Privileged Information Distillation for Language Models
Abstract: Training-time privileged information (PI) can enable LLMs to succeed on tasks they would otherwise fail, making it a powerful tool for reinforcement learning in hard, long-horizon settings. However, transferring capabilities learned with PI to policies that must act without it at inference time remains a fundamental challenge. We study this problem in the context of distilling frontier models for multi-turn agentic environments, where closed-source systems typically hide their internal reasoning and expose only action trajectories. This breaks standard distillation pipelines, since successful behavior is observable but the reasoning process is not. For this, we introduce π-Distill, a joint teacher-student objective that trains a PI-conditioned teacher and an unconditioned student simultaneously using the same model. Additionally, we also introduce On-Policy Self-Distillation (OPSD), an alternative approach that trains using Reinforcement Learning (RL) with a reverse KL-penalty between the student and the PI-conditioned teacher. We show that both of these algorithms effectively distill frontier agents using action-only PI. Specifically we find that π-Distill and in some cases OPSD, outperform industry standard practices (Supervised finetuning followed by RL) that assume access to full Chain-of-Thought supervision across multiple agentic benchmarks, models, and forms of PI. We complement our results with extensive analysis that characterizes the factors enabling effective learning with PI, focusing primarily on π-Distill and characterizing when OPSD is competitive.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching smaller, open models to do complex, step-by-step tasks by learning from stronger “frontier” models—even when those strong models keep their detailed thinking secret. The trick is to use “privileged information” during training (extra hints that won’t be available later) and still end up with a student model that performs well without those hints at test time.
Think of it like this: during practice, a coach can whisper helpful tips to a player (“pass left now”), but during the real game, the player must act without those whispers. The paper shows how to use those practice-time tips to build skills that stick.
Key Questions
The paper focuses on three simple questions:
- How can a model learn from special training-time hints (privileged information) and still do well without those hints later?
- Can we copy the abilities of powerful, closed-source models that don’t show their step-by-step reasoning, only their actions?
- Which training strategies and types of hints work best, and when?
How They Did It (Methods)
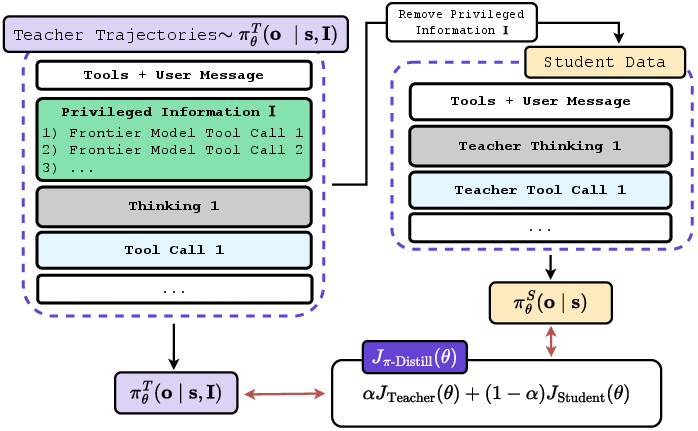
To make this work, the authors use two training approaches that both rely on a “teacher” and a “student,” but with a twist: they’re actually the same model with shared parameters, just used in two different modes.
- Privileged Information (PI): Extra details added during training that won’t be available during testing. For example, the exact tool calls a frontier model made (like “BookRestaurant(name='Luigi’s', time='7pm')”).
- Chain-of-Thought (CoT): The step-by-step reasoning text. Frontier models often hide this. You might see the final action (the move), but not the thought process (why they chose it).
- Reinforcement Learning (RL): Training by trial and error. The model tries actions in an environment and gets a score (reward). Over time, it learns which actions lead to better scores.
- KL Divergence: A way to measure how different two strategies are (like saying how far apart two players’ styles are). A penalty using KL helps keep the teacher and student from drifting too far apart, so learning transfers smoothly.
Here are the two main approaches:
pi-Distill (Privileged Information Distillation)
- Teacher mode: The model sees the training-time hints (PI) and tries to act well, while staying close to the student’s style.
- Student mode: The same model acts without the hints and learns directly from the teacher’s successful examples.
- Both modes are trained together (joint training), which helps the model learn to use hints and also to perform well without them later.
Analogy: It’s like practicing both with the coach’s whispers (teacher) and without them (student), at the same time, so skills transfer.
OPSD (On-Policy Self-Distillation)
- The student acts (no hints). At the same time, the teacher version (with hints) gives guidance, and the training rewards the student for staying close to the teacher’s behavior.
- This is “on-policy” because learning is based on what the student actually does now, not only on past data.
Analogy: The player runs drills without whispers, while comparing each move with what they would have done if they had the coach’s tip—and gets points for matching.
Types of training-time hints (PI) they tried
To learn from frontier models that hide their thought process, the authors turned those models’ action traces into different kinds of hints:
- Tool calls with arguments: Exact tools plus their inputs (most detailed), e.g., “SearchFlights(origin=NYC, date=June 12).”
- Tool calls only: Just the tool names, no inputs (less detailed).
- Self-generated hints: A short suggestion the student creates by summarizing the frontier model’s successful steps (more like advice than instructions).
Where they tested
They used multi-turn, tool-using environments where the model has to plan and call tools:
- TravelPlanner: Planning trips with tools (finding hotels, restaurants, etc.).
- τ-Bench (retail and airline): Customer service tasks using tools (gather info, book flights, help with shopping).
- GEM suite (7 search-based QA tasks): Tests if skills generalize to different domains (out-of-domain, OOD).
Models: Qwen3-4B, Qwen3-8B, and R1-Distill-Llama-8B.
Baselines: Standard supervised fine-tuning (SFT) with and without CoT, RL alone, and SFT followed by RL (industry standard).
What They Found (Results)
In plain terms: using training-time hints worked really well, often better than the usual way of copying the frontier model’s reasoning (CoT) and then doing RL.
Here are the key takeaways:
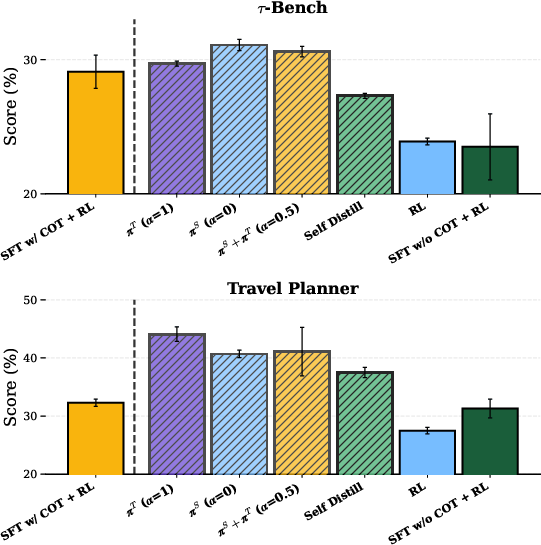
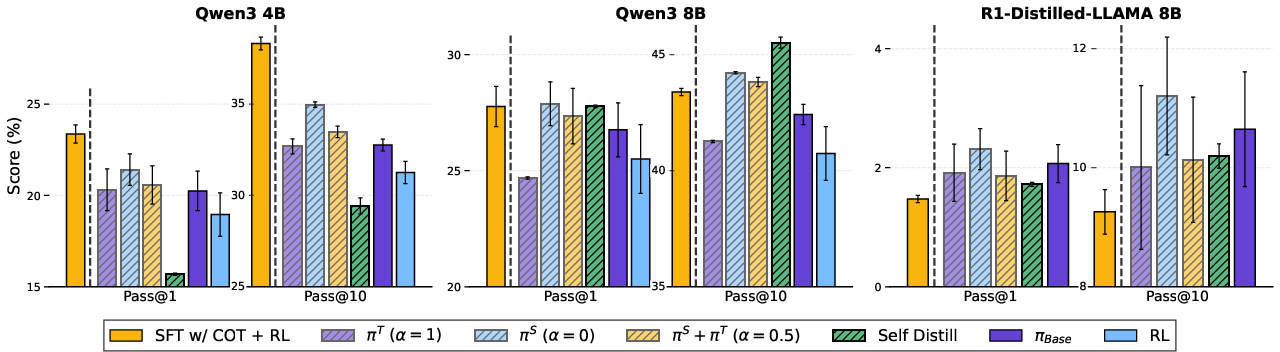
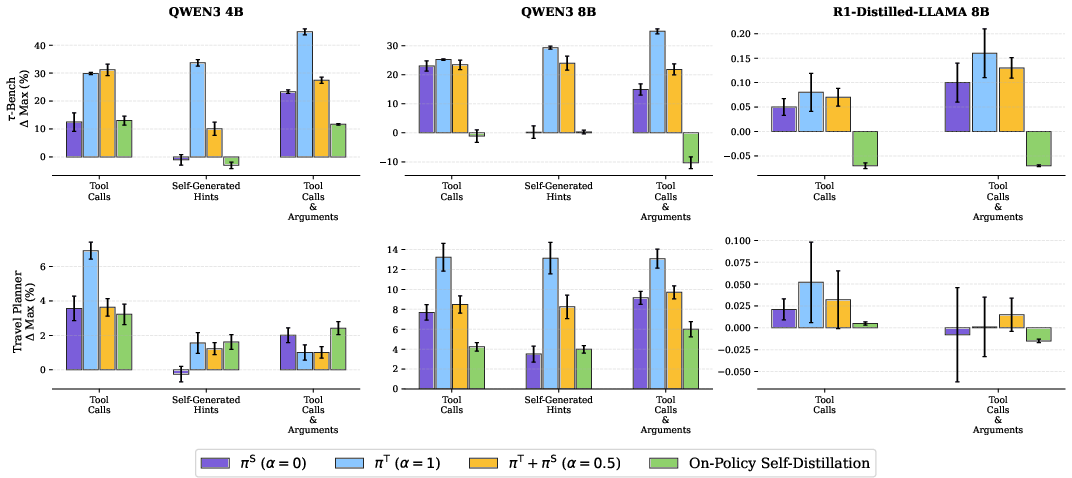
- pi-Distill consistently beats standard methods, including SFT with CoT followed by RL, in many settings. It’s especially strong with the larger Qwen3-8B model on TravelPlanner and τ-Bench (retail).
- OPSD also performs very well in several cases, especially as models get larger. It can outperform RL and SFT+RL that don’t have CoT.
- Even without seeing the frontier model’s CoT (only actions), both methods learn strong behavior and generalize to new, different tasks (OOD tests on the GEM suite).
- Standard RL alone often makes things worse than the base model. pi-Distill avoids this degradation, and OPSD does too on stronger models.
- Efficiency: pi-Distill needs just one training phase, while SFT+RL often requires picking the “just right” fine-tuning checkpoint (which is slow and expensive).
What Makes Hints Work (Simple Insights)
The authors studied why some hints help more than others. Two big factors:
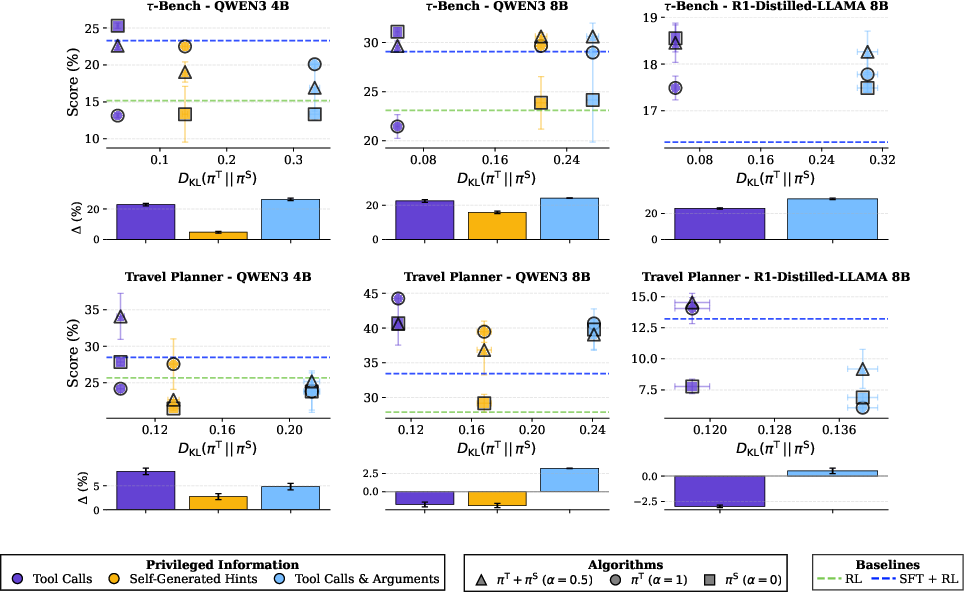
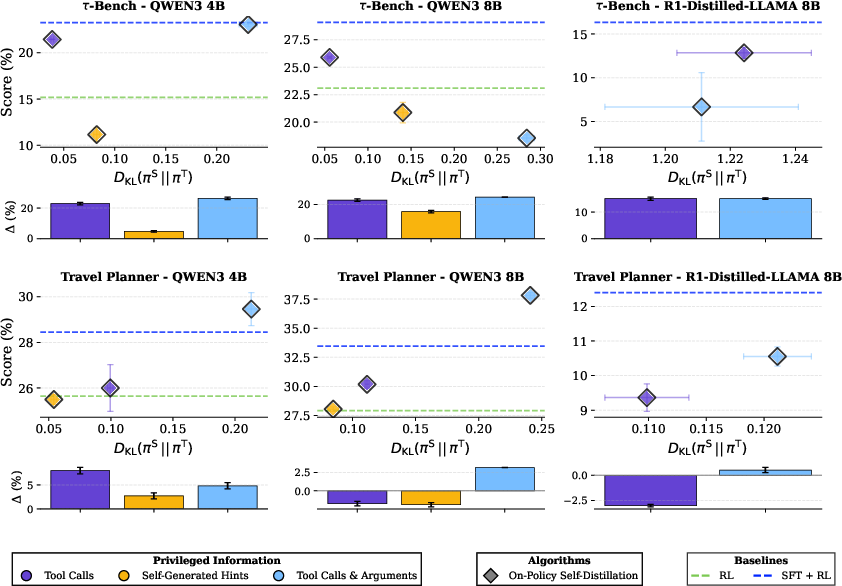
- How different the teacher and student are at the start (KL divergence): If the teacher’s style with hints is too different from the student’s style without hints, it’s harder to transfer the skill.
- How useful the hint is (utility): Does the hint help the teacher actually do better? If the hint doesn’t improve the teacher’s score, it’s not helpful.
Simple rules they observed:
- Student-only training (no teacher updates) works great when the hint makes the teacher and student behave similarly (low KL) and the hint is useful.
- Teacher-only training can fail if the teacher collapses to the student’s behavior and stops using the hints. Joint training avoids that.
- Joint training (both teacher and student together) is the most stable choice overall when you can’t predict which hints will be best.
- For OPSD, richer hints (like tool calls with arguments) often help more, but if the difference between student and teacher is too big (very high KL), the gains can vanish—especially for smaller models.
Why This Matters (Impact)
This work shows a practical path to share the abilities of top, closed-source models without needing their secret step-by-step thoughts. That means:
- Better open models for complex, multi-step tasks like planning trips or handling customer requests.
- Less dependence on hidden Chain-of-Thought data from frontier models.
- More reliable training that doesn’t collapse or overfit, and often better generalization to new tasks.
- Faster training pipelines (pi-Distill needs only one phase), which saves time and compute.
In short, this paper gives us new, effective ways to train models with practice-time help (hints) so they play the real game confidently on their own.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These are grouped to help future researchers prioritize follow‑ups.
Methodology and Theory
- Lack of formal convergence guarantees for π-Distill and OPSD: no proof that joint teacher–student optimization converges to a stable fixed point or that the learned student approximates the intended target distribution under practical settings (finite samples, nonstationary environments, shared parameters).
- Unclear role of KL directionality: the paper empirically uses reverse KL in multiple places, but does not analyze when reverse vs forward KL is preferable for PI transfer and how this choice affects stability, exploration, and mode-covering/mode-seeking behavior.
- Incomplete connection to Variational EM: the proposed link is suggestive, but the target distribution π* is not rigorously characterized for language-agent MDPs; no guarantees that alternating/joint updates approximate a valid E/M-step nor conditions under which collapse is avoided.
- Off-policy bias in π-Distill remains unquantified: student learns from teacher-generated trajectories; the magnitude of off-policy bias, gradient mismatch, and their effect on sample efficiency and stability are not analyzed.
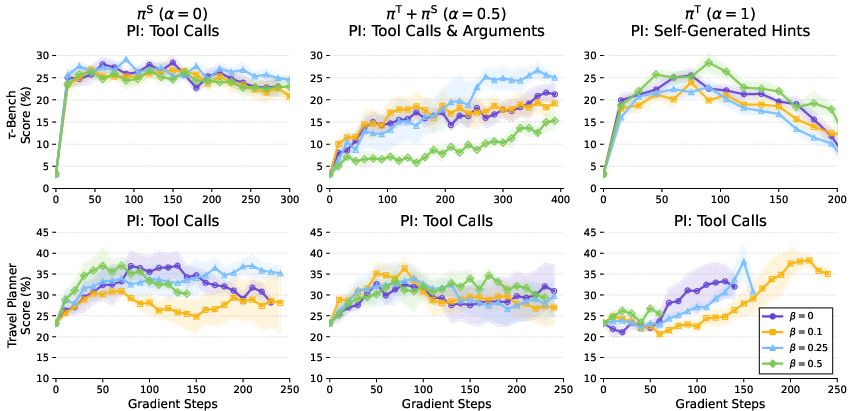
- Missing analysis of β (KL weight) and α (teacher–student blend) schedules: no principled annealing strategies or theoretical guidelines to prevent collapse, reduce distribution shift, and optimize transfer across PI regimes.
Training Dynamics and Stability
- Teacher–student collapse with α=1 is observed but not fully addressed: the paper documents early KL collapse (Teacher ≈ Student) despite β=0; root-cause analysis and robust mitigations (e.g., reference models, adaptive KL targets, orthogonal adapters) are incomplete.
- Sensitivity to hyperparameters: performance depends on α, β, GRPO settings, length penalties, and token-frequency penalties; no systematic sensitivity analysis or automated tuning strategies provided.
- Detecting and handling harmful PI (Δ < 0) is unsolved: the methods degrade when PI utility is negative; no gating/diagnostics to detect low-utility PI online or to adaptively ignore/update PI sources.
- Lack of exploration analysis: unclear whether teacher conditioning dampens exploration; no study of how π-Distill/OPSD behave in sparse-reward settings when PI is partial or misleading.
- Absence of curriculum/annealing for PI usage: no investigation of gradually reducing PI conditioning or staged α/β schedules to smooth the student’s transition to test-time conditions.
Assumptions and Acquisition of Privileged Information
- Realistic PI availability and noise are underexplored: closed-source systems may expose partial/misformatted/noisy actions; robustness to incomplete, inconsistent, or adversarial PI (e.g., truncated arguments, tool failures, API changes) is not evaluated.
- PI coverage and data-scaling unknowns: how performance scales with the number of tasks with PI (e.g., 300/500 in τ-Bench), PI density (arguments vs names vs hints), and multiple trajectories per task remains unquantified.
- Cost–performance trade-offs: the sample efficiency and cost of acquiring frontier trajectories (API cost, rate limits, licensing) vs gains from π-Distill/OPSD are not estimated; no active selection strategy for which trajectories to mine or which PI type to construct.
- Limited PI formats: only three PI types (calls+args, calls-only, self-generated hints) are considered; utility of additional forms (e.g., error traces, environment states, teacher value estimates, counterfactuals, failure annotations) is untested.
Empirical Scope and Evaluation
- Domain generality is uncertain: experiments focus on tool-use customer service and travel planning plus search QA; applicability to other agentic settings (web navigation, code agents, math reasoning, robotics, multi-modal tools) is untested.
- Simulator and environment changes may confound comparability: replacing GPT-4o user simulator with Qwen-14B and modifying TravelPlanner reward rubrics limit comparability with prior work; no ablation estimating impact of these changes.
- OOD evaluation breadth: OOD tests cover search-tool QA only; generalization to dissimilar tools, longer horizons, non-search APIs, and dynamic web environments remains unknown.
- Metrics narrowness: evaluation emphasizes task success (Pass@k); sample efficiency (episodes to reach X%), latency, token/step efficiency, and human-in-the-loop measures are not reported.
- Fair data accounting: SFT baselines use all successful traces, while π-Distill/OPSD rely on a selected minimal-step trace per task; effects of different data budgets and selection criteria are not controlled.
OPSD-Specific Questions
- Model-size dependence: OPSD underperforms on smaller models (e.g., Qwen3-4B) but excels on larger ones; the mechanism behind this capacity dependence and guidelines for choosing OPSD vs π-Distill are unclear.
- KL vs information richness trade-offs: OPSD sometimes benefits from high-information PI despite high KL, yet fails when KL is too large; a predictive criterion or adaptive control to balance KL and information content is missing.
- On-policy variance and safety: the stability and variance of OPSD updates under sparse/noisy rewards are not quantified; no analysis of catastrophic policy drift or safeguards.
Practical Deployment and Safety
- PI leakage safeguards are ad hoc: token-frequency penalties and prompt placements are used, but no formal guarantees or audits ensure the student does not implicitly depend on PI tokens or memorized patterns at test time.
- Reward hacking and simulator artifacts: the need to remove reward-hack-prone tools indicates vulnerability; robustness to reward gaming and adversarial environment responses is not studied.
- Privacy and compliance: using proprietary trajectories as PI raises data-governance questions (consent, storage, re-use); no discussion of compliance constraints or privacy-preserving PI distillation.
Algorithmic Extensions and Alternatives
- Alternatives to shared-parameter coupling: whether separate teacher/student with partial parameter sharing (adapters/LoRA), or orthogonal subspaces, would reduce collapse and improve transfer is not explored.
- Alternative RL/backbones: results use GRPO variants; comparative performance with PPO, ReMax, DAPO, or value-based/actor–critic methods and their interaction with PI are unknown.
- Multi-trajectory and confidence-weighted distillation: using multiple frontier traces per task, aggregating with uncertainty/confidence scores, or filtering suboptimal traces is not investigated.
- Active/online PI acquisition: how to request, summarize, or select PI adaptively during training (e.g., querying frontier models only when the student’s uncertainty or error is high) is open.
- Cross-domain/meta-PI transfer: whether PI learned in one domain can be distilled to improve policies in different tools/domains (meta-learning or representation transfer) remains untested.
- Multi-modal and non-language PI: applicability to vision or audio tool-use and environments where PI includes non-text signals (screenshots, UI states) is unaddressed.
Reproducibility and Reporting
- Compute and efficiency reporting: wall-clock time, tokens processed, and energy costs are not reported; head-to-head efficiency vs SFT+RL (including SFT checkpoint sweeps) is unclear.
- Seed and variance characterization: while three seeds are reported, deeper variance diagnostics (run-to-run instability, early stopping sensitivity, outlier runs) and confidence intervals across environments are limited.
- Open-source parity: modifications to benchmarks and reward functions may hinder exact replication; standardized evaluation harnesses and environment diffs are not provided.
These gaps suggest concrete next steps: robustly model KL/utility trade-offs, develop collapse-resistant schedules and architectures, broaden PI types and domains, quantify data and compute efficiency, and formalize guarantees for safe and privacy-preserving PI transfer.
Glossary
- Action-only PI: A form of privileged information that contains only the actions (not reasoning) from expert trajectories. Example: "effectively distill frontier agents using action-only PI."
- Agentic environments: Interactive, multi-step settings where an LM acts as an agent over multiple turns. Example: "distilling frontier models for multi-turn agentic environments"
- Chain-of-Thought (CoT): Explicit intermediate reasoning tokens produced by an LM. Example: "hide their full Chain-of-Thought (CoT) reasoning,"
- Clipped importance-weighted policy updates: A stabilization technique in policy optimization that limits importance weights when updating the policy. Example: "clipped importance-weighted policy updates"
- Clipping parameter: The hyperparameter controlling the bounds for ratio clipping in policy optimization. Example: "and ε is the clipping parameter."
- Dense per-token reward: A learning signal that assigns rewards at the token level rather than only at episode end. Example: "the reverse KL acts as a dense per-token reward"
- Distillation: Transferring knowledge from a teacher model to a student model. Example: "This breaks standard distillation pipelines,"
- Distribution shift: A mismatch between the training and deployment distributions that can harm transfer. Example: "actively mitigating distribution shift during transfer."
- Frontier models: The most capable, state-of-the-art LLMs, often closed-source. Example: "distilling frontier models for multi-turn agentic settings."
- Group Relative Policy Optimization (GRPO): A policy-gradient algorithm using groupwise baselines and clipping for stability. Example: "We optimize using Group Relative Policy Optimization (GRPO)"
- Group-relative advantage: An advantage computed relative to other sampled trajectories in the same group. Example: "We define a group-relative advantage "
- Length penalty: A reward shaping term that penalizes overly long trajectories. Example: "we adopt a length penalty reward"
- Markov Decision Process (MDP): A formalism for sequential decision making defined by states, actions, transitions, and rewards. Example: "We formalize long-horizon, multi-turn agentic environments as a Markov Decision Process (MDP)."
- Maximum attainable utility (Δ_max): The best possible performance gain from PI relative to non-PI training. Example: "maximum attainable utility on "
- Off-policy learning: Training a policy using trajectories generated by a different policy. Example: "can be viewed as off-policy learning,"
- On-Policy Self-Distillation (OPSD): An objective that trains the student on its own rollouts while regularizing toward a PI-conditioned teacher via reverse KL. Example: "On-Policy Self-Distillation (OPSD), an alternative approach that trains using Reinforcement Learning (RL) with a reverse KL-penalty"
- Out-of-distribution (OOD): Evaluation on tasks or domains different from those seen in training. Example: "out-of-distribution (OOD) on GEM tool-use tasks"
- Pass@1/Pass@10: Metrics reporting the probability that a correct solution appears within the top 1 or top 10 attempts. Example: "We report Pass@1 and Pass@10 on the GEM search-tool benchmark suite"
- Privileged Information (PI): Additional training-time information unavailable at inference that can improve learning. Example: "Training-time privileged information (PI) can enable LLMs to succeed on tasks they would otherwise fail,"
- Privileged Information Distillation (π-Distill): A joint objective where a PI-conditioned teacher and unconditioned student share parameters and are trained together. Example: "we introduce -Distill, a joint teacher-student objective"
- Reverse KL divergence: A divergence measure D_KL(p||q) used here to regularize the student toward the teacher or vice versa. Example: "uses a reverse KL divergence between the student and the PI-conditioned teacher"
- Reward hacking: Exploiting loopholes in the reward function to obtain high reward without solving the intended task. Example: "as it consistently led to reward hacking."
- Sampling policy μ: The policy used to generate trajectories for estimating objectives or gradients. Example: "according to the current sampling policy "
- Self-generated hints: Summaries or guidance produced by the model from expert trajectories to provide compact PI. Example: "Self-generated hints. We prompt the trained model model to summarize a successful trajectory"
- Shared-parameter model: A single model that serves both teacher and student roles by conditioning, sharing all weights. Example: "using a single shared-parameter model"
- Stop gradient operator: An operation that prevents gradients from flowing through a variable during backpropagation. Example: "where indicates the stop gradient operator."
- Supervised Fine-Tuning (SFT): Training on labeled outputs (e.g., expert trajectories) via supervised learning. Example: "Supervised Fine-Tuning (SFT) on frontier model outputs"
- Teacher–student objective: A training setup where a teacher guides a student policy, often via distillation or KL regularization. Example: "a joint teacher-student objective"
- Tool-calling environments: Benchmarks where agents must invoke external tools/functions to complete tasks. Example: "within multi-turn tool-calling environments."
- Transition function: The stochastic mapping from current state and action to the next state. Example: "via a transition function "
- Utility Δ: The performance gain provided by PI relative to no-PI, measured as Teacher score minus Student score on training tasks. Example: "captured by the utility "
- Variational Expectation-Maximization (EM): A framework alternating between optimizing an approximate posterior (E-step) and parameters (M-step). Example: "Variational Expectation-Maximization (EM)"
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed with current tooling and data practices, each linked to sectors and noting key dependencies.
- Customer-service tool-use agent distillation
- Sector: Software, Retail, Travel, Telecom
- Application: Distill closed-source agents’ successful action traces (API calls, parameters) from production logs into open-source models using π-Distill/OPSD to improve resolution rates in multi-turn support (returns, bookings, account updates).
- Workflow/Product: “Action-only distillation” pipeline: Log2PI converter + PI-aware trainer (π-Distill with GRPO) + evaluation harness (τ-Bench/TravelPlanner/GEM).
- Assumptions/Dependencies: Access to high-quality successful action logs; consistent tool schemas; reward functions aligned to business outcomes; privacy compliance for log export; moderate compute.
- Enterprise workflow automation from runbooks and click-streams
- Sector: Software (SaaS), IT Ops, DevOps
- Application: Distill human or legacy agent runbooks and UI/API action histories into a student policy that operates without hints at inference (ticket triage, change management, incident resolution).
- Workflow/Product: “Runbook distiller” that ingests tool calls only or tool calls + arguments and trains a shared-parameter teacher/student.
- Assumptions/Dependencies: Stable runbook schemas; sufficient coverage of successful traces; monitoring to prevent teacher–student collapse (KL checks); A/B testing.
- Sales and retail assistants for catalog and order management
- Sector: Retail, E-commerce
- Application: Improve multi-turn tool-calling (inventory lookup, pricing, returns) by converting frontier agent action trails into PI (tool calls + args; tool calls only) and training open models with π-Distill.
- Workflow/Product: “CatalogOps Agent Trainer” with PI type selection and α-tuning (student-only vs joint).
- Assumptions/Dependencies: Accurate product metadata; robust argument extraction from traces; simulated or offline rewards to reduce live risk.
- Travel planning assistants
- Sector: Travel, Hospitality
- Application: Use successful itineraries and tool interactions (search, bookings, constraints verification) as PI to train smaller open models to match frontier-level planning without CoT.
- Workflow/Product: “Itinerary Distiller” built atop TravelPlanner; hint generator for self-generated PI where tool calls are sparse.
- Assumptions/Dependencies: High-utility PI (positive Δ); adjusted rewards to avoid length-induced collapse; provenance tracking of booked constraints.
- Security operations (SOC) playbook distillation
- Sector: Security
- Application: Distill action-only traces from SOC runbooks (query logs, containment actions) to produce agents that execute incident response steps without sensitive CoT.
- Workflow/Product: “SOC Playbook Distiller” with OPSD for stronger models to leverage dense per-token reverse-KL reward.
- Assumptions/Dependencies: Strict access control; de-identification; reward shaping for false positives/negatives; trace quality.
- Customer onboarding, KYC automation
- Sector: Finance, FinTech
- Application: Train agents to navigate KYC toolchains from successful action logs (document verification, sanctions checks) while preserving compliance by avoiding CoT retention.
- Workflow/Product: “KYC Action Distiller” using tool calls + arguments PI; audit dashboard to track KL and Δ during training.
- Assumptions/Dependencies: Regulatory approval; de-identified logs; explainability requirements; sandbox evaluation.
- Educational LMS assistants
- Sector: Education
- Application: Distill teacher or expert agent action sequences (grading tools, rubric application) to produce tutoring and auto-feedback agents that operate without CoT and reduce leakage risk.
- Workflow/Product: “LMS Tutor Distiller” with self-generated hints for sparse or high-KL settings; α=0.5 joint training for stability.
- Assumptions/Dependencies: Consent and FERPA/GDPR compliance; reward definition aligned to pedagogy (learning gains, rubric adherence); OOD evaluation.
- Internal compliance and policy assistants
- Sector: Enterprise Governance, Legal
- Application: Distill compliant workflows from action logs (policy retrieval, exception handling) to assist employees without exposing sensitive internal rationales.
- Workflow/Product: “Compliance Companion” trained on tool calls only to mitigate distribution shift; OPSD in stronger models for generalization.
- Assumptions/Dependencies: Policy repository access; legal review; tracking teacher–student KL to avoid overfitting.
- Productization of PI-distillation tooling
- Sector: Software, MLOps
- Application: Offer an SDK around π-Distill/OPSD with:
- Log2PI converter (tool calls + args, tool calls only, self-generated hints)
- PI-aware trainer (GRPO + reverse KL, α scheduling)
- Benchmarks and OOD suites (τ-Bench, TravelPlanner, GEM)
- Assumptions/Dependencies: Integration with customer logging stacks; ethical data use; resource management (context limits, token KL penalties).
- Privacy-preserving frontier behavior transfer
- Sector: Cross-sector
- Application: Improve open models by learning from frontier action trajectories without storing CoT; reduces risk of proprietary or sensitive rationale leakage.
- Workflow/Product: “Action-Only Distillation Service” offering managed training with confidentiality guarantees.
- Assumptions/Dependencies: Contractual permission to log actions; data minimization; PI leakage checks; policy to prevent teacher–student collapse.
Long-Term Applications
The following use cases require further research, scaling, validation, or cross-domain adaptation before broad deployment.
- Clinical workflow assistants trained from EHR action logs
- Sector: Healthcare
- Application: Distill clinician tool-use (order sets, documentation macros) into safe assistants that operate without privileged inputs at inference.
- Tools/Products: “EHR Workflow Distiller” with offline RL simulators; risk-aware reward; joint training for stability (α≈0.5).
- Assumptions/Dependencies: IRB approval; de-identification; extensive clinical validation and safety monitoring; regulatory clearance (FDA/EMA); robust OOD generalization.
- Financial decision support and trade operations
- Sector: Finance
- Application: Distill expert action sequences (risk checks, trade routing, reconciliation) into assistants that support decisions without exposing proprietary CoT.
- Tools/Products: “OpsDistill for Finance” with multi-modal PI (market states) and governance integration (audit trails, controllable policies).
- Assumptions/Dependencies: Supervisory approval; model risk management; stress testing; safeguards against hallucinatory actions; data-sharing agreements.
- Robotics and embodied agents with privileged sensors at train-time
- Sector: Robotics, Manufacturing, Logistics
- Application: Apply the PI concept to privileged onboard sensors (e.g., motion capture, full state) at training, distilling policies that act with limited perception at test-time.
- Tools/Products: “Privileged-to-Policy” trainer bridging language/action frameworks to control; sim-to-real curricula leveraging OPSD.
- Assumptions/Dependencies: Adaptation of token-based PI to continuous control; new reward formulations; safety validation; sim fidelity; hardware integration.
- Energy grid operations assistants from SCADA/EMS action logs
- Sector: Energy, Utilities
- Application: Distill operator action sequences (dispatch changes, contingency analysis) into advisory agents that respect safety limits and operate without privileged grid state at inference.
- Tools/Products: “GridOps Distiller” with domain-specific reward shaping and guardrails.
- Assumptions/Dependencies: Critical infrastructure constraints; rigorous sandboxing; regulator collaboration; incident post-mortem data availability.
- Federated or privacy-preserving PI distillation at the edge
- Sector: MLOps, Consumer Devices
- Application: Train assistant policies across organizations/devices from local action logs without centralizing sensitive data; share parameter updates, not raw PI.
- Tools/Products: “Federated PI-Distill” platform with differential privacy and KL/Δ telemetry.
- Assumptions/Dependencies: Communication efficiency; privacy guarantees; heterogeneity of tools; standardization of action schemas.
- Governance frameworks for action-log sharing and interoperability
- Sector: Policy, Standards
- Application: Establish standards to export action-only traces with consent, enabling ecosystem-level model distillation while protecting proprietary CoT.
- Tools/Products: “Action Trace Standard” and audit tools; best-practice guides for KL/Δ monitoring; contracts for limited-use PI.
- Assumptions/Dependencies: Industry consensus; privacy/security norms; enforcement mechanisms; alignment to regional regulations.
- Multi-modal privileged information distillation
- Sector: Cross-sector AI
- Application: Extend π-Distill/OPSD to vision/speech privileged signals (e.g., high-resolution sensor data, expert annotations) during training, generalizing to low-information modalities at inference.
- Tools/Products: “MM-PI Trainer” with shared-parameter teacher/student across modalities.
- Assumptions/Dependencies: Architectures supporting multi-modal KL penalties; data availability; robust reward design.
- Continual learning with on-policy self-distillation
- Sector: Research, MLOps
- Application: Use OPSD to maintain performance across evolving tasks and tools, minimizing catastrophic forgetting and improving OOD generalization.
- Tools/Products: “Continual OPSD” scheduler with task-aware α/β tuning and KL caps; dynamic reward reweighting.
- Assumptions/Dependencies: Stronger base models (OPSD benefits scale with capacity); reliable per-token reward signals; evaluation suites for drift.
- Safety and alignment guardrails for action-only PI
- Sector: Safety, Responsible AI
- Application: Formalize safeguards to prevent reward hacking and PI leakage (e.g., “hint” token penalties), detect teacher–student collapse, and constrain high-KL regimes that degrade performance.
- Tools/Products: “PI Safety Kit” (leakage penalties, KL monitors, Δ dashboards, collapse detectors).
- Assumptions/Dependencies: Organizational adoption of safety telemetry; red-teaming; incident response playbooks.
Implementation Notes and Dependencies (cross-cutting)
- Data prerequisites: Access to high-quality successful trajectories (action logs); de-identification and consent; schema consistency for tools/APIs.
- Model/training prerequisites: Compute capacity; reward functions (task success, length penalties); monitoring of initial KL and utility Δ; α selection (student-only for low-KL, joint for robustness).
- Legal and compliance: Contracts for trace sharing; adherence to privacy regulations (GDPR/CCPA/HIPAA/FERPA); internal data governance.
- Risk management: A/B testing before full rollout; OOD evaluation (GEM) to detect regressions; fallback policies; human-in-the-loop for safety-critical domains.
By focusing on action-only privileged information and shared-parameter teacher–student training, the paper’s methods enable organizations to transfer frontier behaviors into deployable open models today, while laying groundwork for safe, scalable adoption across regulated and high-stakes settings.
Collections
Sign up for free to add this paper to one or more collections.