- The paper presents a thorough empirical and theoretical dissection of on-policy distillation, identifying failures like teacher-student mismatch and biased Top-K reverse KL gradients.
- It shows how specific challenges such as semantic conflicts and unstable loss approximations lead to model collapse, with practical fixes including stop-gradient approaches and RLVR teacher adaptation.
- It demonstrates that supervised fine-tuning (SFT) stabilizes student outputs, ensuring reliable performance in tasks like reasoning, alignment, and prompt internalization.
Comprehensive Analysis of On-Policy Distillation: Failure Modes and Practical Remedies
Introduction and Motivation
On-policy distillation (OPD) and on-policy self-distillation (OPSD) have emerged as core post-training methodologies for LLMs, leveraging the student’s own policy rollouts for dense token-level supervision. OPD provides a framework for integrating external teacher models, offering an avenue for knowledge transfer and mitigating issues such as catastrophic forgetting and sample inefficiency. OPSD, in contrast, uses the student model itself augmented with privileged information (PI) as the teacher, aiming to distill context or alignment behaviors. However, practical deployments reveal a multifaceted landscape: while successes are documented in system prompt internalization and knowledge compression, multiple recent studies report instability, degradation, and outright failure modes, particularly in reasoning tasks. The paper "The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes" (2605.11182) provides a thorough empirical and theoretical dissection of OPD and OPSD, identifying critical failure mechanisms and prescribing robust stabilizers.
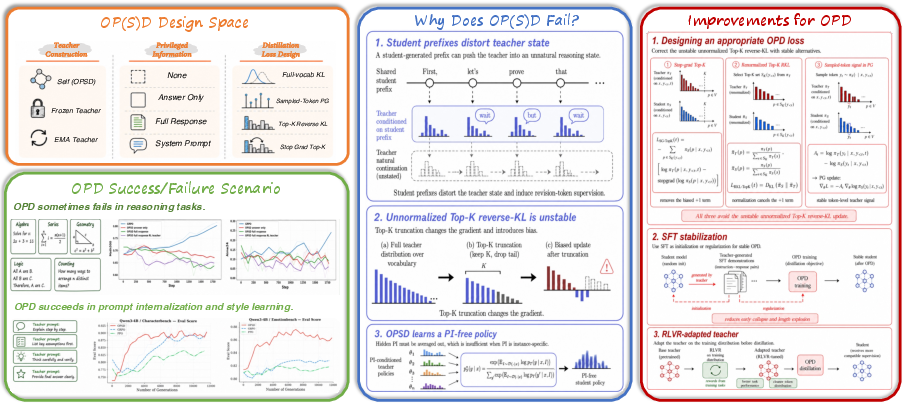
Figure 1: Mapping the OP(S)D design space, mechanisms of failure, and corresponding practical fixes.
Mechanisms of Failure in OPD and OPSD
Teacher-Student Distribution Mismatch
A fundamental limitation arises from conditioning the teacher on prefixes generated by the student. The student’s trajectory may diverge significantly from the teacher’s optimal reasoning path, leading to semantic conflict and locally incompatible token-level supervision. Empirical analysis demonstrates that the teacher’s accuracy substantially decreases when forced to continue from truncated student trajectories compared to standalone reasoning.
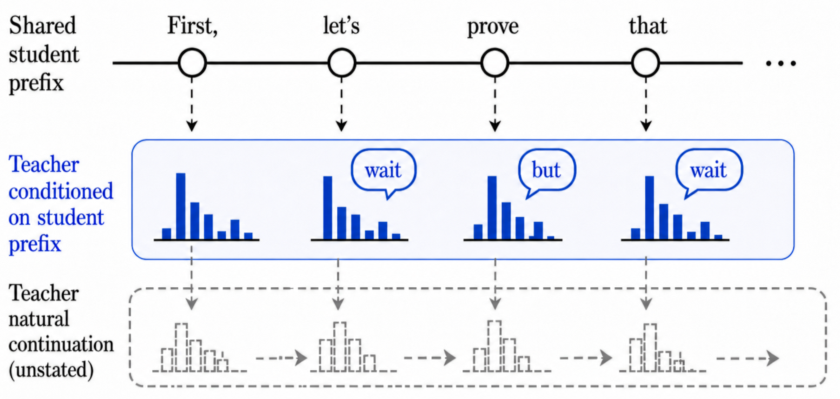
Figure 2: Local semantic conflict induced by student prefixes; teacher supervises branch switching rather than branch refinement, often via revision tokens.
Instability of Top-K Reverse KL Objectives
To make full-vocabulary KL objectives computationally tractable, Top-K approximations are typically employed. However, the unnormalized Top-K reverse KL introduces biased gradient terms due to incomplete cancellation of constant terms, destabilizing optimization and culminating in model collapse and repetitive behaviors.
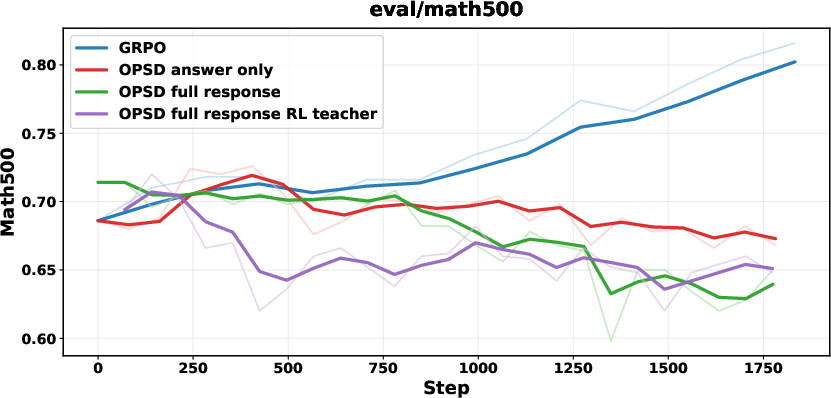
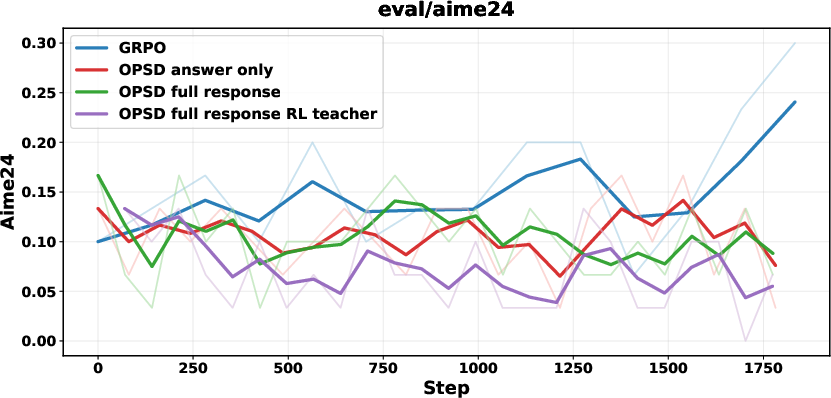
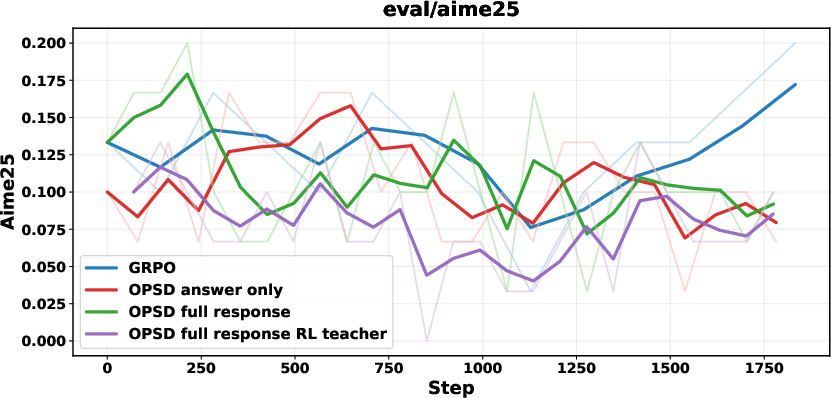
Figure 3: OPSD under math reasoning fails to yield improvement; student models collapse with verbose or degenerate outputs.
OPSD attempts to marginalize across PI-conditioned teachers, learning a PI-free consensus policy. When PI is instance-specific rather than reflecting a shared latent rule, this aggregation causes suppression of outputs supported only in certain PI contexts and further weakens the distilled model relative to PI-conditioned teachers.
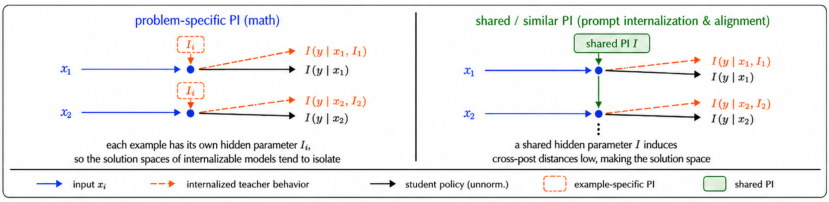
Figure 4: Effectiveness of OPSD heavily depends on the nature and structure of privileged information.
Empirical Characterization Across Tasks
Mathematical Reasoning
OPSD is empirically ineffective for math reasoning—neither answer-only nor full-response PI yields improvement, and RLVR-trained teachers further exacerbate mismatch. OPD using stronger teachers provides initial gains but collapses after successive training steps, manifesting as length explosion and repetitive token sequences.
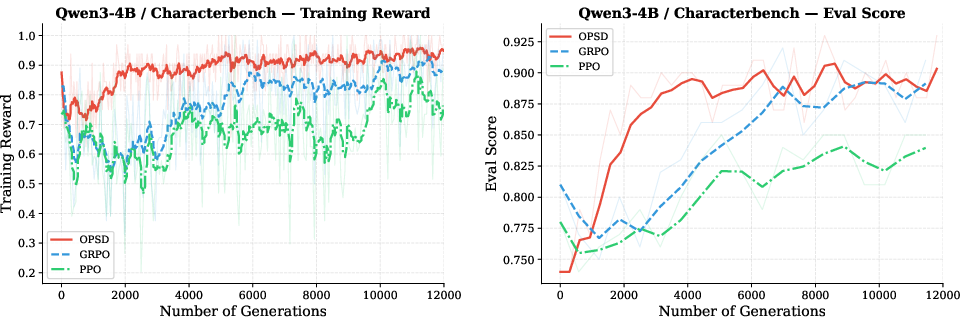
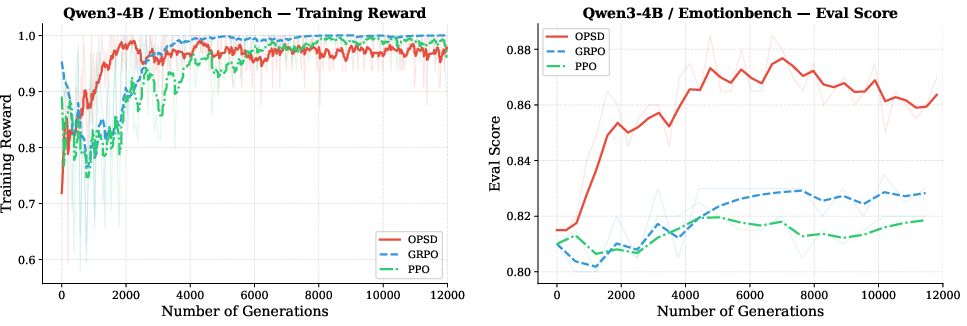
Figure 5: OPD, GRPO, and PPO comparison on style alignment tasks; OPSD demonstrates superior sample efficiency.
Alignment and Prompt Internalization
For tasks such as style alignment (CharacterBench, EmotionBench) and system prompt internalization, OPSD excels. Here, PI represents a fixed latent rule or prompt, allowing the student to internalize alignment protocols and achieve rapid convergence versus RL baselines.
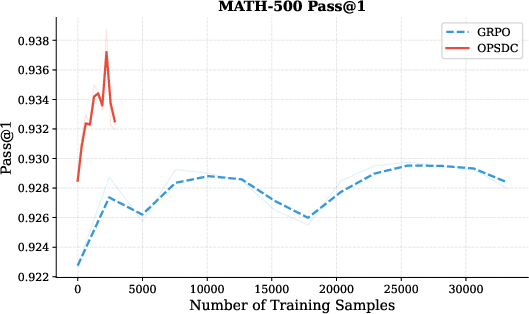
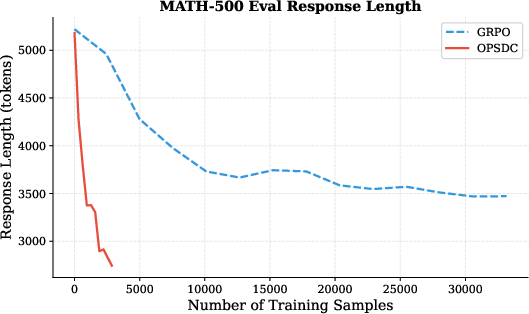
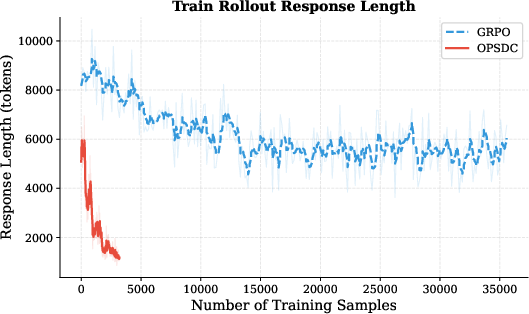
Figure 6: OPSD versus GRPO on reasoning compression; OPSD provides similar accuracy but more efficient compression of response length.
Task-specific analyses highlight that effectiveness is determined by PI structure: global PI (system prompts, style instructions) admits successful distillation, while instance-specific PI induces conflicting supervision.
Practical Fixes and Stabilizing Strategies
Stop-Gradient and Renormalized Top-K KL Losses
Biased gradients in unnormalized Top-K reverse KL are mitigated with a stop-gradient formulation, renormalization within the Top-K set, or sampled-token policy-gradient objectives. These corrections ensure stability and prevent collapse.
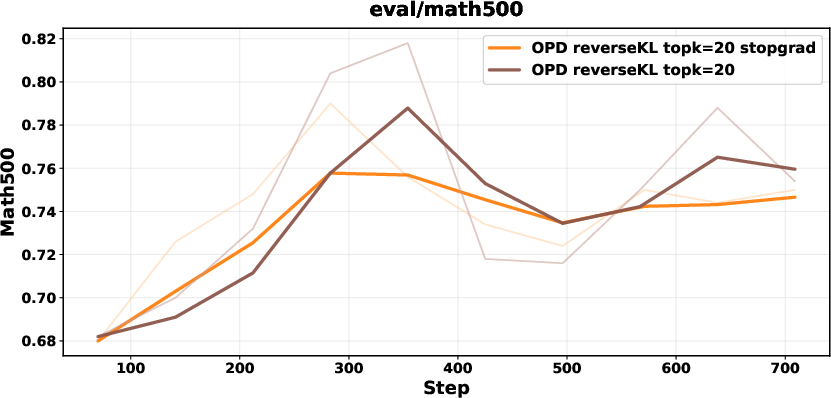
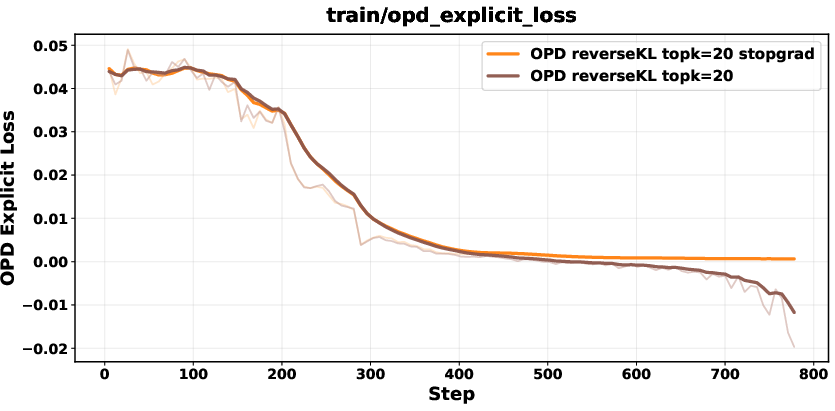
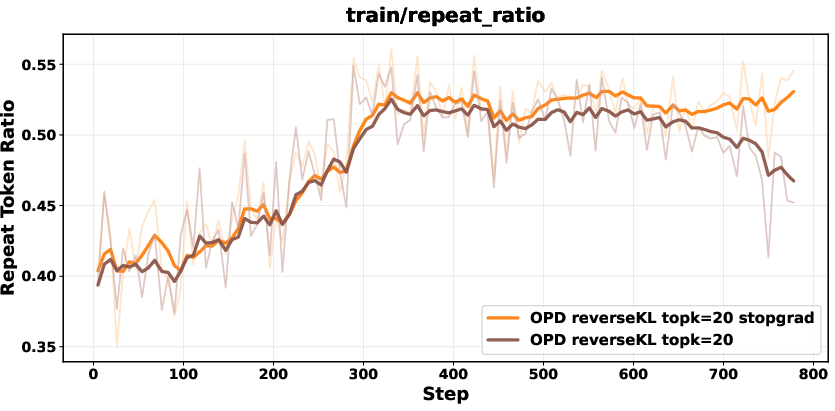
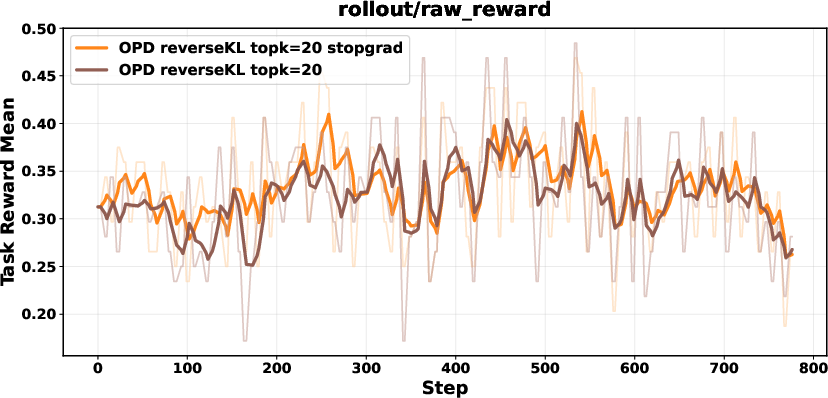
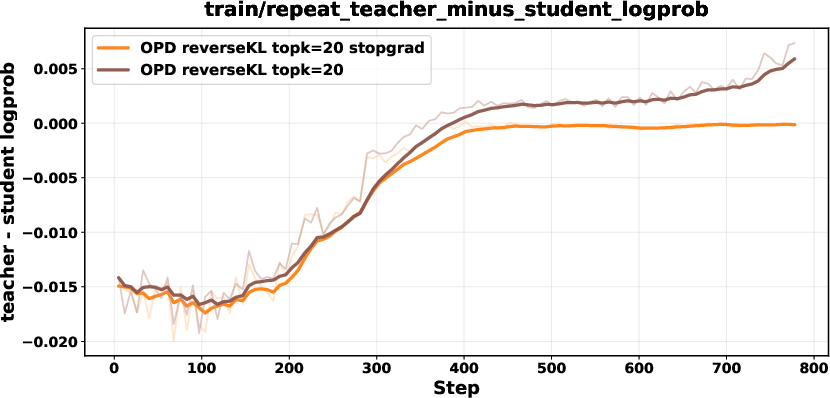
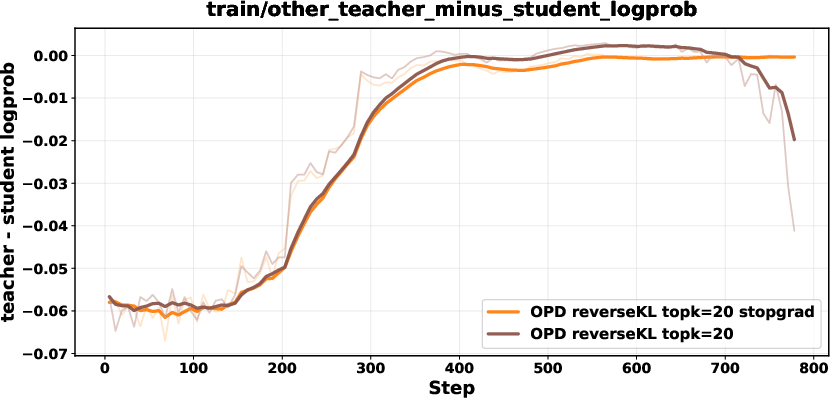
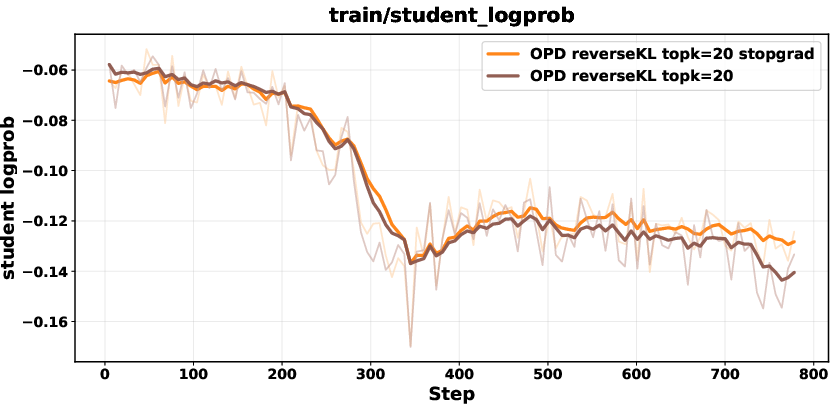
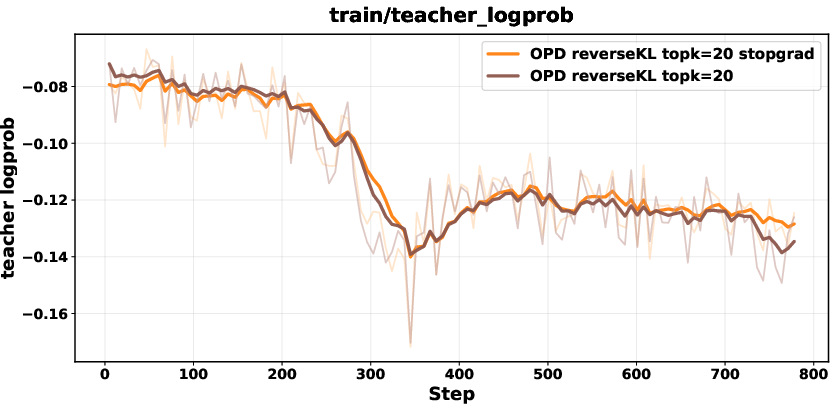
Figure 7: Comparison between biased reverse KL and stopgrad-based approaches; stop-gradient variant achieves stable performance.
RLVR Teacher Adaptation
Adapting the teacher with RLVR on the student’s distribution aligns the teacher’s outputs more closely with student prefixes, decreasing mismatch and boosting distillation efficacy even when teacher benchmark accuracy is not superior.
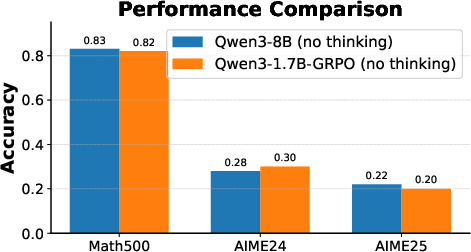
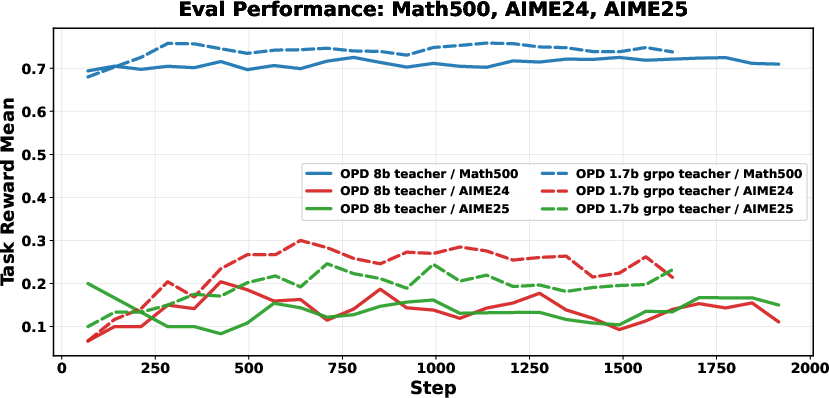
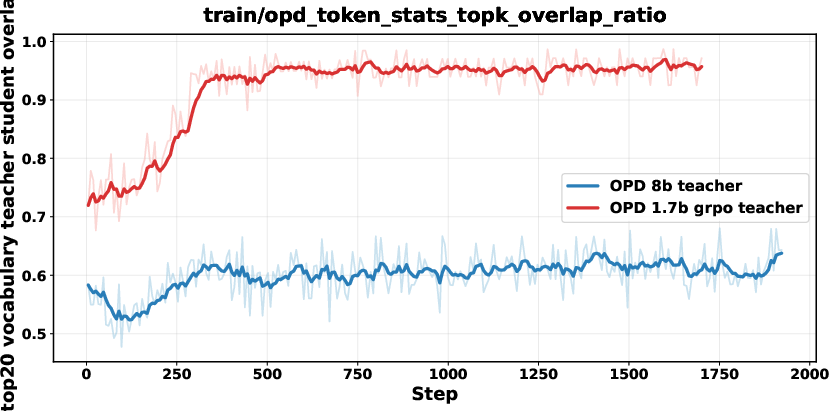
Figure 8: RLVR-adapted teacher and standard teacher comparison; adapted teacher distribution aligns more tightly with student distribution.
Supervised Fine-Tuning (SFT) Stabilization
SFT on teacher-generated traces regularizes the student’s output space, prevents degenerate token sequences, and ensures well-formed regions during OPD. This is particularly evident in cases where students initially generate non-semantic outputs or garbled sequences.
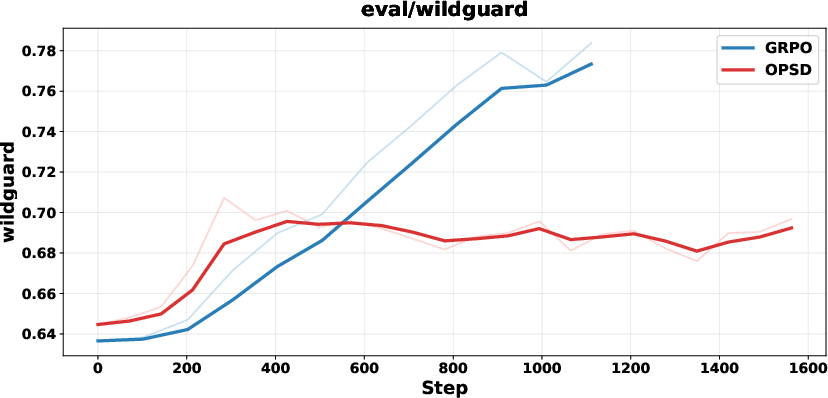
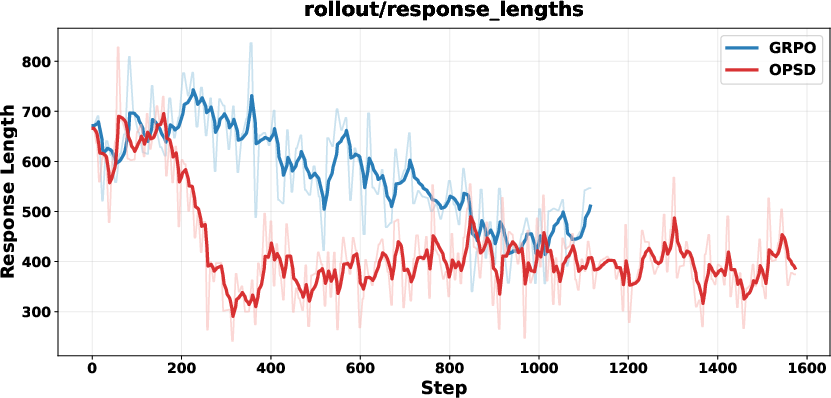
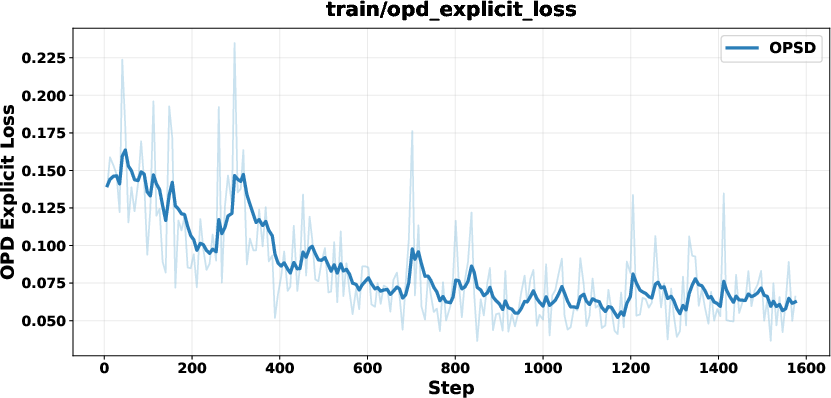
Figure 9: SFT regularization prevents collapse and length explosion, maintaining output consistency on alignment and safety tasks.
Analysis of Supervision Signal and Token Dynamics
Teacher supervision is found to be correctness-skewed and position-dependent: the supervision signal is stronger on incorrect trajectories and early tokens, gradually fading on correct answers and longer responses. PI and teacher model scale modulate the distribution of supervision, but fundamental signal quality is governed by teacher capability.

Figure 10: Heatmap visualization of token-level supervision; PI refines granularity but teacher scale dictates overall distribution.
Implications and Future Directions
The study conclusively establishes that OPD and OPSD are not universally reliable and their efficacy is contingent on task structure, teacher adaptation, loss formulation, and PI properties. The findings direct future research toward hybrid pipelines combining SFT initialization, RL task-specific optimization, and OPD distillation, potentially unlocking iterative self-improvement mechanisms for LLMs. The theoretical analysis further invites exploration in scalable distillation objectives and active teacher-student curriculum design to balance generalization and specialization.
Conclusion
"The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes" provides a granular analysis of OPD and OPSD, revealing critical failure mechanisms and prescriptive remedies. Effectiveness is fundamentally constrained by teacher-student distribution compatibility, loss formulation, and privileged information structure. Stabilization via stop-gradient KL surrogates, RLVR adaptation, and SFT regularization ensures practical training stability and effective distillation. These insights lay the foundation for more robust post-training protocols and advances in dynamic LLM alignment, system internalization, and reasoning compression.

