On-Policy Context Distillation for Language Models
Published 12 Feb 2026 in cs.CL | (2602.12275v1)
Abstract: Context distillation enables LLMs to internalize in-context knowledge into their parameters. In our work, we propose On-Policy Context Distillation (OPCD), a framework that bridges on-policy distillation with context distillation by training a student model on its own generated trajectories while minimizing reverse Kullback-Leibler divergence against a context-conditioned teacher. We demonstrate the effectiveness of OPCD on two important applications: experiential knowledge distillation, where models extract and consolidate transferable knowledge from their historical solution traces, and system prompt distillation, where models internalize beneficial behaviors encoded in optimized prompts. Across mathematical reasoning, text-based games, and domain-specific tasks, OPCD consistently outperforms baseline methods, achieving higher task accuracy while better preserving out-of-distribution capabilities. We further show that OPCD enables effective cross-size distillation, where smaller student models can internalize experiential knowledge from larger teachers.
The paper presents On-Policy Context Distillation (OPCD) to internalize transient context via reverse KL on policy trajectories, eliminating exposure bias.
It employs a teacher-student framework to distill experiential and system prompt knowledge, enhancing both in-distribution and out-of-distribution performance.
Empirical results reveal stair-step accuracy improvements and mitigation of catastrophic forgetting, demonstrating the method's scalability and robustness.
On-Policy Context Distillation for LLMs
Motivation and Problem Statement
Parameterizing persistent knowledge in LLMs via in-context prompts or system instructions incurs substantial runtime and memory overhead and presents an upper bound on achievable in-distribution adaptation. Existing context distillation approaches recast this as knowledge compression through imitation learning by treating the context-conditioned expert as a teacher and offloading the context into a student’s parameters. However, conventional off-policy distillation via forward KL leads to exposure bias and mode-covering artifacts, limiting robustness and task generalization. “On-Policy Context Distillation for LLMs” (2602.12275) introduces On-Policy Context Distillation (OPCD), which fundamentally reorients context distillation via on-policy trajectories and reverse KL minimization, eliminating exposure bias and mode averaging.
Methodology: On-Policy Context Distillation
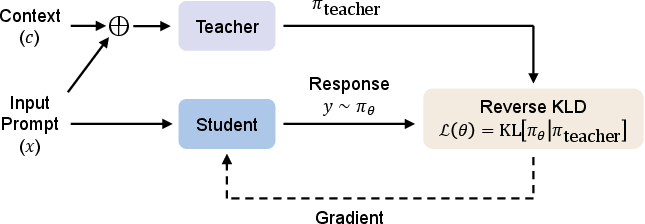
OPCD constructs a context-agnostic student model and a context-informed teacher model. Given data (x,c), where x is the task prompt and c is in-context knowledge (e.g., experiential traces or a system prompt), the student generates autoregressive completions without c. The per-token reverse KL between student and teacher—where the teacher receives [c;x] and the student only x—is minimized along student-sampled trajectories:
This loss incentivizes the student to align its own generation distribution with that of the teacher within the subspace traversed by the student, promoting mode-seeking adaptation and mitigating off-policy artifacts.
Figure 1: Overview of OPCD—student samples without context; reverse KL to a teacher with context updates the student to internalize knowledge on-policy.
OPCD can be instantiated in both teacher-student (πteacher=πθ) and self-distillation (πteacher=πθ) settings, but empirical evidence and stability consistently favor teacher-student with a frozen or periodically updated teacher.
Experimental Validation
Experiential Knowledge Distillation
The primary novel application is task-agnostic experiential knowledge distillation, where the model accumulates context over sequential problem-solving (math reasoning, text games) by extracting high-level, reusable experience from generated traces. OPCD consolidates this context into parameters, measured by subsequent task accuracy and OOD transfer.
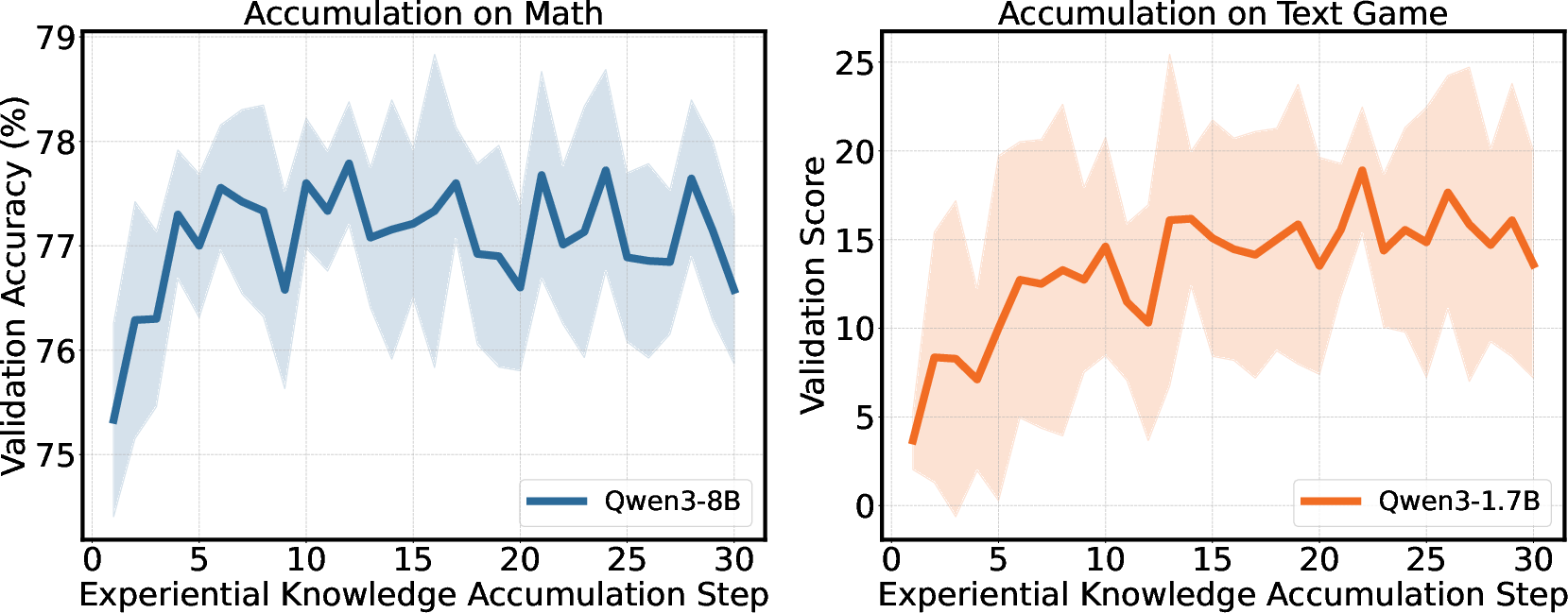
Validation accuracy rises monotonically as experiential knowledge accumulates, with a stair-step improvement after each aggregation step:
Figure 2: Accuracy increases as more distilled experiential knowledge accumulates, demonstrating persistent transfer in both math reasoning and text game domains.
System Prompt Distillation
For persistent behavioral adaptation, OPCD is leveraged to internalize lengthy system prompts for specialized domains (e.g., medical QA, safety classification), enabling downstream deployment without prompt overhead.
On-Policy vs Off-Policy Distillation and Robustness
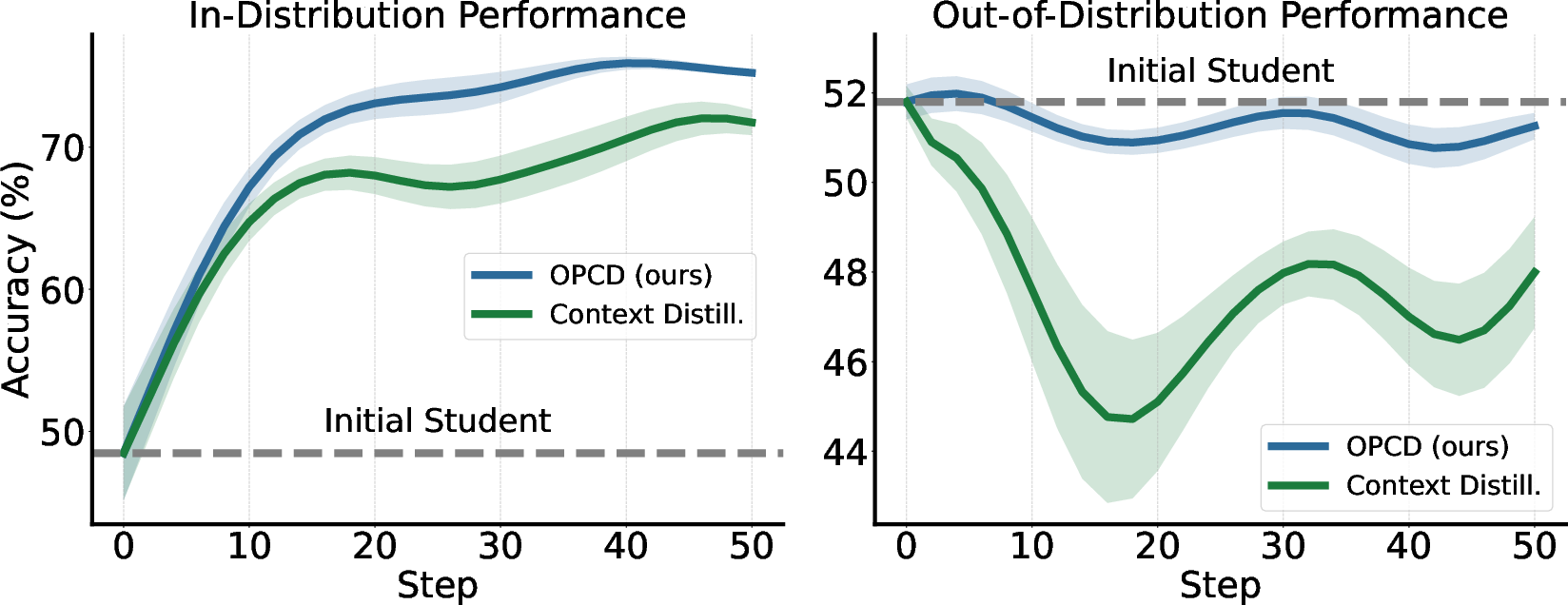
Direct comparison with off-policy distillation shows that OPCD achieves higher in-distribution accuracy and consistently mitigates OOD degradation and catastrophic forgetting. When system prompts for safety are distilled, for instance, OPCD matches or outperforms prior methods, and OOD performance (medical QA after safety prompt distillation) remains preserved, whereas off-policy distillation leads to more severe forgetting:
Figure 3: OPCD preserves OOD (medical) accuracy after safety prompt distillation, in contrast to off-policy distillation, which degrades it.
Model Scale and Teacher-Student Transfer
When knowledge is distilled from a larger frozen teacher to a smaller student, OPCD yields nontrivial gains; direct context injection in small models may even degrade accuracy, revealing the importance of on-policy alignment. Self-distillation was observed to be both less stable and less performant than teacher-student configurations.
Implications, Practicalities, and Theoretical Consequences
OPCD advances context distillation in two critical respects:
Exposure Bias Elimination: Because the student trains on its own trajectories, the mismatch between training and inference is resolved, leading to greater reliability and robustness.
Catastrophic Forgetting Mitigation: By aligning gradients to reverse KL along the student distribution, OPCD avoids broad mode covering, curbing spurious overgeneralization and preserving OOD competencies.
Pragmatically, the method enables continual test-time knowledge accumulation—LLMs can gather experiential traces in live deployment, periodically consolidate them into student models, and deploy these for efficient, prompt-free inference. The architecture is scalable and agnostic to the nature of in-context information (reasoning strategies, safety rules, domain instructions). Theoretically, OPCD aligns context distillation with policy optimization from RL, with the reverse KL fostering sharp, teacher-aligned policies without exposure artifacts.
Exploring hybridization with black-box policy and model distillation for proprietary models.
Integrating OPCD within multi-agent and multi-user environments to support federated or decentralized experiential knowledge accumulation.
Studying the loss landscape, stability, and convergence behaviors of self-vs-teacher-student distillation under varying model update policies.
Conclusion
On-Policy Context Distillation addresses the fundamental shortcomings of off-policy context distillation in LLM knowledge internalization. By minimizing reverse KL divergence on policy, OPCD enables robust and efficient parameterization of transient contexts such as experiential knowledge and system prompts. The method yields improved in-distribution and OOD performance, persistent consolidation of knowledge, and enhanced stability in scaling and transfer. OPCD represents a foundational shift for context distillation methods in LLMs, providing a flexible, theoretically justified, and empirically validated framework for persistent adaptation and continual knowledge integration.