- The paper introduces gradient alignment as a diagnostic measure to compare the teacher’s guidance with the ideal token-level gradient.
- It finds that teacher guidance most benefits student performance on incorrect trajectories, with efficacy varying by model size and demonstration clarity.
- The study reveals that no universal teacher exists, advocating adaptive, context-aware configurations for optimizing reasoning in language models.
Diagnosing On-Policy Distillation: When and Why Teacher Guidance Improves Reasoning Models
Introduction
This work presents a comprehensive analysis of on-policy distillation (OPD) for LLM reasoning, with a focus on mathematically characterizing when teacher supervision actually improves student model performance at the token level. The authors propose a diagnostic pipeline to quantitatively distinguish beneficial, neutral, and detrimental teacher guidance for each token decision—a resolution previously absent in distillation analysis. Crucially, the framework defines an "ideal" gradient at each token: the direction that maximally boosts the student’s probability of success, measured empirically through targeted rollouts. The alignment between this ideal gradient and the actual distillation gradient provides a token-level diagnostic for teacher configuration utility.
This essay systematically discusses the methodology for computing these alignment scores, the empirical results across tasks and model scales, and provides a critical assessment of the practical and theoretical implications.
Theoretical Framework and Methodology
The core contribution is the definition of the "gradient alignment score": a measure of how closely the teacher’s guidance direction matches the empirically optimal update at each token and context. Let Psucck be the empirical probability that, after sampling token k at node u, a student trajectory reaches a correct answer. The ideal objective is Lideal(u)=k∑PθkPsucck, which, when differentiated, yields the per-token reference gradient for updating student logits (see Figure 1).
(Figure 1)
Figure 1: Computing the gradient alignment score at a branching node u; empirical estimates of Psucck inform the ideal gradient, which is compared in direction (cosine) to the distillation gradient for that teacher configuration.
The diagnostic is computationally tractable via a targeted, exponentially windowed rollout scheme which efficiently enriches critical branches of the generation tree. The alignment score (cosine similarity) between the ideal and teacher-induced gradients provides local, actionable signal about teacher utility, bypassing aggregate performance metrics that obscure such fine structure.
Main Findings
1. Gradient Alignment is Highest on Incorrect Trajectories
A strong and consistent pattern is observed across model scales and benchmarks: the teacher’s gradient is significantly more aligned with the ideal reference on incorrect trajectories than on correct ones. That is, when the student deviates from a path leading to success, the teacher’s influence more reliably directs probability mass toward tokens that are empirically associated with correct completion.
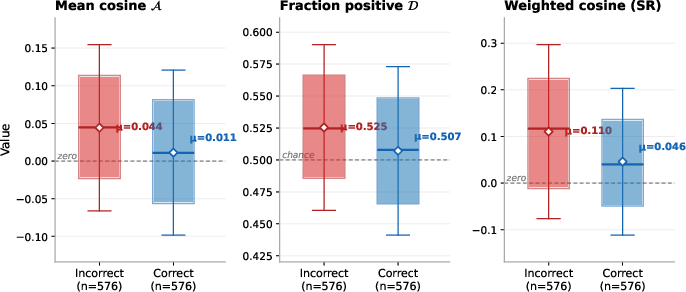
Figure 2: Distribution of gradient alignment as a function of path correctness, showing that alignment is notably higher on incorrect rollouts across teacher types and evaluation metrics.
2. Teacher Efficacy Depends on Student Capacity and Context Comprehensibility
A nuanced relationship emerges between teacher configuration and student model capacity. For smaller students (e.g., Qwen3-0.6B), self-distillation using correct in-context demonstrations (preferably in the model’s own style) is the most reliably aligned teacher. Larger external teachers’ signals are often less interpretable and hence less effective for these students. In contrast, larger students (Qwen3-1.7B) benefit more from external teachers as their capacity enables them to exploit distributional differences and nontrivial reasoning styles.
Summarization of demonstrations brings further complexity: while compressed demonstrations double alignment for large students, small models require full, stepwise traces—highlighting a clear interaction between context complexity and student comprehension.
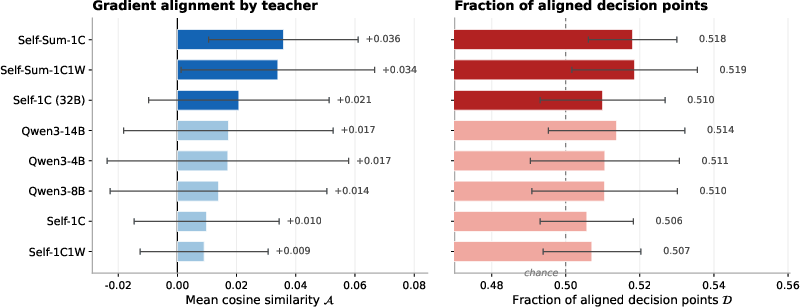
Figure 3: Teacher ranking by gradient alignment for Qwen3-0.6B student on MMLU, illustrating the dominance of self-distillation with correct demonstrations.
Figure 4: Teacher ranking in additional settings; for 1.7B/BoolQ, external teachers outperform, while on MMLU, self-distillation is superior.
3. No Universally Optimal Teacher: Task and Instance Dependency
There is no single teacher or context design that is universally optimal. Optimal configuration shifts with model scale, dataset, and the inherent difficulty and reasoning structure of each task. For example, inclusion of contrastive (wrong) demonstrations may hurt on short-form tasks (BoolQ/MMLU) but help in complex settings (AIME 2025), where common errors are instructive. This mandates per-task and even per-instance diagnostic analysis.
Figure 5: Teacher ranking by gradient alignment for AIME 2025 questions; the best configuration varies with question complexity.
Additional Analyses
Predictors of Alignment
While one might hope for simple proxies (e.g., KL-divergence between student and teacher probabilities) to predict where teacher guidance is helpful, the study finds only weak correlations, indicating that high-divergence is necessary but not sufficient for positive alignment. Alignment also tends to improve with depth into a reasoning chain, corresponding to increased reasoning complexity relative to prompt/boilerplate regions.
Selective Distillation
An upper-bound analysis shows that, if one could restrict distillation updates only to tokens with positive alignment, the effective gradient budget is vastly improved even when using only ~50% of the updates. While such oracle filtering is infeasible at training time, it suggests promise in using divergence-based or outcome-sensitive heuristics.
Implications and Future Directions
Practically, these results caution against monolithic distillation pipelines. Instead, they favor adaptive, diagnostic-driven selection of teacher configurations, possibly modulated at the per-token or per-task level. The heightened utility of teacher signal on incorrect trajectories motivates algorithms that upweight distillation loss on failing rollouts. Multi-teacher or mixture-of-expert configurations may further boost alignment by combining complementary strengths.
Theoretically, all major distillation and reinforcement-style reward objectives are shown to share a common per-token gradient structure, supporting the use of alignment diagnostics for the entire family of token-level training algorithms. This unification will be fundamental as the community continues to search for efficient, scalable, and robust methods for post-training reasoning model improvement.
Conclusion
This paper establishes a rigorous, high-resolution diagnostic for evaluating on-policy distillation algorithms, providing concrete evidence that the benefit of teacher guidance is heterogeneous, primarily realized on student failures, and tightly coupled to capacity and context comprehensibility. No single teacher or context suffices across tasks and conditions. This framework should become standard for analyzing and developing future distillation approaches—motivating (i) adaptive, context-aware pipelines, (ii) real-time diagnostic-informed training strategies, and (iii) rigorous ablation for teacher selection at the per-token level.
The approach also sets a foundation for more general mechanistic interpretability studies of gradient-based learning signals in LLM training regimes.