- The paper introduces RLRT, which inverts teacher-student signals by rewarding self-driven, correct reasoning instead of traditional imitation.
- It uses token-level KL divergence to pinpoint critical decision points, amplifying student innovation on verified trajectories.
- Empirical results demonstrate improved training dynamics and up to 18% performance gains across challenging mathematical reasoning benchmarks.
Introduction and Motivation
The paper introduces RLRT (Reinforcement Learning with Verifiable Rewards and Reversed Teacher), a novel framework that inverts the conventional teacher-student self-distillation pipeline in post-training LLMs for reasoning tasks. While prior methods use a “teacher” model (with privileged information) to guide the “student” toward the teacher’s predictions, RLRT proposes to reward moments where the student intentionally diverges from the teacher and still reaches a correct answer. This reinterpretation of the student-teacher gap transforms it from an alignment signal into a valuable driver of exploration, specifically in trajectories exhibiting successful, self-driven reasoning.
This strategy addresses several long-standing RLVR issues: 1) credit assignment bottleneck due to sparse end-of-trajectory rewards, and 2) a collapse of reasoning diversity, where policies concentrate onto limited areas of solution space after extensive RLVR training.
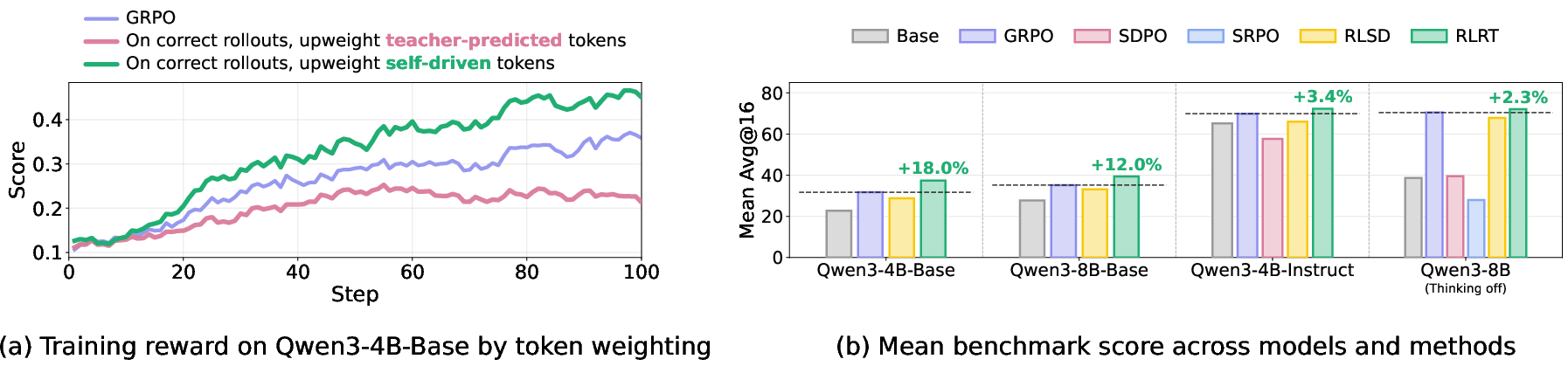
Figure 1: Reversing the teacher signal turns self-distillation from imitation into valuable exploration in RLVR for mathematical reasoning.
Technical Framework
RLRT is built atop the GRPO (Group-Relative Policy Optimization) RLVR paradigm. Key to RLRT's approach is the token-level information asymmetry. For a given trajectory, at each token t, the information asymmetry is captured by
D^t(yt):=logPTt(yt)PSt(yt)
where PSt is the student’s distribution and PTt is the teacher’s (typically conditioned on privileged context). The (expected) position-level asymmetry Dˉt=KL(PSt∥PTt) identifies tokens where the student's distribution diverges from the teacher’s, flagging critical decision points.
Instead of minimizing this asymmetry to align student and teacher (as in SDPO, RLSD), RLRT amplifies self-driven tokens—those for which the student assigns higher likelihood than the teacher—but only on correct trajectories.
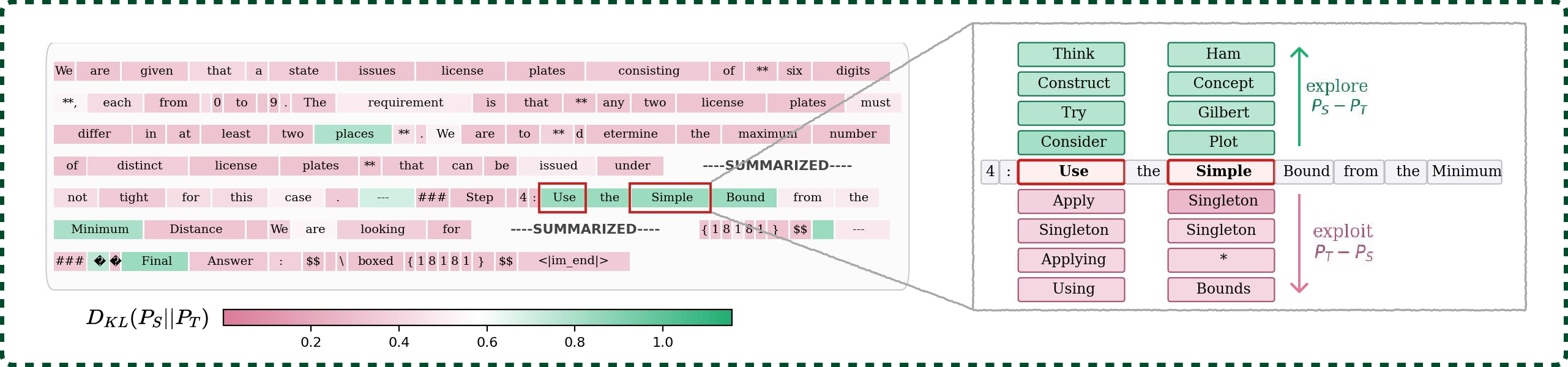
Figure 2: Tokens with large position-level asymmetry Dˉt correspond to critical reasoning decisions; explore (green) versus exploit (pink) candidates are shown at each position.
The rationale is formalized with a Bayesian analysis: Dˉt identifies sensitive decision points, and the sign of D^t separates exploration (student-driven, D^t>0) from exploitation (teacher-driven, D^t<0). RLRT thus sharpens credit assignment without sacrificing solution diversity.
RLRT Algorithmic Implementation
RLRT modifies only the per-token credit assignment in GRPO. For each correct trajectory and token,
D^t(yt):=logPTt(yt)PSt(yt)0
where D^t(yt):=logPTt(yt)PSt(yt)1 is the group-standardized advantage. The update increases weight for self-driven tokens (D^t(yt):=logPTt(yt)PSt(yt)2) on correct rollouts, and appropriately clips or mixes the weight to avoid destabilizing gradients. On incorrect trajectories, RLRT reduces to the vanilla GRPO advantage without augmentation.
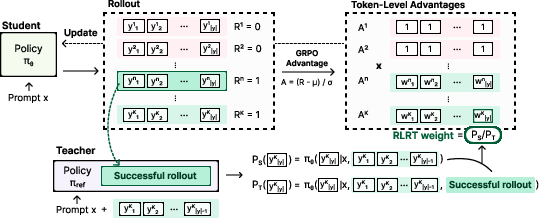
Figure 3: Conceptual illustration of the reversed-teacher signal: RLRT amplifies tokens that capture successful self-driven reasoning.
Empirical Results
Across reasoning-intensive language modeling tasks, RLRT demonstrates substantial improvements in training dynamics, final performance, and exploration efficacy compared to state-of-the-art RLVR and self-distillation baselines.
- On six competitive mathematical reasoning benchmarks (AIME24/25/26, HMMT26, AMC23, MATH500) with several Qwen3 backbone variants, RLRT improves avg@16 by up to 18.0% on base models over the next-best method, with consistent gains on both instruction- and thinking-tuned settings.
- RLRT achieves faster training-score growth, indicating more efficient policy improvement and exploration (see Figure 4).

Figure 4: RLRT achieves faster and higher-scoring training curves across diverse Qwen3 backbones compared to SDPO and GRPO.
- Causal interventions via "reflection injection" show that high-D^t(yt):=logPTt(yt)PSt(yt)3 (critical) positions identified by RLRT truly correspond to decision points causally influencing correctness. Flip rates (wrong→right) at critical positions surpass random or low-asymmetry positions, with RLRT maintaining or amplifying this property through training.
- Token-level analysis reveals that RLRT induces genuinely new distributional shifts: rather than merely sharpening base model preferences, RLRT brings low-probability (under base) tokens to high ranks, promoting deeper, non-local exploration.

Figure 5: Token-level distributional shifts under RLRT reveal more new candidates are promoted to the top, far exceeding vanilla GRPO or RLSD.
- Exploration coverage as measured by pass@D^t(yt):=logPTt(yt)PSt(yt)4 (for large D^t(yt):=logPTt(yt)PSt(yt)5) shows that RLRT outperforms entropy-based and sequence-diversity exploration methods (such as DIVER) at all D^t(yt):=logPTt(yt)PSt(yt)6 values, enhancing reasoning coverage without degeneracy.
Analysis and Ablation
Theoretical and Practical Implications
The findings establish a new design axis—information asymmetry—for exploration in RLVR. Unlike entropy-centric or sequence-diversity heuristics, RLRT leverages the epistemic gap between student and teacher not as an imitation objective, but as a principled signal for identifying and amplifying valuable, empirically verified diversity in successful reasoning.
Practically, RLRT’s approach is compatible with current RLVR pipelines and computationally efficient, as it requires only distributional comparisons at inference. Theoretically, it challenges the alignment-centric dogma of self-distillation, suggesting that selective amplification of student innovation, grounded in outcome verification, is a more effective driver for expanding reasoning capacity.
Future Directions
Potential research avenues include:
- Extending RLRT to settings where the teacher is external or less capable, or where privileged context is partial or noisy.
- Adapting RLRT to multimodal and non-mathematical domains, particularly tasks with sparse or ambiguous supervision signals.
- Integration with off-policy distillation and dynamic routing between teacher-guided and self-driven updates.
Conclusion
RLRT reinterprets the teacher-student asymmetry in self-distillation for RLVR, offering a robust, theoretically justified mechanism for exploration that directly targets innovation in reasoning. Empirical evidence across difficult reasoning tasks and model types demonstrates the superiority of rewarding self-driven, verified divergence over traditional alignment or entropy-driven approaches, marking a substantial advancement in the design of RLVR post-training curricula for LLMs.
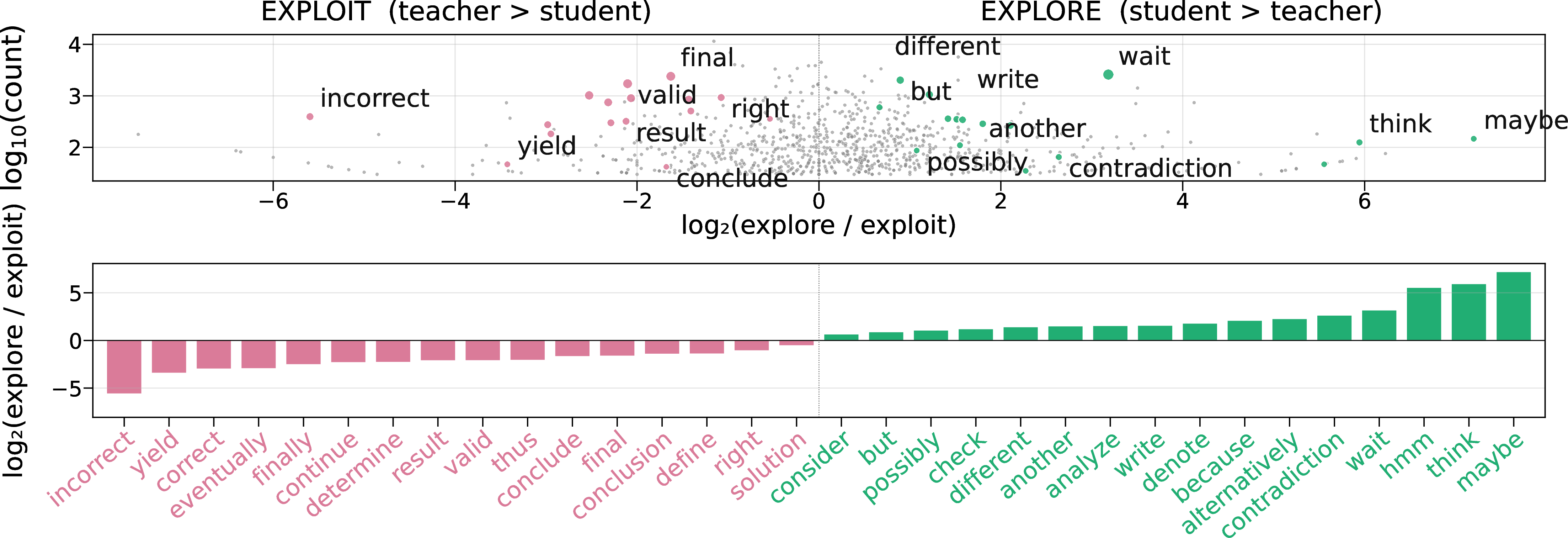
Figure 7: Distribution of explore/exploit linguistic markers shows RLRT encourages reasoning paths associated with deliberation, reflection, and alternative strategies—all key drivers of robust, diverse mathematical problem solving.
