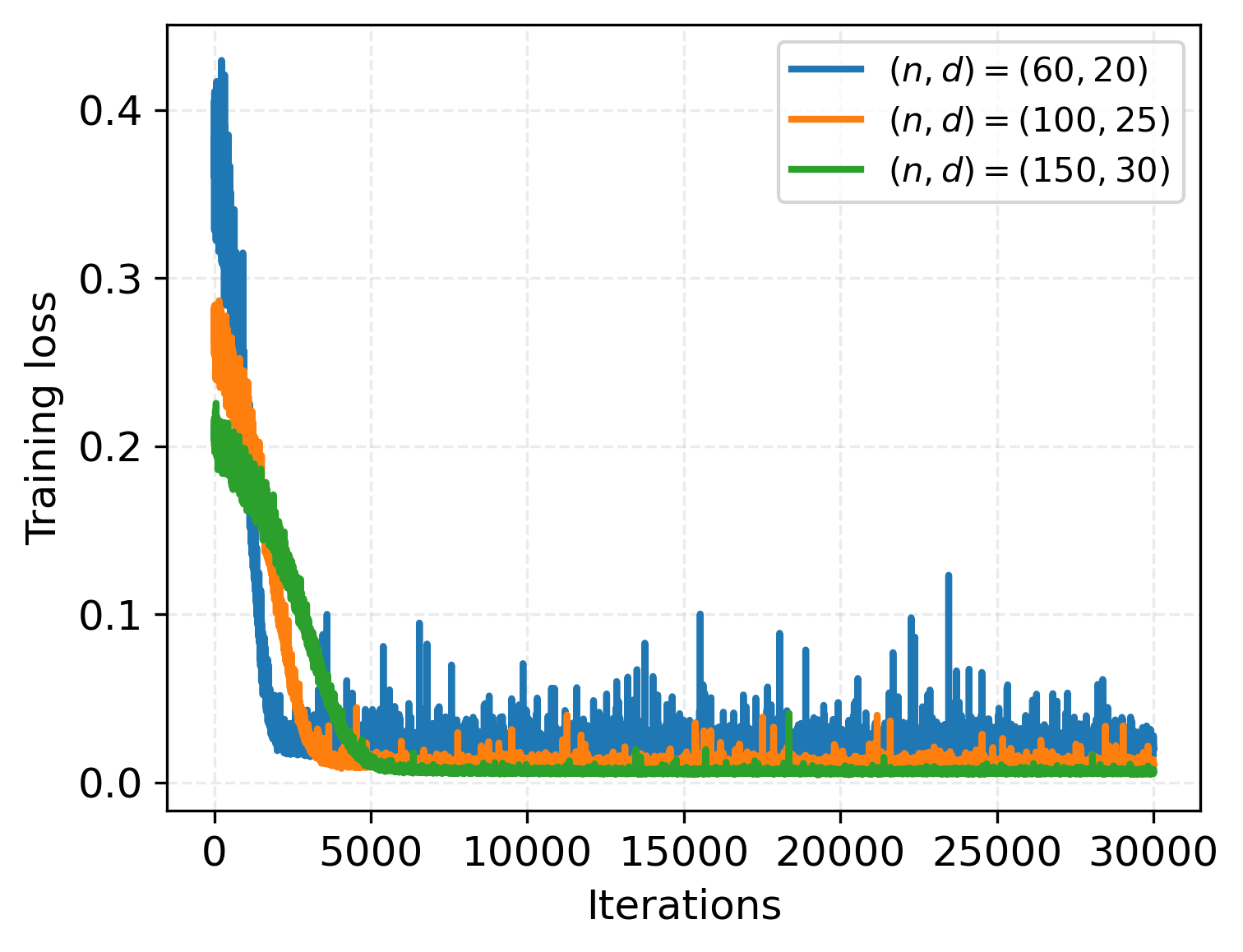
Figure 3: Training loss, α=0.5.
- Heatmaps of learned parameter matrices (V(t), W(t)) confirm that gradient descent preserves the predicted block structure and reduction to a low-dimensional dynamical system.
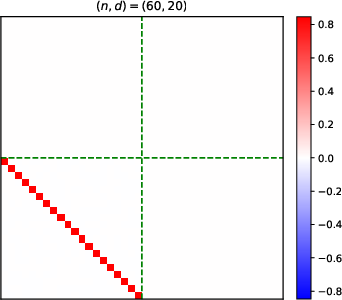
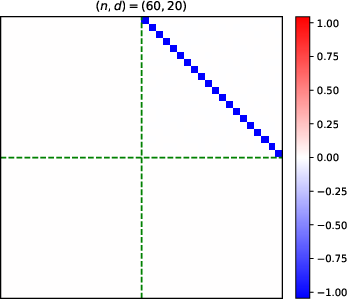
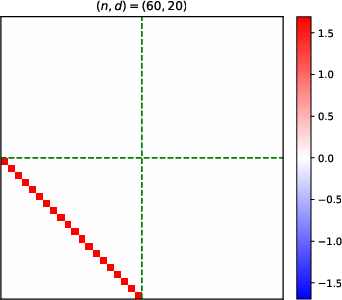
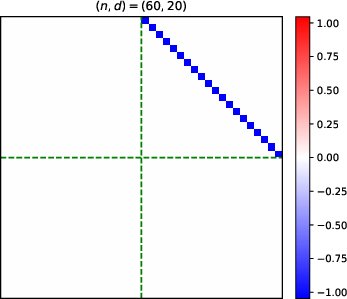
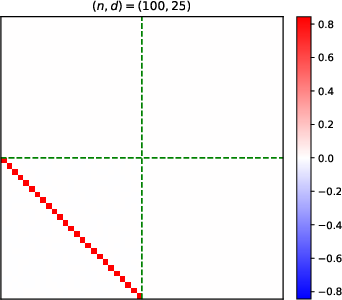
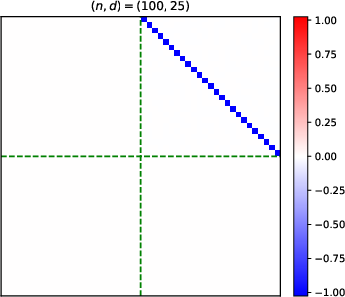
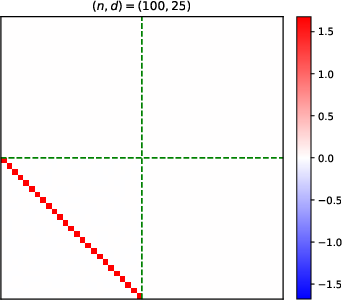
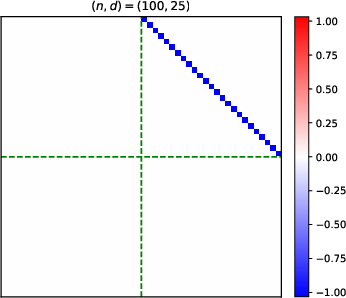
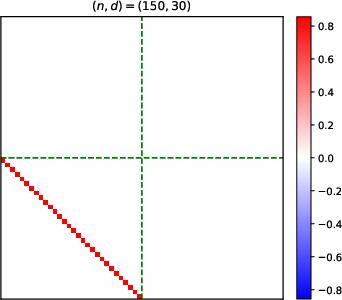
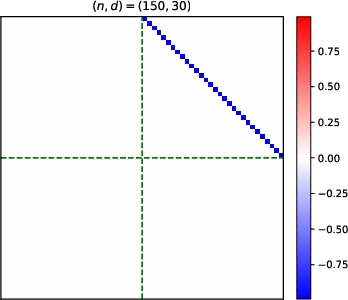
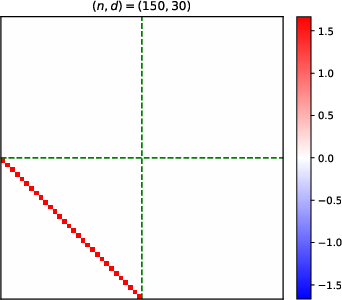
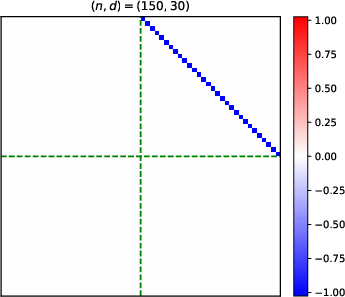
Figure 4: Structure evolution of the V(t) parameter during training with α=0.5 (see main text for analogous W(t) plots).
- Trajectory tracking of scalar update rules aligns precisely with the theoretical NGD parameter dynamics.
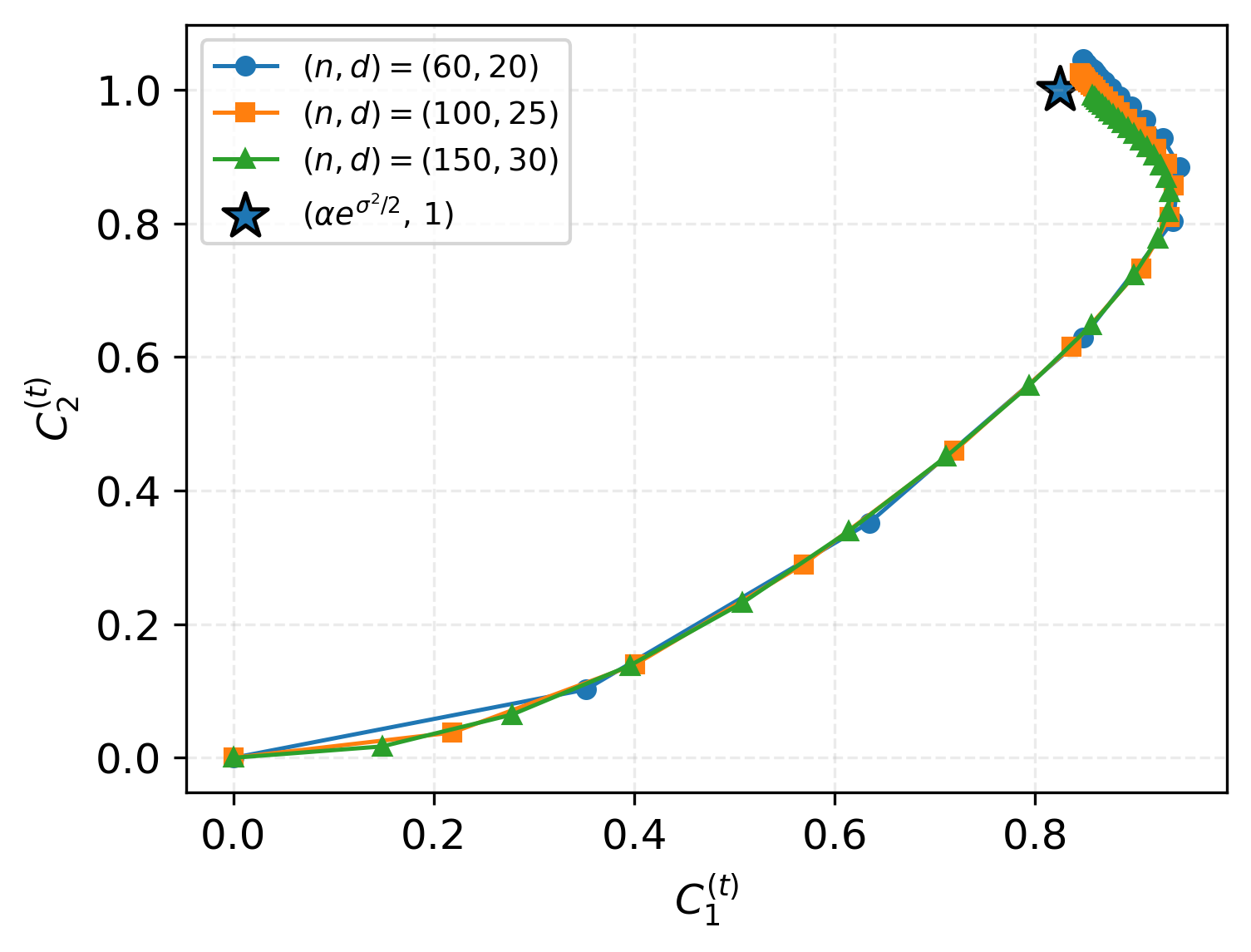
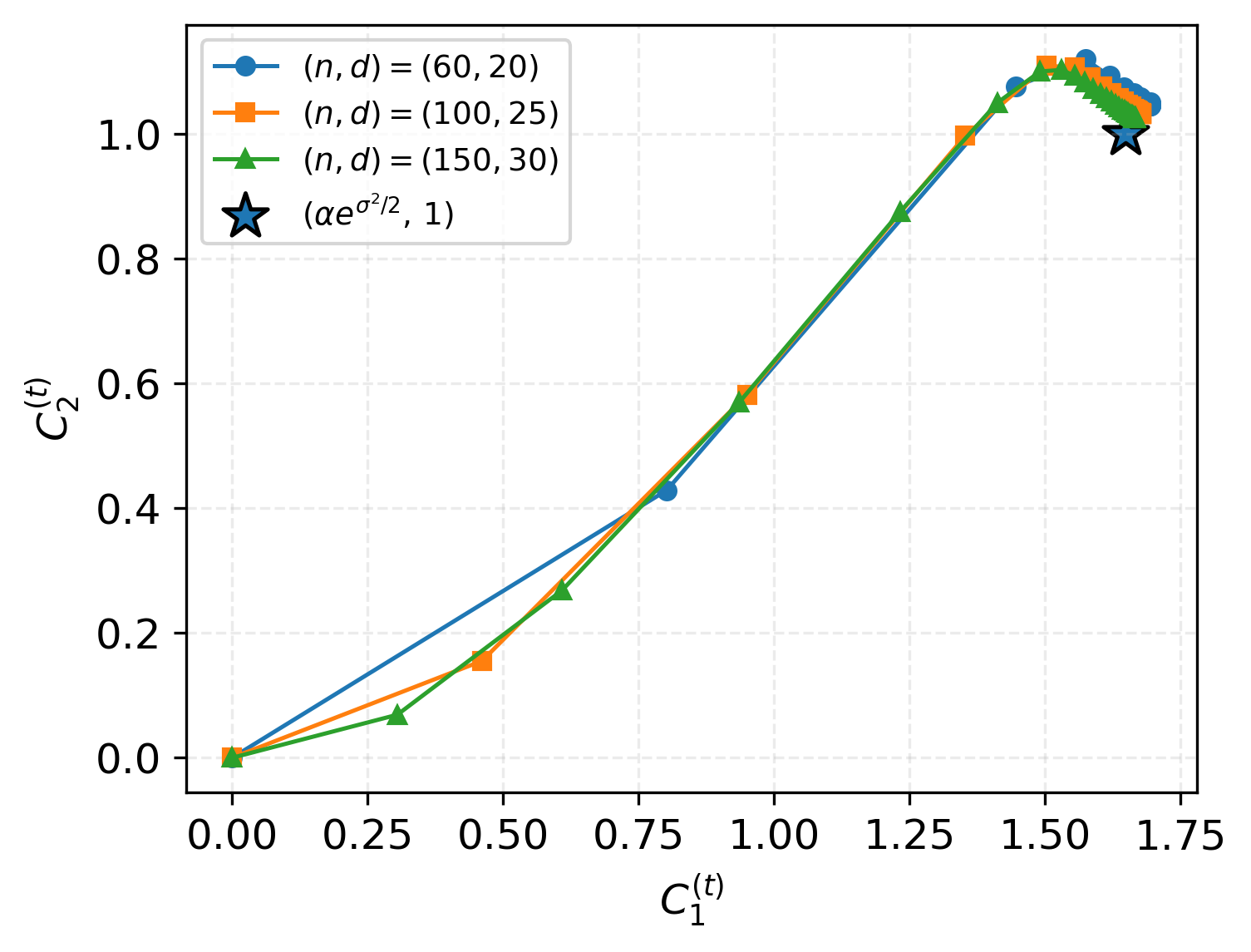
Figure 5: Trajectories, α=0.5; scalar coefficients in the parameterization during SGD iterations.
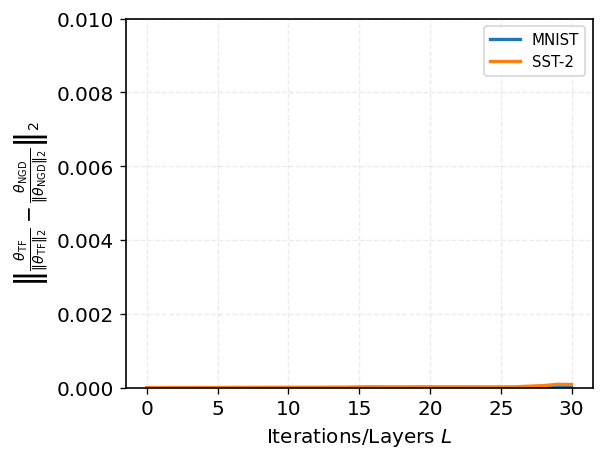
- O.O.D. evaluation on Gaussian, Laplace, and uniform feature contexts shows that looped transformers generalize even to substantial distribution shifts, maintaining low directional error as depth increases.
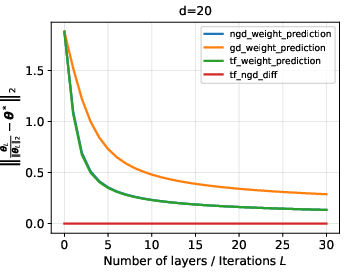
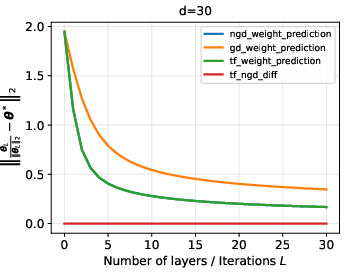
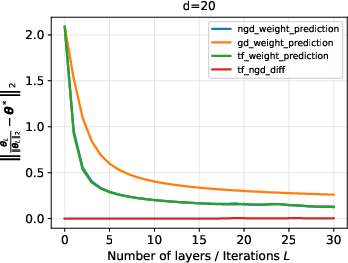
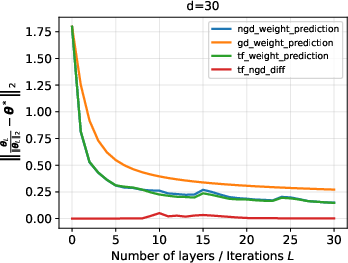
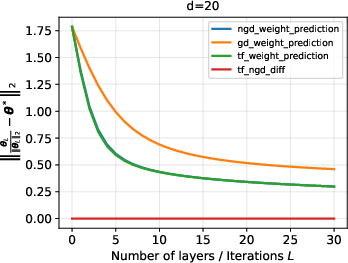
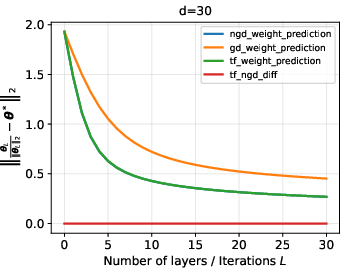
Figure 6: O.O.D. generalization performance for Gaussian data with dimension d=20.
- Performance comparison between transformer outputs, NGD iterates, and standard GD iterates highlights that the transformer closely traces NGD and significantly outperforms standard GD in terms of in-context weight prediction under distribution shift.
- Scaling depth of end-to-end trained looped transformers yields improved weight prediction and faster convergence.
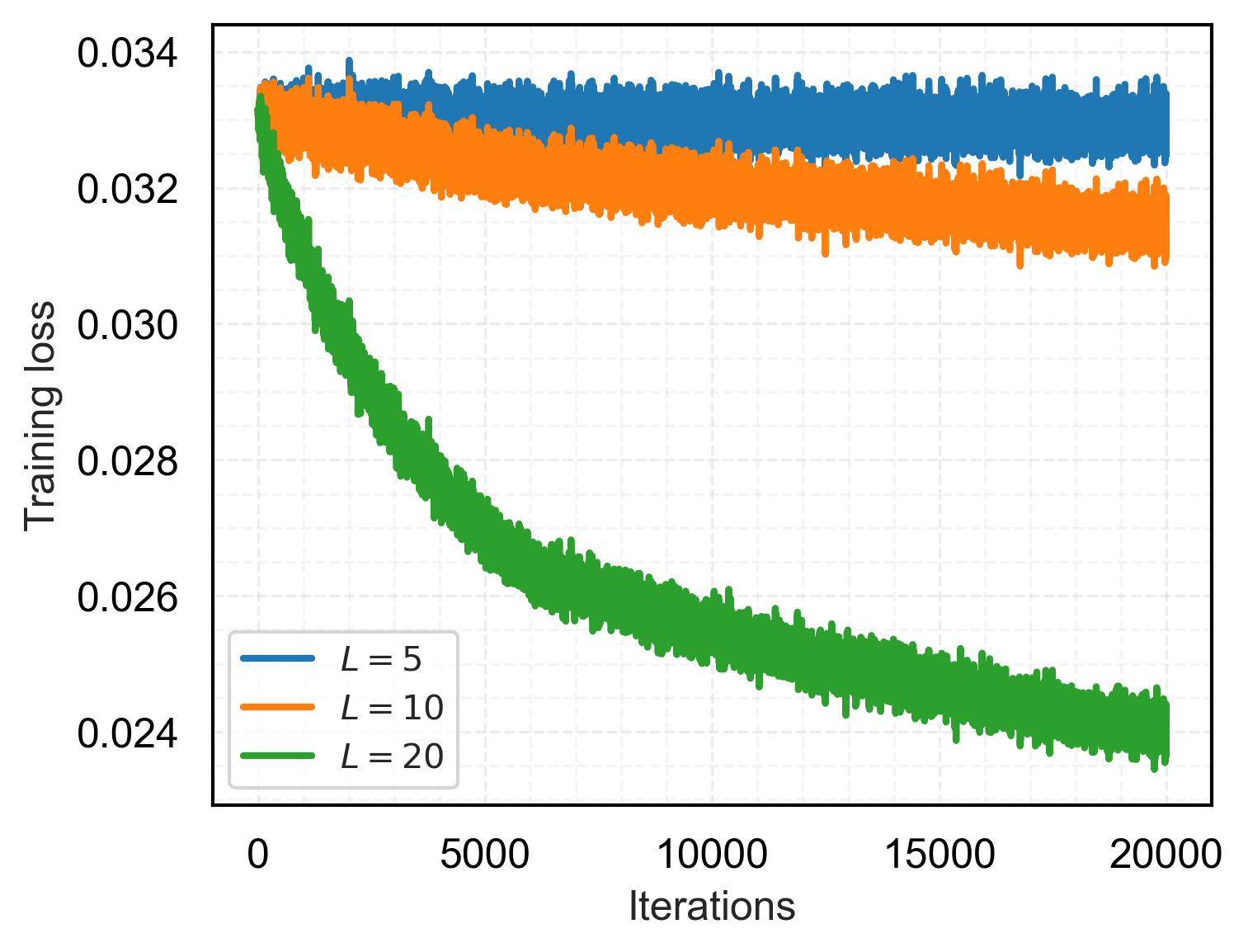
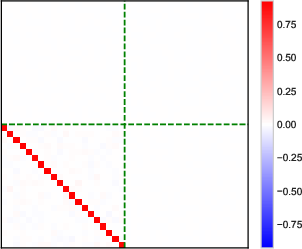
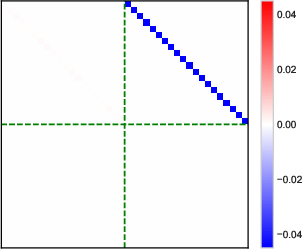
Figure 7: Training loss for varying model depths L∈{5,10,20}.
Numerical and Structural Claims
The paper's strong claims include:
- There exists a single-head deep softmax transformer whose forward pass exactly replicates α=0.50 steps of NGD for exponential loss logistic regression, with no approximation error.
- The O.O.D. generalization error scaling matches the lower bound of PAC learning for linear separators: the dominant term is α=0.51.
- Training a single self-attention layer with SGD under the described protocol (supervised by a GD teacher) always converges to the NGD-implementing structure, regardless of the teacher's use of normalized or non-normalized updates.
- Generalization guarantees are provided pointwise, with high probability, not just in expectation.
Implications and Future Directions
This work advances the mechanistic and statistical understanding of in-context learning with transformers, especially in the classification regime. It demonstrates that standard transformer architectures (without explicit supervision to imitate optimization algorithms) have the structural and learning capacity to internally implement first-order learning algorithms on prompt data—here, specifically, NGD for logistic regression. The equivalence holds exactly, and the inductive bias towards maximum-margin classifiers emerges as a natural consequence of network depth.
From a practical perspective, the results suggest a principled rationale for the empirical benefits of increasing transformer depth in few-shot and in-context learning, especially insofar as richer hierarchical composition allows for more optimization steps and better approximation to optimal solutions. It also gives insight into network design: stacking or looping attention blocks can enhance the model's ability to solve nontrivial algorithmic tasks on-the-fly during inference.
The theoretical techniques introduced—leveraging reductions of the optimization landscape to low-dimensional dynamics, precise trainability analysis under softmax attention, and careful O.O.D. PAC-compliant error control—may find application in broader analyses of expressive and trainable neural sequence models. Extending these techniques to encompass richer data modalities, more general non-linear tasks, or additional architectural components (such as MLP blocks and positional encodings) is a promising direction.
Conclusion
The paper provides a comprehensive theoretical and empirical account of how deep transformers with softmax attention can be constructed and trained to implement normalized gradient descent for in-context logistic regression. The results rigorously link model depth, parameterization, and sample complexity, establishing both mechanistic understanding and generalization guarantees, and are empirically confirmed across synthetic and real-world data domains. This analysis forms a foundational contribution to the theory of algorithmic and statistical properties of in-context learning in modern deep sequence models.