- The paper introduces OGLS-SD, which uses outcome-guided logit steering to overcome teacher–student mismatches in on-policy self-distillation.
- The framework leverages contrastive logits from correct and incorrect rollouts to enhance training stability and reasoning accuracy on benchmarks.
- Empirical results on mathematical reasoning datasets show that OGLS-SD outperforms traditional SFT, RL methods, and vanilla OPSD while preserving epistemic markers.
Outcome-Guided Logit Steering for Stabilizing On-Policy Self-Distillation in LLM Reasoning
Introduction
On-Policy Self-Distillation (OPSD) has emerged as a critical paradigm for post-training LLMs, enabling self-improvement by leveraging privileged guidance from the same underlying model. Despite gains in sample efficiency and performance over traditional RL-with-sparse-rewards approaches, standard OPSD instability—marked by performance collapse and miscalibration—limits its effectiveness. The paper "OGLS-SD: On-Policy Self-Distillation with Outcome-Guided Logit Steering for LLM Reasoning" (2605.12400) presents a rigorous analysis of the sources of teacher–student mismatch in OPSD and introduces the OGLS-SD framework to address these issues via outcome-guided logit steering, producing demonstrable improvements in both training stability and final performance on reasoning benchmarks.
The primary challenge with vanilla OPSD arises from the distributional mismatch between teacher and student outputs. The teacher is instantiated by conditioning the same model on privileged information (e.g., reference solutions), which induces solution-specific bias and overconfident token-level distributions. These mismatches are exacerbated by the fact that, at test time, the student lacks access to the privileged context, rendering the direct matching of teacher and student conditionals ill-posed due to irreducible information asymmetry.
The paper hypothesizes, and empirically supports, that this privileged-induced mismatch—particularly its solution-agnostic overconfidence—can propagate through distillation, degrading reasoning robustness and answer correctness. This problem persists even when using marginalization over privileged contexts, reflecting underlying prompt-induced distributional shifts that are not addressed by naive OPSD, as further illustrated in a controlled toy setting.
OGLS-SD: Outcome-Guided Logit Steering
Method Overview
OGLS-SD mitigates these issues by explicitly contrasting the teacher's logits arising from both successful (correct) and failed (incorrect) on-policy rollouts. For each input, the framework:
- Generates K student rollouts.
- Partitions rollouts into correct and incorrect pools via verifiable outcome rewards.
- Computes average teacher logits for each pool, conditioned on the reference context for correct rollouts and analogously for incorrect rollouts.
- Defines a steering direction Δ as the logit difference between correct and incorrect averages.
- Adjusts base teacher logits by λΔ to produce the steered teacher distribution for token-level supervision.
This process is visualized in the method schematic:
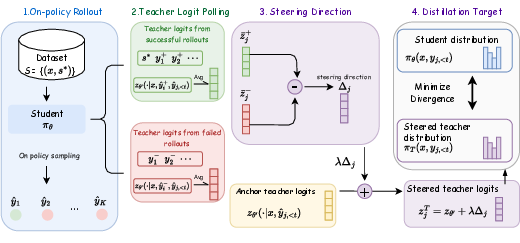
Figure 1: High-level procedure for OGLS-SD, highlighting the extraction and construction of the steering direction for distributional calibration.
The core insight is that both correct and incorrect privileged teachers share certain systematic overconfidence components, but the contrastive operation selectively preserves correctness signals and attenuates spuriously overconfident guidance. This mechanism prevents premature overfitting to privileged artifacts and aligns the student’s distribution with genuinely discriminative features of successful reasoning.
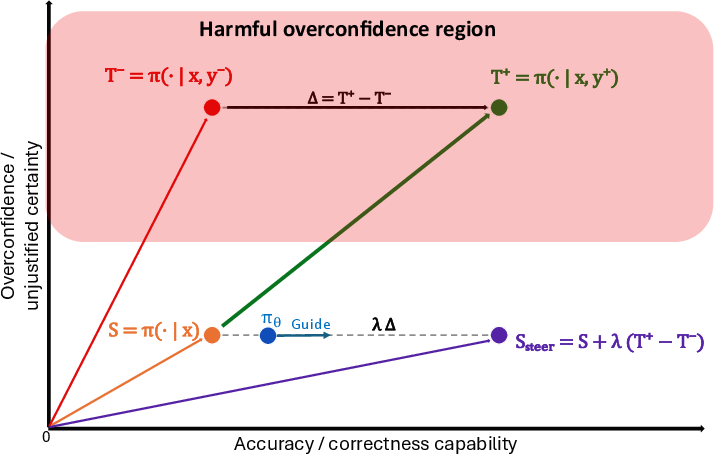
Figure 2: The steering vector guides the student distribution towards correctness without further entrenching overconfidence.
Experimental Results
Main Benchmarks
Evaluations on mathematical reasoning datasets (AIME 2024/2025) with Qwen3-1.7B and Qwen3-4B models demonstrate that OGLS-SD consistently surpasses SFT, reward-based RL (GRPO), and vanilla OPSD. For Qwen3-1.7B, OGLS-SD achieves mean@8 scores of 59.2 (AIME24) and 45.0 (AIME25), outperforming OPSD baselines (56.3/40.8) and GRPO (51.1/38.3). Analogous improvements are observed for Qwen3-4B. Notably, OGLS-SD yields more stable training trajectories, avoiding the characteristic mid-training performance collapse of OPSD.
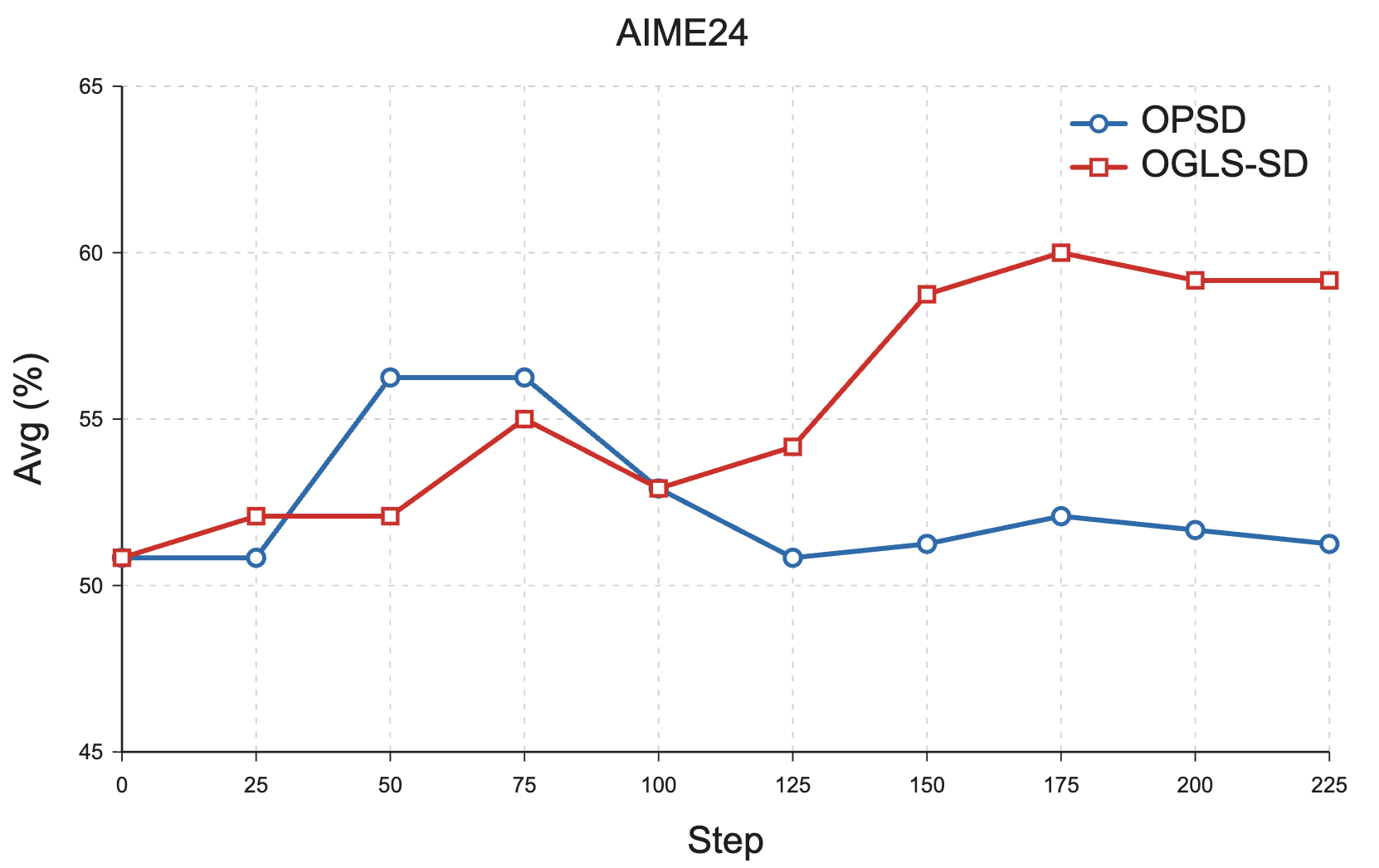
Figure 3: OGLS-SD provides a stable performance improvement curve; OPSD degrades due to teacher–student pattern mismatch.
Behavioral Analysis
A critical finding is the preservation of explicit epistemic reflection in OGLS-SD-trained models. Frequency analysis of epistemic markers in reasoning traces shows that OPSD suppresses these markers, while OGLS-SD increases their prevalence, correlating with improved robustness and solution verification behaviors.
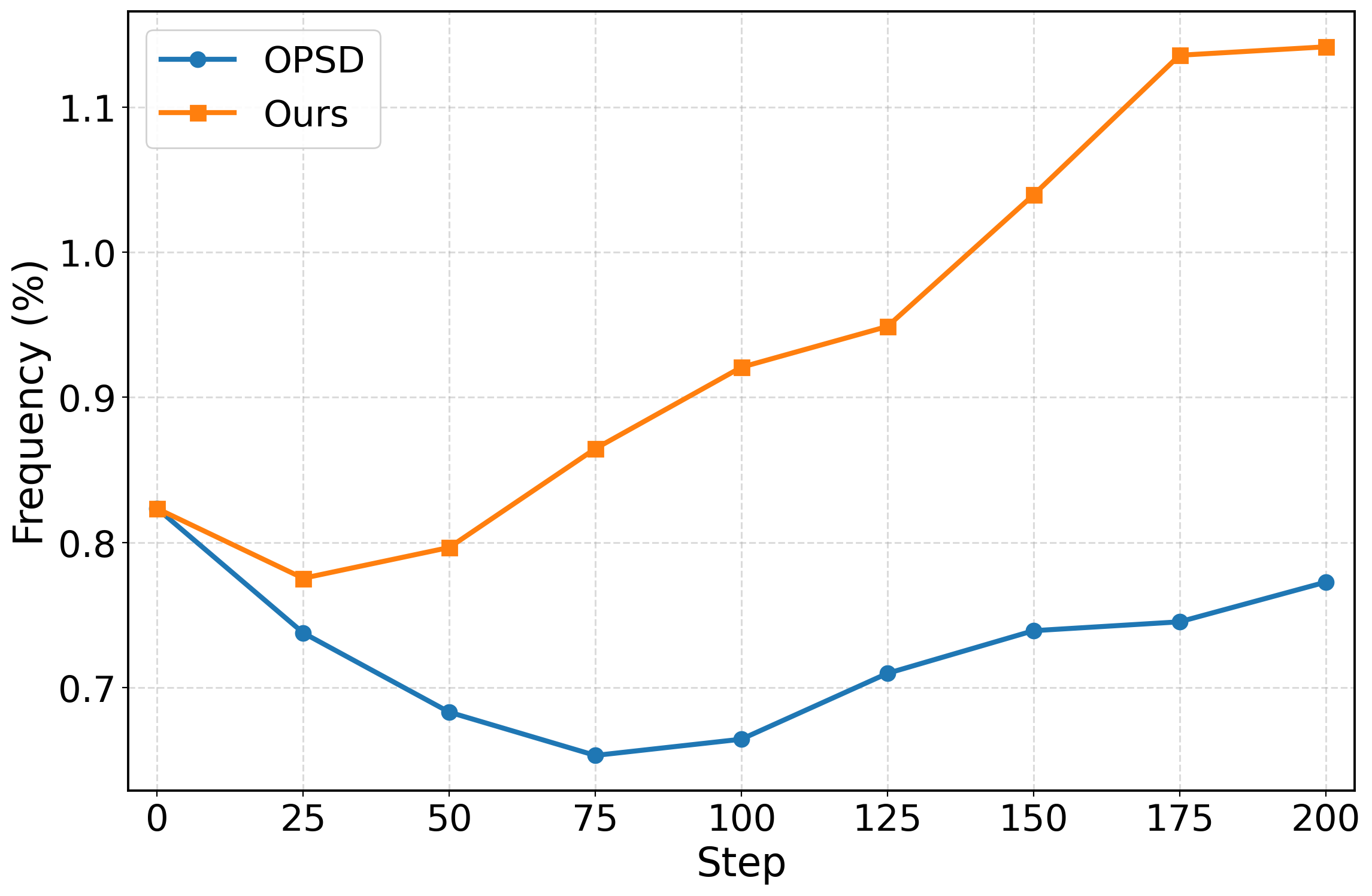
Figure 4: OGLS-SD maintains higher rates of explicit epistemic reflection, suggesting better cognitive calibration.
Qualitative case studies reveal differentiated error correction dynamics in OGLS-SD compared to OPSD. OGLS-SD models revisit uncertain reasoning steps, leading to more reliable answer generation.

Figure 5: OGLS-SD corrects role assignment errors via epistemic revisiting, unlike OPSD which overconfidently outputs incorrect complements.
Ablation Studies
Ablations address two possible confounds: (i) averaging positive privileged contexts (mean teacher) and (ii) amplifying positive guidance without negative rollouts. The positive-mean-teacher variant yields modest gains in stability but is inferior to OGLS-SD. Positive-only steering temporarily boosts early performance but ultimately destabilizes training, confirming that explicit positive–negative contrast rather than mere amplification underpins OGLS-SD’s superior performance.
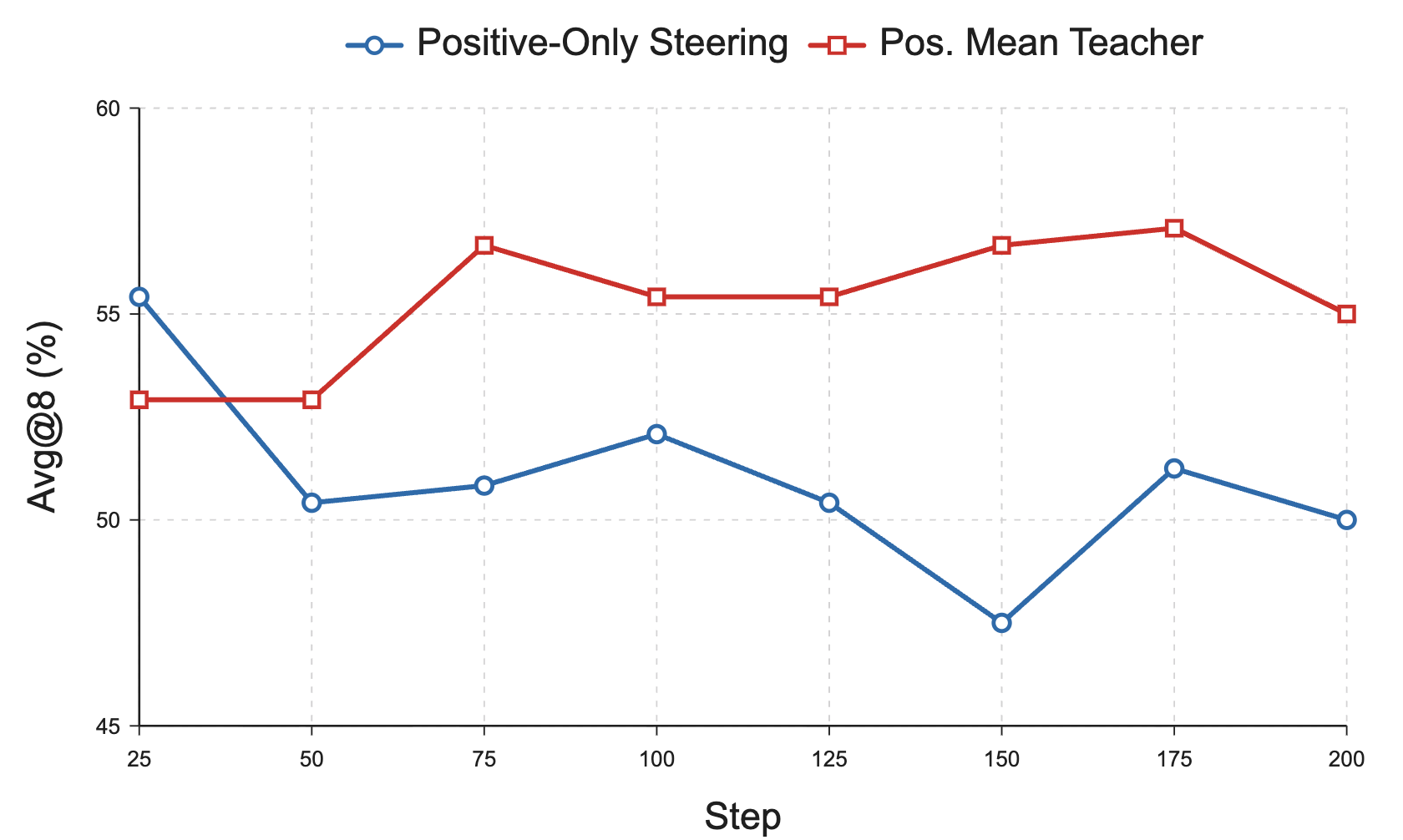
Figure 6: OGLS-SD uniquely avoids the early performance collapse exhibited by positive-only variants.
Theoretical and Practical Implications
Theoretically, OGLS-SD interrogates the limitations of prompt-conditioned self-distillation, emphasizing that even marginalization over privileged rollouts cannot neutralize prompt-induced calibration artifacts. The framework directly operationalizes outcome-driven contrast in the guidance signal, fundamentally altering the information geometry by which the student is updated.
Practically, OGLS-SD offers a robust methodology for industrial post-training pipelines where external large-teacher models are infeasible and where maximizing stability and credit assignment efficiency is critical. Its adoption is likely to be valuable for large-scale reasoning model deployment in domains requiring strong generalization and resistance to overconfident but spurious reasoning patterns.
Extensions and Future Work
Future inquiry may include extending OGLS-SD to multi-modal LLMs, applying similar outcome-guided contrastive calibration in generative policy distillation for agents, or adapting the framework to alleviate reward model bias in RLHF settings. The connection between explicit epistemic marker preservation and downstream reasoning reliability also warrants broader exploration.
Additionally, the paper's toy example exposes a generalizable prompt-induced marginalization mismatch in current LLMs—a phenomenon critical to the theoretical integrity of model alignment protocols.
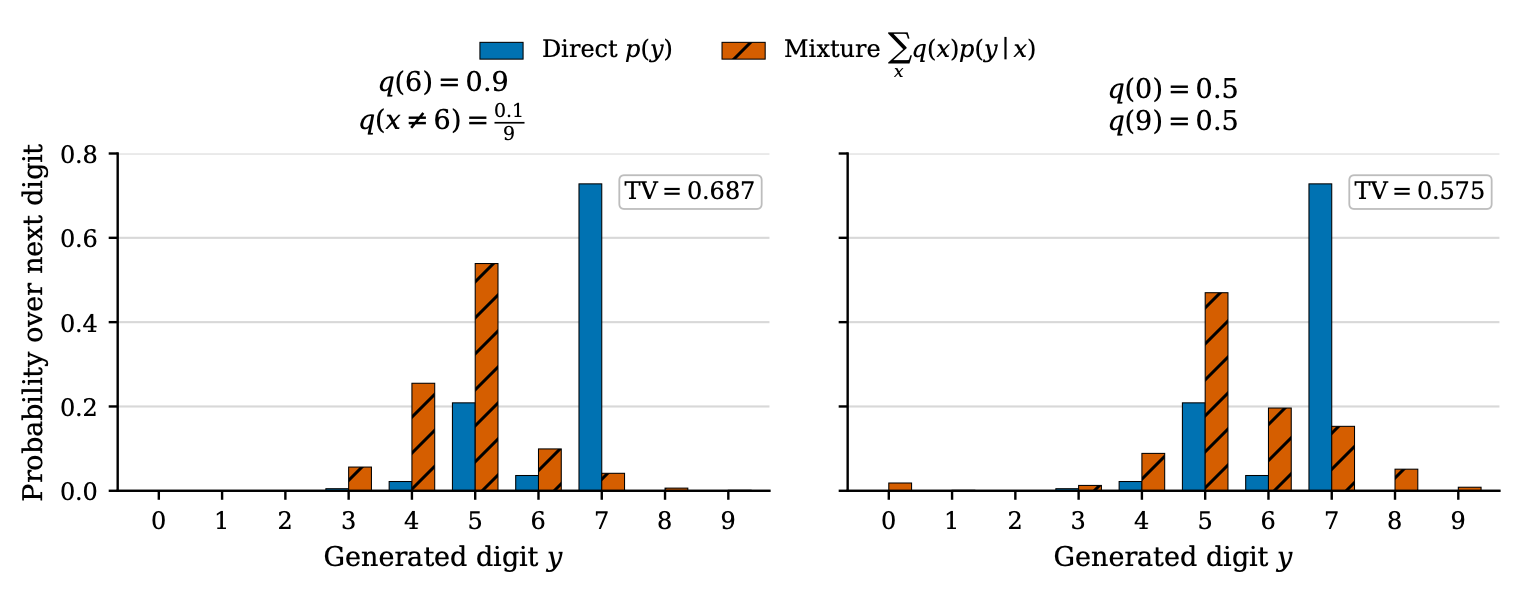
Figure 7: Averaging over privileged contexts via prompt marginalization does not, in general, recover the unprivileged generation distribution.
Conclusion
OGLS-SD establishes outcome-guided logit steering as a rigorous, empirically validated solution to the instability of on-policy self-distillation in LLM reasoning. Its design explicitly addresses the core issue of teacher–student pattern mismatch by constructing and applying a calibrated contrastive steering signal. This results in improved stability, higher accuracy, and preservation of critical epistemic behaviors, underpinning its utility for both future research and applied deployment in high-stakes reasoning tasks.

